 電子發燒友App
電子發燒友App


文章來源:電信工程技術與標準化,作者:林宇俊,許鑫伶,何洋,魯銀冰
近年來,通信信息詐騙造成的損失逐年遞增,且詐騙形式和劇本層出不窮。通信信息詐騙已形成了一條非常完整的犯罪產業鏈。根據有關機構測算,通信信息詐騙從業者達上百萬人,年產業規模已經高達千億元。目前通信信息詐騙案例集中呈現出了一些新的特征。
一是詐騙模式事件鏈化、精準化。犯罪分子往往利用社會工程學設置詐騙場景腳本,利用不斷升級的詐騙手法、運營商的業務規則和流程漏洞,通過詐騙事件鏈設置將受害人一步步引入圈套,讓人防不勝防。
二是詐騙渠道和手段多樣化、專業化,隨著科技手段的進步,作案手段已從最原始的發短信、打電話等發展到掃描惡意二維碼植入木馬病毒、釣魚詐騙等惡意網站等多種渠道聯合作案的新型犯罪手段。
隨著5G技術的發展,通信將變得更加便捷,數據源變得更多樣化,數據量也會呈現激增的趨勢。采用傳統的社會治理手段和識別規則難以適應,相關部門和企業防范打擊經驗不足,防不勝防。
1 研究目的
隨著互聯網和5G的發展,運營商采集的數據源更豐富,產生的數據量呈指數上升。電信詐騙作案方式也層出不窮,從冒充親友類的“猜猜我是誰”的常見詐騙方式,到結合了匿名網站、釣魚網站和垃圾郵件等多種黑產手段的新型詐騙方式。因此,通信信息詐騙案件更難檢測和預防,也對通信信息詐騙治理工作提出了更高要求,即須能夠利用大數據技術,在短時間內處理海量通信數據,并能利用機器學習方法建模,及時對詐騙案件進行研判和處置。
目前業界主要的騷擾詐騙電話識別方案有以下幾種。
(1)語音分析:分析陌生電話語音內容,使用自然語言處理提取行為特征,但造成侵犯用戶通話隱私和影響用戶感知等不良影響。
(2)閾值匹配:從主叫號碼字段匹配及其呼叫頻率閾值,再用投訴樣本數據對其驗證,易造成具有字段特征的普通用戶號碼被誤判,亦難以識別出不具有號碼字段特征的詐騙電話,且投訴樣本數量少,只有少量詐騙電話被記錄。
