 電子發(fā)燒友App
電子發(fā)燒友App


最近非常火的區(qū)塊鏈技術(shù)對(duì)于大家來說應(yīng)該并不陌生。但是很多人只是了解區(qū)塊鏈技術(shù)的一些概念,對(duì)其底層的一些技術(shù)實(shí)現(xiàn)原理可能不是很了解。這篇文章會(huì)向你介紹區(qū)塊鏈底層采用的通信網(wǎng)絡(luò)技術(shù)及其網(wǎng)絡(luò)中節(jié)點(diǎn)間的通信協(xié)議。
區(qū)塊鏈的底層網(wǎng)絡(luò)技術(shù)采用的是peer-to-peer網(wǎng)絡(luò),簡(jiǎn)稱P2P網(wǎng)絡(luò)。這是一種分布式網(wǎng)絡(luò)通信技術(shù),又稱 “對(duì)等網(wǎng)絡(luò)”。與傳統(tǒng)的客戶端/服務(wù)器端(client/server, C/S)結(jié)構(gòu)不同的是,在P2P網(wǎng)絡(luò)中各個(gè)節(jié)點(diǎn)之間沒有主從之分,地位都是對(duì)等的,每一個(gè)節(jié)點(diǎn)既可以是服務(wù)器端也可以是客戶端。
P2P網(wǎng)絡(luò)根據(jù)其路由查詢結(jié)構(gòu)可以分為四種類型,分別是集中式、純分布式、混合式和結(jié)構(gòu)化模型。這四種類型也代表著P2P網(wǎng)絡(luò)技術(shù)的四個(gè)發(fā)展階段。
其中,比特幣采用的身世混合式,而現(xiàn)今公鏈大多采用的是結(jié)構(gòu)化類型。在結(jié)構(gòu)化網(wǎng)絡(luò)的具體實(shí)現(xiàn)上,大都采用DHT(Distributed Hash Table, 分布式哈希表)算法的思想。基于DHT算法思想的具體實(shí)現(xiàn)方案有Chord、Pastry、CAN和Kademlia等算法。其中Kademlia算法是以太坊網(wǎng)絡(luò)使用的算法,本文中我們將對(duì)其進(jìn)行詳細(xì)描述。
比特幣網(wǎng)絡(luò)
區(qū)塊鏈技術(shù)最早的使用是在比特幣中,前面我們也說到了,比特幣網(wǎng)絡(luò)采用的結(jié)構(gòu)是混合式網(wǎng)絡(luò)。
比特幣網(wǎng)絡(luò)節(jié)點(diǎn)有四個(gè)功能,分別是:錢包、挖礦、區(qū)塊鏈數(shù)據(jù)庫(kù)、網(wǎng)絡(luò)路由。這四大功能并不是比特幣中所有節(jié)點(diǎn)都包含,不同類型的節(jié)點(diǎn)只包含部分功能,只有比特幣核心(Bitcoin Core)節(jié)點(diǎn)才會(huì)包含所有的這四個(gè)功能。
依據(jù)其所包含的功能不同節(jié)點(diǎn)的類型也不同,但是所有的節(jié)點(diǎn)都會(huì)包含路由功能,因?yàn)樗械墓?jié)點(diǎn)都要參與校驗(yàn)和廣播(傳播交易和區(qū)塊信息),并且發(fā)現(xiàn)和維持與其他節(jié)點(diǎn)的連接。
除此之外,一些節(jié)點(diǎn)包含完整的區(qū)塊鏈數(shù)據(jù)庫(kù),數(shù)據(jù)庫(kù)中包含所有的交易數(shù)據(jù),這類節(jié)點(diǎn)被稱為 “全節(jié)點(diǎn)(Full Block Chain Node)”。全節(jié)點(diǎn)可以獨(dú)立自主的校驗(yàn)所有交易。
還有一些節(jié)點(diǎn)只包含了部分區(qū)塊鏈數(shù)據(jù),一般只包含區(qū)塊頭,這類節(jié)點(diǎn)通過“簡(jiǎn)易支付驗(yàn)證(SPV)”的方式完成對(duì)交易的驗(yàn)證,該類節(jié)點(diǎn)被稱為“SPV節(jié)點(diǎn)”或者“輕量級(jí)節(jié)點(diǎn)”。
