 電子發(fā)燒友App
電子發(fā)燒友App


本文對(duì)最近被 TPAMI 接收的一篇綜述文章 Human Action Recognition from Various Data Modalities: A Review(基于不同數(shù)據(jù)模態(tài)的人類動(dòng)作識(shí)別綜述)進(jìn)行解讀。

1 概述
人類動(dòng)作識(shí)別(Human Action Recognition, HAR)旨在理解人類的行為,并為每個(gè)行為分配一個(gè)標(biāo)簽。多種不同的數(shù)據(jù)形態(tài)都可以用來表示人類的動(dòng)作和行為。這些模態(tài)可以分為 2 類:視覺模態(tài)和非視覺模態(tài),視覺模態(tài)和非視覺模態(tài)的主要區(qū)別在于:視覺模態(tài)的數(shù)據(jù)對(duì)人類行為的表示相對(duì)直觀,但是非視覺模態(tài)的數(shù)據(jù)則不是。視覺模態(tài)主要包括:如 RGB,骨架,深度,紅外,點(diǎn)云,事件流(event stream)等數(shù)據(jù)模態(tài),而非視覺模態(tài)則主要包括音頻,加速度,雷達(dá),wifi 信號(hào)等數(shù)據(jù)模態(tài),如圖 1 所示。這些數(shù)據(jù)模態(tài)是對(duì)不同的信息來源進(jìn)行編碼,根據(jù)應(yīng)用場(chǎng)景的不同,不同模態(tài)的數(shù)據(jù)有著不同的獨(dú)特優(yōu)勢(shì)。

圖 1 HAR 任務(wù)中使用到的數(shù)據(jù)模態(tài) 該綜述對(duì)基于不同數(shù)據(jù)模態(tài)的深度學(xué)習(xí) HAR 方法的最新進(jìn)展做了一個(gè)綜合調(diào)研。介紹調(diào)研的主要內(nèi)容分為三部分(1)當(dāng)前主流的單模態(tài)深度學(xué)習(xí)方法。(2)當(dāng)前主流的多模態(tài)深度學(xué)習(xí)方法,包括基于融合(fusion)和協(xié)同學(xué)習(xí)(co-learning)的學(xué)習(xí)框架。(3)當(dāng)前 HAR 任務(wù)的主流數(shù)據(jù)集。
2 單模態(tài)學(xué)習(xí)方法
前文中已經(jīng)提到,不同模態(tài)具有著獨(dú)特的優(yōu)勢(shì),在這些模態(tài)中,單獨(dú)使用 RGB / 光流模態(tài)和骨架模態(tài)的 HAR 工作相對(duì)較多。而其他模態(tài)由于其大多存在一些固有的缺陷,所以單獨(dú)使用的情況較少,大部分情況下都是與其他模態(tài)結(jié)合使用。
2.1 RGB 和光流模態(tài)
RGB 模態(tài)指的是由 RGB 相機(jī)捕獲的圖像或序列。而光流則是視頻圖像中同一對(duì)象(物體)像素點(diǎn)移動(dòng)到下一幀的移動(dòng)量,由于通常是由 RGB 模態(tài)數(shù)據(jù)所進(jìn)一步生成,所以下文中把 RGB 和光流模態(tài)統(tǒng)稱為 RGB 模態(tài)。RGB 模態(tài)的優(yōu)點(diǎn)和缺點(diǎn)都非常明顯,優(yōu)點(diǎn)主要有:(1)RGB 數(shù)據(jù)容易收集,通常是最常用的數(shù)據(jù)模態(tài)。(2)RGB 模態(tài)包含所捕獲的場(chǎng)景上下文的信息。(3)基于 RGB 的 HAR 方法也可以用來做 pretrained model。缺點(diǎn)主要有:(1)由于 RGB 數(shù)據(jù)中存在背景、視點(diǎn)、尺度和光照條件的變化,所以在 RGB 模態(tài)中進(jìn)行識(shí)別通常具有挑戰(zhàn)性。(2)RGB 視頻數(shù)據(jù)量較大,計(jì)算成本較高。圖 2 展示了基于 RGB 模態(tài)數(shù)據(jù)的 HAR 方法的主要分類,下面分別對(duì)這些方法進(jìn)行介紹。
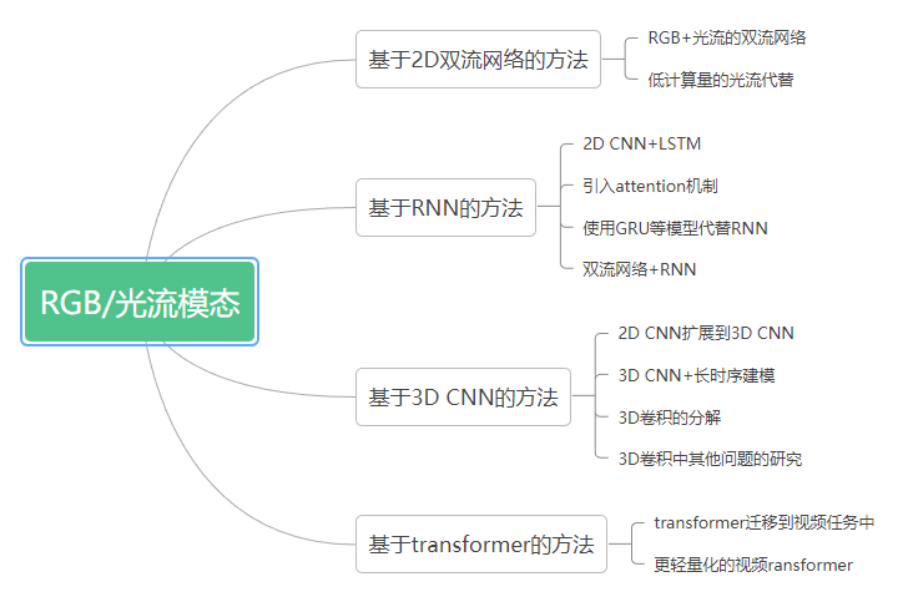
圖 2 基于 RGB / 光流模態(tài)的 HAR 方法分類
基于 2D 雙流網(wǎng)絡(luò)的方法。
這類方法的核心思想是,通過兩個(gè)或多個(gè) backbone 學(xué)習(xí)不同的視頻特征,[1]和 [2] 是這類方法中最具代表性的工作,[1]的兩個(gè) stream 分別輸入 RGB 幀和多幀的光流,以分別學(xué)習(xí)外觀特征和運(yùn)動(dòng)特征, RGB + 光流的模態(tài)組合也被很多后續(xù)的工作所效仿。[2]則對(duì)低分辨率 RGB 幀和高分辨率 RGB 幀的中心裁剪輸入兩個(gè) stream 中,以降低計(jì)算量。 精確的光流獲取通常需要很高的計(jì)算成本,所以如何在較低的計(jì)算成本下獲取光流的近似或代替也是此類方法一個(gè)研究重點(diǎn)。如 [3] 提出了一個(gè)基于知識(shí)蒸餾的框架實(shí)現(xiàn)從使用光流訓(xùn)練的 teacher network 到使用 motion vector 作為輸入的 student 網(wǎng)絡(luò)的知識(shí)遷移。motion vector 可以直接從 compressed videos 中獲得,而不再需要額外的計(jì)算。
基于 RNN 的方法
2D 雙流網(wǎng)絡(luò)的一個(gè)缺點(diǎn)是對(duì)時(shí)序上的長(zhǎng)期依賴關(guān)系的建模不足,那么使用時(shí)序建模的網(wǎng)絡(luò)如 LSTM,則可以彌補(bǔ)這一點(diǎn)。這類基于 RNN 的方法依據(jù)其核心貢獻(xiàn)又可以分為 4 小類:(1)2D CNN 與 RNN 的組合:如 [4] 使用 2D CNN 提取每個(gè) frame 的特征,然后再使用 LSTM 生成動(dòng)作標(biāo)簽。(2)attention 機(jī)制的引入,attention 機(jī)制主要包括空間的 attention 和時(shí)序的 attention,或兩者的組合。比如 [5] 設(shè)計(jì)了一個(gè)多層的 LSTM 模型,可以遞歸地輸出對(duì)下一幀的輸入 feature map 的 attention map。(3)使用 GRU 等模型來代替 RNN,相比于 RNN,GRU 的參數(shù)更少,但在 HAR 任務(wù)上通常可以提供與 LSTM 相近的性能。(4)2D 雙流網(wǎng)絡(luò)和 RNN 的結(jié)合,比如 [6] 中利用 2D 雙流網(wǎng)絡(luò)分別提取 spatial 和短期的運(yùn)動(dòng)特征,然后再分別輸入 2 個(gè) LSTM 來提取長(zhǎng)時(shí)的運(yùn)動(dòng)信息。
