 電子發燒友App
電子發燒友App


RDMA(遠程直接數據存取),以其對業務帶來的高性能、低延時優勢,在數據中心尤其是AI、HPC、大數據等場景得到了廣泛應用。為保障RDMA的穩定運行,基礎網絡需要提供端到端無損零丟包及超低延時的能力,這也催生了PFC、ECN等網絡流控技術在RDMA網絡中的部署。在RDMA網絡中,如何合理設置MMU(緩存管理單元)水線是保證RDMA網絡無損和低延時的關鍵。本文將以RDMA網絡作為切入點,結合實際部署經驗,分析MMU水線設置的一些思路。
什么是RDMA?
RDMA(Remote Direct Memory Access),通俗的說就是遠程的DMA技術,是為了解決網絡傳輸中服務器端數據處理的延遲而產生的。
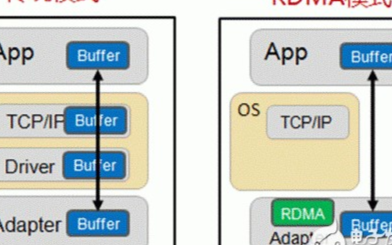
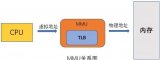
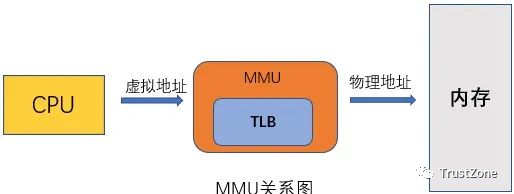
▲ 傳統模式與RDMA模式工作機制對比
如上圖,在傳統模式下,兩臺服務器上的應用之間傳輸數據,過程是這樣的:
● 首先要把數據從應用緩存拷貝到Kernel中的TCP協議棧緩存;
● 然后再拷貝到驅動層;
● 最后拷貝到網卡緩存。
多次內存拷貝需要CPU多次介入,導致處理延時大,達到數十微秒。同時整個過程中CPU過多參與,大量消耗CPU性能,影響正常的數據計算。
在RDMA 模式下,應用數據可以繞過Kernel協議棧直接向網卡寫數據,帶來的顯著好處有:
● 處理延時由數十微秒降低到1微秒內;
● 整個過程幾乎不需要CPU參與,節省性能;
● 傳輸帶寬更高。
RDMA對于網絡的訴求
RDMA在高性能計算、大數據分析、IO高并發等場景中應用越來越廣泛。諸如iSICI, SAN, Ceph, MPI, Hadoop, Spark, Tensorflow等應用軟件都開始部署RDMA技術。而對于支撐端到端傳輸的基礎網絡而言,低延時(微秒級)、無損(lossless)則是最重要的指標。
低延時
網絡轉發延時主要產生在設備節點(這里忽略了光電傳輸延時和數據串行延時),設備轉發延時包括以下三部分:
● 存儲轉發延時:芯片轉發流水線處理延遲,每個hop會產生1微秒左右的芯片處理延時(業界也有嘗試使用cut-through模式,單跳延遲可以降低到0.3微秒左右);
● Buffer緩存延時:當網絡擁塞時,報文會被緩存起來等待轉發。這時Buffer越大,緩存報文的時間就越長,產生的時延也會更高。對于RDMA網絡,Buffer并不是越大越好,需要合理選擇;
● 重傳延時:在RDMA網絡里會有其他技術保證不丟包,這部分不做分析。
無損
RDMA在無損狀態下可以滿速率傳輸,而一旦發生丟包重傳,性能會急劇下降。在傳統網絡模式下,要想實現不丟包最主要的手段就是依賴大緩存,但如前文所說,這又與低延時矛盾了。因此,在RDMA網絡環境中,需要實現的是較小Buffer下的不丟包。
在這個限制條件下,RDMA實現無損主要是依賴基于PFC和ECN的網絡流控技術。
PFC
PFC(Priority-based Flow Control),基于優先級的流量控制。是一種基于隊列的反壓機制,通過發送Pause幀通知上游設備暫停發包來防止緩存溢出丟包。
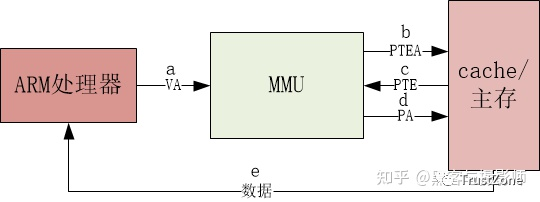
