 電子發燒友App
電子發燒友App


1.0延時
Verilog和VHDL是一種基于實際電路進行設計的硬件描述語言,所以在設計時,要更多的基于實際電路去考慮延時的添加。
在實際電路中,延時分為:慣性延時和傳輸延時。
1.1慣性延時:
通常發生在信號通過邏輯門時發生。
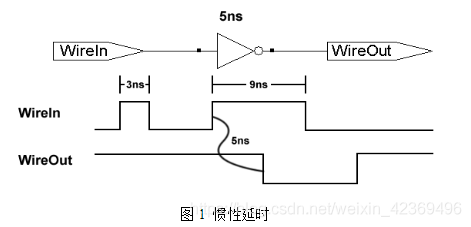
如圖1所示,輸入Wirein有兩個高電平脈沖,第一個寬度為 3ns,第二個寬度為9ns。
當第一個高電平脈沖到達與非門時,因為與非門的延遲是5ns大于第一個脈沖信號寬度3ns,輸出還來不及建立低電平,脈沖信號就已經過去了,導致在輸出信號Wireout上沒有輸出。
當第二個脈沖信號到達與非門時,因其脈沖寬度大于與非門延遲寬度,所以輸出信號Wireout有輸出并整體延遲5ns。
這種延時就被成為慣性延時,如果輸入變化過快,則不會體現在輸出上。
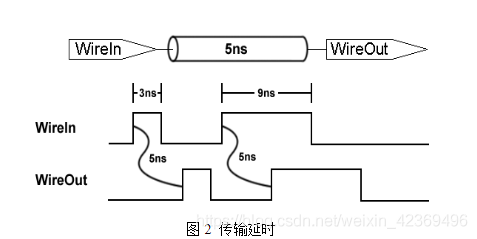
1.2傳輸延時:
傳輸延遲一般為輸入信號變化到對應輸出信號變化經過的時間,不會對輸入信號進行濾除處理,所以傳輸延遲是一種絕對延遲,這種延遲類似于物理傳輸線的延遲,在仿真中用于模擬連線延遲。如下圖所示,輸入一般不會被濾除。
2.0仿真延時
在仿真中,如果在仿真的elaboration過程中沒有顯示指定延遲的類型,那么仿真器一般都會將代碼中指定的延遲作為慣性延遲處理,即此時小于指定延遲寬度的脈沖將被濾除。
如果仿真過程中需要模擬傳輸延遲,需要在elaboration時指定相應的傳輸延遲參數,即使能傳輸延遲模擬功能,此時輸入信號原則上都能通過電路單元。
2.1傳輸延遲參數
在仿真elaboration時,增加如下仿真參數:
“+transport_path_delays +pulse_r/<濾除百分比> +pulse_e/<濾除百分比>”
等可在仿真階段實現傳輸延遲的模擬,并且配置不同的濾除百分比,輸出的結果也會有差異,一般輸出結果為三種情況:濾除、通過、不定態,如下圖所示:
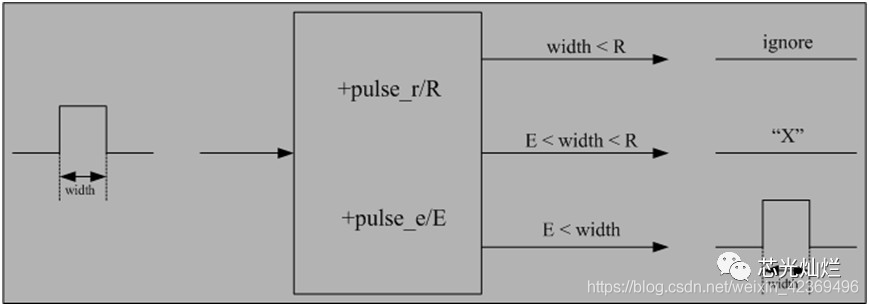
其中“+pulse_r”和“+pulse_e”后指定的參數表示允許通過和濾除的信號的寬度占指定延遲的百分比。
例如,如果指定延遲為5ns,參數為“+pulse_r/40”和“+pulse_e/80”(其中的40和80為百分比),那么小于2ns(5x(40%))的信號將被濾除,大于等于4ns(5x(80%))的信號將可以通過,介于兩者之間的信號將輸出不定態。
Note:如果僅使用“+transport_path_delays”而不使用對脈沖寬度約束的參數(“+pulse_r/e”),那么仿真器將按照慣性延遲處理方式對輸入信號進行處理,即小于指定延遲寬度的信號不能通過電路單元。
同時在EDA工具中還有其他參數(“+pulse_r/e”與“+pulse_int__r/e”等),不同的參數將有不同的仿真效果,具體可參考相關EDA工具手冊。
3.0延時方式
延遲的添加方法有兩種:內定延遲或者正規延遲
內定延遲:C = #2 A+B;
正規延遲:#2 C = A+B;
4.0阻塞賦值延時
阻塞賦值:
always @(a)
y = ~a;
阻塞賦值+正規延遲:
