計算機中內存、cache和寄存器之間的關系
寄存器(Cache)是CPU內部集成的,內存是掛在CPU外面的數據總線上的,訪問內存時要在CPU的寄存器(Cache)填上地址,再執行相應的匯編指令,這時CPU會在數據總線上生成讀取或寫入內存數據的時鐘信號,最終內存的內容會被CPU寄存器(Cache)的內容更新(寫入)或者被讀入CPU的寄存器(Cache)(讀取)。如圖:
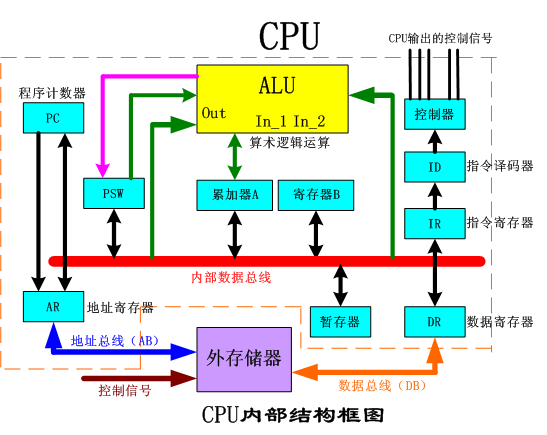
CPU、內存、寄存器之間的關系cpu 取址 -》地址輸入地址寄存器 -》 緩存命中即,則數據進入數據寄存器 -》 緩存未命中則進入內存 -》 內存TLB快表命中則數據塊進入緩存,數據進入寄存器 -》 內存TLB快表未命中則局部數據塊進入緩存和快表 -》 內存未命中則進入硬盤虛擬存儲區
CPU里的寄存器
其實就是我們常說的:Cache,有1級 和 2級,(L1,L2)L1容量比較小,L2(集成在主板上,說使用的為靜態RAM)會多一些,L1是集成在CPU內部的寄存器(L1與CPU 同步),訪問它速度自然很快,但容量比較小,L1 64K L2現在最高的就2MB,這顯然是不夠的,所以我們都需要擴展它,內存(DDR RAM)就是擴展的“寄存器”,它的訪問速度就比 Cache 速度慢!CPU 在運行某計算時,它會把使用頻率高的數據放到L1,L2,把不常用的數據保存在RAM中,需要訪問的時候再讀入Cache,當然相比之下硬盤的速度就更低。
計算機中內存、cache和寄存器之間的關系
寄存器是中央處理器內的組成部份。寄存器是有限存貯容量的高速存貯部件,它們可用來暫存指令、數據和位址。在中央處理器的控制部件中,包含的寄存器有指令寄存器(IR)和程序計數器(PC)。在中央處理器的算術及邏輯部件中,包含的寄存器有累加器(ACC)。
內存包含的范圍非常廣,一般分為只讀存儲器(ROM)、隨機存儲器(RAM)和高速緩存存儲器(cache)。
寄存器是CPU內部的元件,寄存器擁有非常高的讀寫速度,所以在寄存器之間的數據傳送非常快。
Cache :即高速緩沖存儲器,是位于CPU與主內存間的一種容量較小但速度很高的存儲器。由于CPU的速度遠高于主內存,CPU直接從內存中存取數據要等待一定時間周期,Cache中保存著CPU剛用過或循環使用的一部分數據,當CPU再次使用該部分數據時可從Cache中直接調用,這樣就減少了CPU的等待時間,提高了系統的效率。Cache又分為一級Cache(L1
Cache)和二級Cache(L2 Cache),L1 Cache集成在CPU內部,L2 Cache早期一般是焊在主板上,現在也都集成在CPU內部,常見的容量有256KB或512KB L2 Cache。
總結:大致來說數據是通過內存-Cache-寄存器,Cache緩存則是為了彌補CPU與內存之間運算速度的差異而設置的的部件。
首先看一下計算機的存儲體系(Memory hierarchy)金字塔:
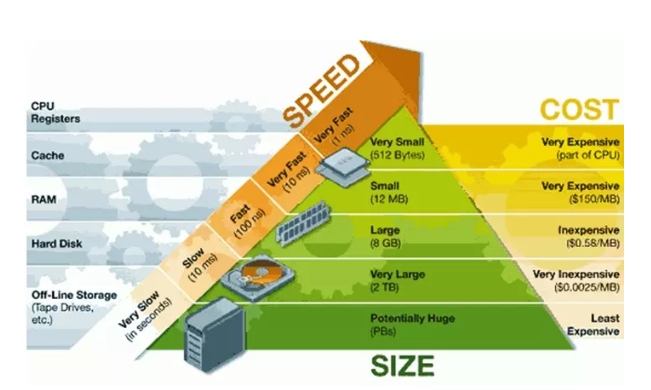
