HBase客戶端實踐重試機制
大小:0.6 MB 人氣: 2017-10-10 需要積分:1
標簽:Hbase(11036)
現在,網易視頻云與大家分享HBase客戶端實踐–重試機制。在運維HBase的這段時間里,發現業務用戶一方面比較關注HBase本身服務的讀寫性能:吞吐量以及讀寫延遲,另一方面也會比較關注HBase客戶端使用上的問題,主要集中在兩個方面:是否提供了重試機制來保證系統操作的容錯性?是否有必要的超時機制保證系統能夠fastfail,保證系統的低延遲特性?
這個系列我們集中介紹HBase客戶端使用上的這兩大問題,本文通過分析之前一個真實的案例來介紹HBase客戶端提供的重試機制,并通過配置合理的參數使得客戶端在保證一定容錯性的同時還能夠保證系統的低延遲特性。
案發現場
最近某業務在使用HBase客戶端讀取數據時出現了大量線程block的情況,業務方保留了當時的線程堆棧信息,如下圖所示:
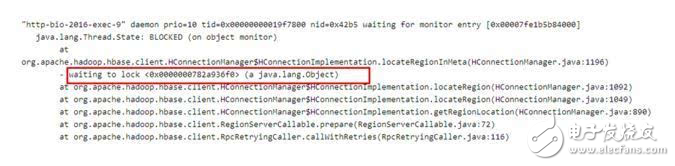
看到這樣的問題,首先從日志和監控排查了業務表和region server,確認了在很長時間內確實沒有請求進來,除此之外并沒有其他有用的信息,同時也沒有接到該集群上其他用戶的異常反饋,從現象看,這次異常是在特定環境下才會觸發的。
案件分析過程
1.根據上圖圖1所示,所有的請求都block在《0x0000000782a936f0》這把全局鎖上,這里需要關注兩個問題:
哪個線程持有了這把全局鎖《0x0000000782a936f0》?
這是一把什么樣的全局鎖(對于問題本身并不重要,有興趣可以參考步驟3)?
2.哪個線程持有了這把鎖?
2.1 很容易在jstack日志中通過搜索找到全局鎖《0x0000000782a936f0》被如下線程持有:
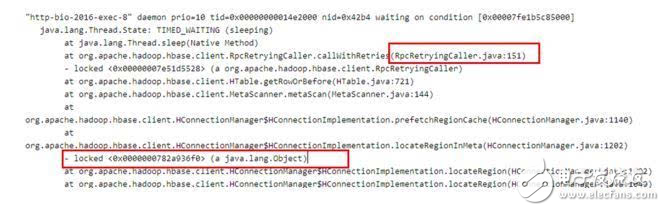
定睛一看,該線程持有了這把全局鎖,而且處于TIMED_WAITING狀態,因此這把鎖可能長時間不釋放,導致所有需要這把全局鎖的線程都阻塞等待。好了,那問題就轉化成了:為什么這個線程會處于TIME_WAITING狀態?
2.2 根據上圖提示,查看源碼中RpcRetryingCall.java的115行代碼,可以確定該線程處于TIME_WAITING狀態是因為自己休眠導致,如下圖所示:
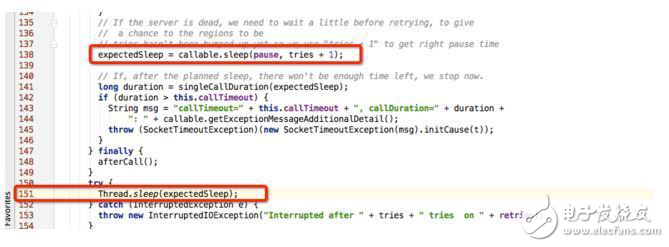
RpcRetryingCall函數是Rpc請求重試機制的實現,所以可以有兩點推斷:
HBase客戶端請求在那個時間段網絡有異常導致rpc請求失敗,進入重試邏輯
根據HBase的重試機制(退避機制),每兩次重試機制之間會休眠一段時間,即上圖115行代碼,這個休眠時間太長導致這個線程一直處于TIME_WAITING狀態。
休眠時間由上圖中expectedSleep = callable.sleep(pause,tries + 1)決定,根據hbase算法(見第三部分),默認最大的expectedSleep為20s,整個重試時間會持續8min,這也就是說全局鎖會被持有8min,可這并不能解釋持續將近幾個小時的阻塞無請求。除非有兩種情況:
配置有問題:需要客戶端檢查hbase.client.pause和hbase.client.retries.number兩個參數配置出現異常,比如hbase.client.pause參數如果手抖配成了10000,就有可能出現幾個小時阻塞的情況
網絡持續有問題:如果線程1持有全局鎖重試失敗之后退出,線程2競爭到這把鎖,此時網絡依然有問題,線程2會再次進入重試,重試8min之后失敗退出,循環下去,也有可能出現幾個小時阻塞的情況
和業務方確認配置,所有參數基本屬于默認配置,因此猜測一不成立,那最有可能的情況就是猜測二。經過確認,在事發當時(凌晨0點~早上6點)確實存在很多服務因為云網絡升級異常發生抖動的情況出現。然而因為沒有具體的日志信息,所以并不能完全確認猜測是否正確。但是,通過問題的分析可以進一步明白HBase重試機制以及部分客戶端參數優化策略,這也是寫這篇文章的初衷之一。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%
下載地址
HBase客戶端實踐重試機制下載
相關電子資料下載
- 【分布式存儲數據恢復】hbase和hive數據庫底層文件誤刪的恢復案例 415
- 使用G1 GC時HBase為什么性能下降了近20% 1653
- Hbase的基礎性介紹與入門 1046
- 阿里HBase高可用8年“抗戰”回憶錄 246
- 阿里云HBase推出普惠性高可用服務,獨家支持用戶的自建、混合云環境集群 205
- 今年小米做東,HBaseCon Asia 2019將在北京召開 2893
- 基于HBase的工業大數據存儲實戰 3130
- 阿里云HBase推出全新X-Pack服務 定義HBase云服務新標準 123
- 阿里云HBase全新發布X-Pack NoSQL數據庫再上新臺階 231
- 八年技術加持,性能提升10倍,阿里云HBase 2.0首發商用 130