(3)聚類計算:計算詐騙電話簇和主叫號碼簇相似度,并與已確認的詐騙電話特征指標值進行匹配,但易造成廣告營銷等電話與詐騙電話較為相似,從而誤判的情況。且通信信息詐騙形式多變,活躍期短,因而無法得到有效管控。
在5G背景下,由于數據流的數量和速度呈指數上升,識別和防止詐騙的數據處理的復雜程度也隨之增大。
在數據源方面:由于5G 將大規模地提供物聯網等微服務,因而數據庫引擎必須能夠從多個通道中提取信令數據,且支持多種數據格式。
在時效性方面:為了更及時有效地識別詐騙行為,需要在秒級別內自動應用數千個內置機器學習規則。
在準確性方面:為了阻止欺詐性交易和用戶,底層數據庫需要實時分析數千個屬性,以做到實時智能和復雜事件處理,例如用戶行為、地理位置、設備信息和交易類型等。使用內置機器學習算法,將這些屬性與正確的行為進行比較,并在事件中識別和阻斷、提醒。
基于上述問題,本文提出了一種治理通信信息詐騙的方法,可利用大數據中的Hadoop組件,實現5G時代下從信令中提取疑似碼號的通信特征,而后利用XGBoost算法,通過對海量黑白樣本的學習,建立一套詐騙案件識別模型,能夠對通訊信息詐騙進行快速研判和處置。
2 系統技術架構
整體系統技術架構如圖1所示。系統主要包含詐騙電話識別、受害程度判定規則及易感人群識別等三大模塊。利用信令數據中異常主叫行為及事件鏈來識別詐騙號碼,利用通話相似行為來識別通信信息詐騙受害人,并結合業務運營支撐系統(BOSS)數據中用戶歷史通話數據、身份數據和消費數據來對易感程度進行分級。
在詐騙電話識別算法中主要涉及到信令數據中的若干字段,提取用戶的通話異常行為,并篩選該通話異常行為前后的通話行為,對與該用戶有過通話的主叫號碼和被叫號碼進行標記,作為疑似詐騙電話集合。從信令數據、BOSS數據中提取疑似詐騙電話的全部通話特征,依據CART決策樹和異常點檢測識別規則對是否為詐騙電話進行判別。
若判別為詐騙電話,則篩選出與詐騙電話有過通話行為的所有號碼,根據通話行為特征判別上述用戶受害程度。