基于 3D CNN 的方法。
基于 RNN 的方法通常是對(duì) CNN 已經(jīng)提取出的 feature 進(jìn)行操作,而不是對(duì)原始的圖像序列進(jìn)行操作。基于 3D CNN 的方法則可以做到這一點(diǎn)。基于 3D CNN 的方法依據(jù)其核心貢獻(xiàn)同樣分為 4 小類:(1)2D CNN 到 3D CNN 的擴(kuò)展,[7]使用 3D conv 從原始的視頻中直接學(xué)習(xí)時(shí)空特征。(2)對(duì)長(zhǎng)時(shí)序依賴關(guān)系的建模,3D CNN 有著 CNN 共同的特點(diǎn),側(cè)重于對(duì) local 信息的提取,而對(duì) global 信息的提取能力不足。[8]中提出了一個(gè)長(zhǎng)時(shí)時(shí)間卷積框架,以降低空間分辨率為代價(jià),增加了 3D 卷積在 temporal 維度上的感受野。(3)3D conv 的分解:3D 卷積通常包含大量的參數(shù),也需要大量的訓(xùn)練數(shù)據(jù),因此其計(jì)算量較大。[9]提出將 3D conv 分解成了空間上的 2d conv 和時(shí)間維度上的 1d conv。(4) 對(duì) 3D conv 中其他問題的討論,比如 [10] 從概率的角度分析了 3d conv 中的時(shí)空融合,[11]提出了一個(gè)隨機(jī)均值縮放的正則化方法來解決過擬合問題。
基于 transformer 的方法。
transformer 是一種以 attention 機(jī)制為核心的模型,其在長(zhǎng)時(shí)序建模、多模態(tài)融合和多任務(wù)處理等方面具有良好的性能,由于 transformer 在 NLP 領(lǐng)域的成功應(yīng)用,目前也有很多將 transformer 應(yīng)用到 HAR 任務(wù)中的方法,如 [12] 通過把 video 分解成 frame-level 的 patches,將 VIT 應(yīng)用到了視頻中,并且在模型的每個(gè) block 中分別應(yīng)用了 spatial 和 temporal 的 attention。 但是,transformer 的通病是其所需的顯存和計(jì)算開銷一般較大,所以也有很多工作,研究了如何降低基于 transformer 的視頻理解模型的復(fù)雜度,比如 [13] 將 3d 的視頻幀轉(zhuǎn)換成 2d 的 super image 作為 transformer 的輸入。[14]使用了在 spatial 維度進(jìn)行特征處理的 backbone(例如 2D CNN)和基于 temporal attention 的 encoder 來達(dá)到精度和速度之間的權(quán)衡。
2.2 骨架數(shù)據(jù)模態(tài)
骨架序列表人體關(guān)節(jié)的軌跡,這些軌跡可以用來表征人體的運(yùn)動(dòng),因此骨架數(shù)據(jù)是比較適配于 HAR 任務(wù)的一種數(shù)據(jù)模態(tài),骨架數(shù)據(jù)提供的是身體結(jié)構(gòu)與姿態(tài)信息,其具有兩個(gè)明顯的優(yōu)點(diǎn):(1)具有比例不變性。(2)對(duì)服裝紋理和背景是魯棒的。但同時(shí)也有兩個(gè)缺點(diǎn):(1)骨架信息的表示比較稀疏,存在噪聲。(2)骨架數(shù)據(jù)缺少人 - 物交互時(shí)可能存在的形狀信息。圖 3 展示了基于骨架模態(tài)數(shù)據(jù)的 HAR 方法的主要分類,下面分別對(duì)這些方法進(jìn)行介紹。
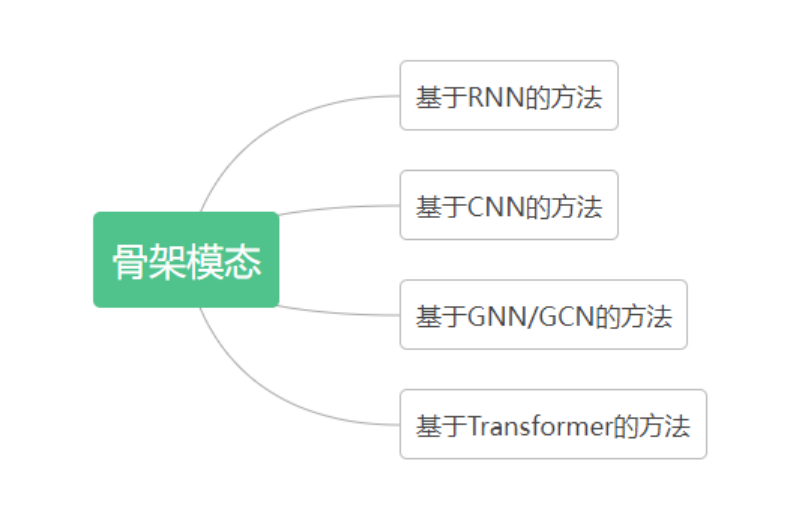
圖 3 基于骨架數(shù)據(jù)模態(tài)的 HAR 方法分類
基于 RNN 的方法。
使用 RNN 的核心原因是希望能夠?qū)W習(xí)時(shí)序數(shù)據(jù)中的動(dòng)態(tài)依賴性。這類基于 RNN 和骨架數(shù)據(jù)的 HAR 方法,大多聚焦于 RNN 或 LSTM 等模型在 HAR 任務(wù)上的改進(jìn)和應(yīng)用。如 [15] 將人體骨骼分為 5 個(gè)部分,這 5 部分分別輸入到多個(gè)雙向 RNN 中,然后再將其輸出進(jìn)行分層融合,以生成動(dòng)作的高級(jí)表示。[16]提出了一個(gè)部分感知 LSTM,并模擬了 LSTM 單元中不同身體部分之間的關(guān)系。
基于 CNN 的方法。
CNN 以其在空間維度上卓越的特征提取和學(xué)習(xí)能力,在 2D 圖像識(shí)別任務(wù)中取得了巨大的成功。把 CNN 應(yīng)用到基于骨架數(shù)據(jù)的 HAR 任務(wù)中時(shí),一個(gè)研究重點(diǎn)是對(duì)時(shí)空信息的建模。如 [17] 和[18]的思路是將骨架序列數(shù)據(jù)編碼成圖像,然后送入 CNN 中進(jìn)行動(dòng)作識(shí)別,它們分別給出了骨骼光譜圖和關(guān)節(jié)軌跡圖。此外也有一些工作專注于解決某些特定的問題,比如視點(diǎn)變化問題和計(jì)算成本過高的問題。
基于 GNN/GCN 的方法。
