深度學習優(yōu)化技術實踐應用分析
自2012年Deep Learning的代表模型AlexNet在ImageNet大賽中力壓亞軍,以超過10個百分點的絕對優(yōu)勢奪得頭籌之后,依托于建模技術的進步、硬件計算能力的提升、優(yōu)化技術的進步以及海量數(shù)據(jù)的累積,Deep Learning在語音、圖像以及文本等多個領域不斷推進,相較于傳統(tǒng)作法取得了顯著的效果提升。工業(yè)界和學術界也先后推出了用于Deep Learning建模用途的開源工具和框架,包括Caffe、Theano、Torch、MXNet、TensorFlow、Chainer、CNTK等等。其中MXNet、TensorFlow以及CNTK均對于訓練過程提供了多機分布式支持,在相當大程度上解放了DL建模同學的生產(chǎn)力。但是,DL領域的建模技術突飛猛進,模型復雜度也不斷增加。從模型的深度來看,以圖像識別領域為例,12年的經(jīng)典模型AlexNet由5個卷積層,3個全連接層構成(圖1),在當時看來已經(jīng)算是比較深的復雜模型,而到了15年, 微軟亞洲研究院則推出了由151個卷積層構成的極深網(wǎng)絡ResNet(圖2);從模型的尺寸來看,在機器翻譯領域,即便是僅僅由單層雙向encoder,單層decoder構成的NMT模型(圖3),在阿里巴巴的一個內(nèi)部訓練場景下,模型尺寸也達到了3GB左右的規(guī)模。從模型的計算量來看,上面提到的機器翻譯模型在單塊M40 NVIDIA GPU上,完成一次完整訓練,也需要耗時近三周。
Deep Learning通過設計復雜模型,依托于海量數(shù)據(jù)的表征能力,從而獲取相較于經(jīng)典shallow模型更優(yōu)的模型表現(xiàn)的建模策略對于底層訓練工具提出了更高的要求。現(xiàn)有的開源工具,往往會在性能上、顯存支持上、生態(tài)系統(tǒng)的完善性上存在不同層面的不足,在使用效率上對于普通的算法建模用戶并不夠友好。阿里云推出的PAI(Platform of Artificial Intelligence)[18]產(chǎn)品則致力于通過系統(tǒng)與算法協(xié)同優(yōu)化的方式,來有效解決Deep Learning訓練工具的使用效率問題,目前PAI集成了TensorFlow、Caffe、MXNet這三款流行的Deep Learning框架,并針對這幾款框架做了定制化的性能優(yōu)化支持,以求更好的解決用戶建模的效率問題。
這些優(yōu)化目前都已經(jīng)應用在阿里巴巴內(nèi)部的諸多業(yè)務場景里,包括黃圖識別、OCR識別、機器翻譯、智能問答等,這些業(yè)務場景下的某些建模場景會涉及到幾十億條規(guī)模的訓練樣本,數(shù)GB的模型尺寸,均可以在我們的優(yōu)化策略下很好地得到支持和滿足。經(jīng)過內(nèi)部大規(guī)模數(shù)據(jù)及模型場景的檢測之后,我們也期望將這些能力輸出,更好地賦能給阿里外部的AI從業(yè)人員。
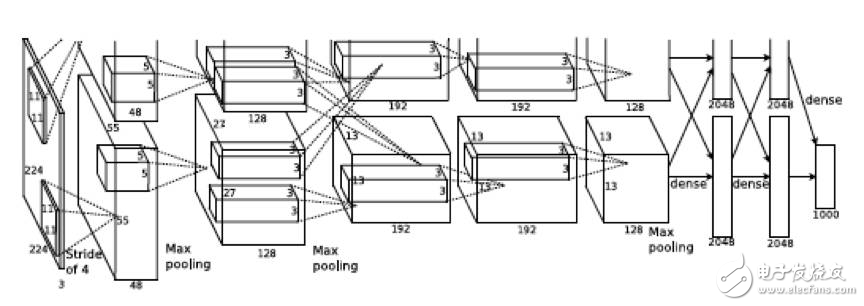
圖1. AlexNet模型示例

圖2. 36層的ResNet模型示例
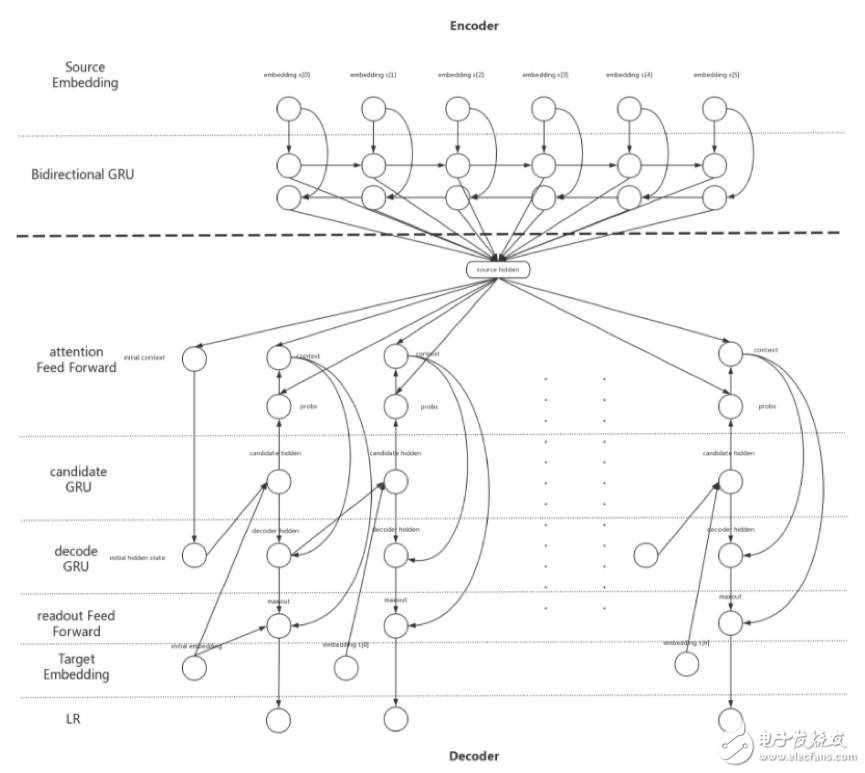
圖3. NMT模型架構示例
接下來,本文會扼要介紹一下在PAI里實現(xiàn)的大規(guī)模深度學習的優(yōu)化策略。
2.大規(guī)模深度學習優(yōu)化策略在PAI中實踐應用
