機器學習的一些測試問題及解答
大小:0.6 MB 人氣:2 2017-10-09 需要積分:1


標簽:機器學習(129859)
目前機器學習是最搶手的技能之一。如果你是一名數據科學家,那就需要對機器學習很擅長,而不只是三腳貓的功夫。作為 DataFest 2017 的一部分,Analytics Vidhya 組織了不同的技能測試,從而數據科學家可以就這些關鍵技能進行自我評估。測試包括機器學習、深度學習、時序問題以及概率。這篇文章將給出機器學習測試問題的解答。在本文的機器學習測試中,超過 1350 人注冊參與其中。該測試可以檢驗你對機器學習概念知識的掌握,并為你步入業界做準備。如果錯過了實時測試,沒有關系,你可以回顧本文以自我提升。機器之心對這些試題及解答進行了編譯介紹。你能答對多少題呢?不妨與我們分享。
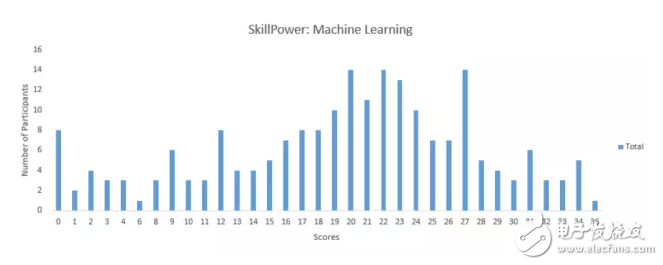
目前已有 210 人參與了這些試題的測試,最高分為 36。平均得分為 19.36,中位數為 21,最常出現的得分(Mode Score)為 27。
測試題與解答
假定特征 F1 可以取特定值:A、B、C、D、E 和 F,其代表著學生在大學所獲得的評分。現在請答題:
1.在下面說法中哪一項是正確的?
A. 特征 F1 是名義變量(nominal variable)的一個實例。
B. 特征 F1 是有序變量(ordinal variable)的一個實例。
C. 該特征并不屬于以上的分類。
D. 以上說法都正確。
答案為(B):有序變量是一種在類別上有某些順序的變量。例如,等級 A 就要比等級 B 所代表的成績好一些。
2.下面哪個選項中哪一項屬于確定性算法?
A.PCA
B.K-Means
C. 以上都不是
答案為(A):確定性算法表明在不同運行中,算法輸出并不會改變。如果我們再一次運行算法,PCA 會得出相同的結果,而 k-means 不會。
3.兩個變量的 Pearson 相關性系數為零,但這兩個變量的值同樣可以相關。
A. 正確
B. 錯誤
答案為(A):Y=X2,請注意他們不僅僅相關聯,同時一個還是另一個的函數。盡管如此,他們的相關性系數還是為 0,因為這兩個變量的關聯是正交的,而相關性系數就是檢測這種關聯。
4.下面哪一項對梯度下降(GD)和隨機梯度下降(SGD)的描述是正確的?
在 GD 和 SGD 中,每一次迭代中都是更新一組參數以最小化損失函數。
在 SGD 中,每一次迭代都需要遍歷訓練集中的所有樣本以更新一次參數。
在 GD 中,每一次迭代需要使用整個訓練集或子訓練集的數據更新一個參數。
A. 只有 1
B. 只有 2
C. 只有 3
D.1 和 2
E.2 和 3
F. 都正確
答案為(A):在隨機梯度下降中,每一次迭代選擇的批量是由數據集中的隨機樣本所組成,但在梯度下降,每一次迭代需要使用整個訓練數據集。
5.下面哪個/些超參數的增加可能會造成隨機森林數據過擬合?
樹的數量
樹的深度
學習速率
A. 只有 1
B. 只有 2
C. 只有 3
D.1 和 2
E.2 和 3
F. 都正確
答案為(B):通常情況下,我們增加樹的深度有可能會造成模型過擬合。學習速率在隨機森林中并不是超參數。增加樹的數量可能會造成欠擬合。
6.假如你在「Analytics Vidhya」工作,并且想開發一個能預測文章評論次數的機器學習算法。你的分析的特征是基于如作者姓名、作者在 Analytics Vidhya 寫過的總文章數量等等。那么在這樣一個算法中,你會選擇哪一個評價度量標準?
(1)均方誤差、(2)精確度、(3)F1 分數
A. 只有 1
B. 只有 2
C. 只有 3
D. 1 和 3
E. 2 和 3
F. 1 和 2
答案為(A):你可以把文章評論數看作連續型的目標變量,因此該問題可以劃分到回歸問題。因此均方誤差就可以作為損失函數的度量標準。
7.給定以下三個圖表(從上往下依次為1,2,3)。 哪一個選項對以這三個圖表的描述是正確的?