always @(a)
#5 y = ~a;
阻塞賦值+內定延遲:
always @(a)
y = #5 ~a;
4.1阻塞賦值+正規延遲
module adder_t1 (co, sum, a, b, ci);
? ? output? ? ? ? ? ? ?co;
? ? output? ?[3:0]? ?sum;
? ? input? ? ? [3:0]? ?a, b;
? ? input? ? ? ? ? ? ? ? ci;
? reg co;
? reg [3:0] sum;
? always @(a or b or ci)
? ? ? ? ? ?#12 {co, sum} = a + b + ci;
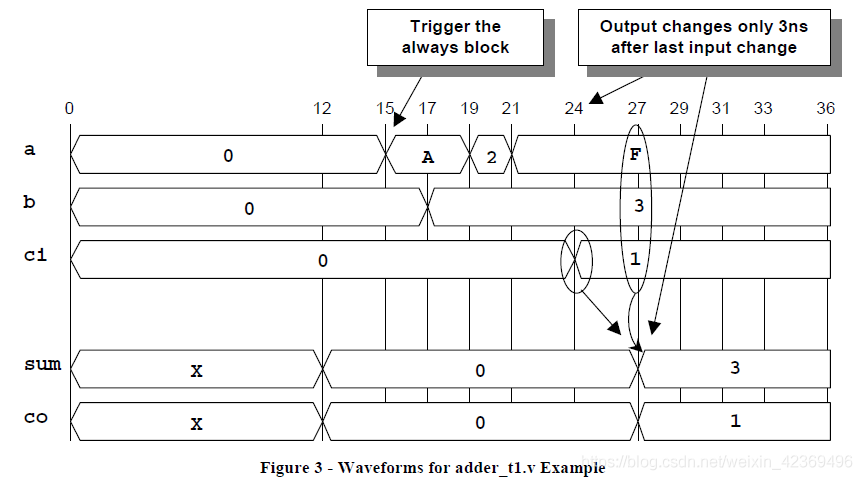
對于adder_t1示例,輸出應在輸入更改后12ns更新。
如圖3所示,如果a輸入在時間15變化,
在接下來的12ns期間a,b和ci輸入發生變化,則輸出將使用a,b和ci的最新值進行更新。
以adder_t7a和adder_t7b為例:
module adder_t7a (co, sum, a, b, ci);
output co;
output [3:0] sum;
input [3:0] a, b;
input ci;
reg co;
reg [3:0] sum;
reg [4:0] tmp;
always @(a or b or ci) begin
#12 tmp = a + b + ci;
{co, sum} = tmp;
end
endmodule
module adder_t7b (co, sum, a, b, ci);
output co;
output [3:0] sum;
input [3:0] a, b;
input ci;
reg co;
reg [3:0] sum;
reg [4:0] tmp;
always @(a or b or ci) begin
tmp = a + b + ci
#12 {co, sum} = tmp;
end
endmodule
adder_t7a的結果與adder_t1一致
adder_t7b的結果由于阻塞賦值的特性,將對第一個輸入變化的輸入進行采樣,并將輸出分配到臨時位置,直到完成指定的阻塞賦值。然后輸出將使用不再有效的舊臨時輸出值寫入。
12ns延遲時間內的其他輸入變化將不會被采樣,這意味著舊的錯誤值將保留在輸出上,直到發生更多輸入變化。
4.1.1準則
1.要對組合邏輯的阻塞賦值進行正規延遲。
2. Testbench指南:在測試平臺中對阻塞賦值進行正規是合理的,因為延遲僅用于時間空間順序輸入激勵事件。
4.2阻塞賦值+內定延遲
module adder_t6 (co, sum, a, b, ci);
output co;
output [3:0] sum;
input [3:0] a, b;
input ci;
reg co;
reg [3:0] sum;
always @(a or b or ci)
{co, sum} = #12 a + b + ci;
endmodule
對于adder_t6,輸出應在輸入更改后12ns更新。
