 電子發燒友App
電子發燒友App


編者按:保護隱私和保障安全的沖突,在多大程度上僅僅是一個技術限制?讓我們和DeepMind數據科學家、Udacity深度學習導師Andrew Trask一起,基于Paillier加密算法和詞袋邏輯回歸實現犯罪檢測。
TLDR:監控是否能夠只侵犯犯罪嫌疑人和恐怖分子的隱私,避免殃及無辜?本文用Python實現了一個原型。
摘要:現代的犯罪嫌疑人和恐怖分子藏身于無辜居民的模式之中,精確地鏡像無辜居民的日常生活,直到變得致命的最后一刻,比如一輛沖上人行道的汽車,或大街上掏出刀子的人。由于即時發生的致命事件不可能通過警力干預,執法部門轉而利用監控檢測犯罪事件,立法上的努力加速了這一轉向,例如愛國者法案、美國自由法案和英國的反恐法案。這些立法引起了激烈的爭議。在本文中,我們將探索隱私和安全的折衷在多大程度上僅僅是一個技術限制,一個可以通過同態加密和深度學習克服的技術限制。我們同時給出了一個原型實現,并討論了哪里可以追加技術投入,使這一技術更成熟。我很樂觀,覺得未來的犯罪檢測工具會比今天的更強大,在提供更高效的監控的同時,保護居民隱私。潛在的濫用可以通過加密人工智能這樣的現代技術緩解。
如果你對訓練加密神經網絡感興趣,可以看看OpenMined的PySyft庫。
一、理想的居民監控
國際機場常常使用緝毒犬檢測毒品。如果沒有緝毒犬,檢測乘客是否攜帶毒品需要打開每個箱包,檢查其中的物品,這是一個昂貴、費時、侵犯隱私的過程。然而,有了緝毒犬,需要搜查的箱包僅僅是那些確實包含毒品的箱包(在緝毒犬看來)。緝毒犬的應用同時增加了隱私和效率。
類似地,電子煙霧報警器和防盜報警器的應用取代了更低效、更侵犯隱私的昂貴系統:24x7站在房門口的保安或防火員。
這兩個場景幾乎不存在隱私和安全的折衷。這是監控的理想狀態。監控是有效的,而隱私得到了保護:
僅當很可能發現危險/犯罪活動時才侵犯隱私。
設備是精確的,假陽性率低。
可以訪問設備的人(陪同緝毒犬的警員和房產業主)并不試圖愚弄這些設備。因此,這些設備的工作機制可以公開,其對隱私的保護可以被大家知曉,并接受審計。
隱私保護、精確性、可審計性的結合是達到監控理想狀態的關鍵。這一點很直觀。只有不到0.001%的飛機乘客會攜帶毒品的情況下,為什么每個包都要打開,每個乘客的隱私都要被侵犯?既然99.999%的時間既沒有發生火災,也沒有發生入室盜竊,為什么要讓保安監看業主家中的監控視頻?