將人體的骨架數(shù)據(jù)表示為一個(gè)序列或 2d/3d 的 image,并不能對(duì)身體關(guān)節(jié)作出完全準(zhǔn)確的模擬。而人體的骨架天然地就可以表示為一個(gè) graph,因此基于 GNN 或 GCN 的 HAR 方法成為了近兩年一個(gè)熱門的研究方向。[19]將人體的骨架表示為了一個(gè)有向無環(huán)圖以有效地合并骨骼和關(guān)節(jié)信息。[20]設(shè)計(jì)了一個(gè)時(shí)空 GCN(Spatial-temporal GCN)以從骨架數(shù)據(jù)中分別學(xué)習(xí) spatial 和 temporal 的 feature。
基于 transformer 的方法。
將 transformer 應(yīng)用于骨骼序列的 HAR 任務(wù)時(shí),研究的重點(diǎn)仍然是時(shí)空維度的建模。比如 [21] 中提出 Spatial-Temporal Specialized Transformer (STST),其由一個(gè) spatial transformer 模塊和一個(gè) temporal transformer 模塊組成。spatial transformer 模塊用于捕捉 frame-level 的姿態(tài)信息,temporal transformer 用于在 temporal 維度上捕捉長(zhǎng)動(dòng)作。
2.3 深度模態(tài)
深度圖中的像素值表示的是從給定視點(diǎn)到場(chǎng)景中的點(diǎn)的距離,所以構(gòu)建深度圖的本質(zhì)是將 3D 數(shù)據(jù)轉(zhuǎn)換為 2D 的 image。該模態(tài)通常對(duì)顏色和紋理的變化比較魯棒,隨著技術(shù)的發(fā)展,現(xiàn)在已經(jīng)有多種設(shè)備可以捕獲場(chǎng)景中的深度圖。現(xiàn)有的對(duì)深度數(shù)據(jù)學(xué)習(xí)的方法大多數(shù)還是利用 CNN 提取深度圖中的 feature。深度數(shù)據(jù)可以提供幾何形狀信息,但是對(duì)外觀數(shù)據(jù)的提供是缺失的,所以深度數(shù)據(jù)通常不單獨(dú)使用,而是與其他模態(tài)的數(shù)據(jù)融合使用。
2.4 紅外模態(tài)
紅外數(shù)據(jù)的獲取主要有兩種方式:(1)主動(dòng)式,發(fā)射紅外線,利用目標(biāo)反射的紅外線感知場(chǎng)景中的物體。(2)被動(dòng)式,通過感知物體發(fā)出的紅外線來感知物體。在目前基于深度學(xué)習(xí)的方法中,比較多的做法是把紅外圖像作為其中一個(gè) stream 輸入雙流或多流網(wǎng)絡(luò)中。紅外數(shù)據(jù)以其不需要依賴外部環(huán)境的可見光的特點(diǎn),特別適合于夜間的 HAR,但是,紅外圖像也有著對(duì)比度低和信噪比低的固有缺點(diǎn)。
2.5 點(diǎn)云模態(tài)
點(diǎn)云數(shù)據(jù)由大量的點(diǎn)組成,這些點(diǎn)可以用來表示物體的空間分布和表面特征。作為一種三維數(shù)據(jù)形態(tài),點(diǎn)云具有很強(qiáng)的表達(dá)物體輪廓和三維幾何形狀的能力,且對(duì)視點(diǎn)的變化不敏感。但是點(diǎn)云中通常存在噪聲和高度不均勻的點(diǎn)分布。[22]將原始的點(diǎn)云序列轉(zhuǎn)換為規(guī)則的體素集合,并應(yīng)用 temporal rank pooling 將 3D 動(dòng)作信息編碼到一個(gè)單獨(dú)的 voxel set 中。最后通過 PonitNet++[23]將體素表示應(yīng)用于 3D HAR 任務(wù)中。但是將點(diǎn)云轉(zhuǎn)換為體素不僅效率較低,而且會(huì)帶來量化誤差。[24]提出直接堆疊多幀點(diǎn)云,并通過聚合 temporal 和 spatial 維度上的相鄰點(diǎn)的信息計(jì)算局部特征。
2.6 事件流模態(tài)
事件照相機(jī)(event camera)可以捕捉照明條件的變化并為每個(gè)像素獨(dú)立產(chǎn)生異步事件。傳統(tǒng)的攝像機(jī)通常會(huì)捕捉整個(gè)圖像陣列,而事件攝像機(jī)僅響應(yīng)視覺場(chǎng)景的變化。事件照相機(jī)能夠有效地濾除背景信息,而只保留前景運(yùn)動(dòng)信息,這樣可以避免視覺信息中的大量冗余,但是其捕捉到的信息通常在時(shí)間和空間維度上是稀疏的,而且是異步的。因此一些現(xiàn)有的方法主要聚焦于設(shè)計(jì)事件聚合策略,將事件攝像機(jī)的異步輸出轉(zhuǎn)換為同步的視覺幀。
2.7 音頻模態(tài)
音頻信號(hào)通常與視頻信號(hào)一起提供,由于音頻和視頻是同步的,所以音頻數(shù)據(jù)可以用定位動(dòng)作。因?yàn)橐纛l信號(hào)中的信息量是不足的,所以單獨(dú)使用音頻數(shù)據(jù)執(zhí)行 HAR 任務(wù)相對(duì)比較少見。更常見的情況是音頻信號(hào)作為 HAR 的補(bǔ)充信息,與其他模態(tài)(如 rgb 圖像)一起使用。
2.8 加速度模態(tài)
加速度信號(hào)通常是從加速度計(jì)中獲得,它具有以下的優(yōu)點(diǎn):(1)對(duì)遮擋、視點(diǎn)、照明、背景等因素的變化具有魯棒性。(2)對(duì)某個(gè)特定的動(dòng)作,人們一般都使用相似的方式完成,所以加速度信號(hào)對(duì)同一個(gè)動(dòng)作的類內(nèi)方差較小。(3)加速模態(tài)可以用于細(xì)粒度的 HAR。但同時(shí),該模態(tài)也存在一些固有的局限性:(1)志愿者需要隨身佩戴傳感器,而且這些傳感器通常比較笨重。(2)傳感器在人體上的具體位置對(duì)性能會(huì)有比較明顯的影響。
2.9 雷達(dá)模態(tài)
雷達(dá)的工作原理是發(fā)射電磁波并接收來自目標(biāo)的回波,其優(yōu)勢(shì)是對(duì)照明和天氣條件變化魯棒,并且具有穿墻感知的能力,但昂貴的傳感器成本是制約其實(shí)際應(yīng)用的重要因素。現(xiàn)有的方法將多普勒頻譜圖視作時(shí)間序列或圖像,并分別送入 RNN 和 CNN 中以預(yù)測(cè)行為類別,目前也有一些方法,將雷達(dá)模態(tài)的數(shù)據(jù)納入到了雙流網(wǎng)絡(luò)結(jié)構(gòu)中。
