云機器學習服務精彩回顧
Amazon,Microsoft,Databricks,Google,HPE和IBM的機器學習工具在廣度、深度及易用性上都具備優勢。
機器學習具有多種形式,其中最純粹的一種可以為分析師提供一組數據探索工具、ML模型選擇、穩健的解決方案以及將此方案用于預測的使用方法。
Amazon,Microsoft,Databricks,Google和IBM的云服務都提供預測API,來進行多重管控。HPE Haven OnDemand還提供了一個有限的預測API,用于解決二元分類問題。
然而,并不是所有的機器學習問題都必須從頭開始解決。有些問題可以用在一個足夠大的樣本中,通過訓練使其廣泛適用。例如,“canned”方案就能夠有效解決語音識別、語音合成、文本分析及人臉識別中存在的問題。不用驚奇,許多云機器學習提供商都會利用一個API,讓開發者在應用程序內能實現這些功能。
這些功能可以識別美式英語口語(和其他一些語言)并將其轉錄。但對于給定的說話者而言,給定的服務能否奏效將取決于他的方言和口音,以及該服務在類似方言和口音上的受訓程度。Microsoft Azure,IBM,Google和Haven On Demand都啟動了語音識別服務。
機器學習也存在多種問題。例如,回歸問題試圖從觀察結果中預測一個連續變量(例如銷售情況),分類問題試圖通過一組給定的觀測值預測種類(例如垃圾郵件)。但是仍然有一些相對完整的工具包,像Amazon,Microsoft,Databricks,Google,HPE和IBM所提供的工具,就可以用來解決一系列的機器學習問題。
本文將簡要地介紹六個商業機器學習方案,還會貼出五個完整實驗結果。不幸的是,Google三月份所宣布的——基于云計算的機器學習工具和應用程序,還沒能使Google Cloud Machine Learning達到公共可用的程度。
Amazon Machine Learning
Amazon一直致力于研究大眾化的機器學習平臺,用來服務那些熟悉業務問題的分析人員,無論他們是否理解數據科學或機器學習算法。
一般來說,要使用Amazon Machine Learning需要經過三個步驟:首先,在S3中清理和上傳CSV格式數據;然后,創建、訓練和評估ML模型;最后,創建批處理或實時預測。每一步都是迭代的,在整個過程中也同樣如此。所以機器學習并不是一個簡單、靜態的萬能藥,即使Amazon已經實現了算法優選。
Amazon Machine Learning支持三種模型:二元分類、多級分類和回歸——一個算法適用一種類型。為了優化,Amazon Machine Learning使用SGD(Stochastic Gradient Descent),將多個連續的訓練數據進行傳遞,并更新功能權重使之成為小批量格式,讓損失函數最小化。損失函數反映了實際值和預測值之間的區別,而且梯度下降優化方法只適用于連續、可微的損失函數,例如物流損失函數和平方損失函數。
Amazon Machine Learning將邏輯回歸(物流損失函數+SGD)用于二元分類。
Amazon Machine Learning將多項邏輯回歸(多項物流損失函數+SGD)用于多級分類。
Amazon Machine Learning將線性回歸(平方損失函數+SGD)用于回歸。
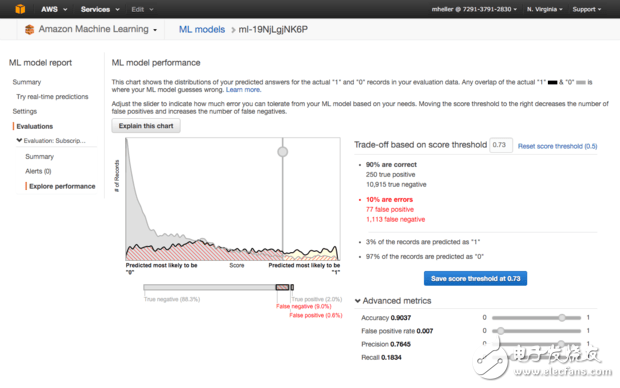
在使用Amazon Machine Learning訓練和評估二元分類模型后,可以選擇分數閾值來實現想要的錯誤率。這里在默認0.5的閾值上有所增加,就可以生成一套更強的引線,有利于更快達到營銷和銷售目的。
Amazon Machine Learning決定了機器學習是任務解決型而不是目標數據型。例如,預測數值目標變量的問題,意味著回歸;預測非數字目標變量的問題時,如果只有兩個目標就是二元分類,如果有兩個以上則是多級分類。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%