二、國家安全監控
在我寫作本文的兩周內,僅僅在曼徹斯特、倫敦、埃及、阿富汗就有超過50人死于恐怖襲擊。我為遇難者和他們的家庭祈禱,我極其希望我們能夠找到更好的保障人們安全的方式。對最近在威斯敏斯特發生的恐怖襲擊的調查顯示,恐怖分子通過Whatsapp交換信息。這引起了一場關于隱私和安全的折衷的激烈爭論。政府希望在Whatsapp一類的應用中置入后門(包括無限制的讀取權限),但很多人不信任老大哥保護WhatsApp用戶隱私的自律能力。另外,置入后門也讓這些應用容易受到攻擊,進一步增加了公眾的風險。
恐怖主義也許是隱私和安全的折衷中討論最多的領域,它并不是唯一被討論的領域。謀殺之類的犯罪奪去了世界上成千上萬人的生命。僅僅在美國,每年就有大約16000起謀殺。
“相當理由”的雞和蛋問題?FBI和當地執法部門面對的挑戰和恐怖主義極其相似。保護公民隱私的法律導致了一個雞和蛋問題,發現“相當理由”(接著獲取搜查令)和得以訪問取得“相當理由”的信息。而在緝毒犬和煙霧報警器這樣的情形中,這不再是一個問題,因為犯罪可以在不對隱私造成顯著附加傷害的前提下被檢測出來,因此“相當理由”不再是限制保障公共安全的因素。
三、人工智能的角色
在理想世界中,會有一個針對謀殺、恐怖襲擊等不可逆的嚴重犯罪的“火警”設備,該設備能夠保護隱私、精確、可審計。幸運的是,商業實體對這類檢測設備的研發投入巨大。這些投入并不是由保護消費者隱私驅動的。相反,這些設備的研發是為了實現大規模檢測。考慮一下Gmail的研發,Gmail想要提供垃圾郵件過濾功能。你可以侵犯人們的隱私,人工讀取他們的郵件,但創建一個可以檢測垃圾郵件的機器更快、更便宜。由于執法部門想要保護廣大人口,不難想見這一過程是高度自動化的。所以,基于這一假設,我們真正欠缺的是轉換AI智能體滿足如下條件的能力:
可供受信任方審計其隱私保護
部署后無法被逆向工程
被監控者無法知道預測
部署方無法篡改預測(比如聊天軟件)
高效、可伸縮
為了完整地說明這一概念,我們將創建一個原型。在下一節,我們將使用雙層神經網絡創建一個檢測器的基礎版本。之后,我們將升級這一檢測器,使其滿足上面列出的要求。這個檢測器將在垃圾郵件數據庫上進行訓練,因此將只能檢測垃圾郵件。不過,可以想像,經過訓練,它可以檢測你想要檢測的任何特定事件(例如,謀殺、縱火,等等)。我選擇垃圾郵件的原因是因為這相對容易訓練,便于我演示這一方法。
四、創建垃圾郵件檢測器
所以,我們的示范案例將是一位當地的執法部門官員(讓我們叫他“Bob”)希望打擊發送垃圾郵件這一犯罪行為。然而,Bob并不打算親自閱讀每個人的郵件,相反,Bob希望檢測發送垃圾郵件這一行為,這樣他就可以申請禁制令和搜查令,并進行進一步調查。這一過程的第一部分是創建一個有效的垃圾郵件檢測器。
Enron Spam Dataset?我們需要大量標記為“垃圾郵件”和“非垃圾郵件”的郵件讓算法學習區分兩種不同的郵件。幸運的是,一家知名的能源公司安然犯下了一些罪行,這些罪行被記錄在郵件中,因此,這家公司相當多的郵件被公開了。由于其中許多郵件是垃圾郵件,因此人們基于這些公開郵件構建了一個Enron Spam Dataset(安然垃圾郵件數據集)。我對這一數據集進行了預處理,生成了兩個文件:
ham.txt 非垃圾郵件,共22032封。
spam.txt 垃圾郵件,共9000封。
文件的每行是一封郵件。我們將留置每個類別中的最后1000封郵件作為測試數據集,其余郵件用作訓練數據集。
模型?我們將使用一個能夠快速訓練的簡單模型,詞袋邏輯分類器(bag-of-words Logistic Classifier)。這是一個雙層的神經網絡(輸入層和輸出層)。我們本可以使用更復雜的模型,比如LSTM,但本文的主題不是過濾垃圾郵件,另外,詞袋LR在垃圾郵件檢測上效果非常好(令人驚訝的是,它在其他許多任務上同樣表現出色)。所以不用過度復雜化。下面是創建這一分類器的代碼。如果你吃不準它是如何工作的,可以參考我之前的文章基于Numpy實現神經網絡:反向傳播。
(在我的機器上,以下代碼在Python 2和Python 3上均能運行。)
import numpy as np
from collections importCounter
import random
import sys
np.random.seed(12345)
f = open('spam.txt','r')
raw = f.readlines()
f.close()
spam = list()
for row in raw:
spam.append(row[:-2].split(" "))
f = open('ham.txt','r')
raw = f.readlines()
f.close()
ham = list()
for row in raw:
ham.append(row[:-2].split(" "))
classLogisticRegression(object):
def __init__(self, positives,negatives,iterations=10,alpha=0.1):
# 創建詞匯表 (真實世界的案例將增加幾百萬其他詞匯
# 以及從網絡上抓取的其他詞匯)
cnts = Counter()
for email in (positives+negatives):
for word in email:
cnts[word] += 1
# 轉換為查找表
vocab = list(cnts.keys())
self.word2index = {}
for i,word in enumerate(vocab):
self.word2index[word] = i