最后根據深度受害人用戶通話和消費行為,對易感人群進行畫像,從而實現對其他用戶的易感程度分級。
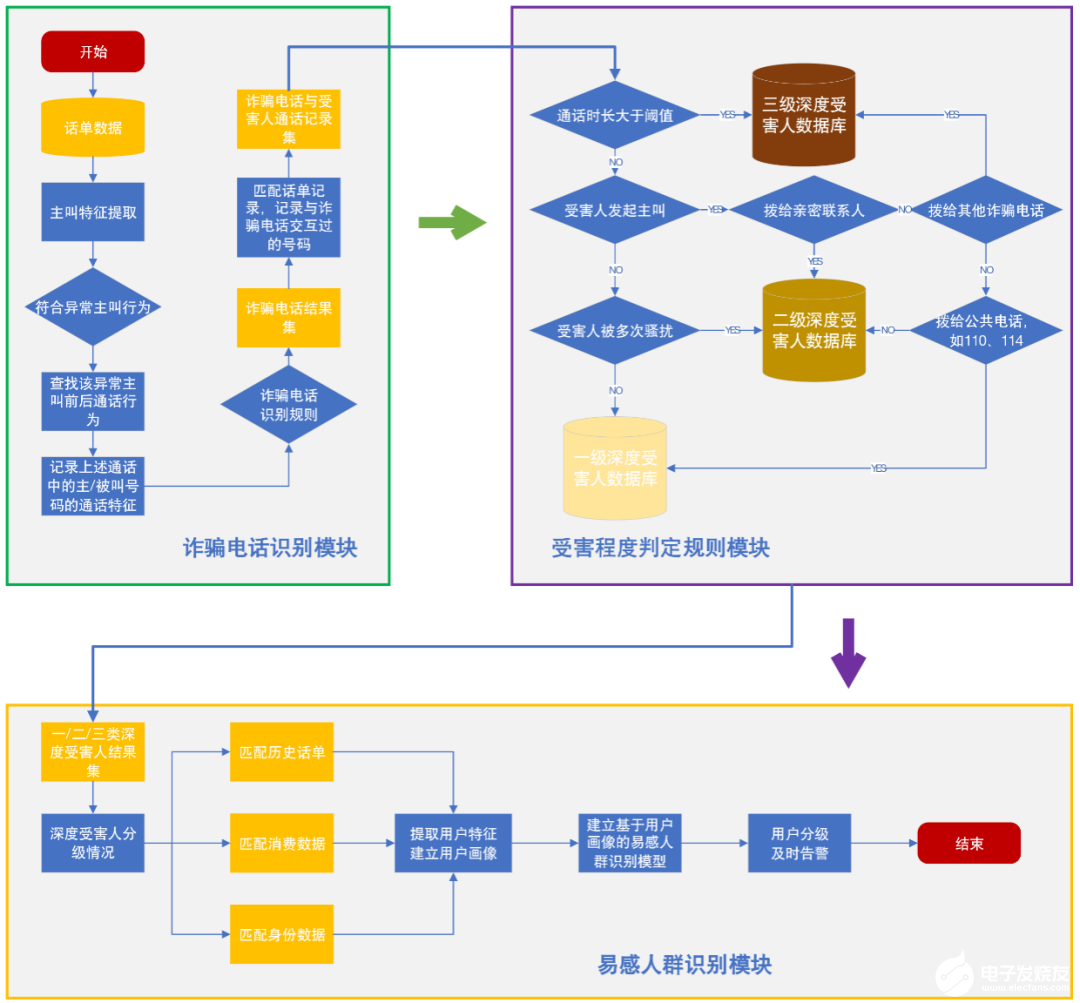
圖1 整體系統技術架構
3 設計實現
3.1 詐騙電話識別模塊
該模塊用于精準識別詐騙電話。對于被網絡爬蟲標記且具有異常通信特征的用戶,采用CART決策樹模型進行識別。而對于活躍期短或新出現的詐騙電話,利用用戶異常主叫及其前后通話行為事件鏈模型進行識別。
3.1.1 標簽樣本爬取及樣本標記
由于大量已標記的詐騙/騷擾電話樣本獲取困難。因此采用網絡爬蟲的方式,將所有樣本號碼提交到360、百度等網站,利用這些網站自有的黑名單庫對樣本號碼進行檢測,爬取被各種手機助手標記的疑似詐騙/騷擾號碼信息。將這些可疑號碼信息導入數據庫用于模型訓練。
由于用戶在各種手機助手標記手機號碼時的不確定性,采用以下方法來提升標記結果的準確性。
(1)當360和百度對同一號碼標記,得到的結果相同時,采用該標記結果。
(2)當360和百度對同一號碼標記,得到的結果不相同時,對該號碼在行為特征上進行分析,選擇行為特征邏輯上與標記結果比較符合的作為最終標記結果。如號碼1822553****,在百度上標記為騷擾電話,在360上標記為正常號碼,從數據庫中分析此號碼通信行為特征可知,該號碼在一天內主叫通話次數14次、主叫率1、主叫聯系人個數14、主叫外地聯系地個數14、被叫通話次數0、回撥率0、聯系人/通話次數比例1等,不太符合正常手機用戶的通信行為,因此將該號碼標記為騷擾電話。
3.1.2 特征選擇及特征統計分析
考慮到詐騙/騷擾電話、響一聲電話、呼死你電話在通信行為上與正常電話之間必然存在某些區別,而且這些電話多為主叫,因此選取以下通信行為特征(包括主叫通話次數、主叫外地通話次數、主叫率、主叫聯系人個數、主叫外地聯系人個數、主叫外地聯系地個數、主叫通話頻率、主叫通話時長、被叫通話次數、回撥率、活動基站數、聯系人/通話次數比例等)進行統計分析。
