深度學習在自然語言處理方面的應用打造智能聊天機器人
作者:張俊林,中科院軟件所博士,技術書籍《這就是搜索引擎:核心技術詳解》、《大數據日知錄:架構與算法》作者。曾擔任阿里巴巴、百度、新浪微博資深技術專家,目前是用友暢捷通工智能相關業務負責人,關注深度學習在自然語言處理方面的應用。
責編:周建丁(zhoujd@csdn.net)
本文為《程序員》原創文章,未經允許不得轉載,更多內容請訂閱2016年《程序員》
聊天機器人(也可以稱為語音助手、聊天助手、對話機器人等)是目前非常熱的一個人工智能研發與產品方向。很多大型互聯網公司投入重金研發相關技術,并陸續推出了相關產品,比如蘋果Siri、微軟Cortana與小冰、Google Now、百度的“度秘”、亞馬遜的藍牙音箱Echo內置的語音助手Alexa、Facebook推出的語音助手M、Siri創始人新推出的Viv……
究其原因在于大家都將聊天機器人定位為未來各種服務的入口,尤其是移動端App及可穿戴設備場景下提供各種服務的入口。
聊天機器人的類型
目前市場上有各種類型的聊天機器人,比如有京東JIMI客服機器人,兒童教育機器人,小冰娛樂聊天機器人,Alexa家居控制、車載控制機器人,Viv全方位服務類型機器人等。這是從應用方向對聊天機器人的一種劃分。
如果對應用目的或者技術手段進行抽象,聊天機器人可以有以下兩種劃分方法。
目標驅動(Goal Driven) VS 無目標驅動(Non-Goal Driven)聊天機器人
目標驅動的聊天機器人指的是聊天機器人有明確的服務目標或者服務對象,比如客服機器人、兒童教育機器人、類似Viv的提供天氣/訂票/訂餐等服務的服務機器人等,這種目標驅動的聊天機器人也可以稱作特定領域的聊天機器人。
無目標驅動聊天機器人指的是聊天機器人并非為特定領域服務目的而開發,比如純粹聊天或者出于娛樂聊天目的以及計算機游戲中的虛擬人物聊天機器人都屬于此類。這種無明確任務目標的聊天機器人也可以稱作為開放領域的聊天機器人。
檢索式 VS 生成式聊天機器人
檢索式聊天機器人指的是事先存在一個對話庫,聊天系統接收到用戶輸入句子后,通過在對話庫中以搜索匹配的方式進行應答內容提取。很明顯,這種方式對對話庫要求很高,需要對話庫足夠大,能夠盡量多地匹配用戶問句,否則會經常出現找不到合適回答內容的情形(因為在真實場景下用戶說什么都是可能的),但它的好處是回答質量高,因為對話庫中的內容都是真實的對話數據,表達比較自然。
生成式聊天機器人則采取不同的技術思路,在接收到用戶輸入句子后,采用一定技術手段自動生成一句話作為應答,這個路線機器人的好處是可能覆蓋任意話題的用戶問句,但是缺點是生成應答句子質量很可能會存在問題,比如語句不通順、句法錯誤等看上去比較低級的錯誤。
本文重點介紹開放領域、生成式的聊天機器人如何通過深度學習技術來構建,很明顯這是最難處理的一種情況。
好聊天機器人應該具備的特點
一般而言,一個優秀的開放領域聊天機器人應該具備如下特點:
首先,針對用戶的回答或者聊天內容,機器人產生的應答句應該和用戶的問句語義一致并邏輯正確,如果聊天機器人答非所問或者不知所云,或者總是回答說“對不起,我不理解您的意思”,無疑是毀滅性的用戶體驗。
其次,回答應該語法正確。這個看似是基本要求,但是對于采用生成式對話技術的機器人來說其實有一定困難,因為機器人的回答是一個字一個字生成,要保證這種生成的若干個字句法正確,并不容易做得那么完美。
再次,應答應該是有趣、多樣而非沉悶無聊的。盡管有些應答看上去語義沒什么問題,但目前技術訓練出的聊天機器人很容易產生“安全回答”的問題,就是說,不論用戶輸入什么句子,聊天機器人總是回答“好啊”、“是嗎”等諸如此類,看上去語義說得過去,但是這給人很無聊的感覺。
此外,聊天機器人應該給人“個性表達一致”的感覺。因為人們和聊天機器人交流,從內心習慣還是將溝通對象想象成一個人,而一個人應該有相對一致的個性特征,如果用戶連續問兩次“你多大了”,而聊天機器人分別給出不同的歲數,那么會給人交流對象精神分裂的印象,這即是典型的個性表達不一致。而好的聊天機器人應該對外體現出各種基本背景信息以及愛好、語言風格等方面一致的回答。
幾種主流技術思路
當前聊天機器人的幾種主流技術包括:基于人工模板、基于檢索、基于機器翻譯技術,以及基于深度學習的聊天機器人。
基于 人工模板的技術通過人工設定對話場景,并對每個場景編寫針對性的對話模板,模板描述了用戶可能的問題以及對應的答案。這個技術路線的好處是精準,缺點是需要大量人工工作,而且可擴展性差,需要一個場景一個場景去擴展。目前市場上各種類似于Siri的對話機器人中都大量使用了人工模板的技術,但其精準性是其他方法還無法比擬的。
基于 檢索技術的聊天機器人則走的是類似搜索引擎的路線,事先存儲好對話庫并建立索引,根據用戶問句,在對話庫中進行模糊匹配找到最合適的應答內容。
基于 機器翻譯技術的聊天機器人把聊天過程比擬成機器翻譯過程,就是說將用戶輸入聊天信息Message,翻譯成聊天機器人應答Response的過程類似于把英語翻譯成漢語。基于這種假設,就完全可以將統計機器翻譯領域相對成熟的技術直接應用到聊天機器人開發中。
基于 深度學習的聊天機器人技術是本文后續內容主要介紹的技術路線,總體而言,絕大多數技術都是在Encoder-Decoder(或者稱作Sequence to Sequence)深度學習技術框架下改進的。使用深度學習技術來開發聊天機器人相對傳統方法來說,整體思路非常簡單并可擴展。
利用深度學習構建聊天機器人
如上所述,目前對于開放領域生成式聊天機器人技術而言,多數采用了Encoder-Decoder框架,所以這里首先描述Encoder-Decoder框架技術原理。然后分別針對聊天機器人研究領域需要特殊考慮的主要問題及其對應的解決方案進行講解,這些主要問題分別是:多輪會話中的上下文機制、“安全回答”以及個性信息一致性問題。
Encoder-Decoder框架
Encoder-Decoder框架可以看作一種文本處理領域的研究模式,應用場景異常廣泛,不僅可用在對話機器人領域,還可以應用在機器翻譯、文本摘要、句法分析等各種場合。圖1是文本處理領域里常用的Encoder-Decoder框架最抽象的一種表示。Encoder-Decoder框架可以直觀地理解為適合處理由一個句子(或篇章)生成另外一個句子(或篇章)的通用處理模型。對于句子對(X,Y),我們的目標是給定輸入句子X,期待通過Encoder-Decoder框架來生成目標句子Y。X和Y可以是同一種語言,也可以是兩種不同的語言。而X和Y分別由各自的單詞序列構成:
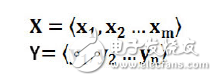
Encoder顧名思義就是對輸入句子X進行編碼,將輸入句子通過非線性變換轉化為中間語義表示C:
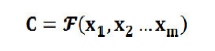
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%