 電子發燒友App
電子發燒友App


芯片設計會議上的討論很少激烈。但一年前在物理設計國際研討會(ISPD) 上,事情變得一發不可收拾。有人將其形容為“火車失事”和“伏擊”。沖突的關鍵是谷歌針對芯片設計中一個棘手問題的人工智能解決方案是否真的比人類或最先進的算法更好。它將成熟的男性電子設計自動化 (EDA) 專家與兩名年輕的谷歌計算機科學家進行較量,而潛在的爭論已經導致一名谷歌研究員被解雇。
今年在同一個會議上,該領域的領導者、IEEE 研究員安德魯·卡恩 (Andrew Kahng ) 希望一勞永逸地結束爭吵。他和加州大學圣地亞哥分校的同事對谷歌的強化學習方法進行了他所謂的“公開透明的評估” 。使用 Google 的開源版本的流程,稱為 Circuit Training,并對 Kahng 的團隊不夠清楚的一些部分進行逆向工程,他們將強化學習設置為針對人類設計師、商業軟件和最先進的學術算法。Kahng 拒絕就本文 與IEEE Spectrum交談,但他上周在虛擬舉行的 ISPD 上與工程師進行了交談。
在大多數情況下,Circuit Training 不是贏家,但它具有競爭力。鑒于實驗不允許 Circuit Training 使用其標志性能力——通過學習其他芯片設計來提高其性能,這一點尤其值得注意。
“我們的目標是明確理解,讓社區繼續前進,”他告訴工程師。只有時間會證明它是否有效。
如何和何時
所討論的問題稱為放置。基本上,它是確定邏輯塊或內存塊應該放置在芯片上的哪個位置的過程,以便最大限度地提高芯片的工作頻率,同時最大限度地降低其功耗和占用的面積。找到這個難題的最佳解決方案是最困難的問題之一,可能的排列比圍棋游戲更多。
但圍棋最終被一種稱為深度強化學習的人工智能擊敗,而這正是前谷歌大腦研究人員 Azalia Mirhoseini 和 Anna Goldie 應用于放置問題的方法。該方案當時稱為 Morpheus,將放置大塊電路(稱為宏)視為游戲,學習尋找最佳解決方案。(宏的位置對芯片的特性有很大的影響。在 Circuit Training 和 Morpheus 中,一個單獨的算法用較小的部分填充了空白,稱為標準單元。其他方法對宏和標準單元使用相同的過程。)
簡而言之,這就是它的工作原理:芯片的設計文件以所謂的網表開始——哪些宏和單元根據什么約束連接到哪些其他宏和單元。然后將標準cell收集到簇中以幫助加快訓練過程。Circuit Training 然后開始將宏一次一個地放置在芯片“畫布”上。當最后一個關閉時,一個單獨的算法會用標準單元填補空白,系統會快速評估嘗試,包括布線的長度(越長越差),它的密集程度(更多密集更糟),以及布線有多擁擠(你猜對了,更糟)。這稱為代理成本,其作用類似于計算如何玩視頻游戲的強化學習系統中的分數。該分數用作調整神經網絡的反饋,并再次嘗試。清洗、沖洗、重復。當系統最終了解其任務時,商業軟件會對完整布局進行全面評估,生成芯片設計人員關心的指標,例如面積、功耗和頻率限制。
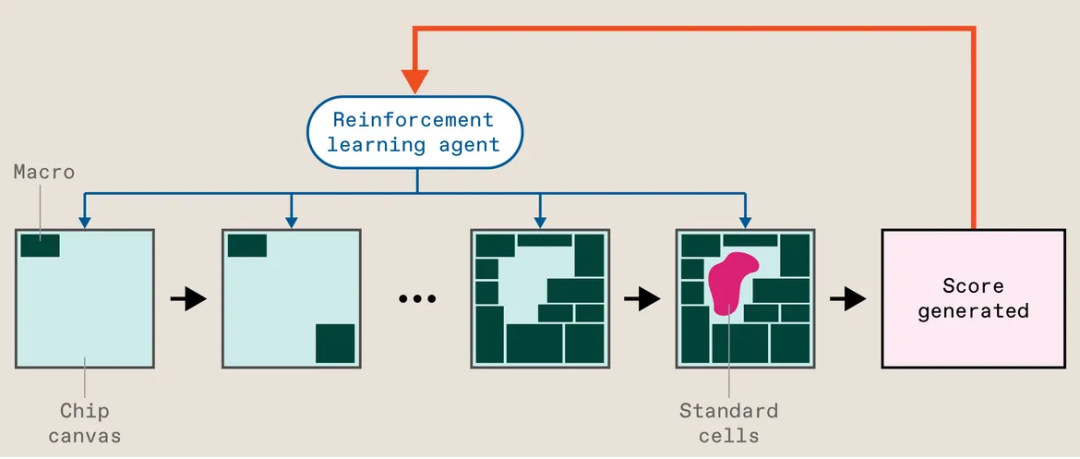
谷歌的強化學習系統將放置稱為宏的大型電路塊視為游戲。代理在芯片畫布上一次放置一個塊。然后一個單獨的算法填充稱為標準單元格的較小部分。根據多個指標對放置進行評分,該分數用作改進代理的反饋。
經過七個月的審查過程, Mirhoseini 和 Goldie于 2021 年 6 月在Nature 上發表了 Morpheus 的結果和方法。(Kahng 是第 3 號評論員。)并且該技術被用于設計不止一代Google 的 TPU AI 加速器芯片。(所以是的,你今天使用的數據可能已經由運行在部分由 AI 設計的芯片上的 AI 處理。但隨著 Cadence 和 Synopsys 等 EDA 供應商全力投入 AI 輔助芯片設計,這種情況越來越多。) 2022 年 1 月,他們在 GitHub 上發布了開源版本Circuit Training。但 Kahng 和其他人聲稱,即使是這個版本也不夠完整,無法重現這項研究。