對某一天某個省的信令數據進行統計分析,以下通過表格的方式對4種號碼類型的各項通信特征的統計值進行具體展現,如表1所示。
表1 4類號碼通信特征統計值

選擇統計分析下較顯著的特征(主叫通話次數、主叫率、主叫外地聯系人個數、主叫外地聯系地個數、主叫通話頻率、主叫通話時長、回撥率、聯系人/通話次數比例),將兩兩特征進一步關聯分析,用圖2直觀地展現這4種號碼類型在特征上的區別。
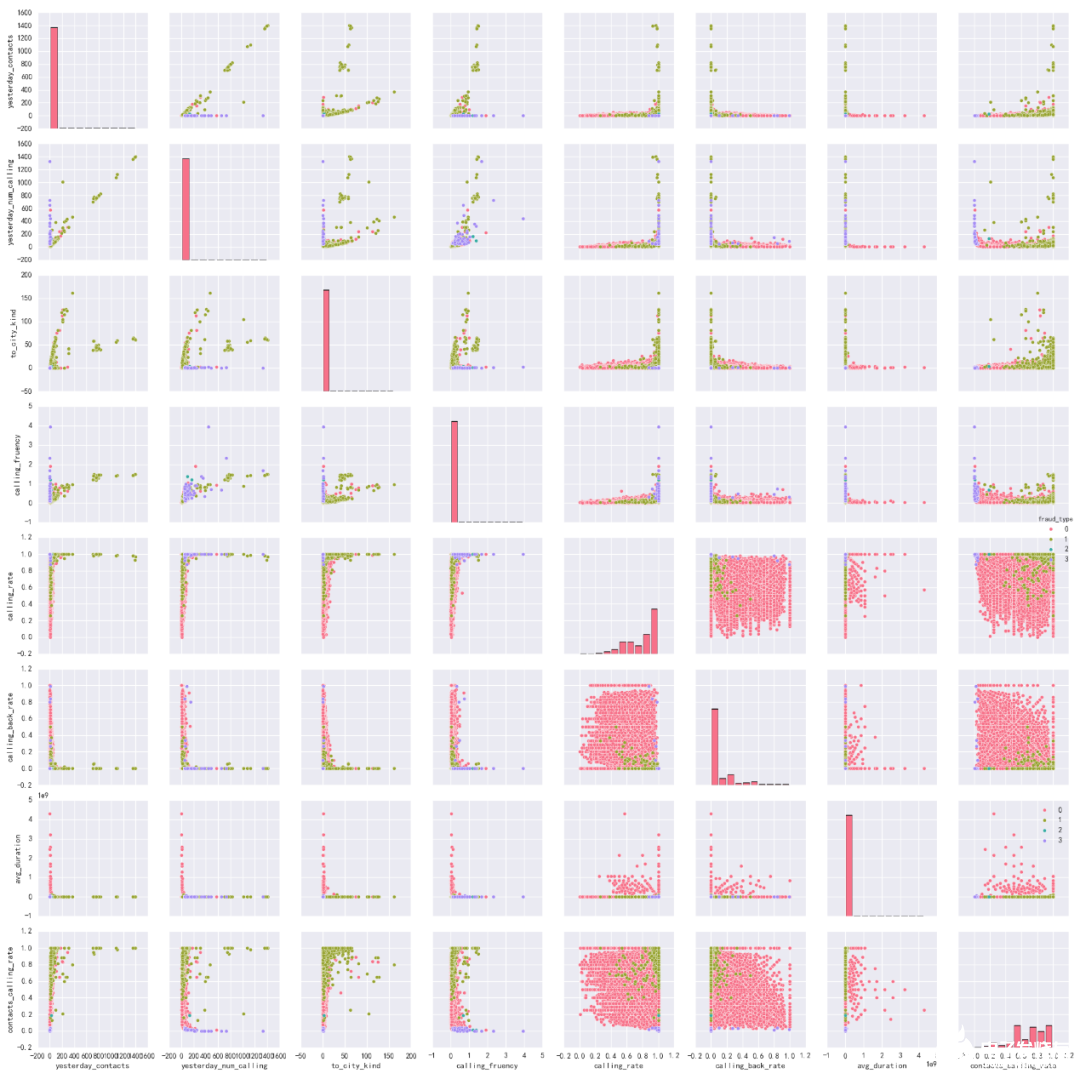
圖2 4類號碼特征區別
從特征統計分析表和兩兩特征關聯分析圖可知,正常號碼、詐騙電話、響一聲、呼死你在某些特征上具有顯著區別。具體如表2所示。
表2 4類號碼主要特征
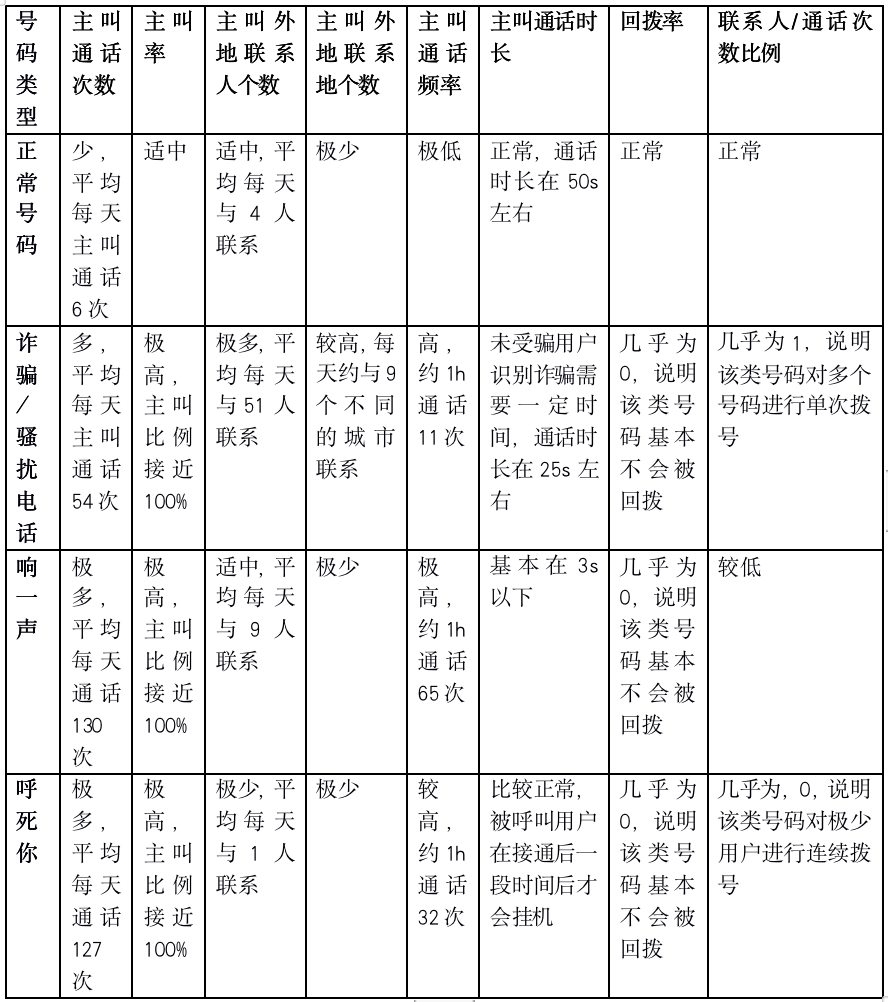
從表2可得以下結論。
(1)詐騙/騷擾電話、響一聲、呼死你在主叫通話次數、主叫率、主叫通話頻率都大大高于正常號碼,而在回撥率上大大低于正常號碼。
(2)響一聲、呼死你相對于詐騙/騷擾電話主叫通話次數更多,主叫外地聯系人個數較少,通話頻率更高,聯系人/通話次數比例極少。
(3)響一聲相對于呼死你、詐騙/騷擾電話在主叫通話時長上有顯著區別。
為進一步區分這4類號碼,引入決策樹做具體分析。
3.1.3 基于CART決策樹的詐騙電話識別模型
將主叫通話次數、主叫率、主叫外地聯系人個數、主叫外地聯系地個數、主叫通話頻率、主叫通話時長、回撥率、聯系人/通話次數比例等共8個特征作為CART決策樹的輸入變量,決策樹深度為5,樣本量為100萬。目標類型中0代表正常號碼、1代表詐騙/騷擾電話、2代表響一聲、3代表呼死你。
通過決策樹得到的決策規則后,對預測數據采用該規則進行預測,得出疑似詐騙/騷擾電話結果集1。
3.1.4 基于XGBoost三分類模型
由于詐騙號碼和廣告號碼沒有明確的界限,需對于CART決策樹結果中詐騙、廣告、普通用戶(類型1和類型2的號碼)進行進一步識別,即三分類模型。其中詐騙即網絡標記為詐騙、騷擾或被用戶舉報的,廣告即網絡標記為中介或廣告推銷等。
