 電子發燒友App
電子發燒友App


隨著互聯網、尤其是物聯網的發展,我們需要把各種類型的終端實時監測、檢查與分析設備所采集、產生的數據記錄下來,在有時間的坐標中將這些數據連點成線,往過去看可以做成多緯度報表,揭示其趨勢性、規律性、異常性;往未來看可以做大數據分析,機器學習,實現預測和預警。
這些數據的典型特點是:產生頻率快(每一個監測點一秒鐘內可產生多條數據)、嚴重依賴于采集時間(每一條數據均要求對應唯一的時間)、測點多信息量大(實時監測系統均有成千上萬的監測點,監測點每秒鐘都產生數據,每天產生幾十GB的數據量)。
基于時間序列數據的特點,關系型數據庫無法滿足對時間序列數據的有效存儲與處理,因此迫切需要一種專門針對時間序列數據來做優化處理的數據庫系統。
一、簡介
1、時序數據
時序數據是基于時間的一系列的數據。
2、時序數據庫
時序數據庫就是存放時序數據的數據庫,并且需要支持時序數據的快速寫入、持久化、多緯度的聚合查詢等基本功能。
對比傳統數據庫僅僅記錄了數據的當前值,時序數據庫則記錄了所有的歷史數據。同時時序數據的查詢也總是會帶上時間作為過濾條件。
3、OpenTSDB
毫無遺漏的接收并存儲大量的時間序列數據。
3.1、存儲
無需轉換,寫的是什么數據存的就是什么數據
時序數據以毫秒的精度保存
永久保留原始數據
3.2、擴展性
運行在Hadoop 和 HBase之上
可擴展到每秒數百萬次寫入
可以通過添加節點擴容
3.3、讀能力
直接通過內置的GUI來生成圖表
還可以通過HTTP API查詢數據
另外還可以使用開源的前端與其交互
4、OpenTSDB核心概念
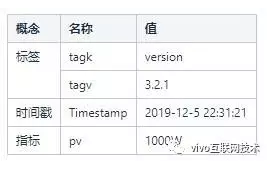
我們來看一下這樣一段信息:2019-12-5 22:31:21版本號為‘3.2.1’的某產品客戶端的首頁PV是1000W
Metric:指標,即平時我們所說的監控項。譬如上面的PV
Tags:維度,也即標簽,在OpenTSDB里面,Tags由tagk和tagv組成的鍵值對,即tagk=takv。標簽是用來描述Metric的,比如上面的某產品客戶端的版本號 version=‘3.2.1’
Value:一個Value表示一個metric的實際數值,比如:1000W
Timestamp:即時間戳,用來描述Value是什么時候發生的:比如:2019-12-5 22:31:21
Data Point:即某個Metric在某個時間點的數值,Data Point包括以下部分:Metric、Tags、Value、Timestamp
保存到OpenTSDB的數據就是無數個DataPoint
上面描述2019-12-5 22:31:21版本號為‘3.2.1’的某產品客戶端的首頁PV是1000W,就是1個DataPoint。
二、OpenTSDB的部署架構
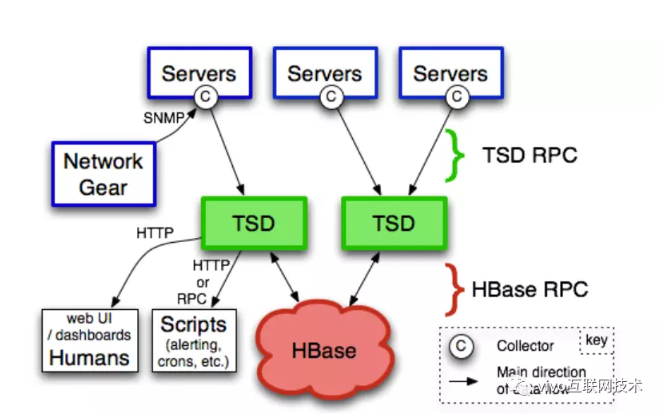
1、架構圖
2、說明
OpenTSDB底層是使用HBase來存儲數據的,也就是說搭建OpenTSDB之前,必須先搭建好HBase環境。
OpenTSDB是由一系列的TSD和實用的命令行工具組成。
應用通過運行一個或多個tsd(Time Series Daemon, OpenTSDB的節點)來與OpenTSDB的交互。
每個TSD是獨立的,沒有master,沒有共享狀態,所以你可以運行盡可能多的 TSD 來處理工作負載。
三、HBase簡介
從OpenTSDB的部署架構中我們看到OpenTSDB是建立在HBase之上的,那么HBase又是啥呢?為了更好的剖析OpenTSDB,這里我們簡要介紹一下HBase。
1、HBase是一個高可靠性、強一致性、高性能、面向列、可伸縮、實時讀寫的分布式開源NoSQL數據庫。
2、HBase是無模式數據庫,只需要提前定義列簇,并不需要指定列限定符。同時它也是無類型數據庫,所有數據都是按二進制字節方式存儲的。
3、它把數據存儲在表中,表按“行鍵,列簇,列限定符和時間版本”的四維坐標系來組織,也就是說如果要唯一定位一個值,需要四個都唯一才行。下面參考Excel來說明一下:

