C10K到C10M高性能網絡的實踐分析
大小:0.6 MB 人氣:0 2017-10-12 需要積分:1


標簽:cpu(204887)
C10K時代的問題與優化手段首先帶大家回顧一下當年C10K場景中遇到的問題以及為了解決我們單機下高并發的承載能力所做的改進。在當時的年代,國內互聯網的普及程度相對較低,C10K并沒有給當時中國的互聯網環境帶來太大沖擊,但是在全球互聯網環境下大家開始意識到這個問題。為了解決該問題,首先的研究方向就是IO模型的優化,逐漸解決了C10K的問題。
epoll、kqueue、iocp就是IO模型優化的一些最佳實踐,這幾種技術實現分別對應于不同的系統平臺。以epoll為例,在它的基礎上抽象了一些開發框架和庫,為廣大軟件開發者在軟件開發帶來了便利,比如libevent、libev等。隨著當年在IO模型上的革命,衍生出了很多至今為止我們都在大量使用的優秀開源軟件,比如nginx、haproxy、squid等,通過大量的創新、實踐和優化,使我們在今天能夠很輕易地解決一個大并發壓力場景下的技術問題。
這里簡單列了幾點,較為常用的優化技術手段。
CPU親和性&內存局域性
目前我們使用的服務器主要是多路、多核心的x86平臺。用于運行我們的軟件代碼,在很多場景的業務需求下,都會涉及一定并發任務,無論是多進程模型還是多線程模型,都要把所有的調度任務交給操作系統,讓操作系統幫我們分配硬件資源。我們常用的服務器操作系統都屬于分時操作系統,調度模型都盡可能的追求公平,并沒有為某一類任務做特別的優化,如果當前系統僅僅運行某一特定任務的時候,默認的調度策略可能會導致一定程度上的性能損失。我運行一個A任務,第一個調度周期在0號核心上運行,第二個調度周期可能就跑到1號核心上去了,這樣頻繁的調度可能會造成大量的上下文切換,從而影響到一定的性能。
數據局域性是同樣類似的問題。當前x86服務器以NUMA架構為主,這種平臺架構下,每個CPU有屬于自己的內存,如果當前CPU需要的數據需要到另外一顆CPU管理的內存獲取,必然增加一些延時。所以我們盡可能的嘗試讓我們的任務和數據在始終在相同的CPU核心和相同的內存節點上,Linux提供了sched_set_affinity函數,我們可以在代碼中,將我們的任務綁定在指定的CPU核心上。一些Linux發行版也在用戶態中提供了numactl和taskset工具,通過它們也很容易讓我們的程序運行在指定的節點上。
RSS、RPS、RFS、XPS
這些技術都是近些年來為了優化Linux網絡方面的性能而添加的特性,RPS、RFS、XPS都是Google貢獻給社區,RSS需要硬件的支持,目前主流的網卡都已支持,即俗稱的多隊列網卡,充分利用多個CPU核心,讓數據處理的壓力分布到多個CPU核心上去。RPS和RFS在linux2.6.35的版本被加入,一般是成對使用的,在不支持RSS特性的網卡上,用軟件來模擬類似的功能,并且將相同的數據流綁定到指定的核心上,盡可能提升網絡方面處理的性能。XPS特性在linux2.6.38的版本中被加入,主要針對多隊列網卡在發送數據時的優化,當你發送數據包時,可以根據CPU MAP來選擇對應的網卡隊列,低于指定的kernel版本可能無法使用相關的特性,但是發行版已經backport這些特性。
IRQ 優化
