基于Spark機器學習工具來分析信用風險問題
大小:0.17 MB 人氣:0 2017-10-10 需要積分:1


分類算法
分類算法是一類監督式機器學習算法,它根據已知標簽的樣本(如已經明確交易是否存在欺詐)來預測其它樣本所屬的類別(如是否屬于欺詐性的交易)。分類問題需要一個已經標記過的數據集和預先設計好的特征,然后基于這些信息來學習給新樣本打標簽。所謂的特征即是一些“是與否”的問題。標簽就是這些問題的答案。在下面這個例子里,如果某個動物的行走姿態、游泳姿勢和叫聲都像鴨子,那么就給它打上“鴨子”的標簽。
我們來看一個銀行信貸的信用風險例子:
我們需要預測什么?
某個人是否會按時還款這就是標簽:此人的信用度
你用來預測的“是與否”問題或者屬性是什么?
申請人的基本信息和社會身份信息:職業,年齡,存款儲蓄,婚姻狀態等等……這些就是特征,用來構建一個分類模型,你從中提取出對分類有幫助的特征信息。
決策樹模型
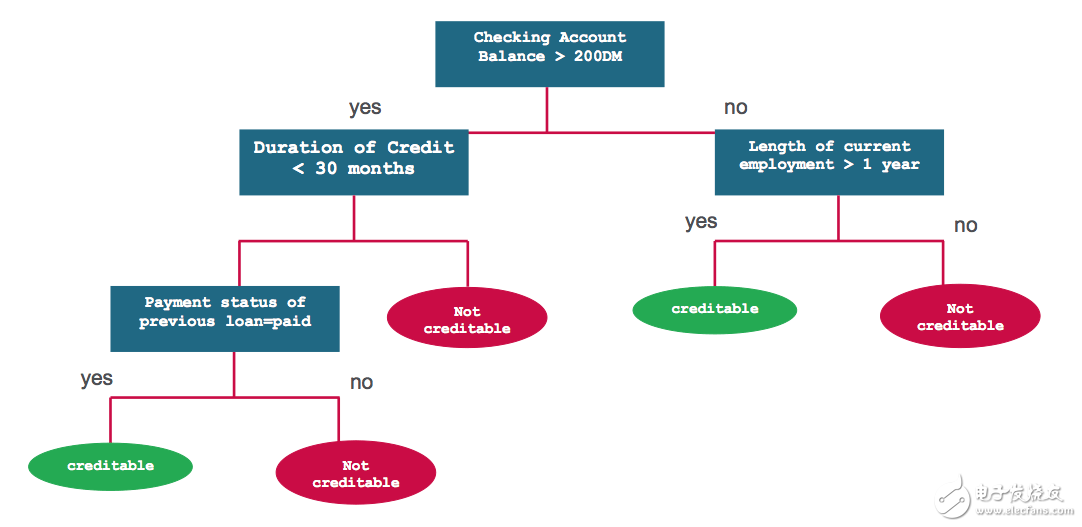
決策樹是一種基于輸入特征來預測類別或是標簽的分類模型。決策樹的工作原理是這樣的,它在每個節點都需要計算特征在該節點的表達式值,然后基于運算結果選擇一個分支通往下一個節點。下圖展示了一種用來預測信用風險的決策樹模型。每個決策問題就是模型的一個節點,“是”或者“否”的答案是通往子節點的分支。
問題1:賬戶余額是否大于200元?
否問題2:當前就職時間是否超過1年?
否不可信賴
隨機森林模型
融合學習算法結合了多個機器學習的算法,從而得到了效果更好的模型。隨機森林是分類和回歸問題中一類常用的融合學習方法。此算法基于訓練數據的不同子集構建多棵決策樹,組合成一個新的模型。預測結果是所有決策樹輸出的組合,這樣能夠減少波動,并且提高預測的準確度。對于隨機森林分類模型,每棵樹的預測結果都視為一張投票。獲得投票數最多的類別就是預測的類別。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%