 電子發燒友App
電子發燒友App


J.P.Morgan的Quorum是在Ethereum的基礎上修改的,他們的理念之一就是,不要重復造輪子,小編很是認可這個理念。他們把Ethereum的PoW共識算法修改成了Raft算法,并且使用了etcd的Raft實現。由于Quorum是用于企業級分布式賬本和智能合約平臺,提供私有智能合約執行方案,是聯盟鏈方案,而不是公鏈。所以項目方認為,在這種場景下,拜占庭容錯是不需要的,分叉也是不會存在的。取而代之的是,需要更快的出塊時間和交易確認。這種共識算法還不會產生出“空快”,并且在需要的時候可以快速有效的創建出新塊。
在geth命令添加 --raft 選項,就會使得geth節點運行raft共識算法。
幾個基本概念
Raft和Ethereum都有自己的“節點”概念,但它們稍微有點兒不一樣。
在Raft里面,一個“節點”在正常操作的時候,要么是Leader,要么是Follower。在整個集群里面,只有一個Leader,所有其他的節點都要從這個Leader來獲取日志數據。這里還有一個Candidate的概念,不過僅僅是在Leader選舉期間才有。
但是在Ethereum里面卻沒有Leader和Follower這樣的概念,對于任何一個節點來說,都可以創建一個新塊(只要計算足夠快),這就類似于Raft里面的Leader。
在基于Raft的共識算法中,在Raft和Ethereum節點之間做了一對一的對應關系,每個Ethereum節點也是Raft節點,并且按照約定,Raft集群的Leader是產生新塊的唯一Ethereum節點。這個Leader負責將交易打包成一個區塊,但不提供工作量證明(PoW)。
在這里把Leader和產生新塊的節點綁定到一起的主要原因有兩點:第一是為了方便,因為Raft確保一次只有一個Leader,第二是為了避免從節點創建新塊到Leader的網絡跳轉,所有的Raft寫入操作都必須通過該跳轉。Quorum的實現關注Raft Leader的變化——如果一個節點成為Leader,它將開始產生新塊,如果一個節點失去Leader地位,它將停止產生新塊。
在Raft的Leader轉換期間,其中有一小段時間,有多個節點可能假定自己具有產生新塊的職責,本文稍后將更詳細地描述如何保持正確性。
Quorum使用現有的Etherum P2P傳輸層來負責在節點之間的通訊,但是只通過Raft的傳輸層來傳輸Block。這些Block是由Leader創造的,并從那里傳輸到集群的其余部分,總是以相同的順序通過Raft傳輸。
當Leader創建新塊時,不像在Ethereum中,塊被寫入數據庫并立即成為鏈的新Head,只在新塊通過Raft傳輸之后才插入塊或將其設置為鏈的新Head。所有節點都會在鎖定步驟中將鏈擴展到新的狀態,就好像是他們在Raft中同步日志。
從Ethereum的角度來說,Raft是通過實現 node/service.go 文件中的 Service 接口而集成的。一個獨立的協議可以通過這個 Service 接口,注冊到節點里面。
// quorum/cmd/geth/config.go
func makeFullNode(ctx *cli.Context) *node.Node {
if ctx.GlobalBool(utils.RaftModeFlag.Name) {
// 在這里判斷,如果是raft mode,則注冊raft service
RegisterRaftService(stack, ctx, cfg, ethChan)
}
}
func RegisterRaftService(stack *node.Node, ctx *cli.Context, cfg gethConfig, ethChan 《-chan *eth.Ethereum) {
// 在這里把raft service注冊到node里面去
if err := stack.Register(func(ctx *node.ServiceContext) (node.Service, error) {
// 調用raft.New創建raft service,這個RaftService實現了node.Service接口
return raft.New(ctx, ethereum.ChainConfig(), myId, raftPort, joinExisting, blockTimeNanos, ethereum, peers, datadir)
}); err != nil {
}
一筆交易的生命周期
現在,讓我們來看看一個典型的交易的生命周期
在任意一個節點上(挖礦者或者驗證者)
· 通過RPC接口向geth提交一筆交易
· 利用Ethereum現有的交易傳播機制,把交易廣播給所有的節點。同時,因為當前集群都被配置成為“靜態節點”模式,所以每一個交易都會被發送給集群中的所有節點
在挖礦者節點
· 挖礦節點接收到交易之后,通過把這個交易加入交易池(transaction pool)的方式加入到下一個block中
· 創建新塊的工作將會觸發一個NewMinedBlockEvent事件,Raft協議管理者通過訂閱了minedBlockSub來接收這個事件。在raft/handler.go文件中的minedBroadcastLoop方法會把這個新塊發送到ProtocolManager.proposeC channel.
