 電子發燒友App
電子發燒友App


這些年來,記憶體領域出現了各種動態隨機存取記憶體(DRAM)標準,這些標準也都各自進一步發展出不同世代的版本。本文將回顧不同DRAM架構的特色,點出這些架構的共同趨勢與瓶頸,并會提出IMEC為了將DRAM性能推至極限而采取的相關發展途徑。
動態隨機存取記憶體(dynamic random access memory;DRAM)主要被用來當作電腦的主要記憶體,中央處理器(CPU)便是從該記憶體讀取指令。這些年來也出現了不同的DRAM標準,以滿足不同需求與應用。為了回應對頻寬越來越高的要求,這些標準都各自進一步發展出不同世代的版本。
IMEC系統記憶體架構師Timon Evenblij與計畫主持人Gouri Sankar Kar將于本文回顧不同DRAM架構的特色,并點出這些架構共同面對的趨勢與瓶頸。他們也會提出IMEC采取的相關發展途徑,以將DRAM性能推升至最終極限。
DRAM的基本概念
位元格(bit cell)
在開始探討不同的DRAM架構之前,我們先來了解DRAM的基本概念吧!以下說明以卡內基.梅隆大學Onur Mutlu教授的課程為基礎。
所有的記憶體都以位元格(bit cell)構成,它是恰好儲存1位元的半導體架構,因而得其名。對DRAM來說,其位元格包含了一個電容(capacitor)和一個晶體管(transistor);電容被用來儲存電荷,而晶體管則用以存取電容,不論是去讀取已儲存的電荷量,或是去儲存新的電荷。
字元線(wordline)一直與晶體管的閘極相連,以控制往電容的通道;位元線則與晶體管的源極相連,以讀取位元格內儲存的電荷,或是在寫入新的數值時提供位元格所需的電壓。這個基本架構很簡單且體積小,所以制造商可以在單一芯片上非常大量制造DRAM的位元格。
但其缺點是,單一晶體管不容易在其狹小的電容中保存電荷,電流會泄漏至電容或從電容中流出,導致晶體管漸漸失去定義完善的電荷狀態。但是這個問題可以透過定期更新(periodically refresh)DRAM記憶體來避免,也就是讀取DRAM記憶體的內容后再重新寫入。
有在專心閱讀的讀者可能已經發現問題了,當電荷自電容中讀取出來時,電荷就消失了。但是在讀取DRAM位元格的數值后,該數值應該要再重新寫入,這也是為何DRAM取名含有「動態」一詞。
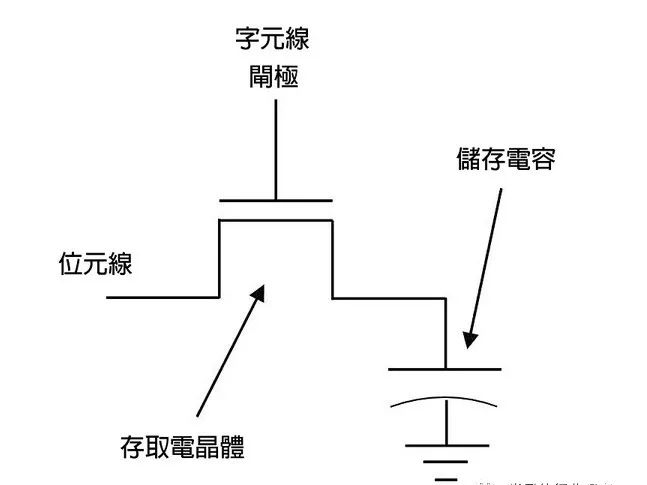
圖一: DRAM位元格的示意圖
進入位元格陣列
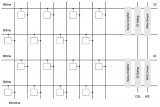