如果a輸入在時間15發生變化,則RHS輸入值將被采樣,輸出更新,而在接下來的12ns期間所有其他a,b和ci輸入變化將不會被采樣。
這意味著舊的錯誤值將保留在輸出上,直到發生更多輸入變化。
module adder_t11a (co, sum, a, b, ci);
output co;
output [3:0] sum;
input [3:0] a, b;
input ci;
reg co;
reg [3:0] sum;
reg [4:0] tmp;
always @(a or b or ci) begin
tmp = #12 a + b + ci;
{co, sum} = tmp;
end
endmodule
module adder_t11b (co, sum, a, b, ci);
output co;
output [3:0] sum;
input [3:0] a, b;
input ci;
reg co;
reg [3:0] sum;
reg [4:0] tmp;
always @(a or b or ci) begin
tmp = a + b + ci;
{co, sum} = #12 tmp;
end
endmodule
當在賦值語句的RHS上發生延遲時,存在多個阻塞賦值的相同問題。
adder_t11a與adder_t6的問題是一樣的。
adder_t11b的輸出將采用最新的值進行輸出。
4.2.1準則
不要在模型組合邏輯的阻塞分配的RHS上設置延遲。
Testbench指南:不要在測試平臺中對阻塞賦值進行內定延遲。
4.3結論
阻塞賦值+延遲,在語句啟動之后,輸出傳輸延時當前時刻或語句啟動時刻的邏輯結果,既不能模擬傳輸延時,也不能模擬慣性延時,所以不建議在阻塞賦值中添加延時。
5.0非阻塞賦值
always @(a)
y <= ~a;
非阻塞賦值+正規延遲
always @(a)
#5 y <= ~a;
非阻塞賦值+內定延遲
always @(a)
y <= #5 ~a;
5.1非阻塞賦值+正規延遲
module adder_t2 (co, sum, a, b, ci);
output co;
output [3:0] sum;
input [3:0] a, b;
input ci;
reg co;
reg [3:0] sum;
always @(a or b or ci)
#12 {co, sum} <= a + b + ci;
endmodule
可以看出,輸出會直接輸出延遲后當前時刻的邏輯結果,并不能反映中間的輸入變化。
5.2非阻塞賦值+內定延遲
module adder_t3 (co, sum, a, b, ci);
output co;
output [3:0] sum;
input [3:0] a, b;
input ci;
reg co;
reg [3:0] sum;
always @(a or b or ci)
{co, sum} <= #12 a + b + ci;
endmodule
向非阻塞賦值的右側(RHS)添加延遲(如圖9所示)將準確地模擬具有傳輸延遲的組合邏輯。
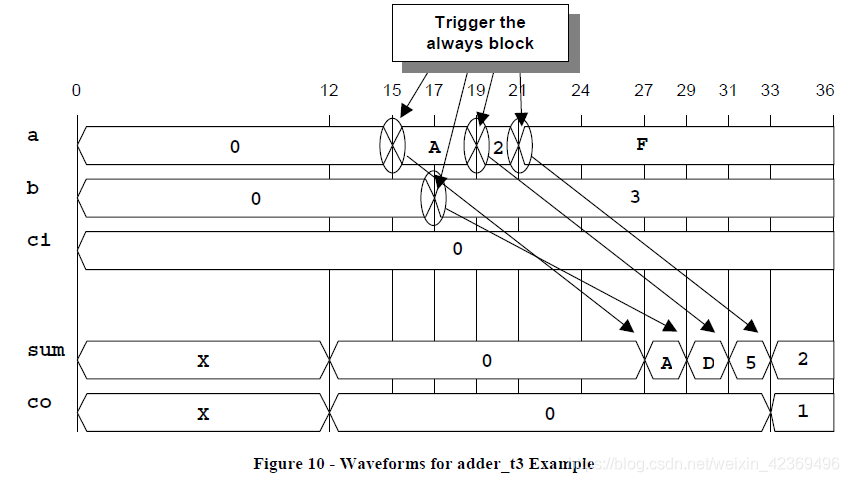
在的adder_t3示例中,如果a輸入在時間15發生變化,如圖10(下一頁)所示,則將采樣所有輸入,并且新輸出值將排隊等待12ns后分配。