# 初始化未加密權重
self.weights = (np.random.rand(len(vocab)) - 0.5) * 0.1
# 在未加密信息上訓練模型
self.train(positives,negatives,iterations=iterations,alpha=alpha)
def train(self,positives,negatives,iterations=10,alpha=0.1):
for iter in range(iterations):
error = 0
n = 0
for i in range(max(len(positives),len(negatives))):
error += np.abs(self.learn(positives[i % len(positives)],1,alpha))
error += np.abs(self.learn(negatives[i % len(negatives)],0,alpha))
n += 2
print("Iter:" + str(iter) + " Loss:" + str(error / float(n)))
def softmax(self,x):
return1/(1+np.exp(-x))
def predict(self,email):
pred = 0
for word in email:
pred += self.weights[self.word2index[word]]
pred = self.softmax(pred)
return pred
def learn(self,email,target,alpha):
pred = self.predict(email)
delta = (pred - target)# * pred * (1 - pred)
for word in email:
self.weights[self.word2index[word]] -= delta * alpha
return delta
model = LogisticRegression(spam[0:-1000],ham[0:-1000],iterations=3)
# 在留置集上評估
fp = 0
tn = 0
tp = 0
fn = 0
for i,h in enumerate(ham[-1000:]):
pred = model.predict(h)
if(pred < 0.5):
tn += 1
else:
fp += 1
if(i % 10 == 0):
sys.stdout.write(' I:'+str(tn+tp+fn+fp) + " % Correct:" + str(100*tn/float(tn+fp))[0:6])
for i,h in enumerate(spam[-1000:]):
pred = model.predict(h)
if(pred >= 0.5):
tp += 1
else:
fn += 1
if(i % 10 == 0):
sys.stdout.write(' I:'+str(tn+tp+fn+fp) + " % Correct:" + str(100*(tn+tp)/float(tn+tp+fn+fp))[0:6])
sys.stdout.write(' I:'+str(tn+tp+fn+fp) + " Correct: %" + str(100*(tn+tp)/float(tn+tp+fn+fp))[0:6])
print(" Test Accuracy: %" + str(100*(tn+tp)/float(tn+tp+fn+fp))[0:6])
print("False Positives: %" + str(100*fp/float(tp+fp))[0:4] + " ? ?<- privacy violation level out of 100.0%")
print("False Negatives: %" + str(100*fn/float(tn+fn))[0:4] + " ? <- security risk level out of 100.0%")
結果:
Iter:0Loss:0.0455724486216
Iter:1Loss:0.0173317643148
Iter:2Loss:0.0113520767678
I:2000Correct: %99.798
TestAccuracy: %99.7
FalsePositives: %0.3 ? ?<- privacy violation level out of 100.0%
FalseNegatives: %0.3 ? <- security risk level out of 100.0%
特性:可審計性?這個分類器有一個很棒的特性,它是一個具有高可審計性的算法。它不僅給出了測試數據上的精確評分,我們還能打開它,看看它給不同詞匯的權重有何不同,以確保它基于Bob長官所需標記垃圾郵件。基于這些洞見,Bob長官可以從他的上級那里得到對轄區內的客戶端進行極為有限的監控的許可。注意,Bob無法閱讀任何人的郵件,他僅僅可以檢測他需要檢測的目標。
好,我們的分類器得到了Bob的上級(警長?)的批準。大致上,Bob將在轄區內的所有郵件客戶端上加上這一分類器。每個客戶端在發送郵件前會使用分類器作出預測。預測將發送給Bob,漸漸地,Bob將找出在自己的轄區內每天匿名發送10000封垃圾郵件的人。
問題一:預測可以偽造?過了一周以后,每個人仍然收到成噸的垃圾郵件。而Bob的分類器看起來不能標記任何垃圾郵件,盡管在Bob自己的機器上測試時可以正常工作。Bob懷疑有人攔截了算法的預測,讓垃圾郵件看起來都是“陰性”。他應該怎么做?
