如何為深度學習選擇 GPU 服務器?_目前哪里可以租用到GPU服務器?_gpu服務器出租價格
前言
?現今,日益完善的深度學習技術和-AI-服務愈加受到市場青睞。與此同時,數據集不斷擴大,計算模型和網絡也變得越來越復雜,這對于硬件設備也提出了更為嚴苛的需求。如何利用有限的預算,最大限度升級系統整體的計算性能和數據傳輸能力成為了最為重要的問題。
GPU-的選擇
熟悉深度學習的人都知道,深度學習是需要訓練的,所謂的訓練就是在成千上萬個變量中尋找最佳值的計算。這需要通過不斷的嘗試識別,而最終獲得的數值并非是人工確定的數字,而是一種常態的公式。通過這種像素級的學習,不斷總結規律,計算機就可以實現像人一樣思考。因而,更擅長并行計算和高帶寬的-GPU,則成了大家關注的重點。
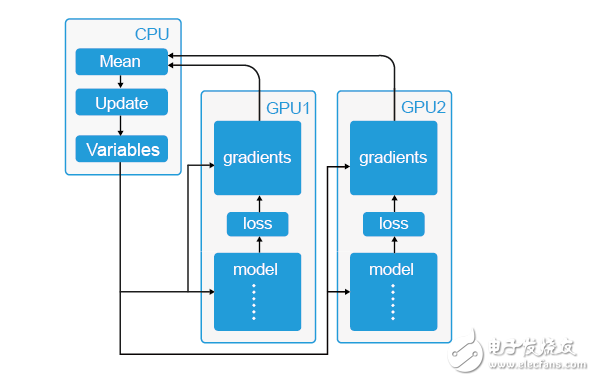
數據并行的原理很簡單,如下圖,其中-CPU-主要負責梯度平均和參數更新,而-GPU1和-GPU2-主要負責訓練模型副本(model replica),這里稱作“模型副本”是因為它們都是基于訓練樣例的子集訓練得到的,模型之間具有一定的獨立性。具體的訓練步驟如下
除了計算能力之外,GPU-另一個比較重要的優勢就是他的內存結構。首先是共享內存。在-NVIDIA-披露的性能參數中,每個流處理器集群末端設有共享內存。相比于-CPU-每次操作數據都要返回內存再進行調用,GPU-線程之間的數據通訊不需要訪問全局內存,而在共享內存中就可以直接訪問。這種設置的帶來最大的好處就是線程間通訊速度的提高(速度:共享內存》》全局內存)。
而在傳統的CPU構架中,盡管有高速緩存(Cache)的存在,但是由于其容量較小,大量的數據只能存放在內存(RAM)中。進行數據處理時,數據要從內存中讀取然后在-CPU-中運算最后返回內存中。由于構架的原因,二者之間的通信帶寬通常在-60GB/s-左右徘徊。與之相比,大顯存帶寬的-GPU-具有更大的數據吞吐量。在大規模深度神經網絡的訓練中,必然帶來更大的優勢。
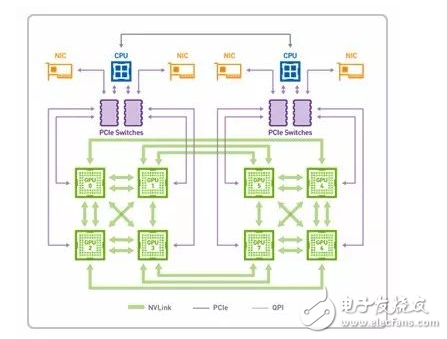
另一方面,如果要充分利用-GPU-資源處理海量數據,需要不斷向-GPU-注入大量數據。目前,PCIe-的數據傳輸速度還無法跟上這一速度,如果想避免此類“交通擁堵”,提高數據傳輸速度可以選擇應用-NVlink-技術的-GPU-卡片。
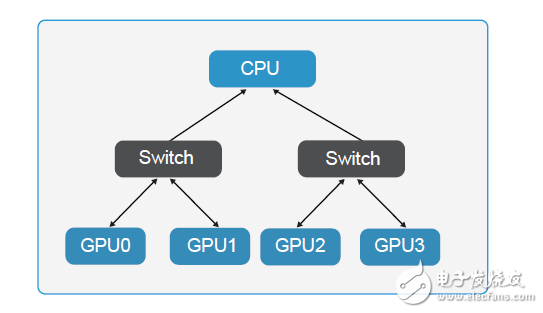
4-GPUs-with-PCIe
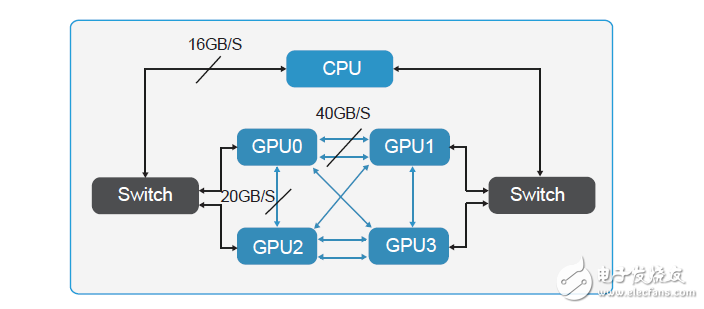
4-GPUs-with-NVLink
NVLink-是目前最快的-GPU-高速互聯技術,借助這種技術,GPU-和-CPU-彼此之間的數據交換速度要比使用PCIe 時快-5-到-12-倍,應用程序的運行速度可加快兩倍。通過-NVLink 連接兩個-GPU-可使其通信速度提高至-80-GB/s,比之前快了-5-倍。
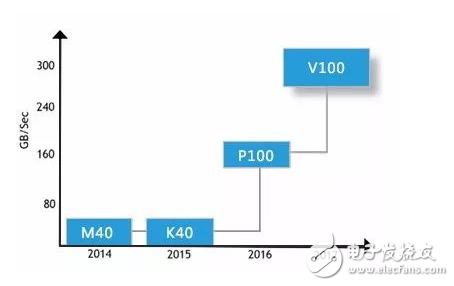
其中-Nvidia-的-Volta-架構計算卡使用的-NVLink-2.0-技術速度更快(20-25Gbps),單通道可提供-50-GB/S-的顯存帶寬。
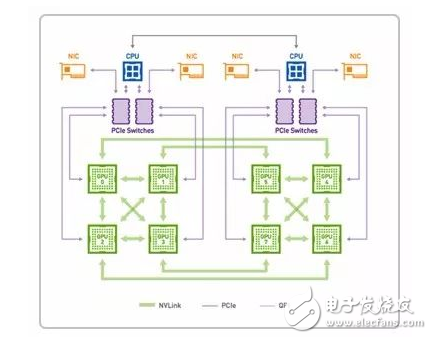