▲ PFC工作機制示意圖
PFC允許單獨暫停和重啟其中任意一條虛擬通道,同時不影響其它虛擬通道的流量。如上圖所示,當隊列7的Buffer消耗達到設置的PFC流控水線,會觸發PFC的反壓:
● 本端交換機觸發發出PFC Pause幀,并反向發送給上游設備;
● 收到Pause幀的上游設備會暫停該隊列報文的發送,同時將報文緩存在Buffer中;
● 如果上游設備的Buffer也達到閾值,會繼續觸發Pause幀向上游反壓;
● 最終通過降低該優先級隊列的發送速率來避免數據丟包;
● 當Buffer占用降低到恢復水線時,會發送PFC解除報文。
RDMA無損網絡的關鍵技術:ECN
ECN(Explicit Congestion Notification):顯示擁塞通知。ECN是一個非常古老的技術,只是之前使用的并不普遍,該協議機制作用于主機與主機之間。
ECN是報文在網絡設備出口(Egress port)發生擁塞并觸發ECN水線時,使用IP報文頭的ECN字段標記數據包,表明該報文遇到網絡擁塞。一旦接收服務器發現報文的ECN被標記,立刻產生CNP(擁塞通知報文),并將它發送給源端服務器,CNP消息里包含了導致擁塞的Flow信息。源端服務器收到后,通過降低相應流發送速率,緩解網絡設備擁塞,從而避免發生丟包。
通過之前的描述可以了解到,PFC和ECN之所以可以實現網絡端到端的零丟包,是通過設置不同的水線來實現的。對這些水線的合理設置,就是針對交換機MMU的精細化管理,通俗講就是對交換機Buffer的管理。接下來我們具體分析下PFC的水線設置。
PFC水線設置
交換芯片都有固定的Pipeline(轉發流水線), Buffer管理處于入芯片流程和出芯片流程的中間位置。報文處于在這個位置上時,已經知道了該報文的入口和出口信息,因此邏輯上就可以分成入方向和出方向分別對緩存進行管理。
PFC水線是基于入方向緩存管理進行觸發的。芯片在入口方向提供了8個隊列,我們可以將不同優先級的業務報文映射到不同的隊列上,從而實現對不同優先級的報文提供不同的Buffer分配方案。
▲ 隊列Buffer的組成部分
具體到每個隊列,其Buffer分配根據使用場景設計為3部分:保證緩存,共享緩存,Headroom。
● 保證緩存:每個隊列的專用緩存,確保每個隊列均有一定緩存以保證基本轉發;
● 共享緩存:流量突發時可以申請使用的緩存,所有隊列共享;
● Headroom:在觸發PFC水線后,到服務器響應降速前,還可以繼續使用的緩存。
保證緩存設置
保證緩存是一個靜態水線(固定的、獨享的)。靜態水線的利用率非常低,資源消耗卻非常大。我們在實際部署時建議不分配保證緩存,以減少這部分的緩存消耗。這樣,入方向報文直接使用共享緩存空間,可提高Buffer的利用率。
共享緩存設置
對于共享緩存的設置,需要采用更為靈活的動態水線。動態水線能根據當前空閑的Buffer資源,以及當前隊列已使用的Buffer資源數量來決定能否繼續申請到資源。由于系統中空閑共享Buffer資源與已使用的Buffer資源都是時刻變化的,因此閾值也處于不斷變動中。相對于靜態水線,動態水線能更靈活、有效的利用Buffer及避免造成不必要的浪費。
銳捷網絡交換機支持基于動態的方式進行Buffer資源的分配,對共享緩存的設置分為11檔,動態水線alpha值=隊列可申請緩存量/剩余共享緩存量。隊列的α值越大,其在共享緩存中可使用的百分數占比也就越高。
