代碼分析CNTK和TensorFlow高層次的對比
大小:0.2 MB 人氣: 2017-10-12 需要積分:1
原標題:當TensorFlow遇見CNTK

CNTK是微軟用于搭建深度神經網絡的計算網絡工具包,此項目已在Github上開源。因為我最近寫了關于TensorFlow的文章,所以想比較一下這兩個系統的相似和差異之處。畢竟,CNTK也是許多圖像識別挑戰賽的衛冕冠軍。為了內容的完整性,我應該也對比一下Theano、Torch和Caffe。后三者也是現在非常流行的框架。但是本文僅限于討論CNTK和TensorFlow,其余的框架將在今后討論。Kenneth Tran對這五個深度學習工具包做過一次高水平(以他個人觀點)的分析。本文并不是一個CNTK或者TensorFlow的使用教程。我的目的在于從程序員的角度對它們做高層次的對比。本文也不屬于性能分析,而是編程模型分析。文中會夾雜著大量的代碼,如果你討厭閱讀代碼,請直接跳到結論部分。
CNTK有一套極度優化的運行系統來訓練和測試神經網絡,它是以抽象的計算圖形式構建。如此看來,CNTK和TensorFlow長得非常相似。但是,它們有一些本質上的區別。為了演示這些特性和區別,我會用到兩個標準示例,它們分別包括了兩個系統及調用各自系統完成的任務。第一個例子是用較淺的卷積神經網絡來解決標準的MNIST手寫數字集的識別任務。我會針對它們兩種遞歸神經網絡方法的差異性做一些點評總結。
TensorFlow和CNTK都屬于腳本驅動型的。我的意思是說神經網絡構建的流程圖都是在一個腳本里完成,并調用一些智能的自動化步驟完成訓練。TensorFlow的腳本是與Python語言捆綁的,Python操作符能夠用來控制計算圖的執行過程。CNTK目前還沒有和Python或是C++綁定(盡管已經承諾過),所以它目前訓練和測試的流程控制還是需要精心編制設計的。等會我將展示,這個過程并不能算是一種限制。CNTK網絡需要用到兩個腳本:一個控制訓練和測試參數的配置文件和一個用于構建網絡的網絡定義語言(Network Definition Language, NDL)文件。
我會首先描述神經網絡的流程圖,因為這是與TensorFlow最相似之處。CNTK支持兩種方式來定義網絡。一種是使用“Simple Network Builder”,只需設置幾個參數就能生成一個簡單的標準神經網絡。另一種是使用網絡定義語言(NDL)。此處例子(直接從Github下載的)使用的是NDL。下面就是Convolution.ndl文件的縮略版本。(為了節省頁面空間,我把多行文件合并到同一行,并用逗號分隔)
CNTK網絡圖有一些特殊的節點。它們是描述輸入數據和訓練標簽的FeatureNodes和LabelNodes,用來評估訓練結果的CriterionNodes和EvalNodes,和表示輸出的OutputNodes。當我們在下文中遇到它們的時候我再具體解釋。在文件頂部還有一些用來加載數據(特征)和標簽的宏定義。如下所示,我們將MNIST數據集的圖像作為特征讀入,經過歸一化之后轉化為若干浮點數組。得到的數組“featScaled”將作為神經網絡的輸入值。
load= ndlMnistMacros # the actual NDL that defines the networkrun= DNN ndlMnistMacros= [ imageW = 28, imageH = 28 labelDim = 10 features = ImageInput(imageW, imageH, 1) featScale = Const(0.00390625) featScaled = Scale(featScale, features) labels = Input(labelDim) ] DNN=[ # conv1kW1 = 5, kH1 = 5 cMap1 = 16 hStride1 = 1, vStride1 = 1 conv1_act = ConvReLULayer(featScaled,cMap1,25,kW1,kH1,hStride1,vStride1,10, 1) # pool1pool1W = 2, pool1H = 2 pool1hStride = 2, pool1vStride = 2 pool1 = MaxPooling(conv1_act, pool1W, pool1H, pool1hStride, pool1vStride) # conv2kW2 = 5, kH2 = 5 cMap2 = 32 hStride2 = 1, vStride2 = 1 conv2_act = ConvReLULayer(pool1,cMap2,400,kW2, kH2, hStride2, vStride2,10, 