下面是 NewMinedBlockEvent 事件的定義
// quorum/core/events.go
type NewMinedBlockEvent struct{ Block *types.Block }
下面的三個代碼塊展示了,訂閱事件,創建新塊的時候觸發事件,以及在接收端轉發這個事件。
// quorum/raft/handler.go
func (pm *ProtocolManager) Start(p2pServer *p2p.Server) {
pm.p2pServer = p2pServer
pm.minedBlockSub = pm.eventMux.Subscribe(core.NewMinedBlockEvent{})
pm.startRaft()
go pm.minedBroadcastLoop()
}
// quorum/miner/worker.go
func (self *worker) wait() {
for {
mustCommitNewWork := true
for result := range self.recv {
// Broadcast the block and announce chain insertion event
self.mux.Post(core.NewMinedBlockEvent{Block: block})
}
}
}
// quorum/raft/handler.go
func (pm *ProtocolManager) minedBroadcastLoop() {
for obj := range pm.minedBlockSub.Chan() {
switch ev := obj.Data.(type) {
case core.NewMinedBlockEvent:
select {
case pm.blockProposalC 《- ev.Block:
case 《-pm.quitSync:
return
}
}
}
}
· serveLocalProposals在這個channel的出口處等待接收這個新塊,它的任務是使用RLP的方式對這個block進行編碼并且提交給Raft協議。一旦這個新塊通過Raft的同步協議同步到了所有的節點,這個新塊就成為整個鏈的最新Head。下面的代碼塊展示了這個過程。
// quorum/raft/handler.go
func (pm *ProtocolManager) serveLocalProposals() {
for {
select {
case block, ok := 《-pm.blockProposalC:
size, r, err := rlp.EncodeToReader(block)
var buffer = make([]byte, uint32(size))
r.Read(buffer)
// blocks until accepted by the raft state machine
pm.rawNode().Propose(context.TODO(), buffer)
}
}
}
在任意一個節點上
· 到了這個時間點,Raft協議會達成共識并且把包含新塊的日志記錄添加到Raft日志之中。Raft完成這一步是通過Leader發送AppendEntries給所有的Follower,并且所有的Follower對這個消息進行確認。一旦Leader收到了超過半數的確認消息,它就通知每一個節點,這個新的日志已經被永久性的寫入日志。
· 這個新塊通過Raft傳輸到整個網絡之后,到達了eventLoop,在這里處理Raft的新日志項。他們從Leader通過pm.transport(rafthttp.Transport的一個instance)到達。
// quorum/raft/handler.go
func (pm *ProtocolManager) eventLoop() {
for {
select {
case 《-ticker.C:
// when the node is first ready it gives us entries to commit and messages
// to immediately publish
case rd := 《-pm.rawNode().Ready():
// 1: Write HardState, Entries, and Snapshot to persistent storage if they
// are not empty.
pm.raftStorage.Append(rd.Entries)
// 2: Send all Messages to the nodes named in the To field.
pm.transport.Send(rd.Messages)
// 3: Apply Snapshot (if any) and CommittedEntries to the state machine.
for _, entry := range pm.entriesToApply(rd.CommittedEntries) {
switch entry.Type {
case raftpb.EntryNormal:
var block types.Block
err := rlp.DecodeBytes(entry.Data, &block)
if pm.blockchain.HasBlock(block.Hash(), block.NumberU64()) {
} else {
pm.applyNewChainHead(&block)
}
pm.advanceAppliedIndex(entry.Index)
}
case 《-pm.quitSync:
return
}
}
}
· 下一步是applyNewChainHead會處理這個新塊。這個方法首先會檢查這個新塊是否擴展了鏈(比如:其parent是當前鏈的head)。如果這個新塊沒有擴展鏈,他會被簡單的忽略掉。如果這個新塊擴展了鏈,并且這個新塊是有效的,則會通過InsertChain把這個新塊寫入鏈中并且作為鏈的Head.