礦工節(jié)點(diǎn)是通過在特殊的設(shè)備上面運(yùn)行工作量證明(proof-of-work)算法的方式(挖礦)來相互競(jìng)爭(zhēng)的生成新的區(qū)塊。
礦工節(jié)點(diǎn)中有些節(jié)點(diǎn)是全節(jié)點(diǎn),被稱為“獨(dú)立礦工(Solo Miner)”,另外一些礦工節(jié)點(diǎn)則需要依賴礦池服務(wù)器維護(hù)的全節(jié)點(diǎn)進(jìn)行挖礦工作,這類礦工被稱為“礦池礦工(Pool Miner)”,礦池礦工與礦池服務(wù)器形成礦池(Mining Pool),這是一個(gè)局部的集中式網(wǎng)絡(luò)。它們之間通過特殊的礦池協(xié)議進(jìn)行通信。
目前主流的礦池協(xié)議是Stratum協(xié)議。錢包功能一般是幫助用戶來查看自己的余額、管理公私鑰對(duì)以及發(fā)起交易,在比特幣網(wǎng)絡(luò)中除了比特幣核心錢包是全節(jié)點(diǎn)之外,大部分的錢包都是輕量級(jí)節(jié)點(diǎn)。
一個(gè)包含了各種節(jié)點(diǎn),不同節(jié)點(diǎn)之間運(yùn)行著比特幣主網(wǎng)絡(luò)協(xié)議、Stratum網(wǎng)絡(luò)協(xié)議和其他礦池網(wǎng)絡(luò)協(xié)議的比特幣擴(kuò)展網(wǎng)絡(luò)如下圖所示:
以太坊網(wǎng)絡(luò)
以太坊作為新一代以區(qū)塊鏈作為底層技術(shù)的平臺(tái),在很多方面與比特幣很類似,其節(jié)點(diǎn)同樣具有錢包、挖礦、區(qū)塊鏈數(shù)據(jù)庫(kù)和路由四大功能、同樣也是由于節(jié)點(diǎn)包含不同的功能而將其分為不同的類型、同樣除了主網(wǎng)絡(luò)之外還存在著許多的擴(kuò)展網(wǎng)絡(luò)。但是,與比特幣不同的是其底層網(wǎng)絡(luò)結(jié)構(gòu),比特幣主網(wǎng)的P2P網(wǎng)絡(luò)是無結(jié)構(gòu)的,而以太坊使用P2P網(wǎng)絡(luò)是有結(jié)構(gòu)的,其P2P網(wǎng)絡(luò)通過Kademlia(簡(jiǎn)稱Kad)算法來實(shí)現(xiàn)。Kad算法作為DHT(分布式哈希表)技術(shù)的一種,可以在分布式環(huán)境下實(shí)現(xiàn)快速而又準(zhǔn)確的路由和定位數(shù)據(jù)的功能。下面我們著重講一下Kad算法的基本內(nèi)容。
Kad算法作為一種分布式數(shù)據(jù)存儲(chǔ)及路由發(fā)現(xiàn)算法,因其具有簡(jiǎn)單性、靈活性、安全性的特點(diǎn),被以太坊用作底層P2P網(wǎng)絡(luò)的主要算法。下面我們將通過一個(gè)例子來形象的說明Kad算法的主要內(nèi)容及其運(yùn)行過程。
問題描述與場(chǎng)景假設(shè)
我們假設(shè)這樣一個(gè)場(chǎng)景:有若干圖書供同學(xué)們共享,為了公平起見每個(gè)人保存其中的幾本,如果你想要看其他的書,就需要向保存這本書的學(xué)生來借。那么問題是我們?cè)趺茨苷业奖4嬷@本書的學(xué)生呢?如果一個(gè)一個(gè)去問的話,效率顯然極低。將這個(gè)問題放到P2P網(wǎng)絡(luò)中,就是一個(gè)節(jié)點(diǎn)如果需要某個(gè)資源,它怎么獲取這個(gè)資源?怎么快速地找到存儲(chǔ)該資源的節(jié)點(diǎn)?