關于IRQ的優化,這里主要有兩點,第一點是關于中斷合并。在比較早期的時候,網卡每收到一個數據包就會觸發一個中斷,如果小包的數據量特別大的時候,中斷被觸發的數量也變的十分可怕。大部分的計算資源都被用于處理中斷,導致性能下降。后來引入了NAPI和Newernewer NAPI特性,在系統較為繁忙的時候,一次中斷觸發后,接下來用輪循的方式讀取后續的數據包,以降低中斷產生的數量,進而也提升了處理的效率。第二點是IRQ親和性,和我們前面提到了CPU親和性較為類似,是將不同的網卡隊列中斷處理綁定到指定的CPU核心上去,適用于擁有RSS特性的網卡。
這里再說說關于網絡卸載的優化,目前主要有TSO、GSO、LRO、GRO這幾個特性,先說說TSO,以太網MTU一般為1500,減掉TCP/IP的包頭,TCP的MaxSegment Size為1460,通常情況下協議棧會對超過1460的TCP Payload進行分段,保證最后生成的IP包不超過MTU的大小,對于支持TSO/GSO的網卡來說,協議棧就不再需要這樣了,可以將更大的TCPPayload發送給網卡驅動,然后由網卡進行封包操作。通過這個手段,將需要在CPU上的計算offload到網卡上,進一步提升整體的性能。GSO為TSO的升級版,不在局限于TCP協議。LRO和TSO的工作路徑正好相反,在頻繁收到小包時,每次一個小包都要向協議棧傳遞,對多個TCPPayload包進行合并,然后再傳遞給協議棧,以此來提升協議棧處理的效率。GRO為LRO的升級版本,解決了LRO存在的一些問題。這些特性都是在一定的場景下才可以發揮其性能效率,在不明確自己的需求的時候,開啟這些特性反而可能造成性能下降。
Kernel 優化
關于Kernel的網絡相關優化我們就不過多的介紹了,主要的內核網絡參數的調整在以下兩處:net.ipv4.參數和net.core.參數。主要用于調節一些超時控制及緩存等,通過搜索引擎我們能很容易找到關于這些參數調優的文章,但是修改這些參數是否能帶來性能的提升,或者會有什么弊端,建議詳細的閱讀kernel文檔,并且多做一些測試來驗證。
更深入的探索和實踐
接下來,我們著重了解如何去更進一步提升我們單機網絡吞吐以及網絡處理性能的技術和手段。
計算機硬件做為當前IT發展的重要組成部分。作為軟件開發者,我們更應該掌握這部分的內容,學習了解我們的軟件如何在操作系統中運行,操作系統又怎樣分配我們的硬件資源。
硬件
CPU
CPU是計算機系統中最核心、最關鍵的部件。在當前的x86服務器領域我們接觸到主要還是Intel的芯片。索性我們就以IntelXeon 2600系列舉例。
Intel Xeon 2600系列的CPU已經發布了3代,第4代產品2016年Q1也即將面市,圖例中均選取了4代產品最高端的型號。圖一為該系列CPU的核心數量統計,從第一代的8核心發展到即將上市的22核心,若干年前,這是很可怕的事情。裝配該型號CPU的雙路服務器,再開啟超線程,輕而易舉達到80多個核心。就多核處理器的發展歷程來講,核心數量逐年提升,主頻基本穩定在一定的范圍內,不是說單核主頻不再重要,而是說在當前的需求場景下,多核心才是更符合我們需求的處理器。
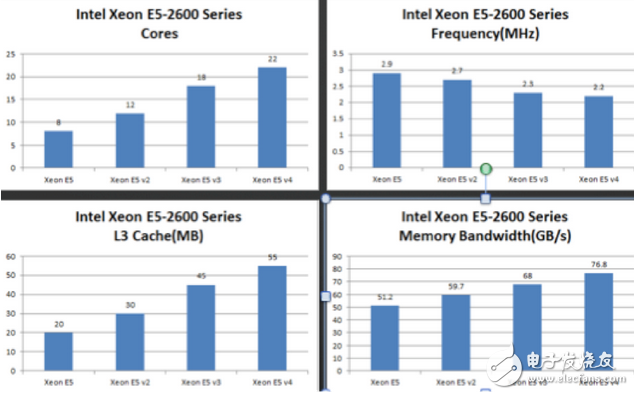
圖1
不僅僅是核心數量,像LLC緩存的容量、內存帶寬都有很大的提升,分別達到了55MB和76.8GB/s。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%