多個位元格可以整合成如矩陣般的大型架構。多條字元線和位元線相互交叉,而每個交叉點都有一個位元格在處理資料。而對某字元線施加電壓就能選出所有相應的位元格,這些位元格則會將電流傳至各自的位元線。這些電流將微幅改變每條位元線的電壓,這個小改變會由感測放大器(sense amplifier)偵測出來。
感測放大器這種結構會將小幅增加的電壓放大成高電壓(代表邏輯1),并把微幅降低的電壓放大成零電壓(代表邏輯0)。它也會將各個邏輯數值儲存至一個多閂(latches)結構,也就是所謂的列緩沖區(row buffer)。列緩沖區的功能就像是快取記憶體,因為位元格內的數值在讀取時會消失,所以在讀取某條字元線上的數個位元格時,列緩沖區就會保存讀取而來的數值。
感測這個步驟本身就是緩慢的過程,而電容越小、位元線越長時,感測時間就會延長。這段感測時間也決定了DRAM的存取時間,而在過去幾十年間,DRAM的感測時間一直維持不變。每一代DRAM的可用頻寬增長,皆是透過在DRAM芯片上運用更多平行處理能力來實現,而不是由縮短存取時間達成。
但在深入探討這個議題前,我們先來看看如何運用這些位元格來建構記憶體系統。這里談到的架構通常用于采用記憶體模組(memory module)的桌機系統。至于其他DRAM架構,它們并未采用模組的概念,但大多都能以相同的術語來描述其運作模式。
DRAM架構
在處理器上,有部份的邏輯電路是專門設計給記憶體控制器(memory controller)來使用,這些電路負責管理所有從CPU到主要記憶體的通道。
處理器可能有多個記憶體控制器,而記憶體控制器具備一個或多個記憶體通道(memory channel),每個通道包含一個指令或位址匯流排,以及一個資料匯流排(預設狀態下寬度為64位元)。
在該通道上,我們可以連接一個或多個記憶體模組,而每個記憶體模組包含一個或兩個秩(rank)。一個秩包含幾個DRAM芯片,這些芯片整合在一起就能在每個周期提供足夠的位元來填充資料匯流排。
在一般情況下,也就是資料匯流排為64位元寬且每芯片提供8位元的儲存空間(所謂的x8芯片),一個秩包含8個芯片。如果模組配有超過一個秩,這些秩會多工傳輸至同一個匯流排,所以不同秩不能同時向該匯流排傳輸資料。
每秩上的各芯片以相同速度同步運行,也就是說它們會一直執行完全相同的指令,且不能分開定址。這對接下來要說明的概念來說很重要:每個芯片包含數個記憶體庫(memory bank)—記憶體庫就是數個位元格所組成的大型矩陣,而位元格,如上所述,具備字元線、位元線、一個感測放大器以及列緩沖區。由于同一秩內的芯片會同步運行,所以記憶體庫一詞也可以指同一秩內的8個芯片上的8個記憶體庫。
在第一個案例,我們會使用「實體記憶庫」一詞,而在第二個案例,則偏好使用「邏輯記憶庫」一詞,但其實文獻資料并不總是清楚界定這些術語。