P100-NVLink1.0-數據傳輸模式
V100-NVLink2.0-數據傳輸模式
而且就目前而言,越來越多的深度學習標準庫支持基于-GPU-的深度學習加速,通俗點描述就是深度學習的編程框架會自動根據-GPU-所具有的線程/Core-數,去自動分配數據的處理策略,從而達到優化深度學習的時間。而這些軟件上的全面支持也是其它計算結構所欠缺的。
簡單來看,選擇-GPU-有四個重要參數:浮點運算能力、顯存、數據傳輸與價格。
對于很多科學計算而言,服務器性能主要決定于-GPU-的浮點運算能力。特別是對深度學習任務來說,單精浮點運算以及更低的半精浮點運算性能則更為重要。如果資金充足的情況下,可以選擇應用-NVLink-技術單精計算性能高、顯存大的-GPU-卡片。如果資金有限的話,則要仔細考量核心需求,選擇性價比更高的-GPU-卡片。
內存大小的選擇
心理學家告訴我們,專注力這種資源會隨著時間的推移而逐漸耗盡。內存就是為數不多的,讓你保存注意力資源,以解決更困難編程問題的硬件之一。與其在內存瓶頸上兜轉,浪費時間,不如把注意力放在更加緊迫的問題上。如果你有更多的內存,有了這一前提條件,你可以避免那些瓶頸,節約時間,在更緊迫問題上投入更多的生產力。
所以,如果資金充足而且需要做很多預處理工作,應該選擇至少和-GPU-內存大小相同的內存。雖然更小的內存也可以運行,但是這樣就需要一步步轉移數據,整體效率上則大打則扣。總的來說內存越大,工作起來越舒服。
在一些深度學習案例中,硬驅會成為明顯的瓶頸。如果數據組很大,通常會在硬驅上放一些數據,內存中也放一些,GPU-內存中也放兩-mini-batch。為了持續供給-GPU,我們需要以-GPU-能夠跑完這些數據的速度提供新的-mini-batch。
為此,可以采用和異步-mini-batch-分配一樣的思路,用多重-mini-batch-異步讀取文件。如果不異步處理,結果表現會被削弱很多(5-10%),而且讓認真打造的硬件優勢蕩然無存。那么,這時候就需要-SSD,因為-100-150MB/S-的硬驅會很慢,不足以跟上-GPU。
許多人買一個-SSD-是為了舒服:程序開始和響應都快多了,大文件預處理也快很多,但是,對于深度學習來說,僅當輸入維數很高,不能充分壓縮數據時,這才是必須的。如果買了-SSD,則應該選擇能夠存下和使用者通常要處理的數據集大小相當的存儲容量,也額外留出數十-GB-的空間。另外用普通硬驅保存尚未使用的數據集的主意也不錯。
非常好我支持^.^
(60) 93.8%
不好我反對
(4) 6.2%
相關閱讀:
- [電子說] 租用GPU服務器一般多少錢 2024-11-25
- [電子說] GPU服務器和傳統的服務器有什么區別 2024-11-07
- [電子說] GPU服務器AI網絡架構設計 2024-11-05
- [電子說] GPU服務器用途 2024-10-18
- [電子說] GPU服務器在AI訓練中的優勢具體體現在哪些方面? 2024-09-11
- [電子說] gpu服務器與cpu服務器的區別對比,終于知道怎么選了! 2024-08-01
- [電子說] gpu服務器是干什么的 gpu服務器與cpu服務器的區別有哪些 2024-01-30
- [電子說] 超微gpu服務器評測 2024-01-10
( 發表人:彭菁 )