在輸出排隊(計劃用于將來分配)但尚未分配之后,將立即再次設置始終塊以在下一個輸入事件上觸發。這意味著所有輸入事件將在12ns延遲后將新值排隊到輸出上。
這種編碼風格模擬了具有傳輸延遲的組合邏輯。
這種編碼風格將精確地模擬具有純傳輸延遲的傳輸延遲;
但是,這種編碼風格通常會導致模擬速度變慢。
Testbench指南:當必須在未來的時鐘邊緣或設定的延遲之后安排刺激時,此編碼樣式通常用于測試平臺,同時不阻止在同一程序塊中分配后續刺激事件。
多個非阻塞賦值和內定延遲
module adder_t9c (co, sum, a, b, ci);
output co;
output [3:0] sum;
input [3:0] a, b;
input ci;
reg co;
reg [3:0] sum;
reg [4:0] tmp;
always @(a or b or ci or tmp) begin
tmp <= #12 a + b + ci;
{co, sum} <= tmp;
end
endmodule
module adder_t9d (co, sum, a, b, ci);
output co;
output [3:0] sum;
input [3:0] a, b;
input ci;
reg co;
reg [3:0] sum;
reg [4:0] tmp;
always @(a or b or ci or tmp) begin
tmp <= a + b + ci;
{co, sum} <= #12 tmp;
end
endmodule
組合邏輯是有缺陷的,除非所有RHS輸入標識符都列在靈敏度列表中,包括僅在always塊內分配和使用的中間臨時值,如adder_t9c和adder_t9d。
對于adder_t9c和adder_t9d示例,非阻塞賦值是并行執行的,并且在更新tmp之后,由于tmp在靈敏度列表中,因此將再次觸發始終塊,評估RHS方程并使用更新LHS方程正確的值(在第二次通過always塊時)。
建模指南:通常,不要將非阻塞賦值的內定延遲放在模型組合邏輯上。這種編碼風格可能令人困惑,并且模擬效率不高。
將非阻塞賦值的內定延遲置于時序邏輯上的時鐘到輸出行為模型是一種常見且有時有用的做法。
Testbench:有一些多時鐘設計驗證套件可以從使用RHS延遲的多個非阻塞賦值中受益;
但是,這種編碼風格可能會令人困惑,因此通常不建議在測試平臺中對非阻塞賦值的RHS進行延遲。
5.3結論
對于非阻塞賦值,當只有一個時,內定延遲可以很好的模擬傳輸延遲的情況。
當非阻塞賦值變為多個時,需要將變量放入敏感事件表中。
因此,非阻塞賦值+內定延遲更適合于設計時序邏輯,而不適合組合邏輯。
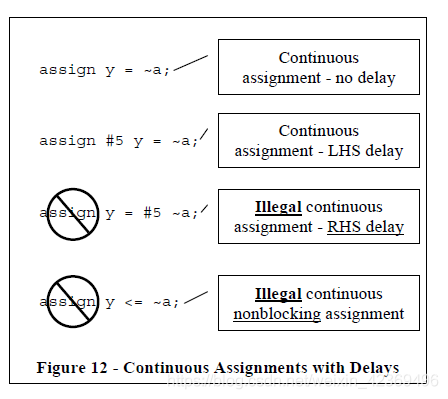
6.0連續賦值
6.1連續賦值+正規延遲
module adder_t4 (co, sum, a, b, ci);
output co;
output [3:0] sum;
input [3:0] a, b;
input ci;
assign #12 {co, sum} = a + b + ci;
endmodule
增加連續賦值的延遲可以精確地模擬具有慣性延遲的組合邏輯,是一種推薦的編碼方式。