在介紹這些術語后,我們現在就可以來談談不同的DRAM架構和世代,以及它們如何奠基在彼此的架構上進行改良。我們一樣會先從個人電腦(PC)的常規DRAM模組談起。
DRAM標準
常規DDR
DRAM記憶體已經存在許久,但我們不會在此上一堂完整的歷史課。我們只會在開始討論雙倍數據傳輸率(double data rate;DDR)世代之前,先快速帶過單倍數據傳輸率(single date rate;SDR)記憶體。我們要了解SDR的重點,是其介面與資料匯流排的I/O時脈(IO clock)與記憶體的內存時脈(internal clock)頻率相同。這種記憶體受限于其內部記憶體的存取速度。
第一代DDR的目標是在每I/O時脈周期傳輸兩個資料字組(data word),一組在時脈升緣時傳輸,另一組則在降緣時傳輸。此傳輸模式的設計者采用了預取(prefetching)這個概念來實現將傳輸速率翻倍。一個被稱為「預取緩沖區(prefetch buffer)」的結構被插置在DRAM記憶體庫和輸出電路之間,這個小型緩沖區在每時脈周期、同一條匯流排上能夠儲存的位元數量,是原本SDR設計的兩倍。
就x8芯片而言,其預取緩沖區為16位元。我們將此稱作「2n」預取緩沖區。以讀取一整列DRAM的內存讀取周期來說,例如讀取一列包含2000行的數據,就會有很多資料能來填充該預取緩沖區。該緩沖區內也會有足夠的資料來填充匯流排,在時脈的升降兩緣分別傳遞一組字組。
這個預取概念也適用于DDR2架構,只是其預取緩沖區變成「4n」。如此,設計者就能將I/O時脈提升至內存時脈的兩倍,且在每周期內都能將資料匯流排填滿資料。以此類推,DDR3同樣將預取緩沖區的位元數翻倍(亦即「8n」),而其I/O時脈現在增至內存時脈的四倍。
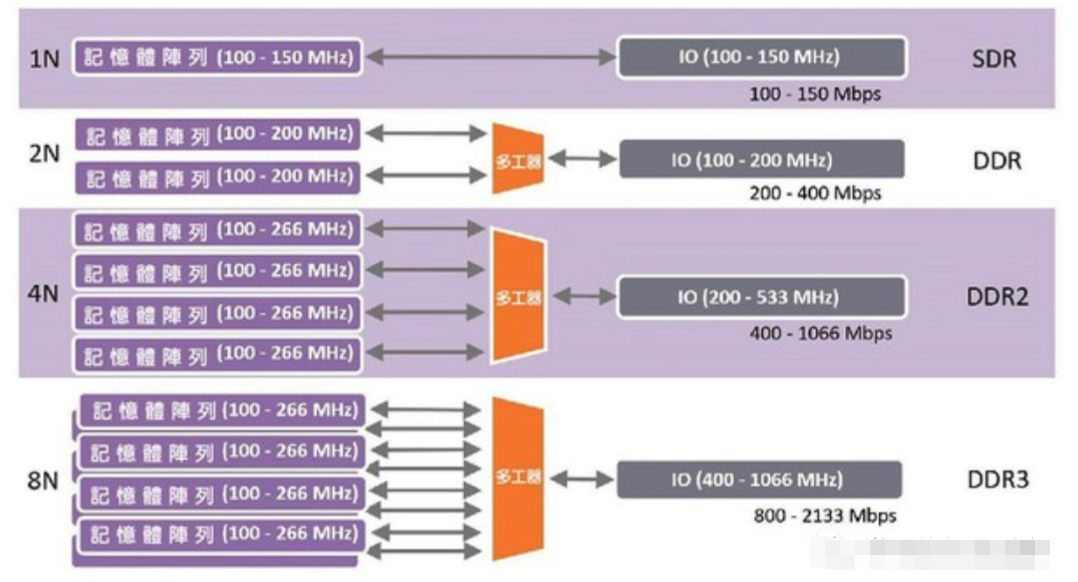
圖二: DDR的預取機制(source:synopsys)
但是,如此類推還是有個極限。將預取緩沖區的傳輸位元數再度翻倍以達到「16n」,意味著每個讀取指令中會有64個位元被傳遞至處理器16次,此資料量是一般快取行( cache line)的兩倍(快取行是處理器快取資料的基本單位)。如果只有一條快取行包含有用資料,那么再去傳遞第二條快取行就會浪費很多時間和能耗。
因此,DDR4并未將預取的位元數翻倍,而采用了另一項技術,叫做記憶體分組(bank grouping)。該技術引進多組記憶體庫,每組都有各自的8n預取緩沖區,另有一個多工器負責從適切的分組里選取輸出資料。如果控制器的記憶體請求能以交錯的方式發出,以連續請求來存取不同分組的資料的話,I/O速度一樣能成長一倍,變成內存時脈的八倍。
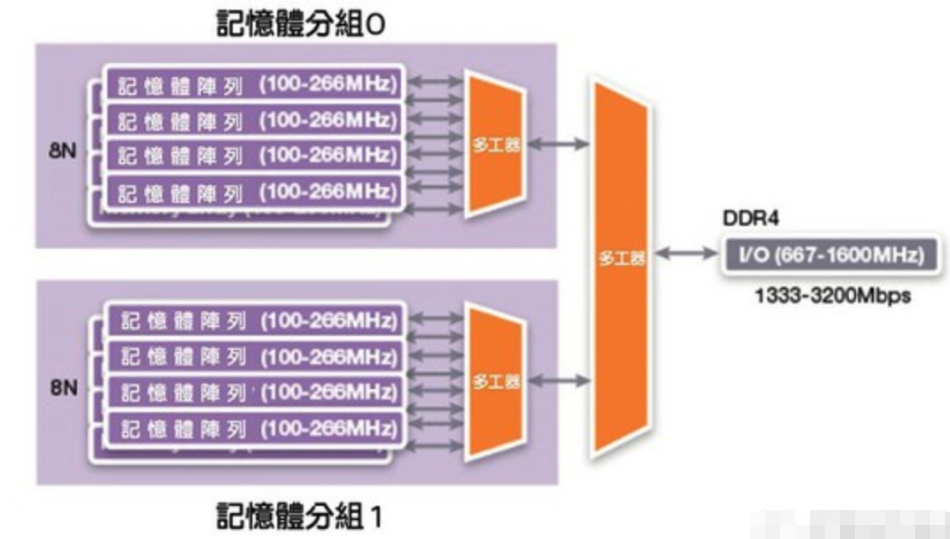
