機器學習之模型評估和優化
大小:0.5 MB 人氣: 2017-10-12 需要積分:1
標簽:機器學習(129859)
監督學習的主要任務就是用模型實現精準的預測。我們希望自己的機器學習模型在新數據(未被標注過的)上取得盡可能高的準確率。換句話說,也就是我們希望用訓練數據訓練得到的模型能適用于待測試的新數據。正是這樣,當實際開發中訓練得到一個新模型時,我們才有把握用它預測出高質量的結果。
因此,當我們在評估模型的性能時,我們需要知道某個模型在新數據集上的表現如何。這個看似簡單的問題卻隱藏著諸多難題和陷阱,即使是經驗豐富的機器學習用戶也不免陷入其中。我們將在本文中講述評估機器學習模型時遇到的難點,提出一種便捷的流程來克服那些棘手的問題,并給出模型效果的無偏估計。
問題:過擬合與模型優化
假設我們要預測一個農場谷物的畝產量,其畝產量與農場里噴灑農藥的耕地比例呈一種函數關系。我們針對這一回歸問題已經收集了100個農場的數據。若將目標值(谷物畝產量)與特征(噴灑農藥的耕地比例)畫在坐標系上,可以看到它們之間存在一個明顯的非線性遞增關系,數據點本身也有一些隨機的擾動(見圖1)。
為了描述評價模型預測準確性所涉及的一些挑戰,我們從這個例子說開去。
圖1:信噪比
現在,假設我們要使用一個簡單的非參數回歸模型來構建耕地農藥使用率和谷物畝產量的模型。最簡單的機器學習回歸模型之一就是內核平滑技術。內核平滑即計算局部平均:對于每一個新的數據來說,用與其特征值接近的訓練數據點求平均值來對其目標變量建模。唯一一個參數——寬參數,是用來控制局部平均的窗口大小。
圖2演示了內核平滑窗寬參數取值不同所產生的效果。窗寬值較大時,幾乎是用所有訓練數據的平均值來預測測試集里每個數據點的目標值。這導致模型很平坦,對訓練數據分布的明顯趨勢欠擬合(under-fit)了。同樣,窗寬值過小時,每次預測只用到了待測數據點周圍一兩個訓練數據。因此,模型把訓練數據點的起伏波動完完全全地反映出來。這種疑似擬合噪音數據而非真實信號的現象被稱為過擬合(over-fitting)。我們的理想情況是處于一個平衡狀態:既不欠擬合,也不過擬合。
圖2:三種平滑回歸模型對谷物產量數據的擬合。
現在,我們再來重溫一遍問題:判斷分析機器學習模型對預測其它農場的谷物產量的泛化能力。這個過程的第一步就是選擇一個能反映預測能力的評估指標(evaluation metric)。對于回歸問題,標準的評估方法是均方誤差(MSE),即目標變量的真實值與模型預測值的誤差平方的平均值。
這正是令人棘手的地方。當我們擬合訓練數據時,模型預測的誤差(MSE)隨著窗寬參數的減小而減小。這個結果并不出人意料:因為模型的靈活度越高,它對訓練數據模式(包括信號和噪音)的擬合度也越好。然而,由于窗寬最小的模型擬合了訓練數據的每一處隨機因素導致的波動,它在訓練數據集上出現了嚴重的過擬合情況。若用這些模型來預測新的數據將會導致糟糕的準確率,因為新數據的噪音與訓練數據的噪音模式不盡相同。
所以,訓練集的誤差和機器學習模型的泛化誤差(generalization error)存在分歧。在圖3所示谷物產量數據的例子中可以看到這種分歧。對于較小的窗口參數值,訓練數據集的MSE非常小,而在新數據(10000個新數據)上的MSE則大得多。簡單地說,一個模型在訓練集上的預測效果并不能反映出它在新數據集上的預測效果。因此,把模型的訓練數據直接當作驗證數據是一件非常危險的事情。
使用訓練數據的注意事項
用同一份訓練數據來擬合模型和評價模型,會使得你對模型的效果過于樂觀。這可能導致你最終選擇了一個次優的模型,在預測新數據時表現平平。
如我們在谷物產量的例子中所見,若按照最小化訓練集MSE的原則優化,則得到窗寬參數最小的模型。這個模型在訓練集上的MSE為0.08。但是,若用新的數據測試,同樣的模型得到的MSE達到0.50,效果比優化模型糟糕的多(窗寬0.12,MSE=0.27)。
我們需要一個評價指標,能更好地估計模型在新數據集上的效果。這樣,我們在用模型預測新數據集時有把握取得一個較好的準確率。下一節我們將討論這個話題。
圖3:谷物產量回歸問題,訓練集上誤差和新數據集上誤差的比較。訓練集誤差過于樂觀地反映了模型在新數據集上的效果,尤其是在窗寬參數值較小的情況下。很顯然,用模型在訓練集上的誤差來替代其在新數據集上的誤差,會給我們帶來許多麻煩。
解決方案:交叉驗證
我們已經剖析了模型評估的難解之處:模型在訓練集數據上的誤差不能反映其在新數據集上的誤差情況。為了更好地估計模型在新數據集上的錯誤率,我們必須使用更復雜的方法,稱作交叉驗證(cross validation),它嚴格地使用訓練集數據來評價模型在新數據集上的準確率。
兩種常用的交叉驗證方法是holdout方法和K-fold交叉驗證。
Holdout 方法
同一份訓練數據既用于數據擬合又用于準確率評估,會導致過度樂觀。最容易的規避方法是分別準備訓練和測試的兩個子數據集,訓練子集僅用于擬合模型,測試子集僅用于評估模型的準確率。
這個方法被稱作是holdout方法,因為隨機地選擇一部分訓練數據僅用于訓練過程。通常保留30%的數據作為測試數據。holdout方法的基本流程如圖4所示,Python的偽代碼詳見列表1.
