Tdsql數據庫水平拆分
隨著互聯網應用的廣泛普及,海量數據的存儲和訪問成為系統設計的瓶頸問題。對于大型的互聯網應用,每天幾十億的PV無疑對數據庫造成了相當高的負載。給系統的穩定性和擴展性造成了極大的問題。通過數據的切分來提高系統整體性能,擴充系統整體容量,橫向擴展數據層已經成為架構研發人員首選的方式。
2004年,騰訊開始逐步上線互聯網增值服務,業務量開始第一次爆炸。計費成為所有業務都需要的一個公共服務,不再是某個服務的專屬。業務量的爆炸給DB層帶來了巨大的壓力,原來的單機模式已經無法支撐。伴隨計費公共平臺的整合建設,在DB層開始引入分庫分表機制:針對大的表,按照某個key預先拆成n個子表,分布在不同的機器節點上。邏輯層在訪問DB時,自己根據分表邏輯將請求分發到不同的節點。在擴容時,需要手工完成子表數據的搬遷和訪問路由的修改。DB層在業務狂潮之下,增加各種工具和補丁來解決容量水平擴展的問題。2012年TDSQL項目立項,目標為金融聯機交易數據庫。
TDSQL(Tencent Distributed MySQL,騰訊分布式MySQL)是針對金融聯機交易場景推出的高一致性、分布式數據庫解決方案。產品形態為一個數據庫集群,底層基于MySQL,對外的功能表現上與MySQL兼容。截至2017年,TDSQL已在公司內部關鍵數據領域獲得廣泛應用,其中之一作為Midas(米大師)核心數據庫,經受了互聯網交易場景的考驗。Midas作為騰訊官方唯一數字業務支付平臺,為公司移動App(iOS、Android、Win phone等)、PC客戶端、Web等不同場景提供一站式計費解決方案。
水平拆分
TDSQL規定shardkey為表拆分的依據,即進行SQL查詢時,shardkey作為查詢字段指明該SQL發往哪個Set(數據分片)。在分庫分表之前需要Schedule初始化集群,我們這里稱作一個Group。在初始化Group時要確定最初的分片大小,因而需要確定準備幾套Set。例如,我們需要對邏輯表拆分成四張子表,需要我們在初始化集群時準備四個Set,同時指定每個Set的路由信息,并將這些路由信息寫入ZK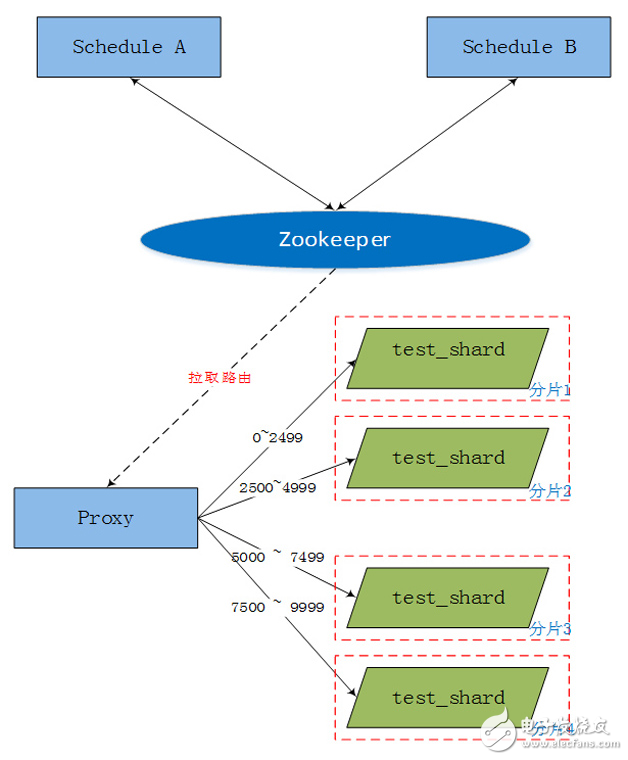
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%