2.10 wifi 模態(tài)
wifi 是現(xiàn)在最常見的室內(nèi)無線信號(hào)類型之一,由于人體是無線信號(hào)的良好反射體,所以 wifi 信號(hào)可以用于 HAR 任務(wù),現(xiàn)有的基于 wifi 的 HAR 方法大多使用信道狀態(tài)信息(CSI)來執(zhí)行 HAR 任務(wù)。如何更有效地利用 CSI 的相位和幅度信息,以及如何在處理動(dòng)態(tài)環(huán)境時(shí)提高魯棒性,是目前基于 wifi 的 HAR 任務(wù)所面臨的主要挑戰(zhàn)。
3 多模態(tài)學(xué)習(xí)方法
多模態(tài)機(jī)器學(xué)習(xí)是一種建模方法,旨在處理和關(guān)聯(lián)來自多模態(tài)的視覺信息,通過聚合各種數(shù)據(jù)模態(tài)的優(yōu)勢(shì),多模態(tài)學(xué)習(xí)可以在 HAR 任務(wù)上得到更魯棒和準(zhǔn)確的結(jié)果。多模態(tài)學(xué)習(xí)方法主要有兩種,融合(fusion)和協(xié)同學(xué)習(xí)(co-learning)。其中融合指的是對(duì)來自兩個(gè)或更多模態(tài)的信息進(jìn)行集成,并將其用于訓(xùn)練或推理,而協(xié)同學(xué)習(xí)指的則是對(duì)不同模態(tài)之間的知識(shí)進(jìn)行遷移。圖 4 展示了多模態(tài)學(xué)習(xí)方法的分類,對(duì)于每種類型的多模態(tài)學(xué)習(xí)方法,本篇解讀會(huì)介紹原綜述文章中提及的一些具有代表性的方法,更多的方法介紹請(qǐng)直接閱讀原綜述文章。
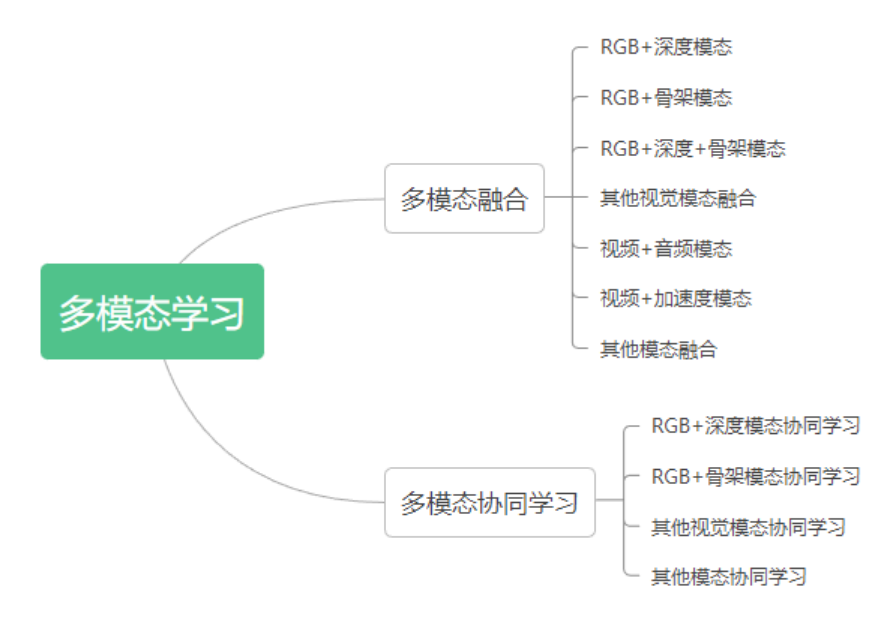
圖 4 多模態(tài) HAR 方法分類
3.1 HAR 任務(wù)中的多模態(tài)融合
模態(tài)融合的目的是利用不同數(shù)據(jù)模態(tài)的互補(bǔ)優(yōu)勢(shì),以達(dá)到更好的識(shí)別性能。現(xiàn)有的多模態(tài)融合方案主要有兩種:(1)評(píng)分融合(score fusion),即對(duì)不同模態(tài)輸出的 score 做融合,例如使用加權(quán)平均或?qū)W習(xí)一個(gè)分?jǐn)?shù)融合模型。(2)特征融合,即對(duì)來自不同模態(tài)的特征進(jìn)行組合。數(shù)據(jù)融合(在特征提取之前就融合不同模態(tài)的輸入數(shù)據(jù))可以看成是特征融合,因?yàn)槟骋荒B(tài)的數(shù)據(jù)可以被視為該模態(tài)的原始特征。依據(jù)輸入模態(tài)的不同,現(xiàn)有的多模態(tài)融合方法大概可以分為視覺模態(tài)之間的融合,與視覺 + 非視覺模態(tài)之間的融合兩種,下面對(duì)這兩類方法分別做一個(gè)較為詳細(xì)的介紹。
視覺模態(tài)之間的融合
(1)RGB + 深度模態(tài):RGB 和深度模態(tài)分別能夠捕捉外觀信息和 3D 形狀信息,因此它們具有比較強(qiáng)的互補(bǔ)性。[25]提出了一個(gè) four-stream CNN,其中一個(gè) stream 輸入 RGB 數(shù)據(jù),剩下三個(gè) stream 分別輸入三個(gè)不同視點(diǎn)下捕捉的深度運(yùn)動(dòng)圖,融合策略選擇評(píng)分融合。[26]將 RGB 和深度數(shù)據(jù)看做兩對(duì) RGB 和深度的動(dòng)態(tài)圖像,通過一個(gè)協(xié)同訓(xùn)練的 CNN 提取特征,并聯(lián)合優(yōu)化排序損失和 softmax 損失來進(jìn)行訓(xùn)練。[27]同樣提出了一個(gè)多流混合網(wǎng)絡(luò),該網(wǎng)絡(luò)分別使用 CNN 和 3D convLSTM 來提取來自 RGB 和深度圖的特征,然后通過典型關(guān)聯(lián)分析(Canonical Correlation Analysis)進(jìn)行模態(tài)間的信息融合。
(2)RGB + 骨架模態(tài):骨架模態(tài)可以提供身體位置和關(guān)節(jié)運(yùn)動(dòng)信息,同樣和 RGB 模態(tài)是互補(bǔ)的。[28]提出了一個(gè)雙流深度網(wǎng)絡(luò),兩個(gè) stream 分別是 CNN 和 RNN,用以分別處理 RGB 和骨架數(shù)據(jù),融合方式同時(shí)嘗試了特征融合和分?jǐn)?shù)融合,并發(fā)現(xiàn)應(yīng)用特征融合策略可以取得更好的效果。[29]設(shè)計(jì)了一個(gè) three-stream 的 3D CNN 來分別處理人體姿態(tài)、運(yùn)動(dòng)和 RGB 圖像,通過馬爾科夫鏈來融合三個(gè) stream,并用于動(dòng)作分類。[30]提出了一種時(shí)空 LSTM 網(wǎng)絡(luò),它能夠在 LSTM 單元內(nèi)有效地融合 RGB 和骨架特征。
(3)深度圖 + 骨架模態(tài):[31]將身體的每個(gè)部分與其他部分之間的相對(duì)幾何關(guān)系作為骨架特征,將不同身體部分周圍的深度圖像塊作為外觀特征,以編碼身體 - 對(duì)象和身體部分 - 身體部分之間的關(guān)系,進(jìn)而實(shí)現(xiàn)可靠的 HAR。[32]提出了一種 three-stream 的 2D CNN,對(duì)深度和骨架序列提取的三種不同的手工特征進(jìn)行分類,然后采用評(píng)分融合模塊得到最終的分類結(jié)果。
(4)RGB + 深度圖 + 骨架模態(tài):這類方法大多是前文提到的三類多模態(tài)融合方法的擴(kuò)展。如 [33] 研究了模態(tài)之間的相關(guān)性,將它們分解成相關(guān)和獨(dú)立的成分,然后使用一個(gè)結(jié)構(gòu)化的基于稀疏性的分類器輸出分類結(jié)果。[34]從每個(gè)模態(tài)提取 temporal feature map,然后再在模態(tài)維度對(duì)這些 feature map 執(zhí)行 concat 操作,以獲得跨 RGB、骨架和深度模態(tài)的時(shí)變信息。[35]提出了一個(gè) five-stream network,歷史運(yùn)動(dòng)圖像、深度運(yùn)動(dòng)圖、以及三個(gè)分別從 RGB, 深度和骨架序列生成的骨架圖像分別是這 5 個(gè) stream 的輸入。