三分類標簽化處理情況如下:設label0-1代表互聯網標簽無標記的號碼,label1-1代表互聯網標簽標記為“騷擾” 或 “詐騙”的號碼,label2-1代表互聯網標簽標記為“外賣” 或 “中介”或 “廣告” 或 “購物”的號碼,label1-2代表第三方數據標記為關停或加黑的號碼。
黑白名單劃分邏輯如下:白名單(0)代表label0-1號碼 + 聯系人數小于20的非label1號碼,黑名單(1)代表label1-1 號碼+ label1-2號碼,灰名單(2)代表label2-1號碼。
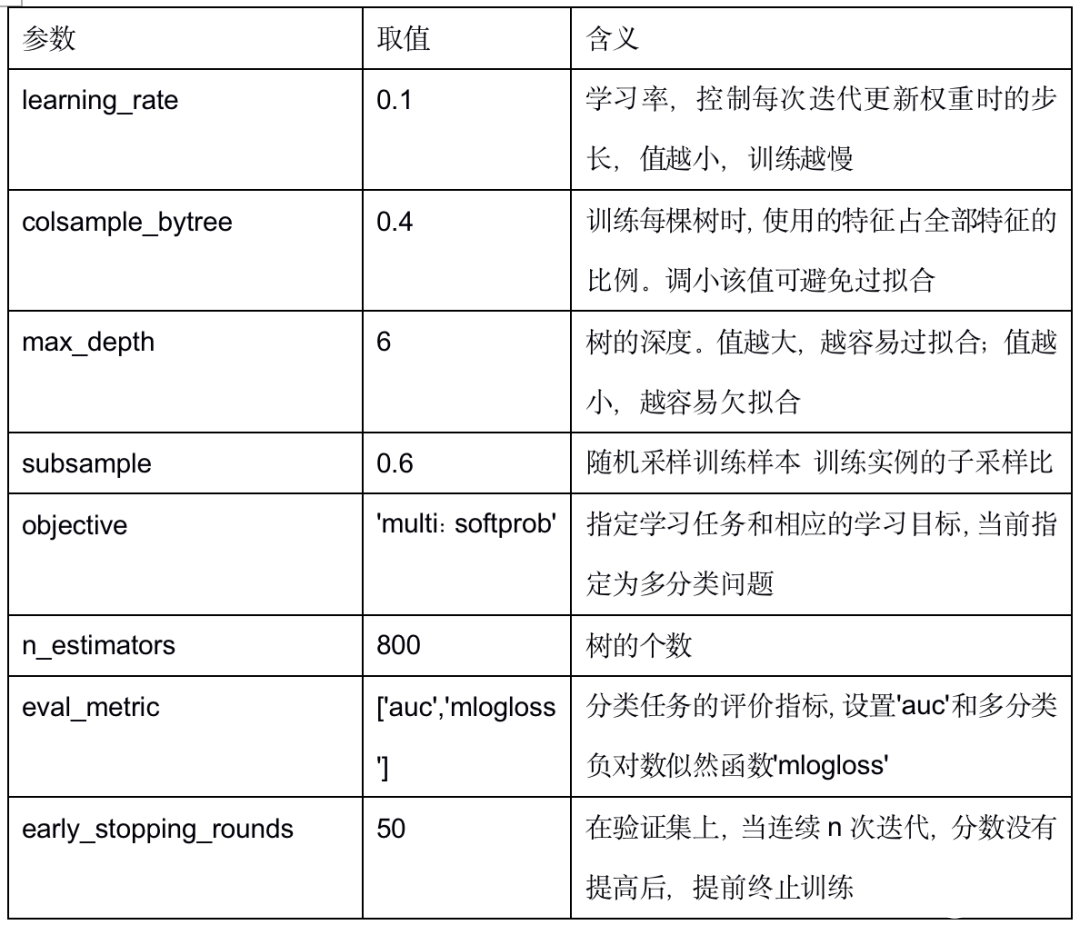
本次XGBoost調整的參數如表3所示,其它參數采用模型默認取值,不做調整。
表3 三分類參數設置
獲取結果集中的類型3和類型4,與三分類模型輸出結果合并為結果集2。
3.1.5 基于事件鏈的詐騙電話識別模型
對于活躍期短或新出現的詐騙電話難以識別。根據圖3所示通信信息詐騙場景圖,一般單獨一次通話無法完成整個詐騙流程,而多是由詐騙團伙成員各有分工,通過多次通話獲得受害人信任,從而完成詐騙。
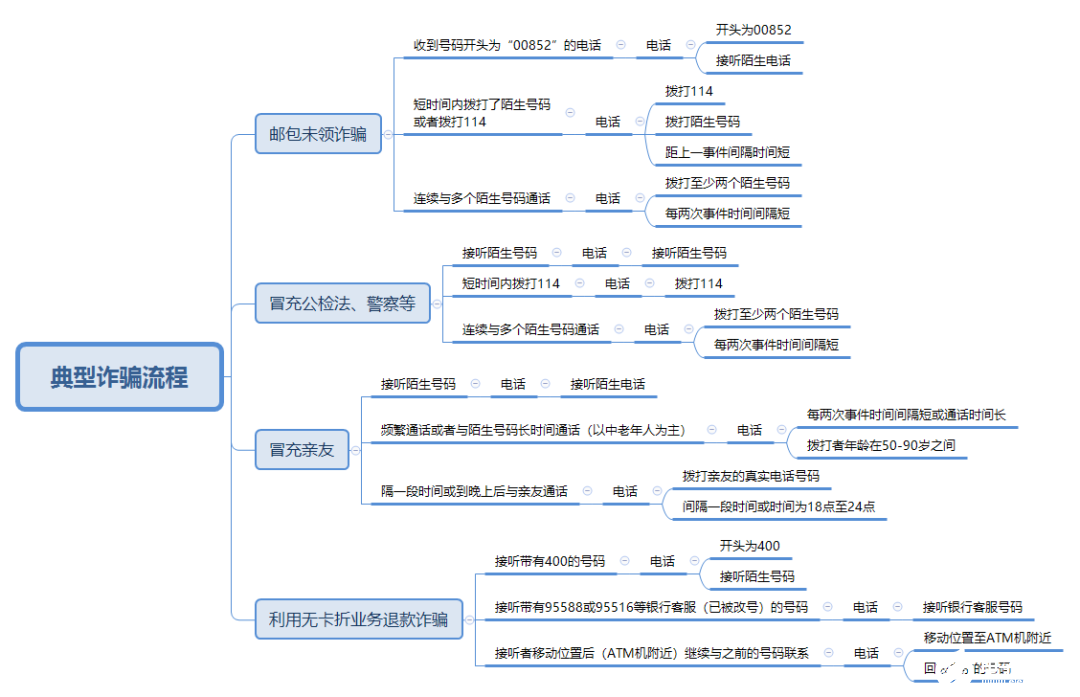
圖3 通信信息詐騙場景
從用戶角度而言,大部分用戶接到詐騙電話后可短時間內識別,不會有后續通話行為。而無法短時間內識別詐騙電話的用戶,則會與詐騙號碼及其他號碼有交互行為,且通話時間較長。因此可從用戶異常主叫行為角度入手,通話挖掘用戶異常通話行為,定位疑似詐騙電話,再通過詐騙電話識別規則,對詐騙電話進行精準識別。用戶異常行為主要有以下幾種。
(1)多個用戶短時間內接到了一組陌生電話。
(2)用戶在接到某陌生電話后,短期內發生主叫行為,且對象為公共電話。
(3)多個用戶在接到某陌生電話后,短期內發生主叫行為,且主叫對象為同一陌生電話。