對于adder_t4示例,輸出在最后一次輸入更改后12ns內不會改變(所有輸入穩定后12ns)。任何間隔小于12ns的輸入變化序列將導致任何未來的預定輸出事件(具有相應分配時間的輸出值)被替換為新的輸出事件。
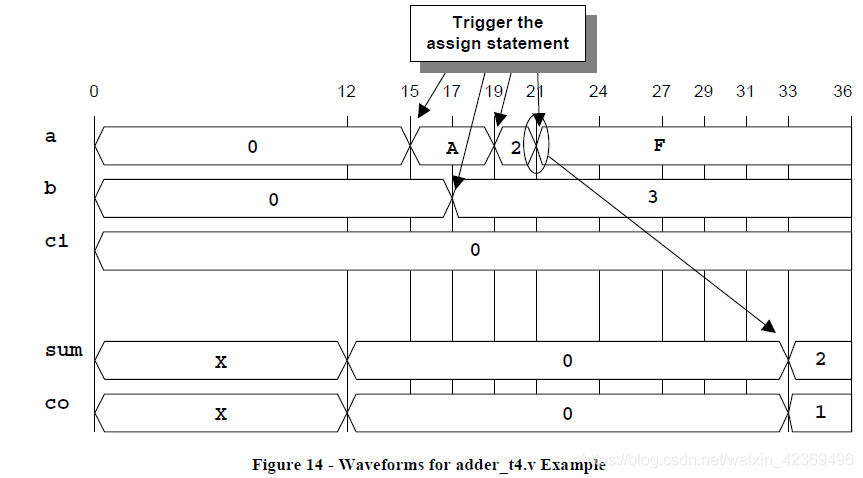
圖14顯示了在圖13中所示的adder_t4代碼上運行模擬的輸出波形。第一個a輸入變化發生在時間15,這導致輸出事件被安排在時間27,但是b輸入上的變化并且在時間17,19和21分別對輸入進行了兩次更改,導致安排三個新的輸出事件。只有最后一個輸出事件實際完成,輸出在時間33分配。連續分配不會“排隊”輸出分配,它們只跟蹤下一個輸出值以及何時發生;因此,連續分配模型具有慣性延遲的組合邏輯。
6.2多個連續賦值+延遲
module adder_t10a (co, sum, a, b, ci);
output co;
output [3:0] sum;
input [3:0] a, b;
input ci;
wire [4:0] tmp;
assign tmp = a + b + ci;
assign #12 {co, sum} = tmp;
endmodule
module adder_t10b (co, sum, a, b, ci);
output co;
output [3:0] sum;
input [3:0] a, b;
input ci;
wire [4:0] tmp;
assign #12 tmp = a + b + ci;
assign {co, sum} = tmp;
endmodule
可以類似地表明,通過向連續分配添加延遲來建模邏輯功能,其輸出用于驅動具有延遲的其他連續分配的輸入,也精確地模擬具有慣性延遲的組合邏輯。
6.3混合無延遲always塊和連續分配
module adder_t5 (co, sum, a, b, ci);
output co;
output [3:0] sum;
input [3:0] a, b;
input ci;
reg [4:0] tmp;
always @(a or b or ci) begin
tmp = a + b + ci;
end
assign #12 {co, sum} = tmp;
endmodule
在沒有延遲的始終塊中建模邏輯功能,然后將始終塊中間值傳遞給具有延遲的連續分配,如adder_t5所示,將精確地模擬具有慣性延遲的組合邏輯。
在上例中,tmp變量在任何輸入事件之后更新。
連續分配輸出在tmp變量最后一次更改后12ns內不會改變。始終塊輸入信號的任何變化都將導致tmp更改,這將導致在連續分配輸出上調度新的輸出事件。直到連續賦值輸出才會更新。
這種編碼風格模擬了具有慣性延遲的組合邏輯。
建模指南:使用具有延遲的連續賦值來建模簡單的組合邏輯。這種編碼風格將準確地模擬具有慣性延遲的組合邏輯。
Testbench指南:可以在測試平臺的任何位置使用連續賦值來將激勵值驅動到輸入端口和實例化模型的雙向端口。
結論
1 ) 模擬慣性延遲的方法:連續賦值+正規延遲
2 ) 模擬傳輸延遲的方法:.非阻塞賦值+內定延遲
3)阻塞賦值不建議添加延遲。









 工商網監
工商網監
評論