(5)其他視覺模態(tài)間的融合:這些方法的思路與前文中所述的基本類似,比如 [36] 中提出了一個(gè)基于 TSN[37]的多模態(tài)融合模型,RGB、深度圖、紅外和光流序列分別使用 TSN 執(zhí)行初始分類,然后使用一個(gè)融合網(wǎng)絡(luò),以獲取最終的分類分?jǐn)?shù)。
視覺模態(tài) + 非視覺模態(tài)的融合
同樣地,視覺與非視覺模態(tài)的融合,其目的也是希望能夠利用不同模態(tài)之間的互補(bǔ)性,得到更精確的 HAR 模型。
(1)視頻與音頻的融合:前文中已經(jīng)提到,音頻可以為視頻的外觀和運(yùn)動(dòng)信息提供補(bǔ)充信息。所以目前已經(jīng)有一些基于深度學(xué)習(xí)的方法來融合這種模態(tài)的數(shù)據(jù),比如 [38] 引入了一個(gè) three-stream 的 CNN,從音頻信號(hào),RGB 幀和光流中分別提取特征,然后再進(jìn)行融合(在該文中,特征融合的效果好于評(píng)分融合)。[39]是 [37] 的一個(gè)改進(jìn),其在每個(gè)時(shí)間綁定窗口內(nèi)融合多模態(tài)輸入序列(也就是說,融合來自不同模態(tài)的信息可能是異步的)。[40]利用音頻信號(hào)減少了視頻中的時(shí)間冗余,其思想是把使用 video clips 訓(xùn)練的 teacher network 中的知識(shí)提取到使用圖像 - 音頻對(duì)訓(xùn)練的 student network 中。
(2)視頻與加速度模態(tài)的融合:現(xiàn)有的基于深度學(xué)習(xí)的視頻與加速度模態(tài)融合的方法大多是采用雙流或多流網(wǎng)絡(luò)的架構(gòu),比如 [41] 將慣性信號(hào)表示為圖像,然后使用兩個(gè) CNN 分別處理視頻和慣性信號(hào),最后使用評(píng)分融合的方法融合兩個(gè)模態(tài)的信號(hào)。[42]則是將 3D 視頻幀序列和 2D 的慣性圖像分別送入 3D CNN 和 2D CNN 中,然后執(zhí)行模態(tài)間的融合。
(3)其他類型的模態(tài)融合:這類方法中,相對(duì)比較有代表性的是 [43] 和[44],其中 [43] 的核心思想是將非 RGB 模態(tài)的數(shù)據(jù),包括骨架、加速度和 wifi 數(shù)據(jù)都轉(zhuǎn)換成彩色圖像,然后送入 CNN 中。[44]則提出了一種 video-audio-text transformer(VATT),將視頻,音頻和文本數(shù)據(jù)的線性投影作為 transformer 的輸入,并提取多模態(tài)的特征表示,VATT 還量化了不同模態(tài)的粒度,并且采用視頻 - 音頻對(duì)和視頻 - 文本對(duì)的 NCE Loss 進(jìn)行訓(xùn)練。
3.2 HAR 任務(wù)中的多模態(tài)協(xié)同學(xué)習(xí)
多模態(tài)協(xié)同學(xué)習(xí)旨在探索如何利用輔助模態(tài)學(xué)習(xí)到的知識(shí)幫助另一個(gè)模態(tài)的學(xué)習(xí),希望通過跨模態(tài)的知識(shí)傳遞和遷移可以克服單一模態(tài)的缺點(diǎn),提高性能。多模態(tài)協(xié)同學(xué)習(xí)與多模態(tài)融合的一個(gè)關(guān)鍵區(qū)別在于,在多模態(tài)協(xié)同學(xué)習(xí)中,輔助模態(tài)的數(shù)據(jù)僅僅在訓(xùn)練階段需要,測(cè)試階段并不需要。所以多模態(tài)協(xié)同學(xué)習(xí)尤其適用于模態(tài)缺失的場(chǎng)景。此外對(duì)于模態(tài)樣本數(shù)較小的場(chǎng)景,多模態(tài)協(xié)同學(xué)習(xí)也可以起到一定的幫助作用。
視覺模態(tài)的協(xié)同學(xué)習(xí)
(1)RGB 和深度模態(tài)的協(xié)同學(xué)習(xí)。如 [45] 使用知識(shí)蒸餾的方法實(shí)現(xiàn)模態(tài)間的協(xié)同學(xué)習(xí),其中 teacher network 輸入深度圖,而 student network 輸入的則是 RGB 圖像。[46]提出了一種基于對(duì)抗學(xué)習(xí)的知識(shí)提取策略用來訓(xùn)練 student network。[47]則提出了一種合作學(xué)習(xí)策略,即在不同的輸入模態(tài)中,使用分類損失最小的模態(tài)所生成的預(yù)測(cè)標(biāo)簽,作為其他模態(tài)訓(xùn)練的附加監(jiān)督信息。 (2)RGB 和骨架模態(tài)的協(xié)同學(xué)習(xí)。如 [48] 利用 CNN+LSTM 執(zhí)行基于 RGB 視頻的分類,并利用在骨架數(shù)據(jù)上訓(xùn)練的 LSTM 模型充當(dāng)調(diào)節(jié)器,強(qiáng)制兩個(gè)模型的輸出特征相似。 (3)其他視覺模態(tài)的協(xié)同學(xué)習(xí)。除了 RGB、骨架、深度模態(tài)的協(xié)同學(xué)習(xí)之外,目前也有一些其他的視覺模態(tài)的協(xié)同學(xué)習(xí)的工作,比如 [49] 提出了一種可遷移的生成模型,該模型使用紅外視頻作為輸入,并生成與其對(duì)應(yīng)的 RGB 視頻的虛假特征表達(dá)。該方法的生成器由兩個(gè)子網(wǎng)絡(luò)組成,第一個(gè)子網(wǎng)絡(luò)用以區(qū)分生成的虛假特征和真實(shí)的 RGB 特征,第二個(gè)子網(wǎng)絡(luò)將紅外視頻的特征表達(dá)和生成的特征作為輸入,執(zhí)行動(dòng)作的分類。