圖三: 記憶體分組機制的示意圖。(source:synopsys)
那么接下來的DDR5會如何發展?其目標也是要將I/O速度翻倍。DDR5呢,計畫是引用一項已應用在LPDDR4的技術,我們稱之為通道分裂(channel splitting)。
該技術將64位元的匯流排分成兩個獨立的32位元通道。因為現在每通道只提供32位元的資料空間,我們就能將預取增加至16n,這就能將存取粒度提升至64位元組,剛好等于一般快取行的資料大小。如此增加預取的資料量就能再次提升I/O時脈速度。
當然,提升I/O時脈速度并不只是在每周期內以充足的可用資料填充匯流排那樣簡單,還要面對多種與高頻率訊號相關的挑戰,像是訊號完整性、雜訊與功耗使用的問題。這些挑戰可以運用幾項技術解決,例如芯片內建終端架構(on-die termination)、差分時脈(differential clocking),以及將記憶體與處理器進行更密切的整合。這些技術大多源自其他DRAM架構,也就是LPDDR和GDDR,但我們將更聚焦在一個整合的概念上。
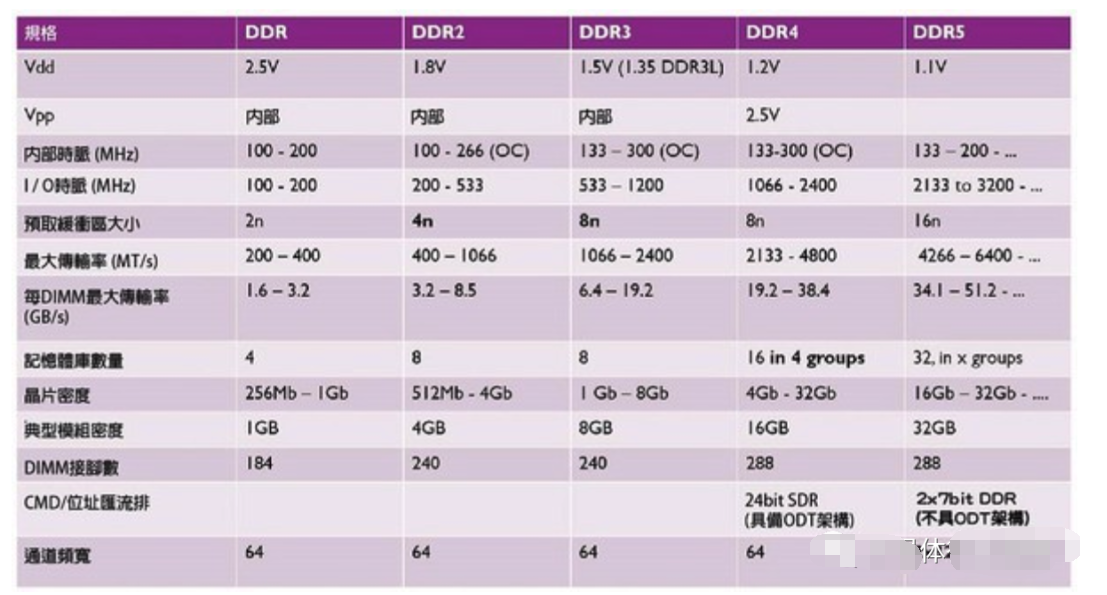
圖四: 各代DDR記憶體的規格比較。
LPDDR
LPDDR指的是低功耗雙倍數據傳輸率(low power DDR)。該標準的主要概念,一如其名,就是降低記憶體的功耗,而要實現這個目標有很多種方法。
LPDDR和普通記憶體的第一個差異,在于它和處理器的連接方式。LPDDR記憶體與處理器緊密整合,不論是被焊接在主機板上,與CPU緊鄰,或是采用越來越普及的作法—以封裝層疊技術(package-on-package;PoP)直接堆疊在處理器上方(通常是SoC)。更加緊密的整合能讓連接記憶體和處理器間的導線電阻更小,進而降低功耗。
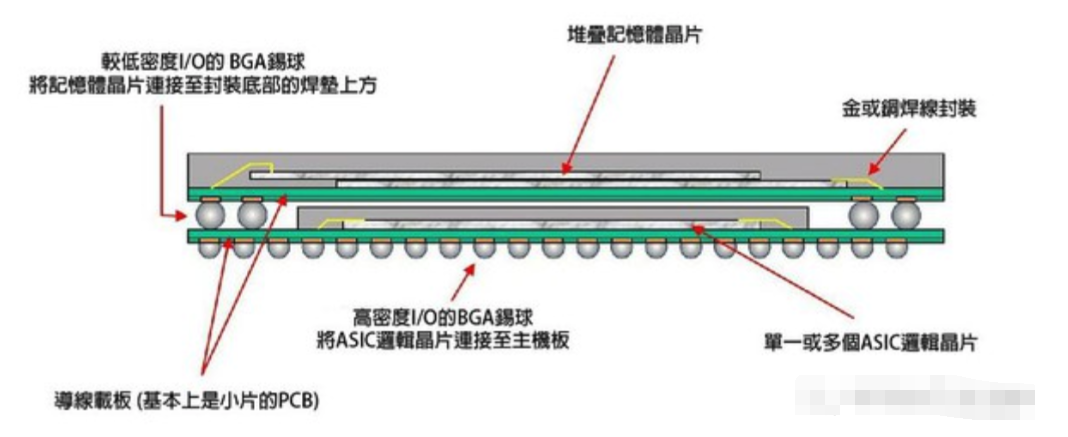
圖五: 以封裝層疊技術進行整合的示意圖。(source:wikipedia)
第二個差異則是通道寬度。LPDDR記憶體沒有固定的匯流排寬度,雖然一般來說最常見的是32位元。這個規格與普通記憶體相比算是較小,因而能節省能耗。
此外,LPDDR記憶體以較低的電壓運作,這也會大大影響功耗。最后一點,LPDDR藉由多種辦法優化記憶體更新這個步驟,像是依據溫度調適更新、局部陣列自行更新(partial array self-refresh;PASR)、深度省電狀態(deep power-down state)等,將LPDDR的備用功耗(standby power)大幅降低了。
我們現在不會深入探討這些技術,但基本上它們都必須犧牲部份的反應時間,以換取更低的備用功耗,因為記憶體在能夠回應請求前,需要一些時間從省電模式中「醒來」。
