 電子發燒友App
電子發燒友App


導讀
所謂人臉融合:給定輸入人臉A、B,輸出的人臉C具有A和B共同的特征,是一張全新的人臉,也可以說是一張假臉。 人臉融合的過程主要有三步:人臉特征點定位,人臉融合,人臉交換。
第一步,通過深度學習訓練的模型對兩張待融合的圖像進行關鍵點定位;
第二步,根據定位結果對人臉進行融合;
第三步,將融合得到的人臉交換到待交換的人臉上,合成最終圖像。
實際上做到第二步已經達到了人臉融合的基本要求,對于人臉交換,大部分用于假臉交換起到一定的隱私保護作用,用在人臉融合這里也算剛剛好,如果隨意用于交換真臉,那就是信息災難了,例如各種換臉的視頻電影層出不窮。 ?
1 人臉特征點定位
1.1 訓練模型
數據集越大,訓練的模型越精確。人臉特征點檢測有一個非常著名的數據集300-W(300 Faces In-The-Wild Challenge)。300-W是一項專注于人臉特征點的檢測的競賽,在該競賽中,參賽隊伍需要從600張圖片中檢測出人臉,并且將面部的68個特征點全部標記出來。300W數據的壓縮包有2G多。包含各種各樣已經標記好的人臉信息。因為在如此大的數據集上訓練需要大量的資源和時間。所以,在本次的設計中,我們使用少量的數據集來訓練。 ? 訓練特征點檢測模型,這里我們用到了imglab工具。Imglab用于標記可用于訓練dlib或其他對象檢測器的對象的圖像。通過cmd:
imglab -c training_with_face_landmarks.xml images 來創建我們記錄標簽的xml文件,接下來通過cmd:
imglab training_with_face_landmarks.xml 打開imglab工具對圖像打標簽。這里我們按照dlib官方給出的68個特征點對每張圖片進行標注,shift+鼠標左鍵拖動截取人臉,雙擊選擇的矩形,shift+左鍵進行特征點標注。 接下來就可以開始訓練模型,這一步就看電腦性能了。首先定義參數設置函數:
options = dlib.simple_object_detector_training_options() 大部分參數,我們使用默認值,針對我們的訓練集,主要設定如下幾個參數。
Oversampling_amount: 通過對訓練樣本進行隨機變形擴大樣本數目。比如N張訓練圖片,通過設置該參數,訓練樣本數將變成N * oversampling_amount張。所以一般而言,值越大越好,只是訓練耗時也會越久。因為本例中訓練集數據較少,所以我們將值設得較高(300)。
Nu: 正則項。nu越大,表示對訓練樣本fit越好。
Tree depth: 樹深。本例中通過增加正則化(將nu調小)和使用更小深度的樹來降低模型的容量。
Be_verbose,是否輸出訓練的過程中的相關訓練信息,設置為真。
1.2 測試模型
人臉特征點檢測模型訓練完成后,需要測試該模型的準確率。測試模型的準確率包括兩部分,訓練集測試和測試集測試。訓練集就是訓練該模型的數據集合。輸出在訓練集中的準確率的核心代碼為:
print("Training accuracy{0}".format(dlib.test_shape_predictor(training_xml_path,"predictor.dat"))) 測試集即非訓練集數據的集合。輸出在測試集中的準確率的核心代碼為:
print("Testing accuracy:{0}".format(dlib.test_shape_predictor(testing_xml_path, "predictor.dat"))) 1.3 特征點定位 用訓練好的模型進行人臉特征點檢測。具體步驟如下,導入上述訓練好的模型:
predictor = dlib.shape_predictor("predictor.dat"); 檢測人臉:
dets = detector(img, 1) 返回人臉所在矩形,可通過len(dets)獲得人臉個數;獲取檢測到的人臉特征點:
lanmarks = [[p.x, p.y] for p in predicator(img1, d).parts()]; 在圖片中循環打印出68個特征點,? ??