A. 1 是 tanh,2 是 ReLU,3 是 SIGMOID 激活函數
B. 1 是 SIGMOID,2 是 ReLU,3 是 tanh 激活函數
C. 1 是 ReLU,2 是 tanh,3 是 SIGMOID 激活函數
D. 1 是 tanh,2 是 SIGMOID,3 是 ReLU 激活函數
答案為(D):因為 SIGMOID 函數的取值范圍是 [0,1],tanh 函數的取值范圍是 [-1,1],RELU 函數的取值范圍是 [0,infinity]。
8.以下是目標變量在訓練集上的 8 個實際值 [0,0,0,1,1,1,1,1],目標變量的熵是所少?
A. -(5/8 log(5/8) + 3/8 log(3/8))
B. 5/8 log(5/8) + 3/8 log(3/8)
C. 3/8 log(5/8) + 5/8 log(3/8)
D. 5/8 log(3/8) – 3/8 log(5/8)
答案為(A)
9.假定你正在處理類屬特征,并且沒有查看分類變量在測試集中的分布。現在你想將 one hot encoding(OHE)應用到類屬特征中。那么在訓練集中將 OHE 應用到分類變量可能要面臨的困難是什么?
A. 分類變量所有的類別沒有全部出現在測試集中
B. 類別的頻率分布在訓練集和測試集是不同的
C. 訓練集和測試集通常會有一樣的分布
D. A 和 B 都正確
E. 以上都不正確
答案為(D):A、B 項都正確,如果類別在測試集中出現,但沒有在訓練集中出現,OHE 將會不能進行編碼類別,這將是應用 OHE 的主要困難。選項 B 同樣也是正確的,在應用 OHE 時,如果訓練集和測試集的頻率分布不相同,我們需要多加小心。
10.Skip gram 模型是在 Word2vec 算法中為詞嵌入而設計的最優模型。以下哪一項描繪了 Skip gram 模型?
A. A
B. B
C. A 和 B
D. 以上都不是
答案為(B):這兩個模型都是在 Word2vec 算法中所使用的。模型 A 代表著 CBOW,模型 B 代表著 Skip gram。
11.假定你在神經網絡中的隱藏層中使用激活函數 X。在特定神經元給定任意輸入,你會得到輸出「-0.0001」。X 可能是以下哪一個激活函數?
A. ReLU
B. tanh
C. SIGMOID
D. 以上都不是
答案為(B):該激活函數可能是 tanh,因為該函數的取值范圍是 (-1,1)。
12.對數損失度量函數可以取負值。
A. 對
B. 錯
答案為(B):對數損失函數不可能取負值。
13.下面哪個/些對「類型 1(Type-1)」和「類型 2(Type-2)」錯誤的描述是正確的?
類型 1 通常稱之為假正類,類型 2 通常稱之為假負類。
類型 2 通常稱之為假正類,類型 1 通常稱之為假負類。
類型 1 錯誤通常在其是正確的情況下拒絕假設而出現。
A. 只有 1
B. 只有 2
C. 只有 3
D. 1 和 2
E. 1 和 3
F. 3 和 2
答案為(E):在統計學假設測試中,I 類錯誤即錯誤地拒絕了正確的假設(即假正類錯誤),II 類錯誤通常指錯誤地接受了錯誤的假設(即假負類錯誤)。
14.下面在 NLP 項目中哪些是文本預處理的重要步驟?
詞干提取(Stemming)
移去停止詞(Stop word removal)
目標標準化(Object Standardization)
A. 1 和 2
B. 1 和 3
C. 2 和 3
D. 1、2 和 3
答案為(D):詞干提取是剝離后綴(「ing」,「ly」,「es」,「s」等)的基于規則的過程。停止詞是與語境不相關的詞(is/am/are)。目標標準化也是一種文本預處理的優良方法。
15.假定你想將高維數據映射到低維數據中,那么最出名的降維算法是 PAC 和 t-SNE。現在你將這兩個算法分別應用到數據「X」上,并得到數據集「X_projected_PCA」,「X_projected_tSNE」。下面哪一項對「X_projected_PCA」和「X_projected_tSNE」的描述是正確的?
A. X_projected_PCA 在最近鄰空間能得到解釋
B. X_projected_tSNE 在最近鄰空間能得到解釋
C. 兩個都在最近鄰空間能得到解釋
D. 兩個都不能在最近鄰空間得到解釋
答案為(B):t-SNE 算法考慮最近鄰點而減少數據維度。所以在使用 t-SNE 之后,所降的維可以在最近鄰空間得到解釋。但 PCA 不能。
16-17 題的背景:給定下面兩個特征的三個散點圖(從左到右依次為圖 1、2、3)。
16.在上面的圖像中,哪一個是多元共線(multi-collinear)特征?
