基于檢索結果排序的偽相關反饋
大小:0.76 MB 人氣: 2017-12-13 需要積分:3
標簽:排序(9674)
隨著Web的普及,越來越多的用戶希望從互聯網上獲取信息。對于目前主流的基于關鍵詞的搜索方式,用戶必須通過構造有限的查詢詞來表達信息需求( information need)。Carpineto等在查詢擴展綜述中明確指出,大多數用戶喜歡構造短查詢交給搜索引擎,且構造的查詢詞多以1-3個詞居多;并且用戶的查詢構造本身就是一個抽象的過程,查詢構造結果具有模糊性、不確定性和描述的多樣性。在這種情況下,由于缺乏上下文語境,搜索引擎很難完全理解用戶的查詢意圖,返回的結果中經常會包含大量無關或相似的文檔。特別是當查詢詞出現歧義時,返回的文檔集會偏向于某一個主題,而該主題往往并不是用戶潛在查詢意圖。如果搜索引擎能夠將與用戶初始查詢構造相關的信息全部返回給用戶,那么,用戶就可以在多個不同查詢結果中找到自己最想要的結果。
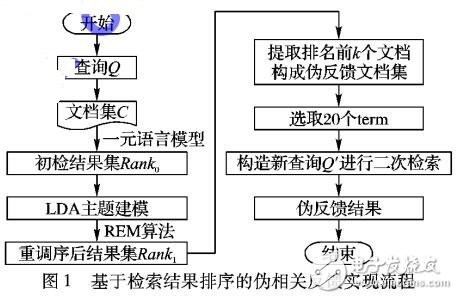
針對傳統偽相關反饋(PRF)算法擴展源質量不高使得檢索效果不佳的問題,提出一種基于檢索結果的排序模型( REM)。首先,該模型從初檢結果中選擇排名靠前的文檔怍為偽相關文檔集;然后,以用戶查詢意圖與偽相關文檔集中各文檔的相關度最大化、并且各文檔之間相似性最小化作為排序原則,將偽相關文檔集中各文檔進行重排序;最后,將排序后排名靠前的文檔作為擴展源進行二次反饋。實驗結果表明,與兩種傳統偽反饋方法相比,該排序模型能獲得與用戶查詢意圖相關的反饋文檔,可有效地提高檢索效果。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%
下載地址
基于檢索結果排序的偽相關反饋下載
相關電子資料下載
- 手把手教你排序算法怎么寫 437
- FPGA實現雙調排序方法詳解 195
- 用FPGA實現雙調排序的方法(2) 427
- FPGA實現雙調排序算法的探索與實踐 205
- 想聽聽48和大對數光纜的排序? 211
- C語言實現經典排序算法概覽 298
- 十大排序算法總結 830
- 時間復雜度為O (nlogn)的排序算法簡述 378
- 數據結構:單鏈表的排序 600
- python中如何交換兩個數的值相加 460