2 人臉融合
這一步首先介紹兩個算法,Delaunay三角剖分,仿射變換。
2.1 Delaunay三角剖分
設點集V,x,y屬于點集V,多邊形S中兩個端點為x,y的一條邊e,若過x,y兩點存在一個圓,且點集V中任何其他的點都不在該圓內,圓上包括x,y兩點最多三點,那么稱e為Delaunay邊。那么如果點集V的一個三角剖分T只包含Delaunay邊,那么該三角剖分稱為Delaunay三角剖分。 ? Delaunay三角剖分有兩個重要特性,一個是空接圓特性:Delaunay三角剖分是唯一的,任意四點不能共圓,在Delaunay三角剖分中任一三角形的外接圓范圍內不會有其它點存在。另外一個是最大化最小角特性:在散點集形成的所有三角剖分中,Delaunay三角剖分所形成的三角形的最小角最大。 ? 該算法其實來源于美術館問題,美術館是一個復雜的多邊形,我們需要在美術館當中安排警衛,在使得他們能觀察到美術館的所有角落前提下,安排的警衛最少。多邊形中的視野問題不好處理,所以將多邊形剖分成多個三角形從而使問題得到簡化。警衛站在三角形的任意一個位置都能觀察到這個三角形中的每一個點。數學家Steve Fisk對這個問題給出了非常精彩的解答:剖分成三角形后,每個三角形的三個頂點共用三種不同的顏色染色,染色結束后在最少的顏色上設置警衛即可,如下圖所示。
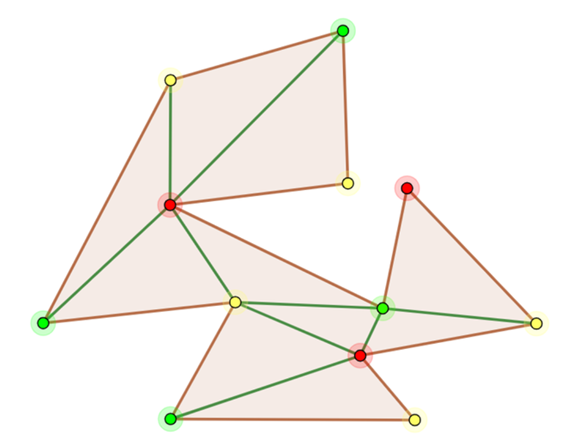
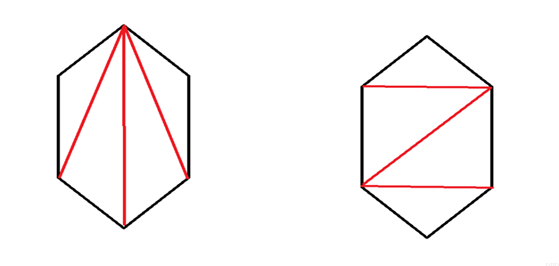
所以問題簡化成將該多邊形剖分成一個個三角形。另外三角剖分也有優劣之分,一般來說,剖分出來的三角形越勻稱越好,勻稱的三角形在圖形圖像處理方面效果比陡峭的三角形更好,如下圖所示,都是對同一個六邊形進行三角剖分,但是右邊的效果更好,這就是Delaunay三角剖分。而在人臉融合技術中,Delaunay三角剖分也扮演了不可或缺的角色。
我們根據得到的特征點對人臉進行Delaunay三角剖分,將人臉剖分成一個個三角形,然后將一個個三角形進行仿射變換,再調整透圖片透明度,便可得到融合后的人臉,訓練的特征點越多,融合的效果便越好。OpenCV提供了Subdiv2D類實現了Delaunay三角剖分算法,subdiv = cv2.Subdiv2D(rect),將68個特征點的位置插入subdiv,subdiv.insert§ ,獲取Delaunay三角列表:
trangleList = subdiv.getTriangleList() 最后調用cv2.line()將剖分后的結果畫出,
2.2 仿射變換
仿射變換,又稱仿射映射,是指在幾何中,一個向量空間進行一次線性變換并接上一個平移,變換為另一個向量空間。仿射變換能夠保持圖像的“平直性”,包括旋轉,縮放,平移,錯切操作。一般而言,仿射變換矩陣為2*3的矩陣,第三列的元素起著平移的作用:
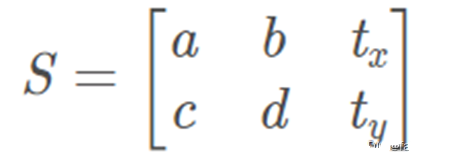
前面兩列的數字對角線上是縮放,其余為旋轉或者錯切的作用。仿射變換是一種二維坐標(x, y)到二維坐標(xt, yt)的線性變換。數學表達式如下圖所示:
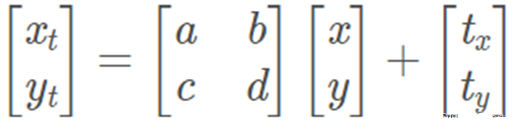
直觀的圖像表示就是這樣:

首先對之前得到的特征點進行預處理。人臉特征點檢測算法得出的人臉68個特征點保存在本地的txt文件中。同時,Delaunay三角剖分算法得到的三角形的索引結點也保存在本地的txt文件中。讀取人臉A的特征點points1,人臉B的特征點points2。因為要求融合的人臉不一定是同等大小,所以我們取一個平均值保存在points中。Points即為我們融合后的人臉特征點所在位置。經過三角剖分后,人臉被剖分成一個個三角形。我們從保存的三角形索引結點中循環讀取每一個三角形的索引點,通過索引結點找到人臉A和人臉B的該三角形所對應的三個特征點位置。取得的三角形以下稱三角形A,三角形B。取平均值的三角形稱為C。因為做仿射變換只需要變換一個我們剖分形成的三角形,不需要變換整張圖片,所以我們可以求得該三角形的最小外接矩形,以提升變換效率,并減少計算量。
