一種聚類個數自適應的聚類方法(簡稱SKKM)
大小:0.82 MB 人氣:12 2017-11-03 需要積分:0


標簽:SKKM(1931)
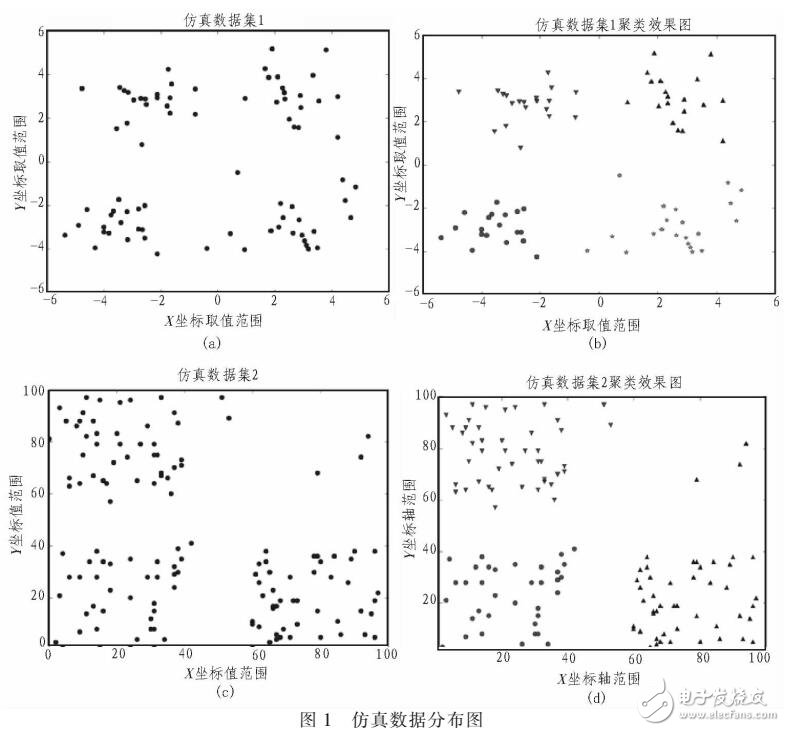
在數據挖掘算法中,K均值聚類算法是一種比較常見的無監督學習方法,簇間數據對象越相異,簇內數據對象越相似,說明該聚類效果越好。然而,簇個數的選取通常是由有經驗的用戶預先進行設定的參數。本文提出了一種能夠自動確定聚類個數,采用SSE和簇的個數進行度量,提出了一種聚類個數自適應的聚類方法(簡稱:SKKM)。通過UCI數據和仿真數據對象的實驗,對SKKM算法進行了驗證,實驗結果表明改進的算法可以快速的找到數據對象中聚類個數,提高了算法的性能。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%