節(jié)點(diǎn)信息
就像我們?cè)趯W(xué)校中對(duì)每一個(gè)學(xué)生有著唯一的標(biāo)識(shí)一樣,在Kad算法中給每個(gè)節(jié)點(diǎn)設(shè)置了幾個(gè)屬性來唯一標(biāo)識(shí)一個(gè)節(jié)點(diǎn),分別是:節(jié)點(diǎn)ID、IP地址、端口號(hào)。對(duì)應(yīng)到我們的例子中就是:節(jié)點(diǎn)ID對(duì)應(yīng)著學(xué)生的學(xué)號(hào),IP地址和端口號(hào)對(duì)應(yīng)著學(xué)生的聯(lián)系方式(電話號(hào)或者家庭住址)。
每個(gè)學(xué)生(節(jié)點(diǎn))手中有以下信息:
· 分配給其的圖書信息(分配到節(jié)點(diǎn)上的資源信息)。這里的信息指的是書名的hash值和書本的內(nèi)容(對(duì)于節(jié)點(diǎn)資源中理解為資源的索引和資源的內(nèi)容,將其以《key, value》的形式存儲(chǔ)在節(jié)點(diǎn)上)。
· 一個(gè)通訊錄,里面存儲(chǔ)著若干條記錄,每條記錄是某本書的書名hash值和存儲(chǔ)這本書的學(xué)生的學(xué)號(hào)和聯(lián)系方式(一張路由表,每個(gè)路由項(xiàng)里面存儲(chǔ)著某個(gè)資源的索引和存儲(chǔ)該資源的節(jié)點(diǎn)信息,在Kad算法中,這個(gè)路由表稱為“K-bucket”,后面我們將對(duì)“K-bucket”進(jìn)行詳細(xì)的介紹)。值得注意的是,這里每個(gè)學(xué)生存儲(chǔ)的只是一部分同學(xué)的聯(lián)系方式(節(jié)點(diǎn)的路由表中只存儲(chǔ)著一部分節(jié)點(diǎn)的信息)。
資源存儲(chǔ)及查找
那么問題來了,我們應(yīng)該如何將書本分發(fā)給各個(gè)同學(xué)呢(將資源分配到節(jié)點(diǎn)上)?
在Kad算法中它是這樣做的:將每本書的書名做一個(gè)hash計(jì)算,將得到書名的hash值作為書本的索引,然后在書本的索引與節(jié)點(diǎn)ID之間建立一個(gè)映射。如果一本書的hash值為000110,那么這本書就會(huì)被分配給學(xué)號(hào)為000110的學(xué)生。(這就要求hash算法的值域和節(jié)點(diǎn)ID的取值范圍是一致的,在以太坊中,節(jié)點(diǎn)ID的是256位二進(jìn)制。因?yàn)橐蕴恢胁捎玫膆ash算法是sha-3,結(jié)果長(zhǎng)度為256位二進(jìn)制)
那這里就會(huì)有人問了,萬一某一個(gè)學(xué)生聯(lián)系不上了(節(jié)點(diǎn)下線或者退出網(wǎng)絡(luò))那么豈不是他保存的書(資源)就沒有辦法獲得了?為了解決這個(gè)問題,Kad算法采取的方法是將這本書的副本存儲(chǔ)在學(xué)號(hào)與000110最接近的若干位學(xué)生手里,這樣學(xué)號(hào)為000111、000101等若干學(xué)生手里也會(huì)有這本書(在節(jié)點(diǎn)中就是將相同的資源存儲(chǔ)在與目標(biāo)節(jié)點(diǎn)ID最接近的幾個(gè)節(jié)點(diǎn)上)。
當(dāng)你需要找到這本書的時(shí)候,你只要對(duì)書名進(jìn)行hash,就可以知道你要找的是哪一(幾)個(gè)學(xué)生的聯(lián)系方式了(對(duì)于節(jié)點(diǎn)中資源來說,我們只需要計(jì)算得到資源索引就可以知道要找哪一個(gè)或者哪幾個(gè)節(jié)點(diǎn)了)。
節(jié)點(diǎn)定位
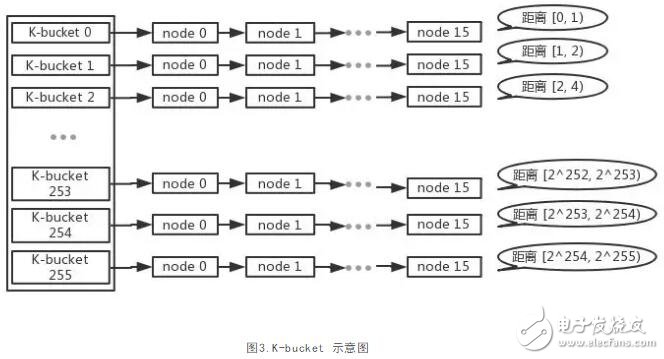
