深度學(xué)習(xí)之GPU硬件選型
深度學(xué)習(xí)在2012年大放異彩,gpu計算也走入了人們的視線之中,它使得大規(guī)模計算神經(jīng)網(wǎng)絡(luò)成為可能。人們可以通過07年推出的CUDA(Compute Unified Device Architecture)用代碼來控制gpu進(jìn)行并行計算。本文首先根據(jù)顯卡一些參數(shù)來推薦何種情況下選擇何種gpu顯卡,然后談?wù)劯鷆uda編程比較相關(guān)的硬件架構(gòu)。
1.選擇怎樣的GPU型號
這幾年主要有AMD和NVIDIA在做顯卡,到目前為止,NVIDIA公司推出過的GeForce系列卡就有幾百張[1],雖然不少都已經(jīng)被淘汰了,但如何選擇適合的卡來做算法也是一個值得思考的問題,Tim Dettmers[2]的文章給出了很多有用的建議,根據(jù)自己的理解和使用經(jīng)歷(其實只用過GTX 970…)我也給出一些建議。

179上面并沒有考慮筆記本的顯卡,做算法加速的話還是選臺式機(jī)的比較好。性價比最高的我覺得是GTX 980ti,從參數(shù)或者一些用戶測評來看,性能并沒有輸給TITAN X多少,但價格卻便宜不少。從圖1可以看出,價位差不多的顯卡都會有自己擅長的地方,根據(jù)自己的需求選擇即可。要處理的數(shù)據(jù)量比較小就選擇頻率高的,要處理的數(shù)據(jù)量大就選顯存大core數(shù)比較多的,有double的精度要求就最好選擇kepler架構(gòu)的。tesla的M40是專門為深度學(xué)習(xí)制作的,如果只有深度學(xué)習(xí)的訓(xùn)練,這張卡雖然貴,企業(yè)或者機(jī)構(gòu)購買還是比較合適的(百度的深度學(xué)習(xí)研究院就用的這一款[3]),相對于K40單精度浮點運算性能是4.29Tflops,M40可以達(dá)到7Tflops。QUADRO系列比較少被人提起,它的M6000價格比K80還貴,性能參數(shù)上也并沒有好多少。
在挑選的時候要注意的幾個參數(shù)是處理器核心(core)、工作頻率、顯存位寬、單卡or雙卡。有的人覺得位寬最重要,也有人覺得核心數(shù)量最重要,我覺得對深度學(xué)習(xí)計算而言處理器核心數(shù)和顯存大小比較重要。這些參數(shù)越多越高是好,但是程序相應(yīng)的也要寫好,如果無法讓所有的core都工作,資源就被浪費了。而且在購入顯卡的時候,如果一臺主機(jī)插多張顯卡,要注意電源的選擇。
2.一些常見的名稱含義
上面聊過了選擇什么樣的gpu,這一部分介紹一些常見名詞。隨著一代一代的顯卡性能的更新,從硬件設(shè)計上或者命名方式上有很多的變化與更新,其中比較常見的有以下一些內(nèi)容。
gpu架構(gòu):Tesla、Fermi、Kepler、Maxwell、Pascal
芯片型號:GT200、GK210、GM104、GF104等
顯卡系列:GeForce、Quadro、Tesla
GeForce顯卡型號:G/GS、GT、GTS、GTX
gpu架構(gòu)指的是硬件的設(shè)計方式,例如流處理器簇中有多少個core、是否有L1 or L2緩存、是否有雙精度計算單元等等。每一代的架構(gòu)是一種思想,如何去更好完成并行的思想,而芯片就是對上述思想的實現(xiàn),芯片型號GT200中第二個字母代表是哪一代架構(gòu),有時會有100和200代的芯片,它們基本設(shè)計思路是跟這一代的架構(gòu)一致,只是在細(xì)節(jié)上做了一些改變,例如GK210比GK110的寄存器就多一倍。有時候一張顯卡里面可能有兩張芯片,Tesla k80用了兩塊GK210芯片。這里第一代的gpu架構(gòu)的命名也是Tesla,但現(xiàn)在基本已經(jīng)沒有這種設(shè)計的卡了,下文如果提到了會用Tesla架構(gòu)和Tesla系列來進(jìn)行區(qū)分。
而顯卡系列在本質(zhì)上并沒有什么區(qū)別,只是NVIDIA希望區(qū)分成三種選擇,GeFore用于家庭娛樂,Quadro用于工作站,而Tesla系列用于服務(wù)器。Tesla的k型號卡為了高性能科學(xué)計算而設(shè)計,比較突出的優(yōu)點是雙精度浮點運算能力高并且支持ECC內(nèi)存,但是雙精度能力好在深度學(xué)習(xí)訓(xùn)練上并沒有什么卵用,所以Tesla系列又推出了M型號來做專門的訓(xùn)練深度學(xué)習(xí)網(wǎng)絡(luò)的顯卡。需要注意的是Tesla系列沒有顯示輸出接口,它專注于數(shù)據(jù)計算而不是圖形顯示。