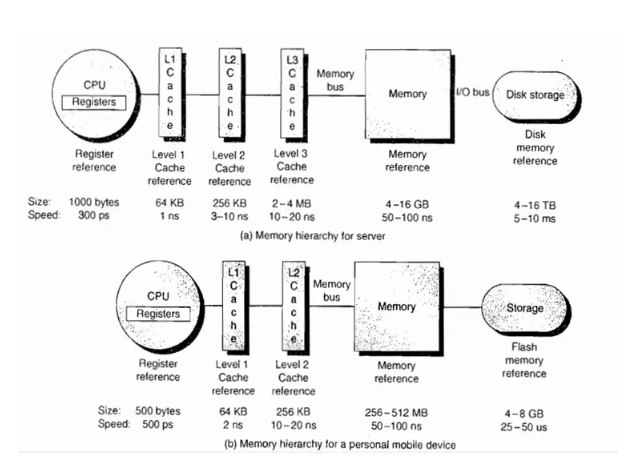
其次我們看看一個計算機的存儲體系
Register
寄存器是CPU的內部組成單元,是CPU運算時取指令和數據的地方,速度很快,寄存器可以用來暫存指令、數據和地址。在CPU中,通常有通用寄存器,如指令寄存器IR;特殊功能寄存器,如程序計數器PC、sp等。
Cache
緩存即就是用于暫時存放內存中的數據,若果寄存器要取內存中的一部分數據時,可直接從緩存中取到,這樣可以調高速度。高速緩存是內存的部分拷貝。
CPU 《--- 》 寄存器《--- 》 緩存《--- 》內存
寄存器的工作方式很簡單,只有兩步:(1)找到相關的位,(2)讀取這些位。
內存的工作方式就要復雜得多:
(1)找到數據的指針。(指針可能存放在寄存器內,所以這一步就已經包括寄存器的全部工作了。)
(2)將指針送往內存管理單元(MMU),由MMU將虛擬的內存地址翻譯成實際的物理地址。
(3)將物理地址送往內存控制器(memory controller),由內存控制器找出該地址在哪一根內存插槽(bank)上。
(4)確定數據在哪一個內存塊(chunk)上,從該塊讀取數據。
(5)數據先送回內存控制器,再送回CPU,然后開始使用。
內存的工作流程比寄存器多出許多步。每一步都會產生延遲,累積起來就使得內存比寄存器慢得多。
為了緩解寄存器與內存之間的巨大速度差異,硬件設計師做出了許多努力,包括在CPU內部設置緩存、優化CPU工作方式,盡量一次性從內存讀取指令所要用到的全部數據等等。
RAM-memory
即內存,是用于存放數據的單元。其作用是用于暫時存放CPU中的運算數據,以及與硬盤等外部存儲器交換的數據。
HardDisk
硬盤
一條匯編指令大概執行過程是(不是絕對的,不同平臺有差異):
取指(取指令)、譯碼(把指令轉換成微指令)、取數(讀內存里的操作數)、計算(各種計算的過程,ALU負責)、寫回(將計算結果寫回內存),有些平臺里,前兩步會合并成一步,某些指令也不會有取數或者回寫的過程。
再提一下CPU主頻的概念:首先,主頻絕對不等于一秒鐘可以執行的指令個數,每個指令的執行成本是不同的,比如x86平臺里匯編指令INC就比ADD要快,具體每個指令的時鐘周期可以參考intel的手冊。
為什么要提主頻?因為上面的執行過程中,每個操作都需要占用一個時鐘周期,對于一個操作內存的加法,就需要5個時鐘周期,換句話說,500Mhz主頻的CPU,最多執行100MHz條指令。
仔細觀察,上面的步驟里不包括寄存器操作,對于CPU來說讀/寫寄存器是不需要時間的,或者說如果只是操作寄存器(比如類似mov BX,AX之類的操作),那么一秒鐘執行的指令個數理論上說就等于主頻,因為寄存器是CPU的一部分。
然后寄存器往下就是各級的cache,有L1 cache,L2,甚至有L3的,以及TLB這些(TLB也可以認為是cache),之后就是內存,前面說寄存器快,現在說為什么這些慢:
