實例分析OLTP類系統數據結轉
業務系統在長期運行的過程中會積累大量的數據,這些數據有些是需要長期保存的,例如一些訂單數據,有些只需要短期保存,例如一些日志信息。業務數據一般都會有一個生命周期,生命周期內的我們叫生產數據,生命周期之外(即業務已經關閉)的叫歷史數據,我們這里提到的數據結轉,指的是將需要長期保存的歷史數據從生產庫遷移到歷史庫(轉),而將需要短期保存的數據定期刪除(結)。
我們已經進入了大數據時代,但在OLTP類系統中,關系型數據庫依然占據主導地位,在關系型數據庫中,如果不及時進行數據結轉,會嚴重影響系統的性能。
關系型數據庫單機容量有限,因此業界普遍的做法是進行垂直分庫和水平分片,一些大型互聯網企業由于業務量龐大,僅分片的集群規模就能達到上千節點,再加上分庫的集群,規模非常巨大。傳統的數據歸檔方法往往針對單庫操作,難以處理如此大規模集群的數據歸檔。
同時,在大型互聯網企業,每日的數據增長量非常大,數據結轉的頻率遠大于傳統行業,這些行業的IT系統往往是7*24小時不間斷提供服務,而且全天24小時的并發量都很大,因此數據結轉操作必須盡量減少對生產庫的性能影響。
為此,我們自主研發了數據結轉平臺,以解決大數據背景下的數據結轉問題。
二、 技術架構
2.1 設計要點
(1)盡量減少對生產庫的影響
數據結轉操作沒有復雜的業務邏輯,因此對數據庫性能的影響主要體現在IO方面,減少對生產庫的影響,最主要的就是減少對生產庫的IO操作。目前我們采用的方案是通過從庫查詢數據,將數據插入歷史庫,然后再從主庫中刪除,如圖1數據結轉邏輯圖所示,將查詢的IO操作轉嫁到從庫上,可以大大減輕對主庫的影響。為了保障數據庫的高可用,業內基本都采用了主從部署模式,因此這個方案具有很高的通用性。
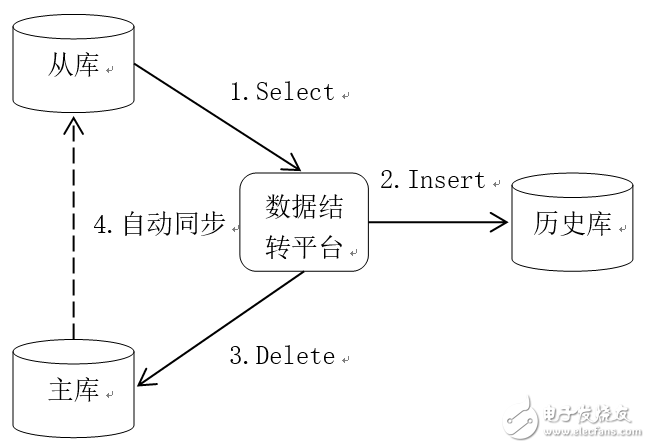
圖1 數據結轉邏輯圖
(2)支持分庫分片集群
我們希望數據結轉平臺的配置足夠簡單并且易于理解。在和用戶的溝通過程中,我們發現他們最強烈的需求就是分庫分片集群的數據結轉。傳統的單機數據結轉操作可以抽象描述為:將數據庫實例A中表B的歷史數據結轉到歷史庫C,用戶的配置主要有4個元素:生產庫實例A、結轉表B、結轉條件和歷史庫。對于大規模的分庫分片集群規模,如果采用傳統單機數據結轉的配置方式,每一個數據庫實例都要配置4個元素,配置量非常大。
在我們的方案中,按照圖2所示對數據庫集群進行劃分,將主庫、從庫、歷史庫作為一個結轉單元,對于分片的數據庫集群,表結構相同,我們將其作為一個分組,對于分庫的集群,表結構不同則劃分為不同的分組。用戶進行配置的時候不是面向一個數據庫實例,而是面向一個分組,數據結轉操作抽象為:結轉分組X中表B的歷史數據,用戶的配置元素有3個:分組X、結轉表B和結轉條件。分組信息僅需配置一次。這樣大大簡化了用戶的配置工作。
(3)支持水平擴展
由于數據庫集群規模較大,數據結轉平臺應該具備水平擴展能力。我們采用的方案是將數據結轉最核心的組件定時任務和數據庫操作(數據結轉執行器)獨立出來,進行分布式部署。如下圖3所示,
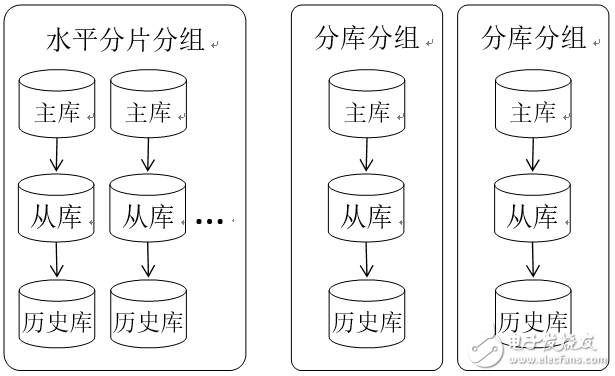
圖2 數據庫集群模型
配置中心為用戶的入口,用戶通過配置中心定義數據結轉任務,任務的關鍵屬性包括:觸發條件、執行條件、目標分組等,配置中心將結轉任務分發給代理程序,同時對代理程序的執行狀態進行監控。結轉任務的觸發條件配置在代理程序中的定時任務中,而執行條件和目標分組則作為數據結轉執行器的執行參數。通過水平擴展代理程序,我們對更多的數據庫進行結轉。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%