最后一個GeForce的顯卡型號是不同的硬件定制,越往后性能越好,時鐘頻率越高顯存越大,即G/GS《GT《GTS《GTX。
3.gpu的部分硬件
這一部分以下面的GM204硬件圖做例子介紹一下GPU的幾個主要硬件(圖片可以點擊查看大圖,不想圖片占太多篇幅)[4]。這塊芯片它是隨著GTX 980和970一起出現(xiàn)的。一般而言,gpu的架構(gòu)的不同體現(xiàn)在流處理器簇的不同設(shè)計上(從Fermi架構(gòu)開始加入了L1、L2緩存硬件),其他的結(jié)構(gòu)大體上相似。主要包括主機(jī)接口(host interface)、復(fù)制引擎(copy engine)、流處理器簇(Streaming Multiprocessors)、圖形處理簇GPC(graphics processing clusters)、內(nèi)存等等。
39主機(jī)接口,它連接了gpu卡和PCI Express,它主要的功能是讀取程序指令并分配到對應(yīng)的硬件單元,例如某塊程序如果在進(jìn)行內(nèi)存復(fù)制,那么主機(jī)接口會將任務(wù)分配到復(fù)制引擎上。
復(fù)制引擎(圖中沒有表示出來),它完成gpu內(nèi)存和cpu內(nèi)存之間的復(fù)制傳遞。當(dāng)gpu上有復(fù)制引擎時,復(fù)制的過程是可以與核函數(shù)的計算同步進(jìn)行的。隨著gpu卡的性能變得強(qiáng)勁,現(xiàn)在深度學(xué)習(xí)的瓶頸已經(jīng)不在計算速度慢,而是數(shù)據(jù)的讀入,如何合理的調(diào)用復(fù)制引擎是一個值得思考的問題。
流處理器簇SM是gpu最核心的部分,這個翻譯參考的是GPU編程指南,SM由一系列硬件組成,包括warp調(diào)度器、寄存器、Core、共享內(nèi)存等。它的設(shè)計和個數(shù)決定了gpu的計算能力,一個SM有多個core,每個core上執(zhí)行線程,core是實現(xiàn)具體計算的處理器,如果core多同時能夠執(zhí)行的線程就多,但是并不是說core越多計算速度一定更快,最重要的是讓core全部處于工作狀態(tài),而不是空閑。不同的架構(gòu)可能對它命名不同,kepler叫SMX,maxwell叫SMM,實際上都是SM。而GPC只是將幾個sm組合起來,在做圖形顯示時有調(diào)度,一般在寫gpu程序不需要考慮這個東西,只要掌握SM的結(jié)構(gòu)合理的分配SM的工作即可。
圖中的內(nèi)存控制器控制的是L2內(nèi)存,每個大小為512KB。
4.流處理器簇的結(jié)構(gòu)
上面介紹的是gpu的整個硬件結(jié)構(gòu),這一部分專門針對流處理器簇SM來分析它內(nèi)部的構(gòu)造是怎樣的。首先要明白的是,gpu的設(shè)計是為了執(zhí)行大量簡單任務(wù),不像cpu需要處理的是復(fù)雜的任務(wù),gpu面對的問題能夠分解成很多可同時獨立解決的部分,在代碼層面就是很多個線程同時執(zhí)行相同的代碼,所以它相應(yīng)的設(shè)計了大量的簡單處理器,也就是stream process,在這些處理器上進(jìn)行整形、浮點型的運算。下圖給出了GK110的SM結(jié)構(gòu)圖。它屬于kepler架構(gòu),與之前的架構(gòu)比較大的不同是加入了雙精度浮點運算單元,即圖中的DP Unit。所以用kepler架構(gòu)的顯卡進(jìn)行雙精度計算是比較好的。
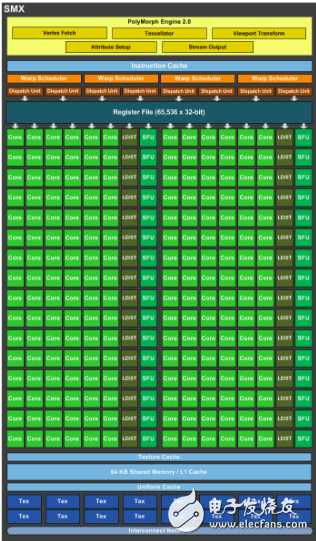
上面提到過的一個SM有多個core或者叫流處理器,它是gpu的運算單元,做整形、浮點型計算。可以認(rèn)為在一個core上一次執(zhí)行一個線程,GK110的一個SM有192個core,因此一次可以同時執(zhí)行192個線程。core的內(nèi)部結(jié)構(gòu)可以查看[5],實現(xiàn)算法一般不會深究到core的結(jié)構(gòu)層面。SFU是特殊函數(shù)單元,用來計算log/exp/sin/cos等。DL/ST是指Load/Store,它在讀寫線程執(zhí)行所需的全局內(nèi)存、局部內(nèi)存等。