其中公共電話指110、114和95550等客服電話。陌生號碼指30天內未曾與該用戶有過通話行為的號碼,且排除上述公共電話。
當發生上述異常行為時,記錄下陌生電話,并標記為疑似詐騙電話。通過查詢疑似詐騙電話的信令、BOSS數據,匹配該疑似詐騙電話的通話行為和消費行為等,如表4所示。
表4 事件鏈模型輸入特征

詐騙電話和廣告推銷等非詐騙電話,均具有主叫高頻、外地聯系人占比高和通話時長長尾型分布等特點。為進一步精確判定詐騙電話,引入離群點檢測方法進行精準識別。
由于對于疑似詐騙電話樣本,難以獲得其是否為真正詐騙的標簽,因此采用無監督學習方法中的離群點檢測技術,找到疑似詐騙電話中的異常點,作為詐騙電話。將疑似詐騙電話樣本集視為X,通過引入基于相對密度概念技術,將離群的得分較高前N個號碼視為詐騙電話,詐騙電話識別規則的具體算法步驟如下。

通過事件鏈模型得出疑似詐騙/騷擾電話結果集3,與疑似詐騙/騷擾電話結果集2進行合并去重得到最后的結果集4。
3.2 受害程度判定規則模塊
該利用用戶與詐騙電話通話情況,對受害程度進行分級。
對于上述已被識別規則判定為詐騙電話的號碼,對被詐騙電話呼叫過的用戶進行細分。由于用戶對詐騙電話的識別能力具有差異性,部分用戶在可以立即判斷并掛掉,此類情況受騙可能性較小。而部分用戶會在接到詐騙電話后,呼叫親友、114等號碼進行確認,也存在部分用戶一天內被多次騷擾的情況,因此需要對多種受害人后續行為場景進行分級,如受害程度判定規則模塊所示。
受害人發起主叫的對象分為親密人、詐騙電話、公共電話和陌生號碼4類。
(1)親密人指在若干天通話記錄中,符合親密人判定規則的聯系人。其中親密人判定規則是指同一歸屬地,且30內與受害人通話不少于5次的號碼。受害人接到詐騙電話后,若撥給自己的親密人,則認為其在一定程度上相信了詐騙電話,需再次向親友核實,故將其放入2級深度受害人數據庫。
(2)詐騙電話指已被識別規則判別為詐騙電話的號碼。受害人接到詐騙電話后,犯罪分子往往會要求受害人撥給一個新號碼,該號碼多為詐騙同伙,則認為受害人在已完全相信了詐騙電話,故將其放入3級深度受害人數據庫。