1) # pool2pool2W = 2, pool2H = 2 pool2hStride = 2, pool2vStride = 2 pool2 = MaxPooling(conv2_act, pool2W, pool2H, pool2hStride, pool2vStride) h1Dim = 128 h1 = DNNSigmoidLayer(512, h1Dim, pool2, 1) ol = DNNLayer(h1Dim, labelDim, h1, 1) ce = CrossEntropyWithSoftmax(labels, ol) err = ErrorPrediction(labels, ol) # Special NodesFeatureNodes = (features) LabelNodes = (labels) CriterionNodes = (ce) EvalNodes = (err) OutputNodes = (ol) ]
DNN小節定義了網絡的結構。此神經網絡包括了兩個卷積-最大池化層,接著是有一個128節點隱藏層的全連接標準網絡。
在卷積層I 我們使用5x5的卷積核函數,并且在參數空間定義了16個(cMap1)。操作符ConvReLULayer實際上是在宏文件中定義的另一個子網絡的縮寫。
在計算時,我們想把卷積的參數用矩陣W和向量B來表示,那么如果輸入的是X,網絡的輸出將是f(op(W, X) + B)的形式。在這里操作符op就是卷積運算,f是標準規則化函數relu(x)=max(x,0)。
ConvReLULayer的NDL代碼如下圖所示:
ConvReLULayer(inp, outMap, inWCount, kW, kH, hStride, vStride, wScale, bValue) = [ convW = Parameter(outMap, inWCount, init=“uniform”, initValueScale=wScale) convB = Parameter(outMap, 1, init=“fixedValue”, value=bValue) conv = Convolution(convW, inp, kW, kH, outMap, hStride,vStride, zeroPadding=false) convPlusB = Plus(conv, convB); act = RectifiedLinear(convPlusB); ]
矩陣W和向量B是模型的參數,它們會被賦予一個初始值,并在訓練的過程中不斷更新直到生成最終模型。這里,convW是一個16行25列的矩陣,B是長度為16的向量。Convolution是內置的卷積函數,默認不使用補零的方法。也就是說對28x28的圖像做卷積運算,實際上只是對24x24的中心區域操作,得到的結果是16個24x24的sudo-image。
接著我們用2x2的區域應用最大池化操作,最后得到的結果是16個12x12的矩陣。
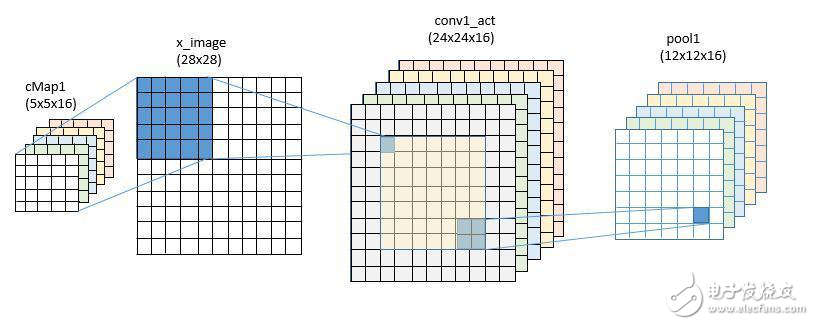
對于第二個卷積層,我們把卷積濾波器的個數由16個提升到32個。這一次我們有16通道的輸入數據,因此W矩陣的尺寸為32行25×16 = 400列,向量B的長度為32。這次的卷積運算針對12x12圖像幀的中心區域,所以得到的結果是32個8x8的矩陣。第二次池化操作的結果是32個4x4的幀,或者32x16=512。
最后兩層,是由512個池化輸出結果經過128個節點的隱藏層連接到10個輸出節點,經歷了兩次運算操作。
DNNSigmoidLayer(inDim, outDim, x, parmScale) = [ W = Parameter(outDim, inDim, init=“uniform”, initValueScale=parmScale) b = Parameter(outDim, 1, init=“uniform”, initValueScale=parmScale) t = Times(W, x) z = Plus(t, b) y = Sigmoid(z) ] DNNLayer(inDim, outDim, x, parmScale) = [ W = Parameter(outDim, inDim, init=“uniform”, initValueScale=parmScale) b = Parameter(outDim, 1, init=“uniform”, initValueScale=parmScale) t = Times(W, x) z = Plus(t, b) ]
如你所見,這些運算步驟都是標準的線性代數運算形式W*x+b。
圖定義的最后部分是交叉熵和誤差節點,以及將它們綁定到特殊的節點名稱。