問題二:模型可以被逆向工程?此外,Bob注意到他可以從預訓練的模型中得到權重值:
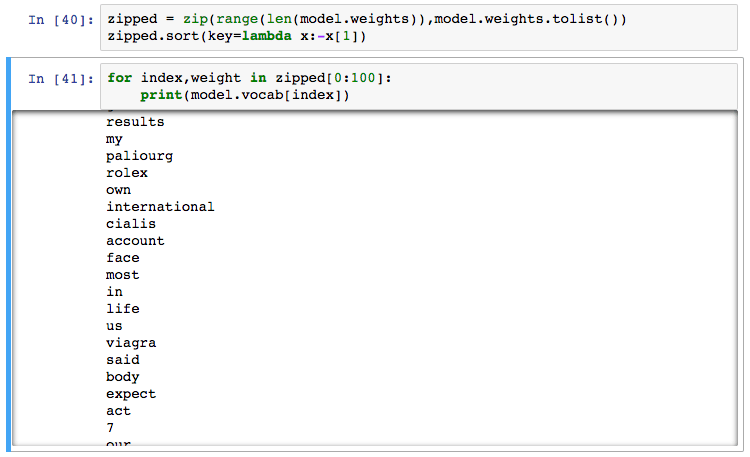
盡管從可審計的角度來說,這是一個優勢(讓Bob的上級確信模型將僅僅找出設計目的所需的信息),這很容易被攻擊!人們不僅可以攔截和修改模型的預測,甚至還可以逆向工程系統找出需要避免哪些單詞。換句話說,模型的能力和預測易受攻擊。Bob需要一道額外的防線。
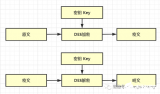
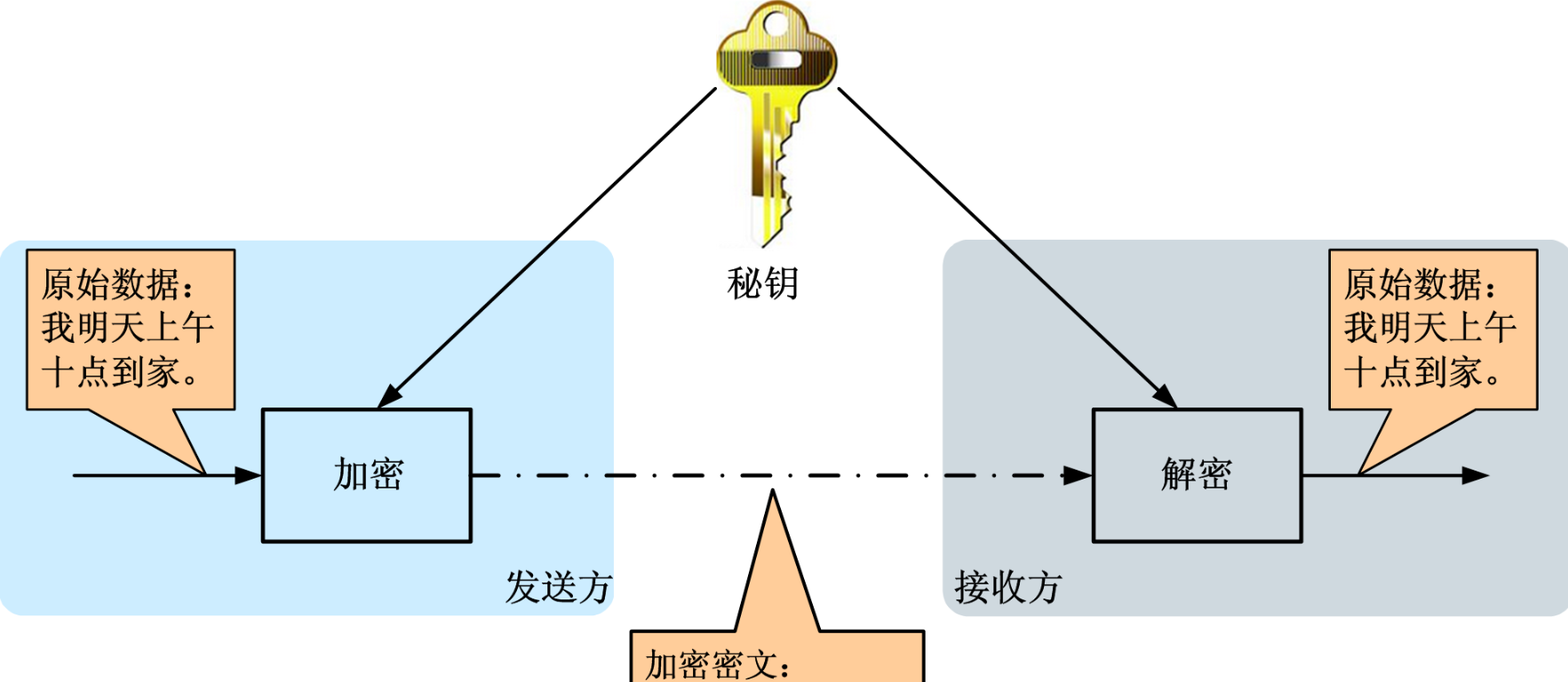
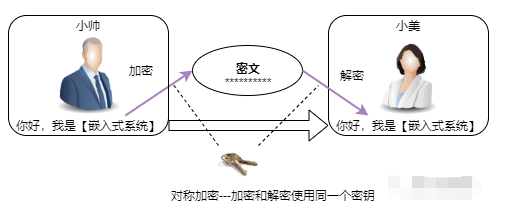
五、同態加密
在之前的文章中,我概述了如何使用同態加密以加密狀態訓練神經網絡(訓練數據未加密),算法實現基于高效整數向量同態加密。不過,之前的文章提到,有很多同態加密方案可供選擇。本文將使用一個不同的方案,Paillier加密。我更新了Paillier加密的Python庫,加入了處理long類型的密文和明文的功能,并修改了一處日志功能的bug.
你可以通過以下命令安裝我修改的Paillier庫:
git clone https://github.com/iamtrask/python-paillier.git
cd python-paillier
python setup.py install
接著運行以下代碼:
import phe as paillier
pubkey, prikey = paillier.generate_paillier_keypair(n_length=64)
a = pubkey.encrypt(123)
b = pubkey.encrypt(-1)
prikey.decrypt(a) # 123L
prikey.decrypt(b) # -1L
prikey.decrypt(a + a) # 246
prikey.decrypt(a + b) # 122
如你所見,我們可以使用公鑰加密(正或負)數,接著將加密值相加,然后解密所得結果。我們使用這些操作就可以加密我們的訓練后的邏輯回歸分類器。如果想了解這些是如何工作的,請參考我上一篇文章。
import phe as paillier
import math
import numpy as np
from collections importCounter
import random
import sys
np.random.seed(12345)
print("Generating paillier keypair")
pubkey, prikey = paillier.generate_paillier_keypair(n_length=64)
print("Importing dataset from disk...")