(3)公共電話指110、114和95550等客服電話。受害人接到詐騙電話后,若及時識別并向110、95550等官方電話進行核實或求助,則認為其收到詐騙可能性較小,故將其放入1級深度受害人數據庫。
(4)陌生號碼指除了親密人、詐騙電話和公共電話之外的號碼,可能是聯系不頻繁的親密人或未標記的詐騙電話,存在一定被騙可能,故將其放入2級深度受害人數據庫。
若受害人在接到騷擾電話后未發起主叫,則考察該受害人是否被頻繁騷擾,若在此記錄前已被多次騷擾,則將其放入2級深度受害人數據庫。若為初次騷擾,則將其放入1級深度受害人數據庫。
在符合深度受害人定義前提下,再對受害人進行細分,并給出1/2/3級深度受害人的定義。
1級深度受害人:與詐騙騷擾電話通話時長較短,且受害人未發起主叫也未被多次騷擾。或受害人發起主叫,主叫對象為110、95550等公共電話,能夠及時中止詐騙。
2級深度受害人:與詐騙騷擾電話通話時長較短,且受害人主叫對象為親密聯系人或陌生電話,存在被騙可能。或受害人在短期內遭到了陌生電話的多次騷擾。
3級深度受害人:與詐騙騷擾電話通話時長較長,超過10min。或受害人在接到詐騙電話后,主動撥給了另一個詐騙電話,被騙可能性很大。
從運營商角度,模擬受害人的受騙心理,從而能夠從源頭上對電信詐騙受害人進行鎖定和監控,為了對用戶進行有針對性的電信詐騙防護,引入如下易感人群畫像和分類模塊。
3.3 易感人群識別模塊
該模型根據用戶通話和消費行為,對易感人群進行畫像和分類。將詐騙電話識別模塊已有的詐騙號碼數據,將該類詐騙號碼聯系過的用戶進行聚合,得出所有被叫用戶的通話類型,將受害人識別模塊和受害程度判定模塊獲得的1/2/3級受害人,分別標記為1/2/3級易感人群,而沒有遭受任何詐騙電話侵害的用戶標記為潛在易感人群。具體輸入變量和輸出目標類型如表5所示。
表5 易感人群識別模塊輸入變量和輸出目標類型