一個SM有192個core,8個SM有1536個core,這么多的線程并行執(zhí)行需要有統(tǒng)一的管理,假如gpu每次在1536個core上執(zhí)行相同的指令,而需要計算這一指令的線程不足1536個,那么就有core空閑,這對資源就是浪費,因此不能對所有的core做統(tǒng)一的調(diào)度,從而設(shè)計了warp(線程束)調(diào)度器。32個線程一組稱為線程束,32個線程一組執(zhí)行相同的指令,其中的每個thread稱為lane。一個線程束接受同一個指令,里面的32個線程同時執(zhí)行,不同的線程束可執(zhí)行不同指令,那么就不會出現(xiàn)大量線程空閑的問題了。但是在線程束調(diào)度上還是存在一些問題,假如某段代碼中有if…else…,在調(diào)度一整個線程束32個線程的時候不可能做到給thread0~15分配分支1的指令,給thread16~31分配分支2的指令(實際上gpu對分支的控制是,所有該執(zhí)行分支1的線程執(zhí)行完再輪到該執(zhí)行分支2的線程執(zhí)行),它們獲得的都是一樣的指令,所以如果thread16~31是在分支2中它們就需要等待thread0~15一起完成分支1中的計算之后,再獲得分支2的指令,而這個過程中,thread0~15又在等待thread16~31的工作完成,從而導(dǎo)致了線程空閑資源浪費。因此在真正的調(diào)度中,是半個warp執(zhí)行相同指令,即16個線程執(zhí)行相同指令,那么給thread0~15分配分支1的指令,給thread16~31分配分支2的指令,那么一個warp就能夠同時執(zhí)行兩個分支。這就是圖中Warp Scheduler下為什么會出現(xiàn)兩個dispatch的原因。
另外一個比較重要的結(jié)構(gòu)是共享內(nèi)存shared memory。它存儲的內(nèi)容在一個block(暫時認(rèn)為是比線程束32還要大的一些線程個數(shù)集合)中共享,一個block中的線程都可以訪問這塊內(nèi)存,它的讀寫速度比全局內(nèi)存要快,所以線程之間需要通信或者重復(fù)訪問的數(shù)據(jù)往往都會放在這個地方。在kepler架構(gòu)中,一共有64kb的空間大小,供共享內(nèi)存和L1緩存分配,共享內(nèi)存實際上也可看成是L1緩存,只是它能夠被用戶控制。假如共享內(nèi)存占48kb那么L1緩存就占16kb等。在maxwell架構(gòu)中共享內(nèi)存和L1緩存分開了,共享內(nèi)存大小是96kb。而寄存器的讀寫速度又比共享內(nèi)存要快,數(shù)量也非常多,像GK110有65536個。
此外,每一個SM都設(shè)置了獨立訪問全局內(nèi)存、常量內(nèi)存的總線。常量內(nèi)存并不是一塊內(nèi)存硬件,而是全局內(nèi)存的一種虛擬形式,它跟全局內(nèi)存不同的是能夠高速緩存和在線程束中廣播數(shù)據(jù),因此在SM中有一塊常量內(nèi)存的緩存,用于緩存常量內(nèi)存。
小結(jié)
本文談了談gpu的一些重要的硬件組成,就深度學(xué)習(xí)而言,我覺得對內(nèi)存的需求還是比較大的,core多也并不是能夠全部用上,但現(xiàn)在開源的庫實在完整,想做卷積運算有cudnn,想做卷積神經(jīng)網(wǎng)絡(luò)caffe、torch,想做rnn有mxnet、tensorflow等等,這些庫內(nèi)部對gpu的調(diào)用做的非常好并不需用戶操心,但了解gpu的一些內(nèi)部結(jié)構(gòu)也是很有意思的。
另,一開始接觸GPU并不知道是做圖形渲染的…所以有些地方可能理解有誤,主要基于計算來討論GPU的構(gòu)造。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%
相關(guān)閱讀:
- [電子說] Blackwell GB100能否在超級計算機(jī)和AI市場保持領(lǐng)先優(yōu)勢? 2023-10-24
- [電子說] 如何使用Rust創(chuàng)建一個基于ChatGPT的RAG助手 2023-10-24
- [電子說] 異構(gòu)時代:CPU與GPU的發(fā)展演變 2023-10-24
- [電子說] RISC-V要顛覆GPU嗎? 2023-10-24
- [電子說] 深度學(xué)習(xí)在工業(yè)缺陷檢測中的應(yīng)用 2023-10-24
- [電子說] 聯(lián)發(fā)科發(fā)布“暴擊,天璣9300跑分超200萬 2023-10-23
- [電子說] 華為最新昇騰芯片910B可對標(biāo)英偉達(dá)A100? 2023-10-23
- [電子說] GPU是否有替代方案? 2023-10-23
( 發(fā)表人:彭菁 )