// quorum/raft/handler.go
func (pm *ProtocolManager) applyNewChainHead(block *types.Block) {
if !blockExtendsChain(block, pm.blockchain) {
headBlock := pm.blockchain.CurrentBlock()
pm.minter.invalidRaftOrderingChan 《- InvalidRaftOrdering{headBlock: headBlock, invalidBlock: block}
} else {
if existingBlock := pm.blockchain.GetBlockByHash(block.Hash()); nil == existingBlock {
if err := pm.blockchain.Validator().ValidateBody(block); err != nil {
panic(fmt.Sprintf(“failed to validate block %x (%v)”, block.Hash(), err))
}
}
_, err := pm.blockchain.InsertChain([]*types.Block{block})
}
}
// quorum/core/blockchain.go
func (bc *BlockChain) InsertChain(chain types.Blocks) (int, error) {
n, events, logs, err := bc.insertChain(chain)
bc.PostChainEvents(events, logs)
return n, err
}
· 通過發送一個ChainHeadEvent事件來通知所有的listener,這個新塊已經被接受了。因為下面這些原因,這個步驟是非常重要的:
從交易池(transaction pool)中刪除相關的交易
從speculativeChain的proposedTxes中刪除相關的交易
觸發requestMinting(在minter.go文件中)事件,通知節點準備創建新塊
// quorum/core/blockchain.go
func (bc *BlockChain) PostChainEvents(events []interface{}, logs []*types.Log) {
for _, event := range events {
switch ev := event.(type) {
case ChainEvent:
bc.chainFeed.Send(ev)
case ChainHeadEvent:
bc.chainHeadFeed.Send(ev)
case ChainSideEvent:
bc.chainSideFeed.Send(ev)
}
}
}
現在, 該交易在群集中的所有節點上都可用, 并且最終確認了。因為Raft保證了存儲在其日志中的條目的單一順序, 而且由于所提交的所有內容都保證保持不變, 所以沒有blockchain在Raft上生成的分叉。
鏈延長、競爭和糾錯
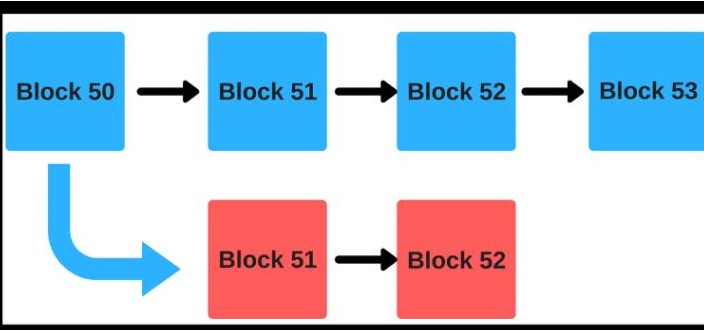
Raft負責達成共識, 有哪些區塊可以被鏈接受。在最簡單的情況下, 通過Raft的每個后續塊都成為新的鏈Head。
然而, 在一些比較極端的情況下, 可能會遇到一個新的塊, 已經通過Raft傳播到整個集群,但卻不能作為新的鏈Head。在這種情況下, 利用Raft的日志順序, 如果我們遇到一個塊, 其parent目前不是鏈的Head, 我們只是簡單地跳過這個日志條目。