圖4:Holdout交叉驗證的流程圖。深綠色的方塊表示目標變量。
# assume that we begin with two inputs:# features - a matrix of input features# target - an array of target variables# corresponding to those featuresN= features.shape[0] N_train= floor(0.7 * N) # randomly select indices for the training subsetidx_train= random.sample(np.arange(N), N_train) # break your data into training and testing subsetsfeatures_train= features[idx_train,:] target_train= target[idx_train] features_test= features[~idx_train,:] target_test= target[~idx_train] # build a model on the training setmodel= train(features_train, target_train) # generate model predictions on the testing setpreds_test= predict(model, features_test) # evaluate the accuracy of the predictionsaccuracy= evaluate_acc(preds_test, target_test)
列表1:Holdout方法的交叉驗證
我們接下去把Holdout方法應用于谷物產量的數據集上。對于不同的窗寬參數,我們應用Holdout方法(三七開)并且在剩余的30%數據上計算預測值的MSE。圖5演示了Holdout方法得到的MSE是如何估計模型在新數據集上的MSE。有兩點需要關注:
Holdout方法計算得到的誤差估計非常接近模型在“新數據集”的誤差。它們確實比用訓練集數據得到的誤差估計更接近(圖3),尤其是對于窗口參數值較小的情況。
Holdout方法的誤差估計有很多噪音。相比從新數據得到的光滑的誤差曲線,其跳躍波動很厲害。
我們可以反復地隨機切分訓練-測試數據集,對結果求平均值,以減小噪音影響。然而,在多次迭代中,每一個數據點被分配到測試數據集的概率并不一定,這將導致我們的結果存在偏差。
更好的一種方法是K-fold交叉驗證。
圖5:在谷物產量數據集上比較Holdout方法的MSE與新數據集的MSE。Holdout誤差是每個模型在新數據集上的一個無偏誤差估計。但是,它的估計值存在很大的噪音,在優化模型的窗寬附近(窗寬=0.12)其誤差波動范圍是0.14~0.40。
K-Fold交叉驗證
一種更好,但是計算量更大的交叉驗證方法是K-fold交叉驗證。如同Holdout方法,K-fold交叉驗證也依賴于訓練數據的若干個相互獨立子集。主要的區別在于K-fold交叉驗證一開始就隨機把數據分割成K個不相連的子集,成為folds(一般稱作K折交叉驗證,K的取值有5、10或者20)。每次留一份數據作為測試集,其余數據用于訓練模型。
當每一份數據都輪轉一遍之后,將預測的結果整合,并與目標變量的真實值比較來計算準確率。K-fold交叉驗證的圖形展示如圖6所示,列表2是偽代碼。
圖6: K-fold交叉驗證的流程圖。
最后,我們把K-fold方法用于谷物產量數據集上。對于不同從窗寬參數,我們選擇K=10的K-fold交叉驗證方法,并計算預測值的準確率。圖7演示了K-fold方法得到的MSE是如何估計模型在新數據集上的MSE。顯然,K-fold交叉驗證的誤差估計非常接近模型在新數據上的誤差值。
# assume that we beginwithtwo inputs: # features - a matrix ofinputfeatures # target - an array oftarget variables # correspondingtothose features N = features.shape[0] K = 10# numberoffolds preds_kfold = np.empty(N) folds = np.random.randint(0, K, size=N) # loop through the cross-validation folds forii innp.arange(K): # break your data intotraining andtesting subsets features_train = features[folds != ii,:] target_train = target[folds != ii] features_test = features[folds == ii,:] # build a model onthe training setmodel = train(features_train, target_train) # generate andstore model predictions onthe testing setpreds_kfold[folds == ii] = predict(model, features_test) # evaluate the accuracy ofthe predictions accuracy = evaluate_acc(preds_kfold, target)
列表2:K-fold交叉驗證