視覺和非視覺模態(tài)的協(xié)同學(xué)習(xí)
這類工作可以大致分為兩種類型,第一種類型是在不同模態(tài)之間進(jìn)行知識(shí)的遷移,如 [50] 中的 teacher network 使用非視覺模態(tài)訓(xùn)練,而 student network 使用 RGB 模態(tài)作為輸入,通過強(qiáng)制 teacher 和 student 的 attention map 相似以彌補(bǔ)模態(tài)間的形態(tài)差距,并實(shí)現(xiàn)知識(shí)的提煉。第二種類型是利用不同模態(tài)之間的相關(guān)性進(jìn)行自監(jiān)督學(xué)習(xí),比如 [51] 分別利用音頻 / 視頻模態(tài)中的無監(jiān)督聚類結(jié)果作為視頻 / 音頻模態(tài)的監(jiān)督信號(hào)。[52]使用視頻和音頻的時(shí)間同步信息作為自監(jiān)督信號(hào)。
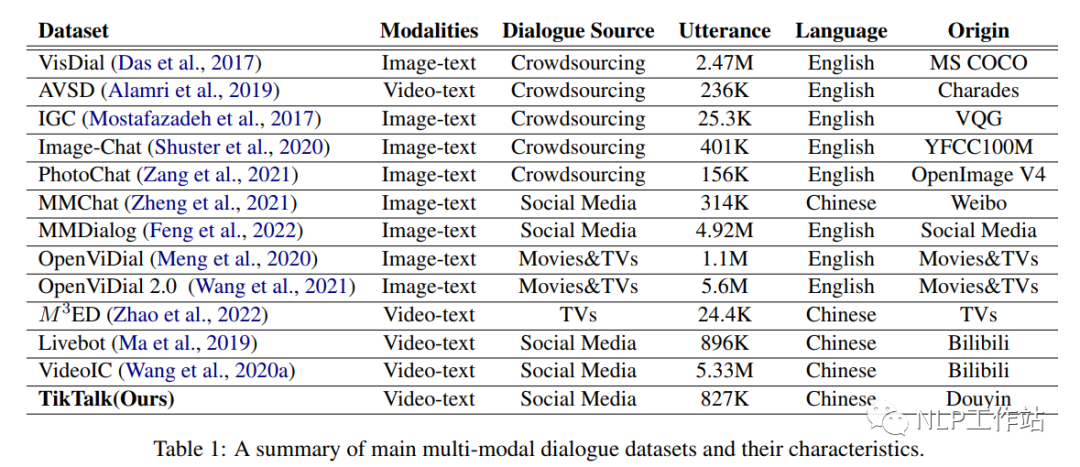
4 現(xiàn)有的數(shù)據(jù)集
原論文中的 table 6 展示了目前 HAR 任務(wù)的各個(gè)數(shù)據(jù)模態(tài)的數(shù)據(jù)集,展示如下:
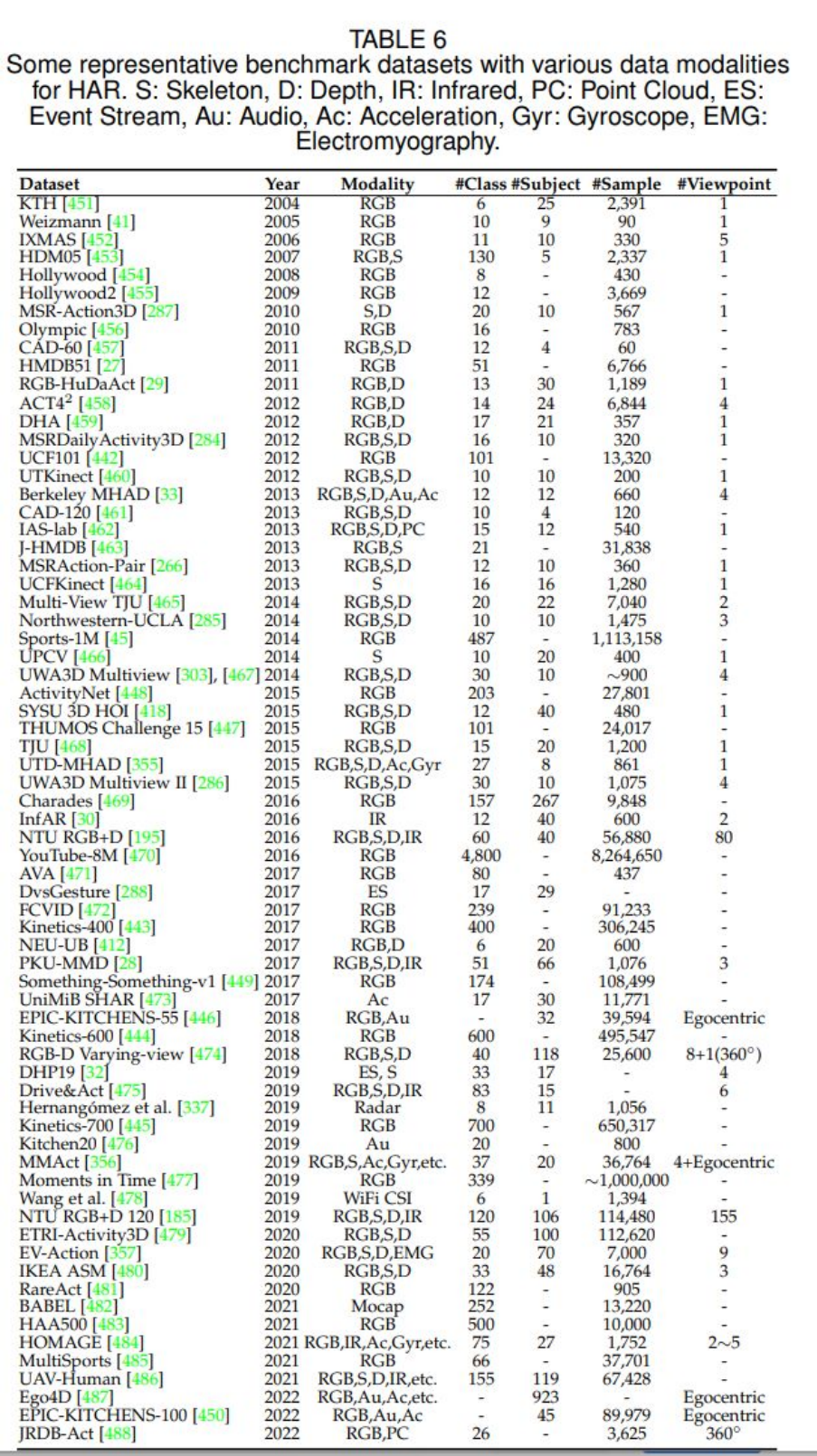
可以看到,對(duì)于絕大部分?jǐn)?shù)據(jù)模態(tài),目前都存在對(duì)應(yīng)的數(shù)據(jù)集,這些數(shù)據(jù)集也在很大程度上方便了我們對(duì) HAR 任務(wù)的研究和探索。 5 總結(jié) 作者在原綜述文章的最后一部分展望了 HAR 領(lǐng)域未來的發(fā)展方向,作者認(rèn)為有 6 個(gè)方向可能是未來研究和探索的重點(diǎn),分別是:(1)新的數(shù)據(jù)集(比如不受控環(huán)境下的多模態(tài)數(shù)據(jù)集);(2)多模態(tài)學(xué)習(xí);(3)高效的行為分析;(4)早期行為識(shí)別(即只有一部分動(dòng)作被執(zhí)行);(5)大規(guī)模訓(xùn)練;(6)無監(jiān)督和半監(jiān)督學(xué)習(xí)。作者還提到,他們會(huì)定期地收集 HAR 領(lǐng)域的最新進(jìn)展并更新到本綜述文章中。
6 個(gè)人思考
該綜述調(diào)研了約 500 篇文章,涵蓋了 HAR 任務(wù)中可能使用的各個(gè)模態(tài),是對(duì)這一領(lǐng)域非常全面的總結(jié)。從綜述中可以看到,無論是單模態(tài)還是多模態(tài)的模型,其 backbone 通常都是以下幾種網(wǎng)絡(luò)之一(或它們的組合):
(1)2D CNN(空間信息的提取);
(2)RNN/LSTM/GRU(時(shí)序信息的提取);
(3)3D CNN(時(shí)間 + 空間維度的信息提取);
(4)GNN/GCN(節(jié)點(diǎn)之間的關(guān)系抽取);
(5)transformer(長(zhǎng)時(shí)序建模)。
對(duì)于 HAR 任務(wù)中的多模態(tài)融合來說,目前最常見的做法是使用一個(gè)雙流或多流網(wǎng)絡(luò),每個(gè) stream 分別提取一個(gè)模態(tài)的特征,然后再后接一個(gè)多模態(tài)融合模塊。對(duì)于 HAR 任務(wù)中的多模態(tài)協(xié)同學(xué)習(xí)來說,目前常見的做法則是使用跨模態(tài)知識(shí)蒸餾或?qū)箤W(xué)習(xí)的框架完成。這些 backbone 和融合 / 協(xié)同學(xué)習(xí)策略的組合,可以概括目前 HAR 領(lǐng)域的大部分文章。 對(duì)不同模態(tài)的數(shù)據(jù),往往需要不同的模型來提取其特征,這對(duì)于 HAR 的模型設(shè)計(jì)來說是非常不方便的。有時(shí)為了適配現(xiàn)有的模型,需要對(duì)某些模態(tài)的數(shù)據(jù)做一些特定的預(yù)處理(比如目前提取音頻模態(tài)特征的一種常用方法是,將一維的音頻信號(hào)轉(zhuǎn)換成二維的頻譜圖,再送入 CNN 中進(jìn)行特征提取),這些特定的預(yù)處理可能存在一定的信息丟失。所以是否可以有一種通用的模型,能夠比較好地處理各種形態(tài)不同的多模態(tài)數(shù)據(jù)呢?這是目前整個(gè) AI 界都比較關(guān)注的一個(gè)問題,而其在 HAR 任務(wù)上體現(xiàn)的尤為明顯。transformer 目前在圖像、文本等模態(tài)中都取得了非常好的效果,它能否成為我們期待的通用模型呢?以現(xiàn)在 AI 領(lǐng)域日新月異的發(fā)展速度,我相信我們很快就可以看到答案。 另外,該綜述的多模態(tài)學(xué)習(xí)部分,按照使用的模態(tài)對(duì)現(xiàn)有的工作進(jìn)行了分類總結(jié),而多模態(tài)學(xué)習(xí)的研究核心,很大的一部分在于模態(tài)間的融合或協(xié)同學(xué)習(xí)的策略,如果能夠按照具體的融合或協(xié)同學(xué)習(xí)的策略對(duì)現(xiàn)有的工作進(jìn)行分類總結(jié),可能會(huì)更好一些。
參考文獻(xiàn)
[1] K. Simonyan and A. Zisserman, "Two-stream convolutional networks for action recognition in videos," in Advances in Neural Information Processing Systems, vol. 27, 2014.
[2] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei, "Large-scale video classification with convolutional neural networks," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 1725-1732.