最常見的情況是, 在Leader發生變化時, 最有可能觸發這種情況。領導者可以被認為是一個代理,這個代理應該創建新塊,這通常都是正確的, 并且只有一個單一的新塊創建者。但是不能依賴于一個新塊創建者的最大并發量來保持正確性。在這樣的過渡過程中, 兩個節點可能會在短時間內都會創建新塊。在這種情況下, 將會有一場競賽, 成功擴展鏈條的第一塊將會獲勝, 競賽的失敗者將被忽略。
請考慮下面的示例, 在這種情況下, Raft試圖延長鏈的日志項被表示為:
[ 0xa12345 Parent: 0xea097c ]
其中0xa12345是新塊的id, 0xea097c是其parent的id。這里初始的挖礦節點(節點1)被分區, 節點2作為后續挖礦節點接管挖礦工作。
新塊提交過程:
鏈的初始狀態:[ 0xa12345 Parent: 0xea097c ]
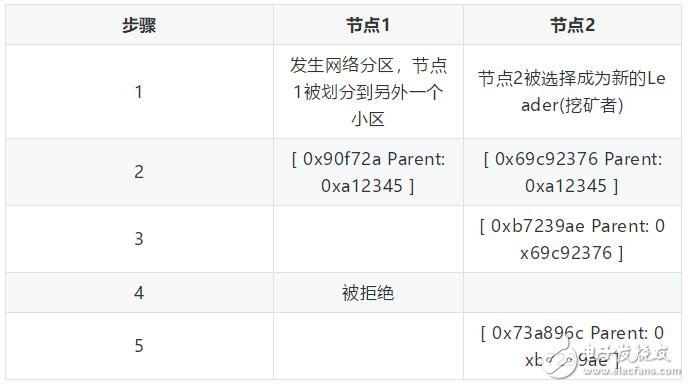
一旦網絡分區愈合, 在Raft層節點1將重新提交0x90f72a, 結果序列化日志可能看起來如下:
· 0xea097c Parent: 0xacaa - 挖礦成功
· [ 0xa12345 Parent: 0xea097c - 挖礦成功 ] (節點2; 競賽獲勝者)
· 0x69c92376 Parent: 0xa12345 - 挖礦成功
· 0xb7239ae Parent: 0x69c92376 - 挖礦成功
· [ 0x90f72a Parent: 0xa12345 - 挖礦失敗,沒有操作 ] (節點1; 競賽失敗者)
· 0x73a896c Parent: 0xb7239ae - 挖礦成功
由于被序列化后的“贏家”將會延長鏈, 所以“失敗者”將不會延長鏈, 因為它的parent(0xea097c)已經不是鏈的head了, 競賽“獲勝者”已經提前延長了同一個parent(0xa12345),然后0xb7239ae進一步延長了它。
請注意, 每個塊都被Raft接受并在日志中序列化, 并且這個失敗者的延長被“忽略”。從Raft的角度來看, 每個日志條目都是有效的, 但在Quorum-Raft的角度看, 將會選擇使用哪些條目作為有效條目, 并且在實際上將延長鏈。此鏈的延長邏輯是確定性的: 在群集中的每個節點上都會發生相同的精確行為, 從而保持blockchain同步。
還要注意Quorum的方法不同于Ethereum的“最長有效鏈”(LVC:Longest Valid Chain)機制。LVC用于在最終一致的網絡中解決分叉問題。因為Quorum使用Raft, blockchain的狀態是保持一致的。Raft設置中不能分叉。一旦一個塊被添加為新的鏈Head, 對于整個集群來說都是這樣的,而且它是永久性的。
創建新塊的頻率
默認情況下, 創建新塊的頻率是50ms。當新的交易來了, 將立即創建一個新塊(所以延遲時間很低), 但是新塊的創建時間至少也是上一個塊創建的50ms之后。這樣的頻率是在交易速度和延遲之間獲取一個平衡。
50ms這個頻率是可以通過參數--raftblocktime配置。
預測挖礦
Quorum的方法不同于Ethereum的方法之一,是引入了一個新的概念“預測挖礦”。對基于Raft的Quorum的共識算法來說, 這并不是嚴格要求的, 而是一個優化, 它提供了降低創建新塊之間的時間延遲,或者說是更快的最終確認時間。
通過基于Raft的共識算法,新塊可以更快的成為鏈的Head。如果在創建新塊之前,所有的節點都同步等待上一個塊成為新的鏈頭,那么這個集群收到的任何交易都需要更多的時間才能使其進入鏈。
在預測挖礦中,我們允許一個parent塊通過Raft進入塊鏈之前,創建一個新塊。
由于這個過程可能重復發生,這些塊(每個都有一個對其父塊的引用)可以形成一種鏈。稱之為“預測鏈”。
在預測鏈形成的過程中,Quorum會持續跟蹤交易池中的事務子集,這些事務子集已經加入到塊中,只是這些塊還沒有放入到鏈中而是在預測鏈中)。