作為對《自然》雜志的回應,一個獨立的工程師小組(主要在谷歌內部)開始研究,他們認為這是一種將強化學習與既定算法進行比較的更好方法。但這不是友好的競爭。據媒體報道,其領導人 Satrajit Chatterjee 多次親自破壞 Mirhoseini 和 Goldie,并因此于 2022 年被解雇。
當 Chatterjee 還在谷歌時,他的團隊發表了一篇題為“ Stronger Baselines ”的論文,批評發表在《自然》雜志上的研究。他試圖在會議上展示它,但在經過獨立決議委員會的審查后,谷歌拒絕了。在他被解雇后,該論文的早期版本在 2022 年 ISPD 之前 通過匿名 Twitter 帳戶泄露,導致公眾對抗。
基準、基線和可重復性
當IEEE Spectrum在 ISPD 2022 之后與 EDA 專家交談時,批評者提出了三個相互關聯的問題——基準、基線和可重復性。
基準是公開可用的電路塊,研究人員可以在這些電路塊上測試他們的新算法。谷歌開始工作時的基準已經有大約二十年的歷史了,它們與現代芯片的相關性存在爭議。卡爾加里大學教授 Laleh Behjat 將其比作規劃現代城市與規劃 17 世紀城市。她說,每個人所需的基礎設施是不同的。然而,其他人指出,如果每個人都在同一組基準上進行測試,研究社區就無法取得進步。
Nature論文 沒有采用當時可用的基準,而是專注于為 Google 的 TPU 做布局,這是一種復雜的尖端芯片,其設計對 Google 以外的研究人員不可用。泄露的“Stronger Baselines”工作放置了 TPU 塊,但也使用了舊的基準。雖然 Kahng 的新作品也為舊的基準測試做了安排,但主要關注點集中在三個更現代的設計上,其中兩個是新推出的,包括一個多核 RISC-V 處理器。
基線是您的新系統與之競爭的最先進算法。Nature將使用商業工具的人類專家與強化學習和當時領先的學術算法 RePlAce 進行了比較。Stronger Baselines 認為Nature 的工作沒有正確執行 RePlAce,并且還需要比較另一種算法,模擬退火。(公平地說,模擬退火結果出現在Nature論文的附錄中。)
但Kahng 真正關注的 是可重復性。他聲稱 Circuit Training 在發布到 GitHub 時未能允許獨立小組完全重現該過程。因此,他們自行對他們認為缺失的元素和參數進行逆向工程。
重要的是,Kahng 的團隊公開記錄了進展、代碼、數據集和程序,以此作為此類工作如何提高可重復性的示例。首先,他們甚至設法說服 EDA 軟件公司 Cadence 和 Synopsys 允許發布實驗中使用的高級腳本。“對于我們的領域來說,這絕對是一個分水嶺,”Kahng 說。
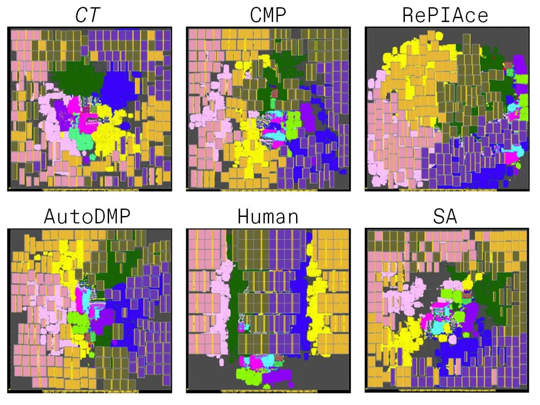
UCSD 的努力,簡稱為MacroPlacement,并不意味著要一對一地重做Nature論文或泄露的 Stronger Baselines 工作。除了使用 2020 年和 2021 年不可用的現代公共基準測試外,MacroPlacement 還將 Circuit Training(雖然不是最新版本)與新的商業工具Cadence 的 Innovus 并發宏布局器 (CMP)以及在 Nvidia 開發的稱為AutoDMP的方法進行了比較新的它只是在 Kahng 發言前的 ISPD 2023 分鐘公開介紹。
強化學習與所有人
Kahng 的論文報告了使用兩種技術(開源的 NanGate45 和GlobalFoundries 的商用 FinFET 工藝 GF12)實施的三種現代基準設計的結果。( 《自然》雜志報道的 TPU 結果使用了更先進的工藝技術。)Kahng 的團隊測量了 Mirhoseini 和 Goldie 在他們的《自然》論文中所做的相同的六個指標:面積、布線長度、功率、兩個時序指標,以及前面提到的代理成本。(代理成本不是生產中使用的實際指標,但它被包括在內以反映自然論文。)結果好壞參半。
正如在《自然》雜志 的原始論文中所做的那樣,強化學習在大多數進行直接比較的指標上都擊敗了 RePlAce。(RePlAce 沒有為三個設計中最大的一個提供答案。)與模擬退火相比,Circuit Training 在生產指標上贏多于輸。