大規(guī)模深度學習作為一個交叉領域,涉及到分布式計算、操作系統(tǒng)、計算機體系結構、數(shù)值優(yōu)化、機器學習建模、編譯器技術等多個領域。按照優(yōu)化的側(cè)重點,可以將優(yōu)化策略劃分為如下幾種:
I. 計算優(yōu)化
II. 顯存優(yōu)化
III. 通信優(yōu)化
IV. 性能預估模型
V 軟硬件協(xié)同優(yōu)化
PAI平臺目前主要集中在顯存優(yōu)化、通信優(yōu)化、性能預估模型、軟硬件協(xié)同優(yōu)化這四個優(yōu)化方向。
1)。 顯存優(yōu)化
內(nèi)存優(yōu)化主要關心的是GPU顯存優(yōu)化的議題,在Deep Learning訓練場景,其計算任務的特點(大量的滿足SIMD特性的矩陣浮點運算執(zhí)行序列,控制邏輯通常比較簡單)決定了通常我們會選擇GPU來作為計算設備,而GPU作為典型的高通量異構計算設備,其硬件設計約束決定了其顯存資源往往是比較稀缺的,目前在PAI平臺上提供的中檔M40顯卡的顯存只有12GB,而復雜度較高的模型則很容易達到M40顯存的臨界值,比如151層的ResNet、阿里巴巴內(nèi)部用于中文OCR識別的一款序列模型以及機器翻譯模型。從建模同學的角度來看,顯存并不應該是他們關心的話題,PAI在顯存優(yōu)化上做了一系列工作,期望能夠解放建模同學的負擔,讓建模同學在模型尺寸上獲得更廣闊的建模探索空間。在內(nèi)存優(yōu)化方面, 通過引入task-specific的顯存分配器以及自動化模型分片框架支持,在很大程度上緩解了建模任務在顯存消耗方面的約束。其中自動化模型分片框架會根據(jù)具體的模型網(wǎng)絡特點,預估出其顯存消耗量,然后對模型進行自動化切片,實現(xiàn)模型并行的支持,在完成自動化模型分片的同時,我們的框架還會考慮到模型分片帶來的通信開銷,通過啟發(fā)式的方法在大模型的承載能力和計算效率之間獲得較優(yōu)的trade-off。
2)。 通信優(yōu)化
大規(guī)模深度學習,或者說大規(guī)模機器學習領域里一個永恒的話題就是如何通過多機分布式對訓練任務進行加速。而機器學習訓練任務的多遍迭代式通信的特點,使得經(jīng)典的map-reduce式的并行數(shù)據(jù)處理方式并不適合這個場景。對于以單步小批量樣本作為訓練單位步的深度學習訓練任務,這個問題就更突出了。
依據(jù)Amdahl’s law[19],一個計算任務性能改善的程度取決于可以被改進的部分在整個任務執(zhí)行時間中所占比例的大小。而深度學習訓練任務的多機分布式往往會引入額外的通信開銷,使得系統(tǒng)內(nèi)可被提速的比例縮小,相應地束縛了分布式所能帶來的性能加速的收益 。
在PAI里,我們通過pipeline communication、late-multiply、hybrid-parallelism以及heuristic-based model average等多種優(yōu)化策略對分布式訓練過程中的通信開銷進行了不同程度的優(yōu)化,并在公開及in-house模型上取得了比較顯著的收斂加速比提升。
在Pipeline communication(圖4)里,通過將待通信數(shù)據(jù)(模型及梯度)切分成一個個小的數(shù)據(jù)塊并在多個計算結點之間充分流動起來,可以突破單機網(wǎng)卡的通信帶寬極限,將一定尺度內(nèi)將通信開銷控制在常量時間復雜度。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%