[3] B. Zhang, L. Wang, Z. Wang, Y. Qiao, and H. Wang, "Real-time action recognition with enhanced motion vector cnns," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 2718-2726.
[4] J. Donahue, L. Anne Hendricks, S. Guadarrama, M. Rohrbach, S. Venugopalan, K. Saenko, and T. Darrell, "Long-term recurrent convolutional networks for visual recognition and description," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 2625-2624.
[5] S. Sharma, R. Kiros, and R. Salakhutdinov, "Action recognition using visual attention," arXiv preprint arXiv:1511.04119, 2015.
[6] Z. Wu, X. Wang, Y.-G. Jiang, H. Ye, and X. Xue, “Modeling spatial-temporal clues in a hybrid deep learning framework for video classification,” in Proceedings of the 23rd ACM international conference on Multimedia, 2015, pp. 461-470.
[7] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, "Learning spatiotemporal features with 3d convolutional networks," in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 4489-4497.
[8] G. Varol, I. Laptev, and C. Schmid, "Long-term temporal convolutions for action recognition," IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 6, pp. 1510-1517, 2017.
[9] Z. Qiu, T. Yao, and T. Mei, "Learning spatio-temporal representation with pseudo-3d residual networks," in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 4489-4497.
[10] Y. Zhou, X. Sun, C. Luo, Z.-J. Zha, and W. Zeng, "Spatiotemporal fusion in 3d cnns: A probabilistic view," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 1725-1732.
[11] J. Kim, S. Cha, D. Wee, S. Bae, and J. Kim, "Regularization on spatio-temporally smoothed feature for action recognition," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 12103-12112.
[12] ] G. Bertasius, H. Wang, and L. Torresani, "Is space-time attention all you need for video understanding?," in ICML, vol. 2, no. 3, 2021.
[13] Q. Fan, C.-F. Chen, and R. Panda, "Can an image classifier suffice for action recognition?," in International Conference on Learning Representations, 2022.
[14] D. Neimark, O. Bar, M. Zohar, and D. Asselmann, "Video transformer network," in Proceedings of the IEEE International Conference on Computer Vision, 2021, pp. 3163-3172.
[15] Y. Du, W. Wang, and L. Wang, "Hierarchical recurrent neural network for skeleton based action recognition," in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 1110-1118.
[16] A. Shahroudy, J. Liu, T.-T. Ng, and G. Wang, "Ntu rgb+d: A large scale dataset for 3d human activity analysis," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 1010-1019.
[17] Y. Hou, Z. Li, P. Wang, and W. Li, "Skeleton optical spectra-based action recognition using convolutional neural networks," IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 3, 2016.