對于各級的cache,訪問速度是不同的,理論上說L1cache(一級緩存)有著跟CPU寄存器相同的速度,但L1cache有一個問題,當需要同步cache和內存之間的內容時,需要鎖住cache的某一塊(術語是cache line),然后再進行cache或者內存內容的更新,這段期間這個cache塊是不能被訪問的,所以L1cache的速度就沒寄存器快,因為它會頻繁的有一段時間不可用。
L1 cache下面是L2 cache,甚至L3 cache,這些都有跟L1 cache一樣的問題,要加鎖,同步,并且L2比L1慢,L3比L2慢,這樣速度也就更低了。
最后說說內存,內存的主頻現在主流是1333左右吧?或者1600,單位是MHz,這比CPU的速度要低的多,所以內存的速度起點就更低,然后內存跟CPU之間通信也不是想要什么就要什么的。
內存不僅僅要跟CPU通信,還要通過DMA控制器與其它硬件通信,CPU要發起一次內存請求,先要給一個信號說“我要訪問數據了,你忙不忙?”如果此時內存忙,則通信需要等待,不忙的時候,通信才能正常。并且,這個請求信號的時間代價,就是夠執行幾個匯編指令了,所以,這是內存慢的一個原因。
另一個原因是:內存跟CPU之間通信的通道也是有限的,就是所謂的“總線帶寬”,但,要記住這個帶寬不僅僅是留給內存的,還包括顯存之類的各種通信都要走這條路,并且由于路是共享的,所以任何請求發起之間都要先搶占,搶占帶寬需要時間,帶寬不夠等待的話也需要時間。
以上兩條加起來導致了CPU訪問內存更慢,比cache還慢。
舉個更容易懂的例子:
CPU要取寄存器AX的值,只需要一步:把AX給我拿來,AX就拿來了。
CPU要取L1 cache的某個值,需要1-3步(或者更多):把某某cache行鎖住,把某個數據拿來,解鎖,如果沒鎖住就慢了。
CPU要取L2 cache的某個值,先要到L1 cache里取,L1說,我沒有,在L2里,L2開始加鎖,加鎖以后,把L2里的數據復制到L1,再執行讀L1的過程,上面的3步,再解鎖。
CPU取L3 cache的也是一樣,只不過先由L3復制到L2,從L2復制到L1,從L1到CPU。
CPU取內存則最復雜:通知內存控制器占用總線帶寬,通知內存加鎖,發起內存讀請求,等待回應,回應數據保存到L3(如果沒有就到L2),再從L3/2到L1,再從L1到CPU,之后解除總線鎖定。
非常好我支持^.^
(6) 100%
不好我反對
(0) 0%
相關閱讀:
- [電子說] 學習STM32F103的ADC功能 2023-10-24
- [編程語言及工具] 常用于緩存處理的機制總結 如何避免緩存雪崩問題? 2023-10-24
- [電子說] 學習STM32F103的DAC功能 2023-10-24
- [電子說] 學習STM32F103的定時器功能 2023-10-24
- [電子說] STM32基礎知識:定時器的PWM輸出功能 2023-10-24
- [電子說] 既然ODR能控制管腳高低電平,為什么還需要BSRR寄存器呢? 2023-10-24
- [電子說] ARM系列-P Channel簡析 2023-10-24
- [控制/MCU] 基于STM32F429芯片的單片機芯片內存映射圖 2023-10-23
( 發表人:李倩 )