f = open('spam.txt','r')
raw = f.readlines()
f.close()
spam = list()
for row in raw:
spam.append(row[:-2].split(" "))
f = open('ham.txt','r')
raw = f.readlines()
f.close()
ham = list()
for row in raw:
ham.append(row[:-2].split(" "))
classHomomorphicLogisticRegression(object):
def __init__(self, positives,negatives,iterations=10,alpha=0.1):
self.encrypted=False
self.maxweight=10
# 創建詞匯表 (真實世界的案例將增加幾百萬其他詞匯
# 以及從網絡上抓取的其他詞匯)
cnts = Counter()
for email in (positives+negatives):
for word in email:
cnts[word] += 1
# 轉換為查找表
vocab = list(cnts.keys())
self.word2index = {}
for i,word in enumerate(vocab):
self.word2index[word] = i
# 初始化未加密權重
self.weights = (np.random.rand(len(vocab)) - 0.5) * 0.1
# 在未加密信息上訓練模型
self.train(positives,negatives,iterations=iterations,alpha=alpha)
def train(self,positives,negatives,iterations=10,alpha=0.1):
for iter in range(iterations):
error = 0
n = 0
for i in range(max(len(positives),len(negatives))):
error += np.abs(self.learn(positives[i % len(positives)],1,alpha))
error += np.abs(self.learn(negatives[i % len(negatives)],0,alpha))
n += 2
print("Iter:" + str(iter) + " Loss:" + str(error / float(n)))
def softmax(self,x):
return1/(1+np.exp(-x))
def encrypt(self,pubkey,scaling_factor=1000):
if(not self.encrypted):
self.pubkey = pubkey
self.scaling_factor = float(scaling_factor)
self.encrypted_weights = list()
for weight in model.weights:
self.encrypted_weights.append(self.pubkey.encrypt(\
int(min(weight,self.maxweight) * self.scaling_factor)))
self.encrypted = True ? ? ? ? ? ?
self.weights = None
return self
def predict(self,email):
if(self.encrypted):
return self.encrypted_predict(email)
else:
return self.unencrypted_predict(email)
def encrypted_predict(self,email):
pred = self.pubkey.encrypt(0)
for word in email:
pred += self.encrypted_weights[self.word2index[word]]
return pred
def unencrypted_predict(self,email):
pred = 0
for word in email:
pred += self.weights[self.word2index[word]]
pred = self.softmax(pred)
return pred
def learn(self,email,target,alpha):
pred = self.predict(email)
delta = (pred - target)# * pred * (1 - pred)
for word in email:
self.weights[self.word2index[word]] -= delta * alpha
return delta
model = HomomorphicLogisticRegression(spam[0:-1000],ham[0:-1000],iterations=10)
encrypted_model = model.encrypt(pubkey)
# 生成加密預測。接著解密它們,并進行評估。
fp = 0
tn = 0
tp = 0
fn = 0
for i,h in enumerate(ham[-1000:]):
encrypted_pred = encrypted_model.predict(h)
try:
pred = prikey.decrypt(encrypted_pred) / encrypted_model.scaling_factor
if(pred < 0):
tn += 1
else:
fp += 1
except:
print("overflow")
if(i % 10 == 0):
sys.stdout.write(' I:'+str(tn+tp+fn+fp) + " % Correct:" + str(100*tn/float(tn+fp))[0:6])
for i,h in enumerate(spam[-1000:]):
encrypted_pred = encrypted_model.predict(h)
try:
pred = prikey.decrypt(encrypted_pred) / encrypted_model.scaling_factor
if(pred > 0):
tp += 1
else:
fn += 1
except:
print("overflow")
if(i % 10 == 0):
sys.stdout.write(' I:'+str(tn+tp+fn+fp) + " % Correct:" + str(100*(tn+tp)/float(tn+tp+fn+fp))[0:6])
sys.stdout.write(' I:'+str(tn+tp+fn+fp) + " % Correct:" + str(100*(tn+tp)/float(tn+tp+fn+fp))[0:6])
print(" Encrypted Accuracy: %" + str(100*(tn+tp)/float(tn+tp+fn+fp))[0:6])
print("False Positives: %" + str(100*fp/float(tp+fp))[0:4] + " ? ?<- privacy violation level")
print("False Negatives: %" + str(100*fn/float(tn+fn))[0:4] + " ? <- security risk level")
輸出:
Generating paillier keypair
Importing dataset from disk...