r = cv2.boundingRect(np.float32([t])) 返回的r為一個四元組,前兩個值為矩形左上角的坐標,后兩個值為矩形的長和寬。因為要在上面獲得的外接矩形中進行仿射變換,所以原點從圖片的左上角點變成了外接矩形的左上角點,從而要修改三角形的三點坐標。
tRect.append(((t[i][0] - r[0]), (t[i][1] - r[1]))) t為預處理中獲得的三角形三個頂點坐標。在上一步中,我們獲得了輸出矩形圖像。但是,我們對矩形區域內的三角形感興趣。因此,我們使用fillConvexPoly創建一個掩模mask,用于遮蔽三角形外的所有像素。這個新的裁剪圖像最終可以使用輸出邊界矩形的左上角坐標點置于輸出圖像中的正確位置。接下來就是通過仿射變換將三角形A,B變換到C的位置上。
warpImage1 = applyAffineTransform(img1Rect, t1Rect, tRect, size)warpImage2 = applyAffineTransform(img2Rect, t2Rect, tRect, size) ApplyAffineTransform是手寫的函數,包括cv2.getAffineTransform,用來找到兩個三角形之間的仿射變換矩陣,cv2.warpAffine將上個函數獲得的矩陣應用于圖像。
# Apply affine tranform calculated using srcTri and sdtTri to src and output an image of sizedef applyAffineTransform(src, srcTri, dstTri, size):??
?# Given a pair of triangles,find the affine transform. ??warpMat = cv2.getAffineTransform(np.float32(srcTri), np.float32(dstTri)) ?
?# Apply the Affine Transform just foundto the src image ?
?dst = cv2.warpAffine(src, warpMat, (size[0], size[1]), None, flags=cv2.INTER_LINEAR, ? ?
? ? ? ? ? ? ? ? ? ? borderMode=cv2.BORDER_REFLECT_101) ?
?return dst
2.3 圖像融合
將人臉剖分成一個個小三角形并仿射變換到既定的位置后,進行圖片融合。簡單來說,通過把圖像設置為不同的透明度,把兩張圖像融合為一張圖像(一般要求圖像需要是等尺寸大小的),公式如下圖所示:

仿射變換時,我們將人臉A的三角形A,人臉B的三角形B仿射到三角形C上。如果不處理,三角形A和三角形B仿射后的圖像會疊加在C上。這里我們設置一個透明度參數alpha為0.5,兩張人臉各占一半。
imgRect = (1.0 - alpha) * warpImage1 + alpha * warpImage2 warpImage1,warpImage2為經過仿射變換的圖像。最后一步,最后將用于遮蔽三角形外的所有像素mask與上個步驟輸出的圖片結果相乘就可以得到對應區域的值了。 ? 得到融合后的人臉后,最后一步,就是將融合后的人臉交換到待交換的人臉上。? ??