[18] P. Wang, Z. Li, Y. Hou, and W. Li, "Action recognition based on joint trajectory maps using convolutional neural networks," in Proceedings of the 24th ACM international conference on Multimedia, 2016, pp. 102-106.
[19] L. Shi, Y. Zhang, J. Cheng, and H. Lu, "Skeleton-based action recognition with directed graph neural networks," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 7912-7921.
[20] S. Yan, Y. Xiong, and D. Lin, "Spatial temporal graph convolutional networks for skeleton-based action recognition," in Thirty-second AAAI conference on artificial intelligence, 2018.
[21] Y. Zhang, B. Wu, W. Li, L. Duan, and C. Gan, "Stst: Spatial-temporal specialized transformer for skeleton-based action recognition," in Proceedings of the 29th ACM international conference on Multimedia, 2021, pp. 3229-3237.
[22] Y. Wang, Y. Xiao, F. Xiong, W. Jiang, Z. Cao, J. T. Zhou, and J. Yuan, "3dv: 3d dynamic voxel for action recognition in depth video," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 511-520.
[23] C. R. Qi, L. Yi, H. Su, and L. J. Guibas, "Pointnet++: Deep hierarchical feature learning on point sets in a metric space," in Advances in Neural Information Processing Systems, vol. 30, 2017.
[24] X. Liu, M. Yan, and J. Bohg, "Meteornet: Deep learning on dynamic 3d point cloud sequences," in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 9246-9255.
[25] J. Imran and P. Kumar, "Human action recognition using rgb-d sensor and deep convolutional neural networks," in 2016 international conference on advances in computing, communications and informatics (ICACCI), 2016, pp. 144-148.
[26] P. Wang, W. Li, J. Wan, P. Ogunbona, and X. Liu, "Cooperative training of deep aggregation networks for rgb-d action recognition," in Thirty-second AAAI conference on artificial intelligence, 2018.
[27] H. Wang, Z. Song, W. Li, and P. Wang, "A hybrid network for large-scale action recognition from rgb and depth modalities," Sensors, vol. 20, no. 11, 2020.
[28] R. Zhao, H. Ali, and P. Van der Smagt, "Two-stream rnn/cnn for action recognition in 3d videos," in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017, pp. 4260-4267.
[29] M. Zolfaghari, G. L. Oliveira, N. Sedaghat, and T. Brox, "Chained multi-stream networks exploiting pose, motion, and appearance for action classification and detection," in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 2904-2913.
[30] J. Liu, A. Shahroudy, D. Xu, A. C. Kot, and G. Wang, "Skeleton-based action recognition using spatio-temporal lstm network with trust gates," IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 12, pp. 3007-3021, 2017.
[31] H. Rahmani and M. Bennamoun, "Learning action recognition model from depth and skeleton videos," in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 5832-5841.
[32] S. S. Rani, G. A. Naidu, and V. U. Shree, "Kinematic joint descriptor and depth motion descriptor with convolutional neural networks for human action recognition," Materials Today, vol. 37, 3164-3173, 2021.
[33] A. Shahroudy, T.-T. Ng, Y. Gong, and G. Wang, "Deep multimodal feature analysis for action recognition in rgb+d videos," IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 5, pp. 1045-1058, 2017.
[34] J.-F. Hu, W.-S. Zheng, J. Pan, J. Lai, and J. Zhang, "Deep bilinear learning for rgb-d action recognition," in Proceedings of the European Conference on Computer Vision, 2018, pp. 5832-5841.
[35] P. Khaire, P. Kumar, and J. Imran, "Combining cnn streams of rgb-d and skeletal data for human activity recognition," Pattern Recognition Letters, vol. 115, pp. 107-116, 2018.
[36] S. Ardianto and H.-M. Hang, "Multi-view and multi-modal action recognition with learned fusion," in 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pp. 1601-1604, 2018.
[37] L. Wang, Y. Xiong, Z. Wang, Y. Qiao, D. Lin, X. Tang, and L. Van Gool, "Temporal segment networks: Towards good practices for deep action recognition," in Proceedings of the European Conference on Computer Vision, 2016, pp. 20-36.
[38] C. Wang, H. Yang, and C. Meinel, "Exploring multimodal video representation for action recognition,"in 2016 International Joint Conference on Neural Networks (IJCNN), pp. 1924-1931, 2016.
[39] E. Kazakos, A. Nagrani, A. Zisserman, and D. Damen, "Epic-fusion: Audiovisual temporal binding for egocentric action recognition," in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 5492-5501.
[40] R. Gao, T.-H. Oh, K. Grauman, and L. Torresani, "Listen to look: Action recognition by previewing audio," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 10457-10467.
[41] N. Dawar and N. Kehtarnavaz, "A convolutional neural network-based sensor fusion system for monitoring transition movements in healthcare applications," in 2018 IEEE 14th International Conference on Control and Automation (ICCA), pp. 482-485, 2018.
[42] H. Wei, R. Jafari, and N. Kehtarnavaz, "Fusion of video and inertial sensing for deep learning–based human action recognition," Sensors, vol. 19, no. 17, 2019.
[43] A. Gorban, H. Idrees, Y.-G. Jiang, A. Roshan Zamir, I. Laptev, M. Shah, and R. Sukthankar, "THUMOS challenge: Action recognition with a large number of classes." http://www.thumos.info/, 2015.
[44] H. Akbari, L. Yuan, R. Qian, W.-H. Chuang, S.-F. Chang, Y. Cui, and B. Gong, "Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text,"in Advances in Neural Information Processing Systems, vol. 27, 2014.
[45] N. C. Garcia, P. Morerio, and V. Murino, "Modality distillation with multiple stream networks for action recognition," in Proceedings of the European Conference on Computer Vision, 2018, pp. 5832-5841.
[46] N. C. Garcia, P. Morerio, and V. Murino, "Learning with privileged information via adversarial discriminative modality distillation," IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 10, pp. 2581-2593, 2019.
[47] N. C. Garcia, S. A. Bargal, V. Ablavsky, P. Morerio, V. Murino, and S. Sclaroff, "Dmcl: Distillation multiple choice learning for multimodal action recognition," arXiv preprint arXiv:1912.10982, 2019.
[48] B. Mahasseni and S. Todorovic, "Regularizing long short term memory with 3d human-skeleton sequences for action recognition," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 3054-3062.
[49] . Wang, C. Gao, L. Yang, Y. Zhao, W. Zuo, and D. Meng, "Pm-gans: Discriminative representation learning for action recognition using partial-modalities," in Proceedings of the European Conference on Computer Vision, 2018, pp. 384-401.
[50] Y. Liu, K. Wang, G. Li, and L. Lin, "Semantics-aware adaptive knowledge distillation for sensor-to-vision action recognition," IEEE Transactions on Image Processing, vol. 30, pp. 5573-5588, 2021.
[51] H. Alwassel, D. Mahajan, L. Torresani, B. Ghanem, and D. Tran, "Self supervised learning by cross-modal audio-video clustering," arXiv preprint arXiv:1911.12667, 2019.
[52] B. Korbar, D. Tran, and L. Torresani, "Cooperative learning of audio and video models from self-supervised synchronization," in Advances in Neural Information Processing Systems, vol. 31, 2018.
編輯:黃飛













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論