對于這些實驗,大贏家是最新加入的 CMP 和 AutoDMP,它們在比任何其他方法更多的情況下提供了最佳指標。
在旨在匹配 Stronger Baselines 的測試中,使用較舊的基準測試,RePlAce 和模擬退火幾乎總是擊敗強化學習。但這些結果只報告了一個生產指標,即線長,因此它們并沒有呈現完整的畫面,Mirhoseini 和 Goldie 爭論道。
缺乏學習
可以理解,Mirhoseini 和 Goldie 對 MacroPlacement 工作有自己的批評,但也許最重要的是它沒有使用在其他芯片設計上預訓練的神經網絡,從而剝奪了他們方法的主要優勢。他們在一封電子郵件中寫道,巡回訓練“與所介紹的任何其他方法不同,它可以從經驗中學習,在發現每個問題時更快地做出更好的布置”。
但在 MacroPlacement 實驗中,每個電路訓練結果都來自一個以前從未見過設計的神經網絡。“這類似于在每場比賽前重新設置 AlphaGo……然后在每次面對新對手時迫使它從頭開始學習如何下圍棋!”
Nature論文 的結果證實了這一點,表明系統學習的 TPU 電路塊越多,它為尚未見過的電路塊放置宏的效果就越好。它還表明,經過預訓練的強化學習系統可以在 6 小時內產生與未經訓練的系統在 40 小時后質量相同的位置。
新的爭議?
Kahng 的 ISPD 演講強調了Nature中描述的方法與開源版本 Circuit Training 中的方法之間的特殊差異。回想一下,作為預處理步驟,強化學習方法將標準cell聚集成簇。在 Circuit Training 中,該步驟由商業 EDA 軟件實現,該軟件輸出網表——哪些單元和宏相互連接——以及組件的初始布局。
根據 Kahng 的說法,即使作為該論文的審稿人,他也不知道Nature作品中存在初始位置。根據 Goldie 的說法,生成稱為物理綜合的初始布局是標準的行業慣例,因為它指導網表的創建,即宏布局器的輸入。Nature和 MacroPlacement中的所有布局方法都被賦予了相同的輸入網表。
初始放置是否以某種方式給強化學習帶來了優勢?是的,根據 Kahng 的說法。但從目前的實驗來看,尚不清楚影響到什么程度,甚至是為什么。他的團隊做了實驗,將三種不同的不可能的初始位置輸入到巡回訓練中,并將它們與真實位置進行比較。不可能版本的布線長度要差 7% 到 10%。
Mirhoseini 和 Goldie 反駁說,初始放置信息僅用于聚類標準單元,而強化學習不會放置這些信息。他們說,宏觀放置強化學習部分不知道初始放置。更重要的是,提供不可能的初始位置可能就像在標準cell聚類步驟中使用大錘一樣,因此給強化學習系統一個錯誤的獎勵信號。“Kahng 帶來了一個劣勢,而不是消除了優勢,”他們寫道。
Kahng 建議即將進行更精心設計的實驗。
繼續
這場爭論當然產生了后果,其中大部分是負面的。Chatterjee 與谷歌陷入了一場不當終止訴訟。Kahng 和他的團隊花費了大量時間和精力來重建多年前完成的工作——也許是好幾次。Goldie 和 Mirhoseini 花了數年時間抵御來自未發表和未經審閱的研究的批評,他們的目標是幫助改進芯片設計,離開了一個歷來難以吸引女性人才的工程領域。自 2022 年 8 月以來,他們一直在Anthropic致力于大型語言模型的強化學習。
如果有好的一面,那就是 Kahng 的努力為開放和可重復的研究提供了一個模型,并添加到公開可用的工具庫中,以推動芯片設計的這一部分向前發展。也就是說,Mirhoseini 和 Goldie 在谷歌的團隊已經制作了他們研究的開源版本,這在行業研究中并不常見,并且需要一些重要的工程工作。
盡管發生了所有這些戲劇性的事情,但在芯片設計中,機器學習的普遍使用,特別是強化學習,只是在傳播。甚至在開源之前,不止一個團隊能夠在 Morpheus 的基礎上進行構建。機器學習正在協助商業 EDA 工具不斷發展的方面,例如來自Synopsys和Cadence 的工具。
但是,如果沒有不愉快,所有的好事都可能發生。
編輯:黃飛
?








 工商網監
工商網監
評論