我們已經(jīng)知道應(yīng)該找哪一(幾)個(gè)學(xué)生來獲得圖書,那么接下來的問題就是怎么找到他們的聯(lián)系方式。這里我們對(duì)Kad算法中的路由表--“K-bucket”進(jìn)行介紹,作為一張路由表,K-bucket里面存儲(chǔ)的就是節(jié)點(diǎn)的路由信息,但是和一般的路由表不一樣的是,在K-bucket中是通過距離來對(duì)節(jié)點(diǎn)進(jìn)行分類的,如圖3所示。這里提到了節(jié)點(diǎn)間的距離問題。我們先來看下在kad算法中是如何計(jì)算兩節(jié)點(diǎn)間的距離的。
Kad算法中節(jié)點(diǎn)間的距離是邏輯距離,這個(gè)邏輯距離是通過對(duì)節(jié)點(diǎn)ID進(jìn)行異或來計(jì)算的。目標(biāo)節(jié)點(diǎn)到本節(jié)點(diǎn)的距離在[2(i-1), 2i)范圍內(nèi)時(shí),該節(jié)點(diǎn)被歸為 “K-bucket i”。比如節(jié)點(diǎn)ID為000111的節(jié)點(diǎn)與節(jié)點(diǎn)ID為000110、000011的節(jié)點(diǎn)之間的距離計(jì)算為:000111 ? 000110 = 000001(十進(jìn)制1)、000111 ? 000011 = 000100(十進(jìn)制4)。那么按照上述的算法就是,在節(jié)點(diǎn)ID為000111的K-bucket中,節(jié)點(diǎn)ID為000110的節(jié)點(diǎn)被分配到“K-bucket 1”中、節(jié)點(diǎn)ID為000011的節(jié)點(diǎn)被分配到“K-bucket 3”中。
其實(shí)這種使用異或來計(jì)算距離的方式,相當(dāng)于將整個(gè)網(wǎng)絡(luò)拓?fù)浣M織成一顆二叉前綴樹如圖4所示。這里所有的節(jié)點(diǎn)都分布在二叉前綴樹的葉子節(jié)點(diǎn)上,這種組織形式相當(dāng)于按其節(jié)點(diǎn)ID的每一位對(duì)節(jié)點(diǎn)距離進(jìn)行分類。
以圖中的編號(hào)為110的節(jié)點(diǎn)為例,因?yàn)楣?jié)點(diǎn)000、001、010是第三位(從右往左數(shù))與110不同,因此這三個(gè)節(jié)點(diǎn)就被分配到110 的“K-bucket 3”中,節(jié)點(diǎn)ID為100、101的節(jié)點(diǎn)因?yàn)槭堑诙唬◤挠彝髷?shù))與110不同,因此這兩個(gè)節(jié)點(diǎn)就被分配到110 的“K-bucket 2”中,最后節(jié)點(diǎn)ID為111的節(jié)點(diǎn)因?yàn)槭堑谝晃唬◤挠彝髷?shù))與110 不同,因此它就被安排到110的“K-bucket 1”中。
回到以太坊中,在前面已經(jīng)提到了每個(gè)節(jié)點(diǎn)ID是256位長(zhǎng),因此在以太坊中的節(jié)點(diǎn)的K-bucket大小分配為256行每行最多存儲(chǔ)16節(jié)點(diǎn)的路由信息。
通過前面的內(nèi)容我們已經(jīng)知道了找到另一個(gè)學(xué)生聯(lián)系方式(節(jié)點(diǎn)間的距離計(jì)算)的方法以及每個(gè)學(xué)生存儲(chǔ)的通訊錄是怎樣的的結(jié)構(gòu)(節(jié)點(diǎn)中K-bucket的存儲(chǔ)結(jié)構(gòu))。那我們就來找一本書來看一下在Kad算法中查找某一確定節(jié)點(diǎn)的方式是怎樣的。
學(xué)號(hào)為000111 的A同學(xué)想要找一本名叫《西游記》的書(節(jié)點(diǎn)ID為000111的節(jié)點(diǎn)想要找到某一個(gè)特定的資源),他首先通過對(duì)書名計(jì)算hash值來得到這本書的索引(得到資源的索引),經(jīng)過計(jì)算得到《西游記》的hash值為001011,那么他就知道這本書被保存在學(xué)號(hào)為001011的B學(xué)生手里。接著,A同學(xué)就計(jì)算與這個(gè)學(xué)生的距離來查找他的通訊錄(節(jié)點(diǎn)計(jì)算目標(biāo)節(jié)點(diǎn)與自己的距離,在K-bucket中查找否有目標(biāo)節(jié)點(diǎn)),經(jīng)過異或計(jì)算:000111 &001011 = 001100(十進(jìn)制12),經(jīng)過計(jì)算發(fā)現(xiàn)這個(gè)距離12位于[23, 24)這個(gè)區(qū)間中,因此A同學(xué)就去他的通訊錄的第4行去找有沒有B同學(xué)的聯(lián)系方式:
· 如果有--就直接聯(lián)系B向他借書;
· 如果沒有--就隨便找一個(gè)也在第4行的C同學(xué)與其取得聯(lián)系,讓C同學(xué)在自己的通訊錄中使用同樣的方法找一下是否有B同學(xué)的聯(lián)系方式。這里這樣做的原因是C同學(xué)學(xué)號(hào)的第四位(從右往左數(shù))一定與B同學(xué)學(xué)號(hào)的第四位一樣,因此邏輯上C同學(xué)距離B同學(xué)的距離一定比A同學(xué)距離B同學(xué)要近。那么就會(huì)出現(xiàn)兩種情況:
--如果C同學(xué)有B同學(xué)聯(lián)系方式,那么他就將B同學(xué)的聯(lián)系方式告訴A同學(xué)。
--如果沒有,那么C同學(xué)就將與B同學(xué)在通訊錄的同一行的另一位D同學(xué)的聯(lián)系方式告訴A同學(xué),之后A同學(xué)在將D同學(xué)的聯(lián)系方式存儲(chǔ)起來后與D同學(xué)聯(lián)系,進(jìn)行下一步查找。以此遞歸下去直到找到B同學(xué)為止。
這時(shí)有人就會(huì)問,上面提到一本書不是不僅僅保存在一個(gè)同學(xué)手里嗎?我們?yōu)槭裁捶且驼疫@一個(gè)同學(xué)?這是因?yàn)樯厦嫖覀兠枋龅氖峭ㄟ^一個(gè)確定的節(jié)點(diǎn)ID來查找另一個(gè)節(jié)點(diǎn)的過程,對(duì)應(yīng)著Kad算法中的FIND_NODE指令,當(dāng)然問題中提到的做法是Kad算法中的另一個(gè)指令FIND_VALUE。這個(gè)指令是通過資源的索引值來搜索指定的資源,其操作過程與FIND_NODE非常類似,最后終止的條件就是有某一個(gè)節(jié)點(diǎn)返回了我們要查找的資源數(shù)據(jù)即可。
值得一提的是,K-bucket的這種更新機(jī)制是只有老的節(jié)點(diǎn)失效后,才會(huì)將新節(jié)點(diǎn)加入到K-bucket中,這樣做會(huì)保證在線時(shí)間長(zhǎng)的節(jié)點(diǎn)會(huì)有更大概率被保留,增加了網(wǎng)絡(luò)的穩(wěn)定性,避免網(wǎng)絡(luò)中節(jié)點(diǎn)因大量新節(jié)點(diǎn)加入更新K-bucket而出現(xiàn)拒絕服務(wù)的情況。
總結(jié)
以上就是本文分享的所有內(nèi)容,我們先介紹了P2P網(wǎng)絡(luò)的基本知識(shí),然后介紹了比特幣網(wǎng)絡(luò)的相關(guān)內(nèi)容,最后著重介紹了以太坊網(wǎng)絡(luò)中Kademlia算法的相關(guān)內(nèi)容。
Trias中的goosip協(xié)議與Kad算法比較相關(guān)。相對(duì)于我們今天講的Kad算法來說,二者對(duì)應(yīng)的層面是不同的,Kad算法更接近底層,而goosip協(xié)議偏高層一點(diǎn),底層Kad算法在開始將節(jié)點(diǎn)的路由表(K-bucket)創(chuàng)建好為goosip協(xié)議做準(zhǔn)備,當(dāng)goosip協(xié)議挑選a個(gè)節(jié)點(diǎn)進(jìn)行廣播同步信息時(shí),Kad算法可以保證這a個(gè)節(jié)點(diǎn)都收到消息并將其存儲(chǔ)下來。










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論