基于上述1/2/3類深度受害人和潛在受害人的社交信息、行為信息特征數據,及4類易感人群類別,作為樣本數據集合,利用機器學習中的kNN算法,獲得易感程度分級規則。當輸入沒有標簽的新用戶數據后,將新數據的每個特征值與樣本集中數據對應的特征值進行比較,然后算法提取樣本集中特征最相似的數據的分類標簽,具體實現步驟如下。
步驟1:把兩組已知的打好標簽的用戶數據放到Hadoop的HDFS上,分別作為訓練數據和測試數據。數據的表示形式如下:A用戶可以表示成(xA0, xA1, ……xA10),B用戶可以表示成(xB0, xB1, ……xB10),其中xA0表示用戶A聯系人數,xA1表示外地聯系人個數,以此類推。
步驟2:通過Map函數計算測試數據的節點到訓練樣本節點之間的距離,其中距離計算方法采用上述Mahalanobis距離公式。按照距離遞增次序排序,排序的結果作為Map的輸出結果作為Reduce函數的輸入量。
步驟3:在Reduce函數中,選取與當前節點距離最小的k個點 ,并確定前k個點所在類別的出現頻率,最終返回前k個點出現頻率最高的類別作為當前點的預測分類。
步驟4:計算測試數據中kNN算法的錯誤率,通過調節k的大小來對分類器進行調優。
步驟5:對于新的用戶數據,首先計算其特征值,然后按照步驟2和3,返回易感人群分級類別。
4 結束語
本文設計了一種對通信信息詐騙行為進行識別和對深度受害人進行防控雙重防護的方法。該方法結合可獲知的可疑樣本采用機器學習算法來識別詐騙電話,同時能夠根據用戶與陌生電話的通話行為,匹配異常通話行為模式,并根據疑似詐騙號碼匹配出更多潛在受害人,及時介入并對用戶進行提示告警。最后從用戶角度,對通信信息詐騙易感程度進行分級。
為了能夠更有效地使用論文中的方法來防止5G電話詐騙,下一步需要不斷提升本方法識別精度和識別的覆蓋能力,以及應對5G電話詐騙新衍生場景的能力。
責任編輯:gt















 工商網監
工商網監
評論