3 人臉交換
人臉交換分為五個步驟:特征點檢測,查找凸包,基于凸包三角剖分,仿射變換,無縫克隆。特征點檢測,三角剖分和仿射變換之前的部分提及到,所以詳細介紹一下查找凸包和無縫克隆。
3.1 凸包算法
如下圖所示,所給平面上有點集V,包含p0到p12一共13個點,過p0,p1,p3,p10,p13點作一個多邊形,點集V中所有點都包含在形成的這個多邊形上。如果當這個多邊形是凸多邊形的時候,我們就叫它“凸包”。簡單來說,點集的凸包即一個最小的凸多邊形使得點集中所有的點在該凸邊形內或該凸邊形上。
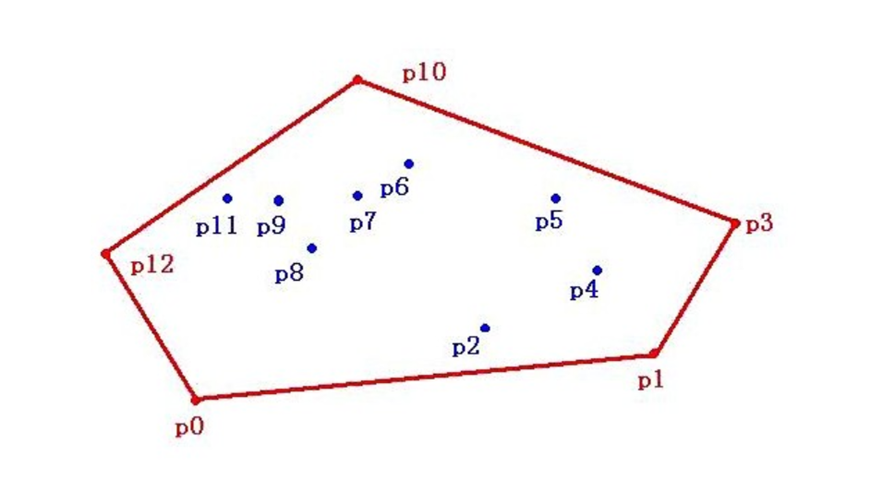
凸包算法為什么會用在人臉交換中呢?人臉交換同樣需要特征點檢測,同樣需要三角剖分,與人臉融合不同的是人臉交換是直接通過仿射變換將人臉A剖分后的三角形仿射到人臉B上。人臉融合剖分的三角形越多,融合效果越完美。 ? 人臉交換不同于融合,第一步只需要將人臉A貼到人臉B上,所以只需要求出68個特征點的凸包多邊形,對這個多邊形剖分即可。OpenCV便提供了求得這個凸包的函數cv2.convexHull()。人臉交換不同于融合,第一步只需要將人臉A貼到人臉B上,所以只需要求出68個特征點的凸包多邊形,對這個多邊形剖分即可, 仿射換臉核心代碼如下:
# Warps and alpha blends triangular regions from img1 and img2 to imgdef warpTriangle(img1, img2, t1, t2):
# Find bounding rectangle for each triangle r1 = cv2.boundingRect(np.float32([t1])) r2 = cv2.boundingRect(np.float32([t2]))
# Offset points by left top corner of the respective rectangles t1Rect = [] t2Rect = [] t2RectInt = [] for i in range(0, 3): t1Rect.append(((t1[i][0] - r1[0]), (t1[i][1] - r1[1]))) t2Rect.append(((t2[i][0] - r2[0]), (t2[i][1] - r2[1]))) t2RectInt.append(((t2[i][0] - r2[0]), (t2[i][1] - r2[1])))
# Get mask by filling triangle mask = np.zeros((r2[3], r2[2], 3), dtype=np.float32) cv2.fillConvexPoly(mask, np.int32(t2RectInt), (1.0, 1.0, 1.0), 16, 0);
# Apply warpImage to small rectangular patches img1Rect = img1[r1[1]:r1[1] + r1[3], r1[0]:r1[0] + r1[2]]
# img2Rect = np.zeros((r2[3], r2[2]), dtype = img1Rect.dtype) size = (r2[2], r2[3]) img2Rect = applyAffineTransform(img1Rect, t1Rect, t2Rect, size) img2Rect = img2Rect * mask
# Copy triangular region of the rectangular patch to the output image img2[r2[1]:r2[1] + r2[3], r2[0]:r2[0] + r2[2]] = img2[r2[1]:r2[1] + r2[3], r2[0]:r2[0] + r2[2]] * ( (1.0, 1.0, 1.0) - mask) img2[r2[1]:r2[1] + r2[3],
r2[0]:r2[0] + r2[2]] = img2[r2[1]:r2[1] + r2[3], r2[0]:r2[0] + r2[2]] + img2Rect 得到的結果,可以明顯看出膚色的差異。 ?