▲共享水線α值與可使用率對應關系
我們不妨分析一下:
隊列的α值設置越小,其最大可申請的共享緩存占比就越小。當端口擁塞時就會越早觸發PFC流控,PFC流控生效后隊列降速,可以很好地保證網絡不丟包。
但從性能的角度看,過早觸發PFC流控,會導致RDMA網絡吞吐下降。因此我們在MMU水線設置時需要選取一個平衡值。
PFC水線到底設置多少,是一個非常復雜的問題,理論上不存在一個固定的值。實際部署時,需要我們具體分析業務模型,并搭建測試環境進行水線調優,找到匹配業務的最佳水線。
Headroom設置
Headroom:顧名思義,就是頭部空間的意思,是在PFC觸發后,到PFC真正生效這一段時間,用來緩存隊列報文的。Headroom設置多大合適?這里與4個因素有關:
● PG檢測到觸發XOFF水線,到構造PFC幀發出的時間(這里主要跟配置的檢測精度以及平均隊列算法相關,固定配置是固定值)
● 上游收到PFC Pause幀,到停止隊列轉發的時間(主要跟芯片處理性能有關系,交換芯片實際上是固定值)
● PFC Pause幀在鏈路上的傳輸時間(跟AOC線纜/光纖距離成正比)
● 隊列暫停發送后鏈路中報文的傳輸時間(跟AOC線纜/光纖距離成正比)
因此Headroom所需要的緩存大小,我們可以根據組網的架構,以及流量模型測算得出。以100米光纖線 + 100G光模塊,緩存64字節小包,計算出所需的Headroom大小是408個cell(cell是緩存管理的最小單元,一個報文會占用1個或者多個cell),實際測試數據也吻合。當然,考慮一定的冗余性,Headroom設置建議比理論值稍大。
RDMA網絡實踐
銳捷網絡在研發中心搭建了模擬真實業務的RDMA網絡,架構如下:
▲銳捷網絡RDMA組網架構
● 組網模型:大核心三級組網架構,核心采用高密100G線卡;
● POD內:Spine采用提供64個100G接口的 BOX設備,Leaf采用提供48個25G接口+8個100G接口的BOX設備;
● Leaf作為服務器網關,支持和服務器間基于PFC流控(識別報文的DSCP并進行PG映射),同時支持擁塞ECN標記;
● RDMA僅運行于POD內部,不存在跨POD的RDMA流量,因此核心無需感知RDMA流量;
● 為了避免擁塞丟包,需要在Leaf與Spine之間部署PFC流控技術,同時Spine設備也需要支持基于擁塞的ECN標記;
● Leaf和Spine設備支持PFC流控幀統計、ECN標記統計、擁塞丟包統計、基于隊列的擁塞統計等,并支持將統計信息通過gRPC同步到遠端gRPC服務器。
寫在最后
銳捷網絡在研發中心同樣搭建了模擬真實業務的浸泡組網環境(包括RG-S6510、RG-S6520、RG-N18000-X系列25G/100G網絡設備、大型測試儀、25G服務器)。在疊加了多種業務模型,并進行了長時間浸泡測試后,我們對于RDMA網絡的MMU水線設置已有一些推薦的經驗值。此外,在RDMA網絡中,還存在一些部署難點,比如多級網絡中 PFC風暴、死鎖問題、ECN水線設計復雜問題等。對于這些問題,銳捷網絡也有一些研究和積累,期待與大家共同探討。
本期作者:顏曉波
銳捷網絡互聯網系統部行業咨詢
感謝您關注銳捷網絡技術干貨文章!現誠邀您參與有獎調研,您寶貴的意見和建議將幫助我們在技術探索與分享上持續精進。
點擊下方鏈接參與調研。
#












 工商網監
工商網監
評論