A. 圖 1 中的特征
B. 圖 2 中的特征
C. 圖 3 中的特征
D. 圖 1、2 中的特征
E. 圖 2、3 中的特征
F. 圖 1、3 中的特征
答案為(D):在圖 1 中,特征之間有高度正相關,圖 2 中特征有高度負相關。所以這兩個圖的特征是多元共線特征。
17.在先前問題中,假定你已經鑒別了多元共線特征。那么下一步你可能的操作是什么?
移除兩個共線變量
不移除兩個變量,而是移除一個
移除相關變量可能會導致信息損失。為了保留這些變量,我們可以使用帶罰項的回歸模型(如 ridge 或 lasso regression)。
A. 只有 1
B. 只有 2
C. 只有 3
D. 1 或 3
E. 1 或 2
答案為(E):因為移除兩個變量會損失一切信息,所以我們只能移除一個特征,或者也可以使用正則化算法(如 L1 和 L2)。
18.給線性回歸模型添加一個不重要的特征可能會造成:
增加 R-square
減少 R-square
A. 只有 1 是對的
B. 只有 2 是對的
C. 1 或 2 是對的
D. 都不對
答案為(A):在給特征空間添加了一個特征后,不論特征是重要還是不重要,R-square 通常會增加。
19.假設給定三個變量 X,Y,Z。(X, Y)、(Y, Z) 和 (X, Z) 的 Pearson 相關性系數分別為 C1、C2 和 C3。現在 X 的所有值加 2(即 X+2),Y 的全部值減 2(即 Y-2),Z 保持不變。那么運算之后的 (X, Y)、(Y, Z) 和 (X, Z) 相關性系數分別為 D1、D2 和 D3。現在試問 D1、D2、D3 和 C1、C2、C3 之間的關系是什么?
A. D1= C1, D2 《 C2, D3 》 C3
B. D1 = C1, D2 》 C2, D3 》 C3
C. D1 = C1, D2 》 C2, D3 《 C3
D. D1 = C1, D2 《 C2, D3 《 C3
E. D1 = C1, D2 = C2, D3 = C3
F. 無法確定
答案為(E):特征之間的相關性系數不會因為特征加或減去一個數而改變。
20.假定你現在解決一個有著非常不平衡類別的分類問題,即主要類別占據了訓練數據的 99%。現在你的模型在測試集上表現為 99% 的準確度。那么下面哪一項表述是正確的?
準確度并不適合于衡量不平衡類別問題
準確度適合于衡量不平衡類別問題
精確率和召回率適合于衡量不平衡類別問題
精確率和召回率不適合于衡量不平衡類別問題
A. 1 and 3
B. 1 and 4
C. 2 and 3
D. 2 and 4
答案為(A):參考問題 4 的解答。
21.在集成學習中,模型集成了弱學習者的預測,所以這些模型的集成將比使用單個模型預測效果更好。下面哪個/些選項對集成學習模型中的弱學習者描述正確?
他們經常不會過擬合
他們通常帶有高偏差,所以其并不能解決復雜學習問題
他們通常會過擬合
A. 1 和 2
B. 1 和 3
C. 2 和 3
D. 只有 1
E. 只有 2
F. 以上都不對
答案為(A):弱學習者是問題的特定部分。所以他們通常不會過擬合,這也就意味著弱學習者通常擁有低方差和高偏差。
22.下面哪個/些選項對 K 折交叉驗證的描述是正確的
增大 K 將導致交叉驗證結果時需要更多的時間
更大的 K 值相比于小 K 值將對交叉驗證結構有更高的信心
如果 K=N,那么其稱為留一交叉驗證,其中 N 為驗證集中的樣本數量
A. 1 和 2
B. 2 和 3
C. 1 和 3
D. 1、2 和 3
答案為(D):大 K 值意味著對過高估計真實預期誤差(訓練的折數將更接近于整個驗證集樣本數)擁有更小的偏差和更多的運行時間(并隨著越來越接近極限情況:留一交叉驗證)。我們同樣在選擇 K 值時需要考慮 K 折準確度和方差間的均衡。
23 題至 24 題的背景:交叉驗證在機器學習超參數微調中是十分重要的步驟。假定你需要為 GBM 通過選擇 10 個不同的深度值(該值大于 2)而調整超參數「max_depth」,該樹型模型使用 5 折交叉驗證。 4 折訓練驗證算法(模型 max_depth 為 2)的時間為 10 秒,在剩下的 1 折中預測為 2 秒。
23.哪一項描述擁有 10 個「max_depth」不同值的 5 折交叉驗證整體執行時間是正確的?
A. 少于 100 秒
B. 100-300 秒
C. 300-600 秒
D. 大于等于 600 秒
E. 無法估計
答案為(D):因為深度為 2 的 5 折交叉驗證每一次迭代需要訓練 10 秒和測試 2 秒。因此五折驗證需要 125 = 60 秒,又因為我們需要搜索 10 個深度值,所以算法需要 6010 = 600。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%