3.2 無縫融合
優秀的技術就像魔法。優秀的魔術師將物理學、心理學和古老的魔術相結合實現了圖像的無縫融合。圖像的編輯包括全局變化和局部變化,無縫融合是將我們所選中的局部區域無縫且無影響地融合到目標圖像中。傳統上的工具來完成局部的剪切與融合,是通過克隆工具直接覆蓋那部分融合區域的內容,因此如果選擇的區域色彩和明暗有明顯的差異,會導致明顯的邊縫,顯得突兀。無縫融合由此誕生。 ? 無縫融合的基本原理基于人的生物學特性,我們人眼天生就對“突變”更為敏感。簡單來說,比如突然從密閉的黑暗房間出來,我們人眼會受到光線的刺激。但是如果我們漸變的適應一下,就不會感受到光線的刺激。就像白紙上的黑色圖形,我們會感覺很“突兀”。同理如果連續平滑的將這個圖像由白入灰再變黑,那么我們就感受不到這種突兀。無縫融合就是基于此生物學特性的魔法,雖然是將一張圖像融合到另一張圖像上,但是我們絲毫感覺不出“突兀”。 ? 這種無縫編輯和克隆方法的核心是數學工具―泊松方程,前提是需滿足在所選區域未知函數的拉普拉斯條件和它的Dirichlct邊界條件:未知函數的邊界值與目標圖像中所選區域的邊界值相同。因為在這兩個條件下方程的解是唯一的。
? 首先,心理學家Land和Mccan在1971年提出通過拉普拉斯算子的限制可以減緩漸變的梯度,當把一幅圖像混淆到另一幅圖像上幾乎注意不到有什么影響。并且,泊松方程可以完成無縫地填滿目標圖像中的選中區域。在數學上說到底就是構建方程組:Ax=b。然后通過求解這個方程組以得到每個像素點的值。矩陣A是一個系數矩陣,矩陣的每一行有五個非零元素,對應于拉普拉斯算法的卷積核,而算法的關鍵在于怎么構建方程組的b值 。首先,計算待融合圖像A和背景圖像B的梯度場;然后計算融合圖像的梯度場,計算完后將A的梯度場覆蓋到B的梯度場上;最后對梯度求偏導求得融合圖像的散度b,解系數方程Ax=b。雖然看起來涉及到許多數學知識,實際上實現起來只要一個函數cv2.seamlessClone,這就是OpenCV(Computer Vision)。 當然了,如果交換的人臉周圍是黑的,就比如下圖我們融合得到的中間的人臉,人臉交換時人臉輪廓難免會包括周圍的黑色背景。所以,為了使無縫融合取得更好的效果,最好在圖片周圍加八個點,將環境也粗略融合一下,這樣就可以避免人臉周圍黑色造成換臉后的“傷疤”。 ? 新加的這8個點,可以通過:
sp = img1.shape # [高|寬|像素值由三種原色構成] #高寬色素 獲取圖片的高和寬,例如高的一半可以sp[0]/2表示,寬的一半sp[1]/2。 將這張人臉進行人臉交換,可以有效防止周圍黑色環境無縫融合產生的“傷疤”。??
4 實驗分析總結
從第一張圖來看,我們對兩張性格相同的人臉進行融合,實驗結果顯示本文提出的人臉融合技術可以實現人臉融合,且最后的融合結果具有高度的真實感,我們基本分辨不出這是融合的效果,初步達到了我們對人臉融合實現的要求。 ? 從第二張、第三張圖來看,我們對兩張性別不同、膚色不同的人臉進行融合,并分別交換到這兩張性別不同的人臉上,從視覺效果上看,我們的算法依然取得了較好的效果,融合的人臉不論是交換在男性身上還是交換在女性身上都顯得非常自然,并且膚色也非常自然,性別,膚色并未對算法結果造成影響。
? 從第四張圖來看,我們選擇了兩張人臉大小不一的圖像來進行融合,我們發現融合仍然具有高度的真實感。但是發現一點瑕疵,左邊的圖像由于燈光的照射使得右側臉頰有陰影,而我們的算法并不能判斷出這是由于燈光產生的陰影還是膚色,導致融合后陰影仍然存在,致使結果有些不自然,但并不影響整個融合的實現,這個問題也是在未來需要解決的。 ? 總的來說,實驗結果證明本文提出的人臉融合實現的融合結果具有高度的真實感,基本實現了最初構想,在效果上也達到了預期要求。但仍然還有需要改進的方向: ? (1)消除燈光照射產生陰影對人臉融合的影響。上述第四張圖片由于燈光的照射使得人臉右側臉頰產生陰影,而我們提到的無縫融合只能將其也歸為膚色,導致融合后即使沒用光照也有陰影,導致實驗效果不自然。方向有兩個,一個是對圖像進行預處理,消除光照產生的影響;另一個就是在融合過程中對陰影部分進行處理。從可行上來看,對圖像進行預處理顯得更加便于操作。 ? (2)消除頭發,眼鏡等遮擋物對融合的影響。我們的算法是在人臉完全展示的狀態下進行剖分并進行融合。如果出現遮擋物,仍然會把遮擋物當成人臉的一部分參與仿射變換并進行融合,這同樣會影響實驗結果。而隨著社會的發展,發型遮擋人臉或者飾品遮擋人臉的情況也比較常見。
編輯:黃飛
?









 工商網監
工商網監
評論