我們接著要來定義訓練的過程,但是先把它與用TensorFlow構建相似的網絡模型做個比較。我們在之前的文章里討論過這部分內容,這里再討論一次。你是否注意到我們使用了與CNTK相同的一組變量,只不過這里我們把它稱作變量,而在CNTK稱作參數。維度也略有不同。盡管卷積濾波器都是5x5,在CNTK我們前后兩級分別使用了16個和32個濾波器,但是在TensorFlow的例子里我們用的是32個和64個。
defweight_variable(shape, names):initial = tf.truncated_normal(shape, stddev=0.1) returntf.Variable(initial, name=names) defbias_variable(shape, names):initial = tf.constant(0.1, shape=shape) returntf.Variable(initial, name=names) x = tf.placeholder(tf.float32, [None, 784], name=“x”) sess = tf.InteractiveSession() W_conv1 = weight_variable([5, 5, 1, 32], “wconv”) b_conv1 = bias_variable([32], “bconv”) W_conv2 = weight_variable([5, 5, 32, 64], “wconv2”) b_conv2 = bias_variable([64], “bconv2”) W_fc1 = weight_variable([7* 7* 64, 1024], “wfc1”) b_fc1 = bias_variable([1024], “bfcl”) W_fc2 = weight_variable([1024, 10], “wfc2”) b_fc2 = bias_variable([10], “bfc2”)
網絡的構建過程也大同小異。
defconv2d(x, W):returntf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding=‘SAME’) defmax_pool_2x2(x):returntf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding=‘SAME’) #first convolutional layerx_image = tf.reshape(x, [-1,28,28,1]) h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) h_pool1 = max_pool_2x2(h_conv1) #second convolutional layerh_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) h_pool2 = max_pool_2x2(h_conv2) #final layerh_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
卷積運算的唯一不同之處是這里定義了補零,因此第一次卷積運算的輸出是28x28,經過池化后,降為14x14。第二次卷積運算和池化之后的結果降為了7x7,所以最后一層的輸入是7x7x64 = 3136維,有1024個隱藏節點(使用relu而不是sigmoid函數)。(在訓練時,最后一步用到了dropout函數將模型數值隨機地置零。如果keep_prob=1則忽略這步操作。)
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%
下載地址
代碼分析CNTK和TensorFlow高層次的對比下載
相關電子資料下載
- 【風火輪YY3568開發板免費體驗】第六章:在Solus上運行自定義模型并遷移到YY3 411
- 深度學習框架tensorflow介紹 480
- 深度學習框架pytorch介紹 454
- 【米爾MYC-JX8MPQ評測】+ 運行 TensorFlow Lite(CPU和NPU對比) 524
- 手把手帶你玩轉—i.MX8MP開發板移植官方NPU TensorFlow例程 444
- 在樹莓派64位上安裝TensorFlow 505
- TensorFlow Lite for MCUs - 網絡邊緣的人工智能 339
- 2023年使用樹莓派和替代品進行深度學習 1506
- 用TensorFlow2.0框架實現BP網絡 1849
- 那些年在pytorch上踩過的坑 571