圖7:在谷物產量數據集上比較K-fold方法的MSE與新數據集的MSE。K-fold交叉驗證得到的誤差很好地驗證了模型在新數據集上的效果,使得我們能夠大膽地估計模型的誤差以及選擇最優模型。
使用交叉驗證的幾點注意事項
交叉驗證為我們在實際使用機器學習模型時提供了一種估計準確率的方法。這非常有用,使得我們能夠挑選出最適于任務的模型。
但是,在現實數據中應用交叉驗證方法還有幾點注意事項需要關注:
在K-fold方法交叉驗證中K的值選的越大,誤差估計的越好,但是程序運行的時間越長。
解決方法:盡可能選取K=10(或者更大)。對于訓練和預測速度很快的模型,可以使用leave-one-out的教程驗證方法(即K=數據樣本個數)。
交叉驗證方法(包括Holdout和K-fold方法)假設訓練數據的分布能代表整體樣本的分布。如果你計劃部署模型來預測一些新數據,那么這些數據的分布應該和訓練數據一致。如果不一致,那么交叉驗證的誤差估計可能會對新數據集的誤差更加樂觀。
解決方法:確保在訓練數據中的任何潛在的偏差都得到處理和最小化。
一些數據集會用到時序相關的特征。例如,利用上個月的稅收來預測本月的稅收。如果你的數據集也屬于這種情況,那你必須確保將來的特征不能用于預測過去的數值。
解決方法:你可以構造交叉驗證的Holdout數據集或者K-fold,使得訓練數據在時序上總是早于測試數據。
總結
我們一開始討論了模型評價的通用法則。很顯然,我們不能交叉使用同一份訓練數據,不能既用來訓練又用來評估。相反,我們引入了交叉驗證這種更可靠的模型評價方法。
Holdout是最簡單的交叉驗證方法,為了更好地估計模型的通用性,分割一部分數據作為待預測的測試數據集。
K-fold交叉驗證 —— 每次保留K份數據中的一份 —— 能夠更確定地估計模型的效果。這種改進的代價來自于更高的計算成本。如果條件允許,K等于樣本數目時能得到最好的估計,也稱為leave-one-out方法。
介紹了模型評價的基本流程。簡單來說就是:
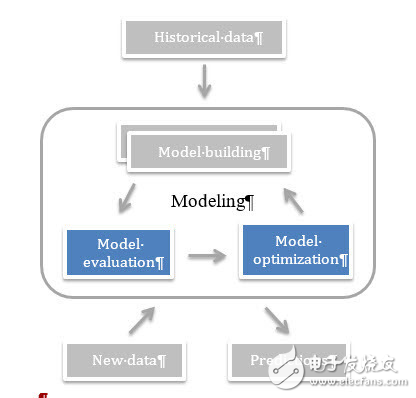
獲取數據并做建模前的預處理(第二章),并且確定合適的機器學習模型和算法(第三章)。構建模型,并根據計算資源選擇使用Holdout或者K-fold交叉驗證方法預測數據。用所選取的指標評估預測結果。如果是分類的機器學習方法,在4.2節里會介紹常見的效果評價指標。同樣,我們會在4.3小節介紹回歸問題的常用評價指標。不斷調整數據和模型,直到取得理想的效果。在5~8章中,我們會介紹真實場景下用于提高模型效果的常用方法。
對于分類模型,我們介紹了幾個用于上述流程中步驟3的模型性能指標。這些技術包括簡單的準確率計算,混淆矩陣,ROC,ROC曲線和ROC曲線下面積。
在回歸模型中,我們介紹了均方根誤差(rMSE)與R平方估計(R-squared),我們討論了簡單的可視化,如預測與實際的散點圖和殘差圖。
我們介紹了調整參數的概念,并展示了如何使用網格搜索算法的參數優化模型。
英文概念
中文概念
定義
Under/over-fitting 欠擬合/過擬合 使用了過于簡單/復雜的模型。
Evaluation metric 評價指標 一個衡量模型效果的數值。
Mean squared error 均方差 回歸模型所使用的一種評價指標。
Cross-validation 交叉驗證 為了更好地估計準確率,把訓練數據分成2份(或者多份)獨立的訓練/測試數據集的方法。
Holdout method Holdout方法 一種交叉驗證的方法,保留一份測試數據集用于模型測試。
K-fold cross-validation K折交叉驗證 一種交叉驗證的方法,數據集被分為K份獨立的子集,每次取出一份作為測試集,其余數據用來訓練模型。
Confusion matrix 混淆矩陣 用于比較分類結果和實際測得值的一種矩陣。
ROC - Receiver operator characteristic ROC 一種用于記錄真陽性、假陽性、真陰性、假陰性的數值。
AUC - Area under the ROC curve ROC曲線下面積 ROC曲線下方的面積大小。
Tuning parameter 調整參數 機器學習算法的一個內部參數,比如內核平滑回歸算法的窗寬參數。
Grid search 網格搜索 優化模型參數時采用的一種暴力搜索策略。
?
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%