4、對 HBase 的操作和訪問有 5 個基本方式,即 Get、Put、Delete 和 Scan 以及 Increment,HBase 基于非行鍵值查詢的唯一途徑是通過帶過濾器的掃描。
5、數據在HBase中的存儲(物理上):
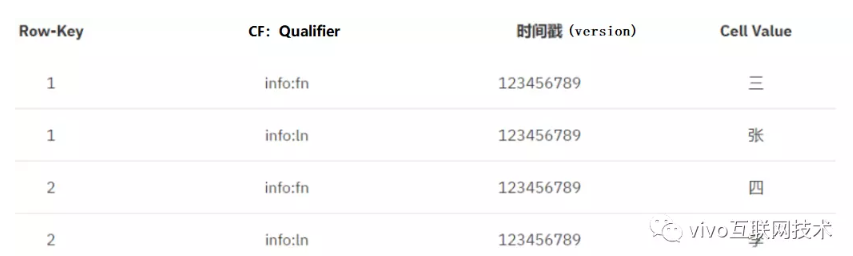
6、數據在HBase中的存儲(邏輯上):

四、 支撐OpenTSDB運行的HBase表
如果你第一次用你的HBase實例運行OpenTSDB,需要創建必要的HBase表,OpenTSDB 運行僅僅需要四張表:tsdb, tsdb-uid, tsdb-tree 和 tsdb-meta,所有的DataPoint 數據都保存在這四張表中,建表語句如下:
1、tsdb-uid
|
1 2 3 |
create 'tsdb-uid', {NAME => 'id', COMPRESSION => 'NONE', BLOOMFILTER => 'ROW', DATA_BLOCK_ENCODING => 'PREFIX_TREE'}, {NAME => 'name', COMPRESSION => 'NONE', BLOOMFILTER => 'ROW', DATA_BLOCK_ENCODING => 'PREFIX_TREE'} |
2、tsdb
|
1 2 |
create 'tsdb', {NAME => 't', VERSIONS => 1, COMPRESSION => 'NONE', BLOOMFILTER => 'ROW', DATA_BLOCK_ENCODING => 'PREFIX_TREE'} |
3、tsdb-tree
|
1 2 |
create 'tsdb-tree', {NAME => 't', VERSIONS => 1, COMPRESSION => 'NONE', BLOOMFILTER => 'ROW', DATA_BLOCK_ENCODING => 'PREFIX_TREE'} |
4、tsdb-meta
|
1 2 |
create 'tsdb-meta', {NAME => 'name', COMPRESSION => 'NONE', BLOOMFILTER => 'ROW', DATA_BLOCK_ENCODING => 'PREFIX_TREE'} |
后面將對照實際數據來專門講解這四張表分別存儲的內容。
五、 OpenTSDB是如何把一個數據點保存到HBase中的呢?
1、首先檢查一下四個表里面的數據
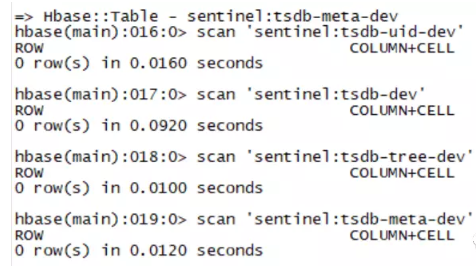
從上面看,四個表里面的數據都是空的
2、然后我們往OpenTSDB寫一個數據點
|
1 2 3 4 5 6 7 8 9 10 |
@Test public void addData() { ????String metricName = "metric"; ????long value = 1; ????Map tags = new HashMap(); ????tags.put("tagk", "tagv"); ????long timestamp = System.currentTimeMillis(); ????tsdb.addPoint(metricName, timestamp, value, tags); ????System.out.println("------------"); } |