如上所述,不同代的LPDDR記憶體也采用了預取技術來增進性能。然而,LPDDR4是第一個引進16n緩沖區與通道分裂技術的標準,而LPDDR5預計會是第一個推出記憶體分組功能的標準。
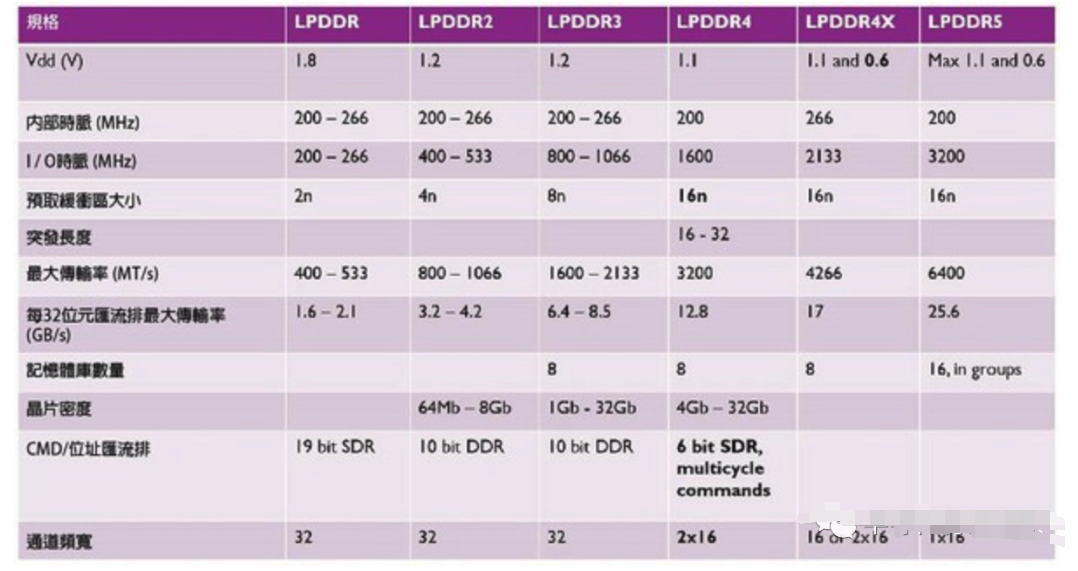
圖六: 各代LPDDR記憶體的規格變化。
GDDR
GDDR亦即繪圖用雙倍數據傳輸率(graphics DDR),其命名暗指該標準適用于繪圖芯片專用的記憶體。如今,這類記憶體在任何具備高頻寬需求的應用上都相當備受矚目,因為高頻寬就是其焦點所在。
GDDR記憶體也與處理器—也就是圖形處理器,密切地整合在一起,方法是將之焊接在PCB上。但GDDR記憶體并非直接放在GPU上方,因為這樣很難達到預定的電容,且在此情況下會很難降溫。
與傳統DDR芯片(例如32位元)相比,GDDR芯片的頻寬更寬,且每個芯片都直接連接至GPU,不須在一個固定64位元的匯流排上進行多工處理。也就是說,繪圖芯片上會有更多GDDR芯片,也就會有更寬頻的匯流排。
此外,由于這些芯片的接線不須進行多工處理,接線的頻率也提高了,就能進一步提升GDDR記憶體的I/O時脈頻率。透過使用更小的陣列與更大的周邊電路,記憶體內部的讀取速度變快了,I/O時脈速度因而提升,同時降低GDDR芯片的記憶體密度。
而更緊密結合記憶體與處理器也代表著,繪圖芯片的最終電容更加受限,畢竟與大尺寸GPU緊密整合的GDDR芯片數量最多只有12個。
為了提升記憶體頻寬,各代GDDR架構也采用與開發DDR時一樣的技術。第一代GDDR標準是GDDR2,該標準基于DDR;而GDDR3基于DDR2;接下來是GDDR4,因為這代幾乎不存在,所以略過不談;GDDR5則以DDR3為基礎,且一直到現在還是非常流行,GDDR5采用差分時脈,還能立即開啟兩個記憶體分頁(memory page)。
GDDR5X則是增進GDDR5性能的過渡版本,采用了具備16n緩沖區的四倍數據傳輸率(quad data rate;QDR)模式,但缺點是存取粒度變大了,但這對GPU來說不是大問題;GDDR6則將通道分裂開來,就像LPDDR4,這樣就能在同一匯流排上提供兩個更小的獨立通道,把存取粒度變小,實現具備16n緩沖區的QDR模式;沒錯,如此說來,GDDR6應該更適合叫做GQDR6。
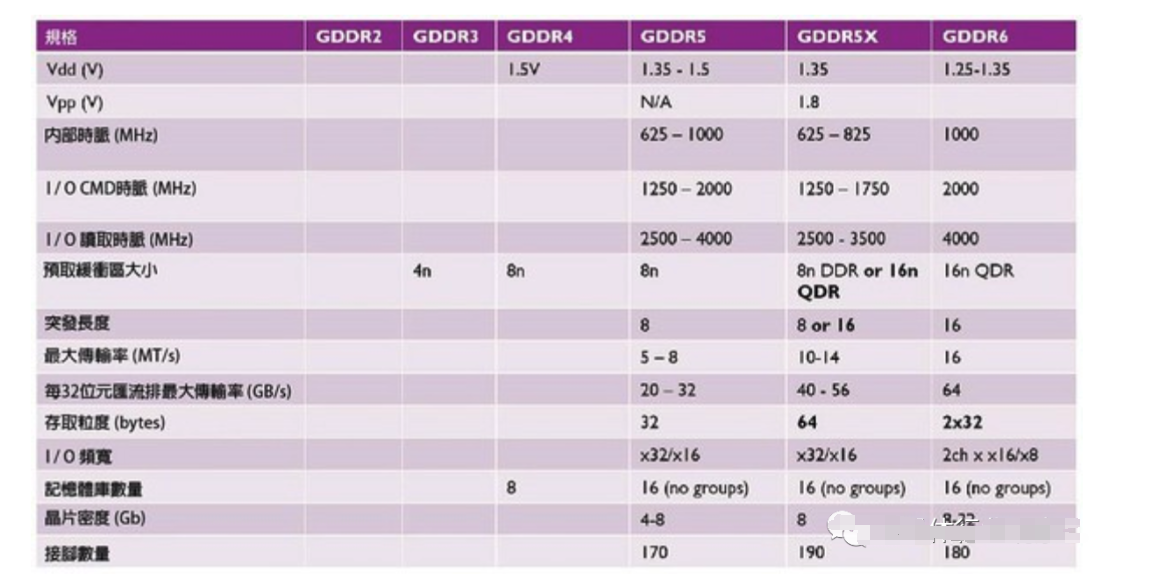
圖七: 各代GDDR記憶體的規格比較。
3D革命
HBM
HBM和GDDR多有雷同,它也與GPU緊密整合,而且也不放在GPU上方,畢竟我們還需要大量電容并將芯片降溫。那么HBM差在哪?
