基于頻繁模式樹的最大頻繁項集挖掘算法
大小:0.58 MB 人氣: 2018-01-15 需要積分:2
標簽:挖掘算法(7655)
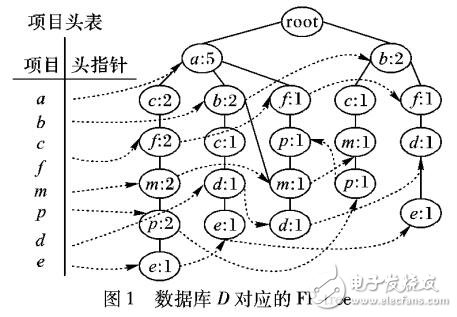
針對最大頻繁項目集挖掘算法( DMFIA)當候選項目集維數(shù)高而最大頻繁項目集維數(shù)較低的情況下要產(chǎn)生大量的候選項目集的缺點,提出了一種改進的基于頻繁模式樹( FP-tree)結(jié)構(gòu)的最大頻繁項目集挖掘算法-FP-MFIA。該算法根據(jù)FP-tree的項目頭表,采用自底向上的搜索策略逐層挖掘最大頻繁項目集,從而加速每次對候選集計數(shù)的操作。在挖掘時根據(jù)每層的條件模式基產(chǎn)生維數(shù)較低的非頻繁項目集,盡早對候選項目集進行剪枝和降維,可大量減少候選項目集的數(shù)量。同時在挖掘時充分利用最大頻繁項集的性質(zhì),減少搜索空間。通過算法在不同支持度下挖掘時間的對比可知,算法FP-MFIA在最小支持度較低的情況下時間效率是DMFIA以及基于降維的最大頻繁模式挖掘算法( BDRFI)的2倍以上,說明FP-MFIA在候選集維數(shù)較高的時候優(yōu)勢明顯。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%