HBase分布式事務與SQL實現
大小:0.5 MB 人氣: 2017-10-13 需要積分:1
目前看NewSQL代表未來(Google Spanner、F1、FoundationDB),HBase在國內有六個Committer,在目前主流的開源數據庫里面幾乎是最強的陣容。大家選型的時候會有一個猶豫,到底應該選擇HBase還是選Cassandra。根據應用場景,如果需要一致性,HBase一定是你最好的選擇,我推薦HBase。它始終保持強一致,我們非常喜歡一致性,喪失一致性的時候有些錯誤會特別詭異,很難查。對于Push-down特性的設計其實比較好,全局上是一個巨大的分布式數據庫,但是邏輯上是分成了一個個Region,Region在哪臺機器上是明確的。
比如要統計記錄的條數,假設數據分布在整個系統里面,對數十億記錄做一個求和操作,就是說不同的機器上都要做一個sum,把條件告訴他要完成哪些任務,他給你任務你再匯總,這是典型的分布式的 MPP,做加速的時候是非常有效的。
2015年HBaseConf 上面有一句總結: “Nothing is hotter than SQL-on-Hadoop, and now SQL-on- HBase is fast approaching equal hotness status”, 實際上SQL-on-HBase 也是非常火。因為 Schema Less 沒有約束其實是很嚇人的一件事情,當然沒有約束也比較爽,就是后期維護十分痛苦,規模進一步擴大了之后又需要遷移到 SQL。
現在無論從品質還是速度上要求已經越來越高,擁有SQL的同時還希望有ACID的東西(OLAP一般不追求一致性)。所以TiDB在設計時就強調這樣的特點:始終保持分布式事務的支持,兼容MySQL協議。無數公司在SQL遇到Scale問題的時候很痛苦地做出了選擇,比如遷移到HBase,Cassandra MongoDB已經看過太多的公司做這種無比痛苦的事情,現在不用痛苦了,直接遷過來,直接把數據導進來就OK了。TiDB最重要的是關注OLTP,對于互聯網業務來說通常是在毫秒級內就需要返回一個結果。
我們到目前為止開發了六個月,開源了兩個月。昨天晚上TiDB達到了第一個Alpha的階段,現在可以擁有一個強大的數據庫:支持分布式事務,始終保持同步的復制,強大的按需Scale能力,無阻塞的Schema變更。發布第一個Alpha版本的時候以前的質疑都會淡定下來,因為你可以閱讀每一行代碼,體驗每個功能。選擇這個領域也是非常艱難的決定,實在太Hardcore了,當初Google Spanner也做了5年。不過我們是真愛,我們就是技術狂,就是要解決問題,就是要挑大家最頭痛的問題去解決。好在目前阿里的OceanBase給我們服了顆定心丸,大家也不會質疑分布式關系型數據庫是否可行。
TiDB名字由來
為什么叫TiDB?大家起名字的時候特別喜歡用希臘神話里面的人物,但幾乎所有的希臘神話人物的名字都被別的項目使用了,后來我們就找了化學元素周期表(理工科男與生俱來的特征),化學元素周期表里找到一個不俗且又能代表我們數據庫特性的元素-Ti 。Ti是航空航天及航海里面很重要的設備都會用到的,特別穩定,也比較貴。
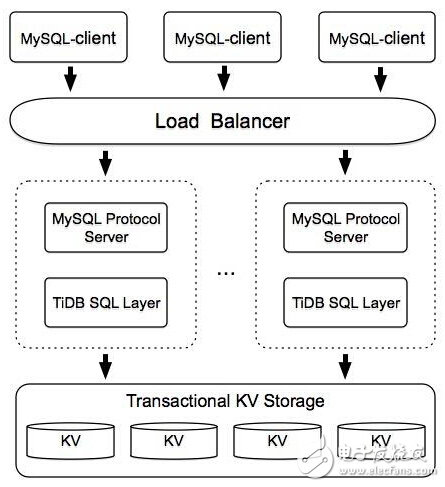
TiDB的系統架構圖
TiDB怎么支持MySQL這個協議?這里會有一個協議解析層,它的作用就是去分析MySQL協議,轉成內部可以識別的分發給自己的SQL Layer。當SQL Layer 拿到這個語句之后會把它拆成對應的分布式KV操作,所以這里會有一個Transactional KV Storage。接下來是在KV基礎上增加事務的支持,再往上是普通的KV操作,理論上KV選什么都可以,如果選的是HBase有一個好處,它本身就是分布式,省掉分布式的工作。目前我們在小米的Themis基礎上做了些優化和改進,和我們TiDB做了一個很好的結合。后期我們有一個計劃,準備自己重寫一套底層的分布式KV,把HBase換掉。因為HBase對于Container不友好,加上GC也是讓人比較討厭的問題,壓力比較大的時候GC延遲會加長。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%