首先,HBM在PCB板的位置并不在GPU旁邊,而是在連接GPU與芯片的中介層(interposer)上。目前,通常使用的是被動式硅中介層,亦即一大片不含任何主動元件的硅芯片,只有內連導線。
這種中介層的優點是能在上面布建更多平行導線,而不會耗費大量功率。因此,一個極寬的匯流排誕生了,以往這在PCB上是不可能實現的。然而,雖然這種中介層相當容易制造,但畢竟還是一大塊硅芯片,因此成本也較高。
再者,記憶體芯片可以相互堆疊,使得芯片在垂直面上能實現小面積仍具備高電容。這些芯片具有大量的硅穿孔,連結記憶體堆內的各個芯片,以及其底部的邏輯芯片。而該邏輯芯片也會連結到中介層上的寬匯流排,使得記憶體芯片和GPU之間具備高頻寬。事實上,該匯流排寬度充足,所以記憶體芯片的I/O時脈可以降至低頻。而降頻加上連接至GPU的導線長度極短,這兩個特點就能在使用HBM時將每位元的能耗大幅降低(大約三倍)。
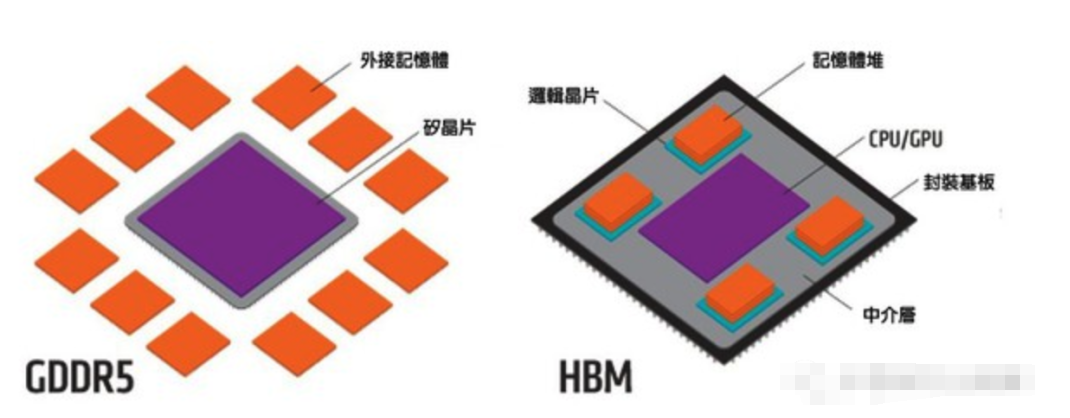
圖一: GDDR5和HBM的比較。(source:graphicscardhub.com)
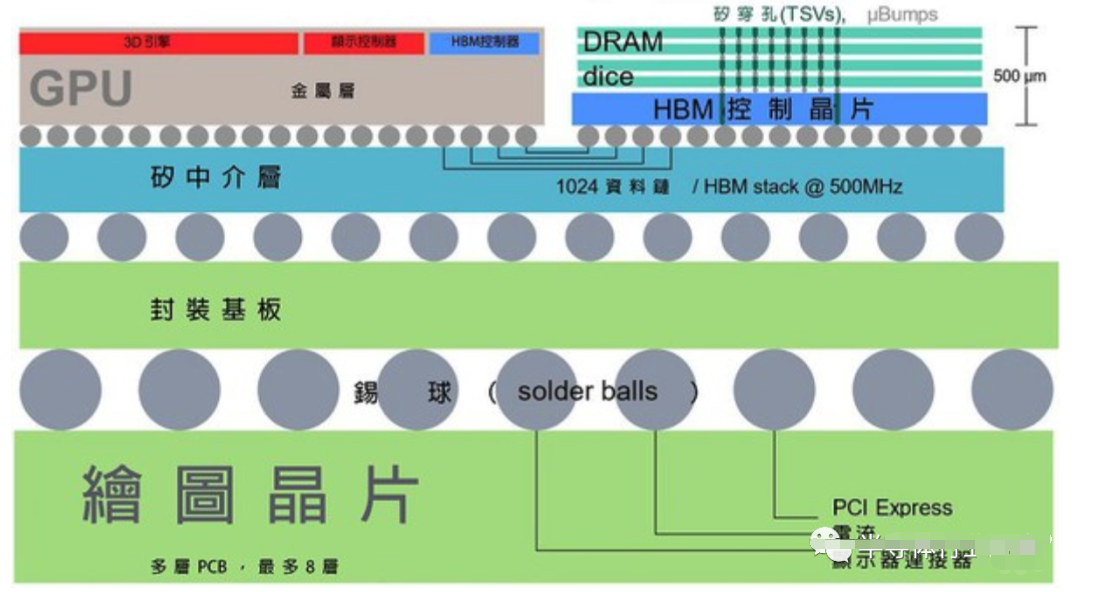
圖二: HBM的芯片垂直面示意圖(source:widipedia.org)
下表顯示了不同代HBM的重點規格。目前來說,HBM2仍在供應中。有趣的是,三星去(2019)年發布了新款HBM2e記憶體,該產品跳脫常見規格,單位芯片具備更高電容(16Gb),并進一步提高資料傳輸率至每堆疊410GB/s。
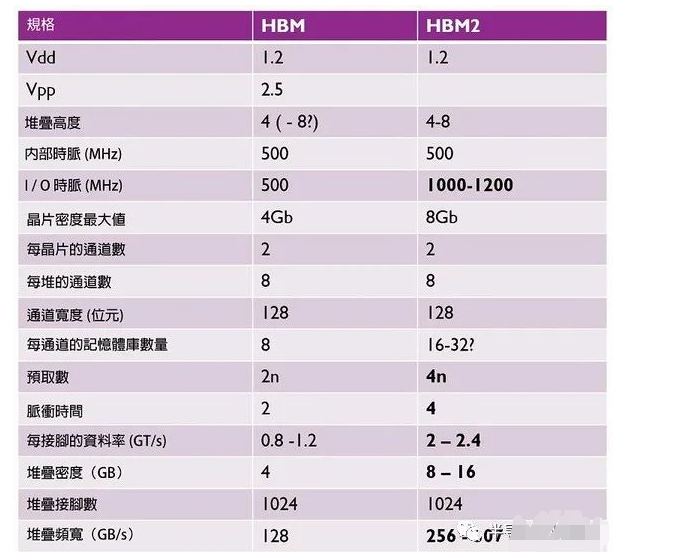
圖三: 各代HBM的規格比較表。
HMC
盡管美光不再努力開發HMC標準,我們還是想要稍微介紹一下。HMC是常規DDR記憶體的3D版,特別鎖定用在未來的伺服器上,雖然這個看法以往在業界并不總是很明確。HBM聚焦在頻寬上,因此需要進行高度整合,犧牲電容和芯片擴展性。這就是所謂的「近記憶體(near memory)」。
HMC的重點則在電容,以及將更多記憶體堆輕松整合至伺服器內,就像運用閑置插槽來將更多DDR記憶體安裝至主機板一樣。這種方式能提供松弛整合,滿足整體系統記憶體要實現高電容的需求。而這通常被稱作「遠記憶體(far memory)」。
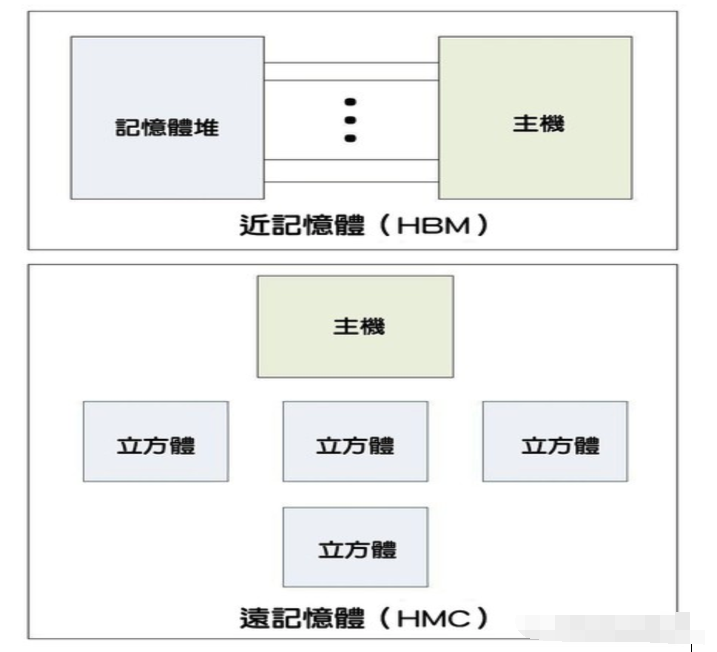
圖四: 近記憶體與遠記憶體的比較。(source:eejournal.com)
除了這點雷同之外,HMC是與DDR最不相同的記憶體標準,差異比其他任何在本文提到的標準都還大。HMC不使用DDR的匯流排傳輸方式,而是使用記憶體封包,這些封包以高速SerDes鏈接在處理器與記憶體立方體之間傳遞。如此就可能形成菊鏈立方體,以有限的內連導線達到更高電容。