Iter:0Loss:0.0455724486216
Iter:1Loss:0.0173317643148
Iter:2Loss:0.0113520767678
Iter:3Loss:0.00455875940625
Iter:4Loss:0.00178564065045
Iter:5Loss:0.000854385076612
Iter:6Loss:0.000417669805378
Iter:7Loss:0.000298985174998
Iter:8Loss:0.000244521525096
Iter:9Loss:0.000211014087681
I:2000 % Correct:99.296
EncryptedAccuracy: %99.2
FalsePositives: %0.0 ? ?<- privacy violation level
FalseNegatives: %1.57 ? <- security risk level
這個模型相當特別(而且很快!……在我的筆記本上,單線程運行,每秒可以處理大約1000封郵件)。注意我們在預測時沒有使用sigmoid(僅在訓練時使用了sigmoid),因為其后的閾值為0.5. 因此,測試時我們可以簡單地跳過sigmoid,并將之后的閾值設為0. 好了,已經談了夠多技術方面的內容了,讓我們回到Bob那里。
Bob之前遇到的問題是人們可以看到預測并偽造預測。然而,現在所有預測都是加密的。

此外,Bob之前還遇到人們讀取權重并逆向工程的問題。然而,現在所有權重也是加密的(并且可以在加密狀態下預測)!
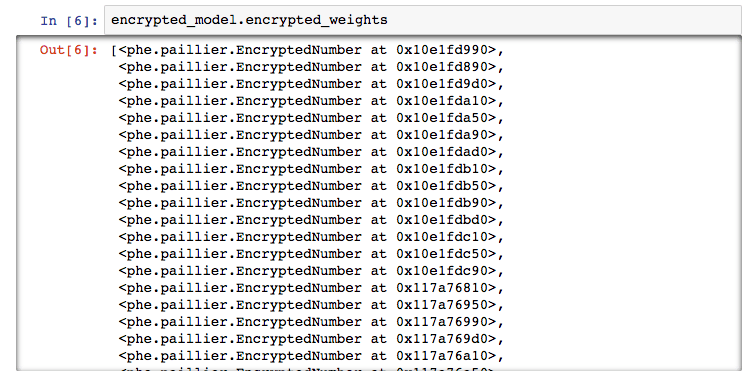
這一模型具有很多我們想要的性質。它可以被第三方審計,預測是加密的,對于想要竊取/愚弄這一系統的人來說,它的智能也是加密的。除此之外,它相當精確(測試數據集上沒有假陽性結果),也很快。
六、創建安全犯罪檢測
讓我們考慮下這樣的模型對執法部門來說意味著什么。今時今日,為了預測謀殺和恐怖襲擊之類的事件,執法部門需要不受限制地訪問數據流。因此,為了檢測在數據中有0.0001%的可能性發生的事件,執法部門需要訪問100%的數據,將這些數據轉到一個秘密的數據倉庫,(我假定)數據倉庫中部署了機器學習模型。
然而,這些現在用來識別犯罪的機器學習模型其實可以加密自身,并部署在數據流上(例如,聊天應用)。執法部門僅僅訪問模型的預測,而不是訪問整個數據集。這類似機場中的緝毒犬。緝毒犬消除了執法部門搜查每個人的箱包以尋找可卡因的需要。相反,狗通過訓練(如同機器學習模型一樣)可以排他性地檢測毒品的存在。叫 == 有毒品。不叫 == 沒毒品。陽性的神經網絡預測意味著“在這個手機上策劃一場恐怖活動”,陰性的神經網絡預測意味著“不在這個手機上策劃恐怖活動”。執法部門不需要看到數據。他們只需要這一個數據點。此外,由于模型是分散的智能,它可以被獨立地評估以確保它只檢測需要檢測之物(正如我們可以通過評估緝毒犬在測試中的精確度以獨立地審計緝毒犬用來訓練什么)。然而,和緝毒犬不同,加密人工智能可以提供檢測任何可由電子證據檢測出的犯罪的能力。
