MLBox庫的打開方式
MLbox的整個管道模型分為3個部分/子包:預處理、優化、預測。
下面我們來詳細學習這三個子包。
1.預處理
運行下面的指令使用該子包內的所有功能:
from mlbox.preprocessing import *
該子包提供了與兩個主要功能相關的部分:
閱讀和清理文件
此軟件包支持讀取各種各樣的文件格式,如csv,Excel,hdf5,JSON等,但在本文中,我們將主要看到最常見的“.csv”文件格式。 請按照以下步驟讀取csv文件:
Step1: 刪除未命名的列。
使用分隔符作為參數創建一個Reader類的對象。 “,”是csv文件的分隔符。
s=“,”
r=Reader(s) #initialising the object of Reader Class
Step2: 刪除重復項
列出練習和測試文件的路徑,并確定目標變量名稱。
path=[“path of the train csv file”,“path of the test csv file ”]
target_name=“name of the target variable in the train file”
Step3: 從“日期”列中提取月份,年份和星期
執行清理操作并創建清理后的練習和測試文件。
data=r.train_test_split(path,target_name)
刪除偏移變量
Step1:創建一個Drift_thresholder類的對象
dft=Drift_thresholder()
Step2:使用創建對象的fit_transform方法來刪除漂移變量。
data=dft.fit_transform(data)
2.優化
運行下面的指令使用該子包內的所有功能:
from mlbox.optimisation import *
優化是該庫的最強之處。從選擇正確的缺失值插補方法到XGBOOST模型的深度,超參數優化方法使用超快速(hyperopt)庫極速優化庫中的 所有內容。該庫創建了一個要優化的參數的高維空間,并選擇了降低數據分數的參數最佳組合。
以下是在MLBox庫中完成的四個廣泛優化的表格,其中有針對不同值優化的連字符術語。
Missing Values Encoder(ne)(缺失值編碼器)- numeric_strategy(數值策略)(估算的列是連續列,如平均值,中位數等), categorical_strategy(分類策略)(估算的列是分類列,如NaN值等)
Categorical Values Encoder(ce) -strategy(分類值編碼器策略)編譯分類變量的方法,例如標簽編碼,實體模型,隨機投影,實體嵌入)
Feature Selector(fs)– strategy (功能選擇器策略)(功能選擇的不同方法,如l1,方差,rf_feature_importance), threshold(閾值)(廢棄的功能的百分比)
Estimator(est)–strategy(估計器策略)(用作估計器的不同算法,例如,LightGBM,xgboost等),params(參數)(使用特定于算法的參數eg- max_depth,n_estimators等)
以創建一個要優化的超參數空間為例,在此先說明要優化的所有參數:
要使用的算法:LightGBM
LightGBM max_depth:[3,5,7,9]
LightGBM n_estimators: [250,500,700,1000]
功能選擇: [方差,l1,隨機森林功能重要性]
缺失值插補:數值(平均值,中位數),分類(NAN值)
分類值編碼器:標簽編碼,實體嵌入和隨機投影
創建超參數空間前,需要記住的是超參數是鍵和值對應的代碼字典,其中,值也是由語法給出的。
{“search”:strategy,“space”:list},其中策略可以是““choice” ”或“uniform”,列表是值的列表。
 使用以下幾步找出從上面選擇最佳組合的過程:
使用以下幾步找出從上面選擇最佳組合的過程:
Step1:創建一個Optimizer類的對象,它的參數是“scoring”和“n_folds”。 評分是優化超參數空間的指標,n_folds是交叉驗證的文件夾個數。
評分值

Step2:使用上面創建的對象的優化函數,它的參數分別是超參數空間、由train_test_split創建的字典、迭代次數。 此函數從超參數空間回歸最佳超參數。
best=opt.optimise(space,data,40)
3.預測
運行下面的指令安裝該子包內的所有功能:
from mlbox.prediction import *
該子包使用優化子包計算的最佳超參數來預測測試數據集。要對測試數據集進行預測,請執行以下步驟。
Step1:創建一個Predictor類的對象
pred=Predictor()
Step2:使用上面創建的對象的fit_predict方法,該方法以一組train_test_split創建的超參數和字典作為參數。
pred.fit_predict(best,data)
上述方法將功能重要性,偏移變量系數和最終預測保存到名為“save”的獨立文件夾中。
使用MLBox構建機器學習回歸器(Machine Learning Regressor)
現在,我們將使用超參數優化在7行代碼中構建機器學習分類器。以解決大型商場銷售問題(Big Marts sales problem)為例。下載練習和測試文件并將它們保存在一個文件夾中。在不查看數據的情況下,使用MLBox庫來提交首個預測。 你可以在下面的代碼中找到該問題的預測。

以下是LightGBM計算出的功能重要性的圖像。

偏移(Drift)的基本理解
偏移不常見,但卻很重要。關于它,應當用單獨的一篇文章去闡述, 但在此我將盡量把Drift_Thresholder的功能解釋清楚。
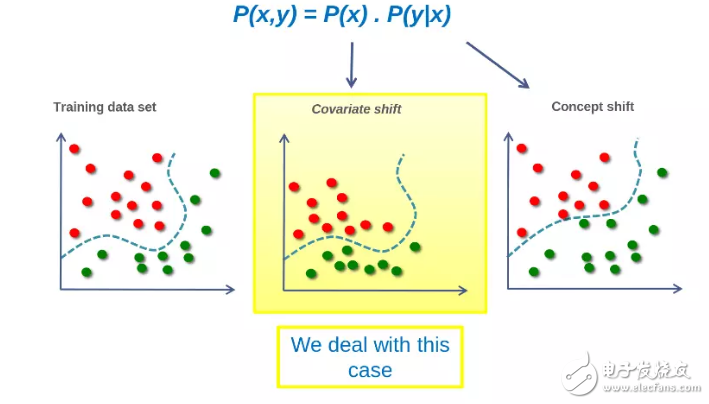
一般來說,我們預設練習和測試數據集是通過相同的生成算法或過程創建的。但這個預設過于強大,現實世界中并非如此,數據發生器或過程可能會發生改變。 例如,在銷售預測模型中,客戶行為隨時間變化,生成的數據將與用于創建模型的數據不同。 這就叫做偏移。
還需要注意的是,在數據集中,獨立功能和依賴功能都可能發生偏移。 當獨立功能發生變化時,稱為協變量;當獨立和相關功能之間的關系發生變化時,稱為概念偏移。 MLBox是處理協變量的。
?
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%