此外,記憶體控制器完全整合在每個立方體的底座芯片,而不像DDR把控制器放在CPU芯片上,也不像HBM那樣分置在GPU和記憶體堆上。
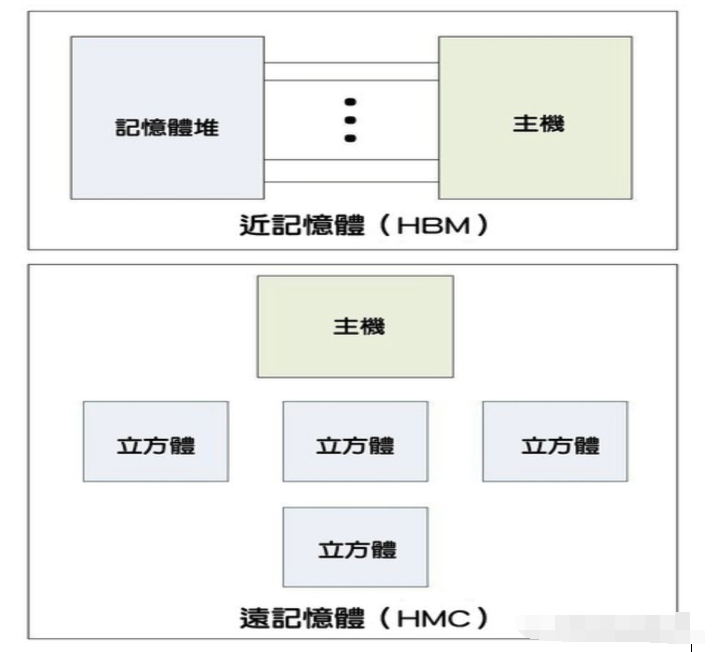
圖五: 比較HMC與HBM結構的示意圖(source:eejournal.com)
Wide I/O
Wide I/O是LPDDR記憶體的3D對應版本,優先采用極端的整合方式來實現可能的最低功耗。這類記憶體應該要直接整合在SoC上方,透過硅穿孔直接連至CPU芯片。如此就能將內連導線變得極短,其所需功耗是所有標準中最低的。
此外,Wide I/O還可能具備極寬的匯流排,端視硅穿孔的密度與尺寸而定。然而,這種極端的整合也要求在SoC內導入硅穿孔,這就會占去大片寶貴的邏輯芯片面積,因此成本極為高昂。這大概也是為什么我們還未見過任何采用該技術的商用產品。或許有趣的是,第一代Wide I/O標準采用了軟體定義無線電(SDR)介面,但第二代標準改用DDR介面。
總結各類DRAM的特點
我們已經呈現了不同DRAM類型在設計本質上曾做出或將來會做出的一些必要取舍。每種標準最終都采用相同的概念來改善每一代版本的頻寬,相關技術例如包含更大的預取緩沖區、記憶體分組、通道分裂、差分時脈、指令匯流排優化,以及更新優化( refresh optimization)。
不同標準不過是擁有各自的發展重點,不論是聚焦電容和彈性整合(DDR和HMC),或最低功耗(LPDDR和Wide I/O),還是最高頻寬(GDDR和HBM)。看到3D技術帶給這幾個目標市場的優勢,其實頗富趣味。
將記憶體進行緊密的3D整合,是能提升頻寬的有效方式,但基本上還是會限制電容。首先,放在靠近運算單元的記憶體堆是有數量限制的,再者,每一堆疊能容納的記憶體芯片數量也有限。
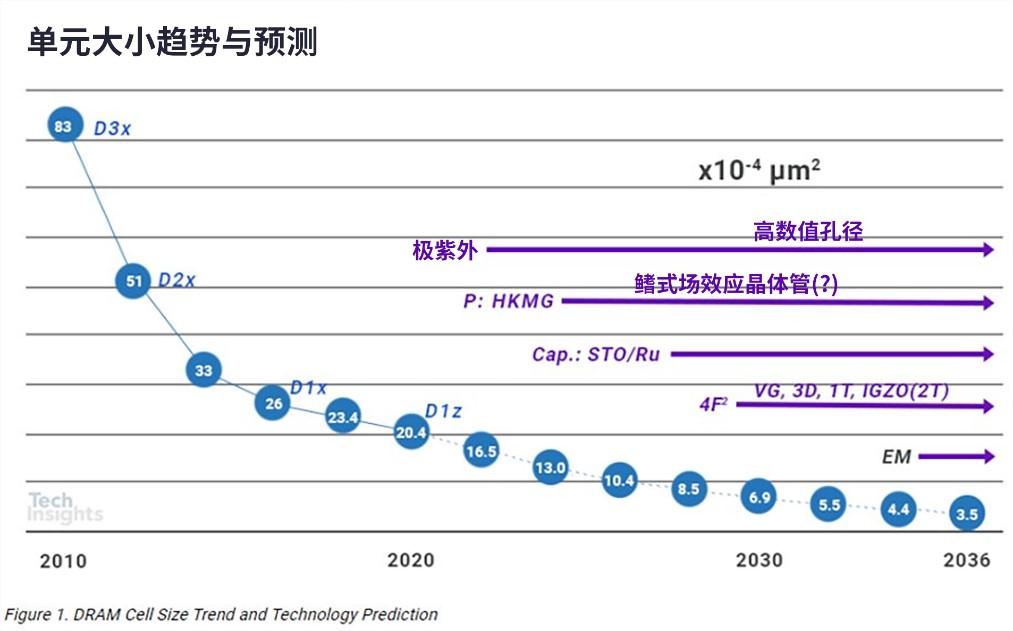
未來我們也將會明白,單一DRAM芯片的儲存格數已經逼近極限了。隨著各式應用對資料量的需求增長,在面對記憶體與處理器之間出現頻寬落差的「記憶體墻(memory wall)」問題時,記憶體密度也成為一個更重要的考量點。
DRAM的未來展望:IMEC觀點
為了將DRAM技術推升至其最終極限,并解決記憶體墻的技術問題,IMEC探索了兩條可能的發展道路。這兩條發展途徑采用了完全迥異的技術,將需要全新的架構標準來促使下一代DRAM記憶體的誕生。