審計考量?所以,我們應該信任誰進行審計?我不是一個政治科學專家,所以我將把這個問題留給其他人。然而,我認為,第三方監察人,政府雇員,甚至開源軟件開發者可以承擔這一角色。如果每種檢測器有足夠多的版本,惡意用戶要找出部署的是哪個版本會很困難(因為它們是加密的)。我想這里有許多可行的選項,審計實體的問題已經有很多人討論過了,因此我將把這部分留給專家。
倫理考量?文藝作品對導致直接定罪的犯罪預測的倫理和道德影響有很多評論(比如《少數派報告》)。然而,犯罪預測的主要價值不在于高效的懲罰和監禁,而在于預防傷害。因此,有兩種微不足道的方法可以防止這一倫理困境。首先,大部分重大犯罪需要一些較輕的犯罪作為預備,通過更精確地檢測較輕的犯罪預測重大犯罪可以避免許多道德困境。其次,預防犯罪的技術可以被用來優化警力資源分配,觸發搜查/調查的方法。一個陽性的預測應該導致調查,而不是直接把人投入監獄。
法律考量?United States v. Place案判決,由于緝毒犬能夠排他性地檢測毒品的氣味(而不檢測其他東西),使用緝毒犬不認為是“搜查”。換句話說,由于它們可以在無需居民泄露其他信息的情況下分類犯罪,它不認為是對隱私的侵犯。此外,我認為公眾對此的一般看法和法律是一致的。在機場中,一個毛茸茸的狗狗過來快速地嗅了下你的袋子是非常高效的保護隱私的監控形式。說來也怪,狗無疑可以訓練來檢測你包中任何令人尷尬的東西。然而,它僅僅訓練檢測犯罪的跡象。同樣,智能體可以訓練僅僅檢測犯罪的跡象,而不檢測其他東西。因此,達到足夠精確度的模型,其法律地位應該比照緝毒犬。
腐敗考量?也許你想問:“為何在這方面進行創新?為何提出新的監控方法?我們受到的監控還不多嗎?”我的回答是:企業或政府應當無法監控任何沒有傷害他人的人(無辜者)。相反地,我們想要檢測任何即將傷害他人的人,以阻止他們。在最近的技術進展之前,這兩者明顯無法同時達到。本文想要主張:我相信在技術上同時保障安全和隱私是可行的。我的意思是,隱私不取決于當局的突發奇想,而取決于像加密人工智能一樣的可審計的技術。該由誰負責審計這一技術,而不泄露給惡意之人?我不確定。也許是第三方監察機構。也許這會是人們可以選擇加入的系統(就像煙霧報警器),然后通過社會契約讓人們避免接觸那些不加入的人。也許它完全通過開源的方式開發,但是足夠有效,無法被繞過?這是問題值得進一步討論。本文不是一個完整的解決方案。社會結構和政府結構無疑需要為這類工具作出調整。然而,我相信這是一個值得追尋的目標,我也期待本文引起的討論。
七、以后的工作
首先,也是首要的,我們需要有主流深度學習框架(PyTorch、TensorFlow、Keras等)支持的現代的浮點向量同態加密算法(FV、YASHE等)。其次,探索如何提升這些算法的速度和安全性是一項高度創新和極其重要的工作。最后,我們需要設想社會結構可以如何配合這些新的工具,在不侵犯隱私的前提下保護人們的安全(并繼續降低當局濫用此項技術的風險)。











 工商網監
工商網監
評論