3、插入數據之后我們再來查看一下四個表數據
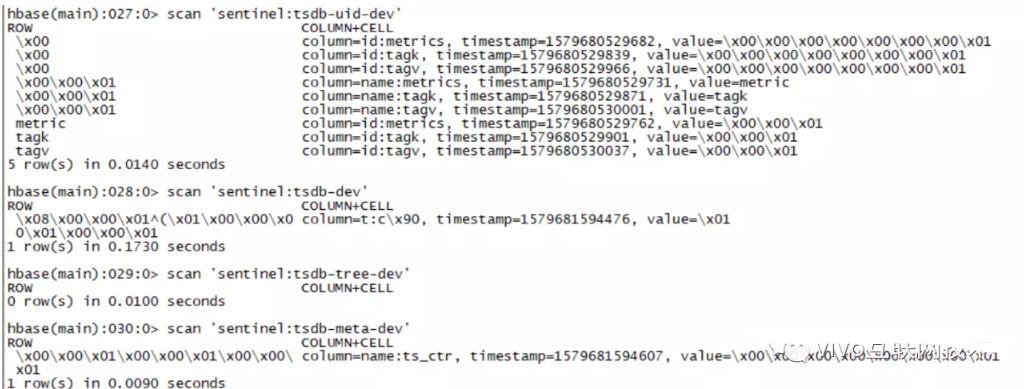
發現HBase里面有數據,在tsdb-uid、tsdb、和 tsdb-meta 表里面有數據,而tsdb-tree 表里面沒任何數據,下面我們針對這些數據做一下具體分析。
4、tsdb-tree表
它是一張索引表,用于展示樹狀結構的,類似于文件系統,以方便其他系統使用,這里我們不做深入的分析。
通過配置項tsd.core.tree.enable_processing來打開是否需要往此表里面寫入數據。
5、tsdb-meta表
這個表是OpenTSDB中不同時間序列的一個索引,可以用來存儲一些額外的信息,該表只有一個列族name,兩個列,分別為ts_meta、ts_ctr。這個表里面的數據是可以根據配置項配置來控制是否生成與否,生成幾個列,具體的配置項有:
|
1 2 3 |
tsd.core.meta.enable_realtime_ts tsd.core.meta.enable_tsuid_incrementing tsd.core.meta.enable_tsuid_tracking |

Row Key?和tsdb表一樣,其中不包含時間戳,[...]
ts_meta?Column?和UIDMeta相似,其為UTF-8編碼的JSON格式字符串
ts_ctr Column 計數器,用來記錄一個時間序列中存儲的數據個數,其列名為ts_ctr,為8位有符號的整數。
6、tsdb-uid表數據分析
tsdb-uid用來存儲UID映射,包括正向的和反向的。存在兩列族,一列族叫做name用來將一個UID映射到一個字符串,另一個列族叫做id,用來將字符串映射到UID。列族的每一行都至少有以下三列中的一個:
metrics?將metric的名稱映射到UID
tagk?將tag名稱映射到UID
tagv?將tag的值映射到UID
如果配置了metadata,則name列族還可以包括額外的metatata列。

6.1、id 列族
Row Key:實際的指標名稱或者tagK或者tagV
Column Qualifiers:metrics、tagk、tagv三種列類型中一種
Column Value :?一個無符號的整數,默認是被編碼為3個byte,自增的數字,其值為UID
6.2、name 列族
Row Key :UID,就是ID列簇的值
Column Qualifiers:metrics、tagk、tagv、metrics_meta、tagk_meta、tagv_meta六種列類型中一種,*_meta是需要開啟tsd.core.meta.enable_realtime_uid才會生成
Column Value:與UID對應的字符串,對于一個*_meta列,其值將會是一個UTF-8編碼的JSON格式字符串。不要在OpenTSDB外部去修改該值,其中的字段順序會影響CAS調用。
7、tsdb表:
時間點數據就保存在此表中,只有一個列簇t:

7.1、RowKey格式
UID:默認編碼為3 Bytes,而時間戳會編碼為4 Bytes
salt:打散同一metric不同時間線的熱點
metric, tagK, tagV:實際存儲的是字符串對應的UID(在tsdb-uid表中)
timestamp:每小時數據存在一行,記錄的是每小時整點秒級時間戳

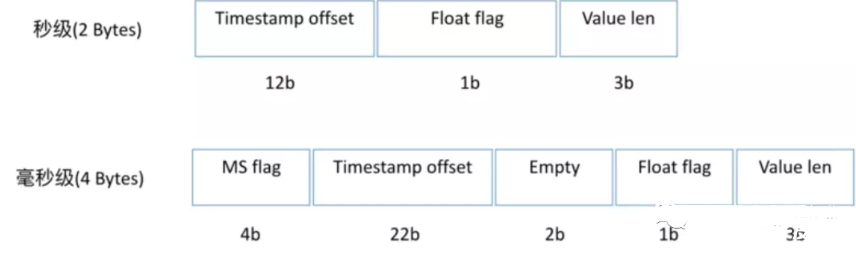
7.2、Column格式
column qualifier?占用2 Bytes或者4 Bytes,
占用2 Bytes時表示以秒為單位的偏移,格式為:
12 bits:相對row表示的小時的delta, 最多2^ 12 = 4096 > 3600因此沒有問題
1 bit: an integer or floating point
3 bits: 標明數據的長度,其長度必須是1、2、4、8。000表示1個byte,010表示2byte,011表示4byte,100表示8byte
占用4 Bytes時表示以毫秒為單位的偏移,格式為:
4 bits:十六進制的1或者F
22 bits:毫秒偏移
2 bit:保留
1 bit: an integer or floating point,0表示整數,1表示浮點數
3 bits: 標明數據的長度,其長度必須是1、2、4、8。000表示1個byte,010表示2byte,011表示4byte,100表示8byte
7.3、value
value 使用8 Bytes存儲,既可以存儲long,也可以存儲double。
7.4、tsdb表設計的特點:

metric和tag映射成UID,不存儲實際字符串,以節約空間。
每條時間線每小時的數據點歸在一行,每列是一個數據點,這樣每列只需要記錄與這行起始時間偏移,以節省空間。
每列就是一個KeyValue。
六、 寫在最后
1、應用場景
作為時序數據庫,OpenTSDB 不僅僅可以提供原始數據的查詢,并且還支持對原始數據的聚合能力,支持過濾、過濾之后的聚合計算。
支持降采樣查詢,比如原始數據是1分鐘一個數據點,如果我想1個小時一個數據點進行展示,也能支持。
支持根據維度分組查詢,比如我有一個中國地市的數據,現在我想根據省份進行分組之后查詢,也能支持。
2、使用注意事項
OpenTSDB 默認情況下的字符集是ISO-8859-1,為什么會使用這個字符集呢,是因為它的編碼是單字節編碼,編碼后的長度是固定的,如果要支持中文,需要對源碼進行編譯,修改為UTF-8即可。
默認提供的HBase建表語句是沒有預分區的,這樣會導致大批量數據寫入的時候有熱點問題,建議進行預分區。
OpenTSDB不適合超大數據量,在千萬級、億級中提取幾萬條數據,比如某個指標半年內的5分鐘級別的數據,還是很快響應的。但如果再提取多點數據,幾十萬,百萬這樣的量級,又或者提取后再做個聚合運算,OpenTSDB 就勉為其難,實際使用的時候用作服務端機器的監控無任何問題,如果作為客戶端APP監控,響應就比較遲緩。
OpenTSDB 只有4 張HBase 表,所有的數據都存放在一張表,這就意味在OpenTSDB 這個層級上是無法更小的粒度來區別對待不同業務,比如不同的業務建不同的表存儲數據。
OpenTSDB 支持實時聚合計算功能,但是基于單點,所以運算能力有限。
3、展望
如果需要支持特大批量時序數據,建議使用Druid或InfluxDB,其中InfluxDB是最易用的時序數據庫。
編輯:hfy









 工商網監
工商網監
評論