第一條發展途徑是提升DRAM位元格的動態性(dynamic nature)。如本文開頭所述,儲存在DRAM位元格電容內的電荷會緩慢流失。因此,DRAM需要被更新。每列通常64毫秒更新一次。這會增加性能與功耗的常態性負擔(overhead)。
采用鐵電材料的電容設計(ferro capacitor)就是一個頗富潛力的辦法,它能讓DRAM位元格儲存電荷的時間延長,這也有助于減緩選擇晶體管(select transistor)對關閉電流的嚴苛要求。此外,鐵電電容能改善DRAM的資料保存時間(retention time),這也帶來諸多益處,例如可忽略更新的負擔、快速開啟或關閉低功耗模式、實現更低的備用功耗,以及進一步推動DRAM的規模化。
在IMEC的鐵電研究計劃中,他們正在開發以鐵電材料為基礎的金屬—絕緣體—金屬(metal-insulator-metal;MIM)電容器,以探索提升DRAM動態性的途徑。為了有效發揮這項技術以達到最低功耗,就需要一套聚焦在這些非揮發特性的全新DRAM架構標準。
然而,要延續DRAM的規模化藍圖以開發出更多代的版本,上述的發展途徑可能并不是最佳選項。因為規模化的問題,芯片密度已開始在約8~16GB的范圍達到飽和,要將DRAM芯片的電容擴充至32GB以上變得相當困難。如果我們想要繼續邁向規模化,將需要更具破壞性的創新技術。
其中一個辦法是以低漏電流沉積的薄膜晶體管(thin-film transistor;TFT),像是氧化銦鎵鋅(indium-gallium-zinc-oxide;IGZO),來取代DRAM位元格內的硅基晶體管。這種材料的寬能隙能確保DRAM具備低關閉電流—這是DRAM儲存單元晶體管的必要特性。由于我們不再需要材料硅來制造儲存單元晶體管,現在就可以將DRAM儲存單元的周邊電路移至DRAM陣列下方。如此,儲存單元的面積就能大幅降低。
下一步我們會考慮堆疊DRAM儲存單元。儲存電荷所需的電容已經達到規模化的極限,但要是我們能用極小的電容來儲存電荷呢?甚至完全不用電容,又會怎樣呢?
IGZO晶體管具備的超低漏電流就有可能開啟一條全新道路,能夠建立不須電容的DRAM儲存單元。由于電容不再,加上IGZO晶體管所用之材料能與后段制程相容,甚至有機會采用可規模化的制程,將不同儲存單元垂直堆疊。這帶來許多好處,但也帶給不同抽象層各式挑戰,例如制程、技術、位元格設計、記憶電路設計與系統架構。
為了解決這些挑戰,IMEC正在思考可能的跨層解決方案,用于未來的高性能DRAM標準,可能提供方法將DRAM記憶體進一步規模化,遠遠超過目前所預期的極限。
責任編輯人:CC










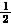










 工商網監
工商網監
評論