由于競賽的存在(如我們上面所詳細描述的),有可能預測鏈的中間某些區塊最終不會進入到鏈。在這種情況下,將會觸發一個InvalidRaftOrdering事件,并且相應地清理預測鏈的狀態。
這些預測鏈的長度目前還沒有限制,但在未來可能會增加對這一點的支持。
預測鏈的狀態
· head:這是最后一個創建的預測區塊,如果最后一個創建的block已經包含在區塊鏈中,這個值可以是nil
· proposedTxes:這是一個交易的集合,這些交易已經被打包到一個block中,并且這個block已經提交到Raft協議,但是這個block還沒有加入到鏈中
· unappliedBlocks:這是一個block的隊列,這些block已經提交到Raft協議,但是這些block還沒有加入到鏈中
· 當創建一個新塊的時候,這個新塊會被添加到這個隊列的尾部
· 當一個新塊被添加到鏈中以后,accept方法會被調用來把這個blokc從這個隊列刪除
· 當一個InvalidRaftOrdering事件發生的時候,通過從隊列的“最新的末尾”彈出最新的塊,直到找到無效的塊來展開隊列。我們必須重復地刪除這些“新”的預測塊,因為它們都依賴于一個沒有被包括在鏈中的block。
· expectedInvalidBlockHashes:在無效塊上建立的一組塊,但尚未通過Raft傳遞。這些塊要被刪除。當這些不延伸的塊通過Raft回來時,會把它們從預測鏈中移除。在不應該去嘗試預測鏈的時候,這一套方法就成為一種保護機制。
Raft傳輸層
Quorum通過Raft(etcd實現)內置的HTTP傳輸方法來傳輸block,從理論上來說,使用Ethereum的P2P網絡來作為Raft的傳輸層也是可以的。在實際的測試中,在高負載的情況下,Raft內置的HTTP傳輸方法比geth中內置的P2P網絡更為可靠。
在缺省情況下,Quorum監聽50400端口,這個也可以通過--raftport參數來做配置。
缺省的peers數量被設置為25。最大的peers數量可以通過--maxpeers來做配置,這個數量也是整個集群的數量。
初始化配置
當前基于Raft的共識算法,要求所有的初始節點都要配置為把前面所有的其他節點都作為靜態節點對待。對每一個節點來說,這些靜態節點的URI必須包含在raftport參數中,比如:enode://abcd@127.0.0.1:30400?raftport=50400
注意:所有節點的static-nodes.json文件中,enodes的順序必須保持一致。
想要從一個集群中刪除一個節點,那就進入JavaScript控制臺,執行命令:raft.removePeer(raftId),這個raftId就是你想要刪除的節點id。對于初始節點來說,這個id是在靜態節點列表中的索引值,這個索引值是從1開始的(不是從0開始)。一旦一個節點從集群中刪除了,這個是永久性的刪除。這個raftId在將來也不能夠使用。如果這個節點想要再次加入集群,那么它必須使用一個新的raftId。
想要把一個節點加入到集群,那就進入JavaScript控制臺,執行raft.addPeer(enodeId)命令。就像enode ID需要包含在靜態節點JSON文件中一樣,這個enode ID也必須要包含在raftport參數中。這個命令會分配一個新的raftID,并且返回。成功執行addPeer命令之后,就可以啟動一個新的geth節點,并且添加參數 --raftjoinexisting RAFTID
小結
通過這篇文章對Quorum共識機制的介紹,我們可以看到,Quorum對于適合于自己的目標場景有著非常清晰的理解和認識,把Ethereum原生的PoW修改成Raft,從而打造出適用于企業級的聯盟鏈平臺。










 工商網監
工商網監
評論