 電子發燒友App
電子發燒友App


王帥琛, 黃倩, 張云飛, 李興, 聶云清, 雒國萃。 2022. 多模態數據的行為識別綜述。 中國圖象圖形學報, 27(11): 3139-3159.
摘要:行為識別是當前計算機視覺方向中視頻理解領域的重要研究課題。從視頻中準確提取人體動作的特征并識別動作,能為醫療、安防等領域提供重要的信息,是一個十分具有前景的方向。本文從數據驅動的角度出發,全面介紹了行為識別技術的研究發展,對具有代表性的行為識別方法或模型進行了系統闡述。行為識別的數據分為RGB模態數據、深度模態數據、骨骼模態數據以及融合模態數據。首先介紹了行為識別的主要過程和人類行為識別領域不同數據模態的公開數據集;然后根據數據模態分類,回顧了RGB模態、深度模態和骨骼模態下基于傳統手工特征和深度學習的行為識別方法,以及多模態融合分類下RGB模態與深度模態融合的方法和其他模態融合的方法。傳統手工特征法包括基于時空體積和時空興趣點的方法(RGB模態)、基于運動變化和外觀的方法(深度模態)以及基于骨骼特征的方法(骨骼模態)等;深度學習方法主要涉及卷積網絡、圖卷積網絡和混合網絡,重點介紹了其改進點、特點以及模型的創新點。基于不同模態的數據集分類進行不同行為識別技術的對比分析。通過類別內部和類別之間兩個角度對比分析后,得出不同模態的優缺點與適用場景、手工特征法與深度學習法的區別和融合多模態的優勢。最后,總結了行為識別技術當前面臨的問題和挑戰,并基于數據模態的角度提出了未來可行的研究方向和研究重點。
00 引言
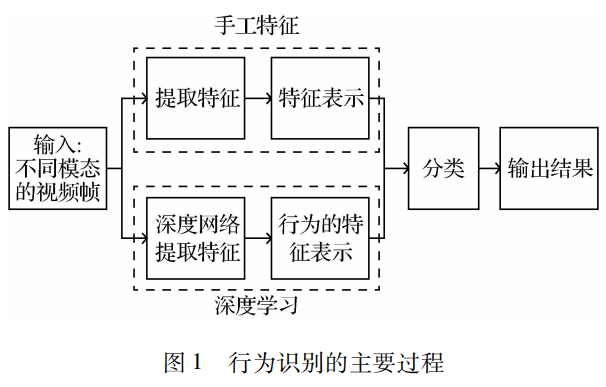
人體行為識別是計算機視覺、深度學習、視頻處理和模式識別等學科交叉的研究課題,是當前計算機視覺的一個研究熱點。行為識別是對包含人體動作行為的視頻序列進行動作特征提取、特征表示和動作識別等操作的過程。由于視頻采集傳感器的成本降低和快速發展,使得行為識別有了廣泛的應用前景,例如視頻檢索、人機交互、醫學監測和自動駕駛等領域,都涉及行為識別的相關技術。行為識別屬于視頻理解的范疇,所以特征的提取和表示至關重要。這兩個過程的好壞會直接影響最終的分類結果。特征可以通過手工制作和網絡學習獲取,圖 1介紹了兩種方法的基本過程。手工特征的方法利用圖像和數學等知識,設計出一種表達動作的方式,通過表達動作的信息區分不同類別的動作。算法實現更簡單,但是常常局限于某個數據集。深度學習網絡自適應性更好,能夠根據輸入數據和設計的網絡提取出側重的特征,并能依靠反向傳播等手段優化提取特征的過程,最終得到一個能高效提取動作特征和正確分類的網絡模型。
從數據驅動的角度出發,可將行為識別方法分為基于RGB數據的方法、基于深度數據的方法、基于骨骼數據的方法和融合以上模態數據的方法,如圖 2所示。每種數據的模態都有自身特性導致的優缺點,如RGB模態數據易采集但魯棒性較差。因此提出了融合多模態的方法,以克服一些單模態存在的問題。本文相比較其他行為識別綜述的貢獻在于:1)本文的數據模態分類、方法分類和數據集分類一一對應,對初學者或者長期研究者都提供了一個結構清晰的介紹和對比;2)其他的行為識別綜述通常注重單一模態下的論述,而本文更加全面地論述了多種數據模態和數據融合的行為識別;3)近年的行為識別綜述只包含深度學習,缺少早期手工特征的方法,本文分析手工特征的思想優點和深度學習的優勢,進而實現優勢互補;4)討論了不同數據模態的優劣性和動作識別的挑戰以及未來研究方向。
01 行為識別數據集
在評價不同識別方法的性能時,數據集有非常重要的作用。目前有許多公開的行為數據集供研究人員使用。主流數據集的詳細信息如表 1所示。
HMDB-51(human motion database)(Kuehne等,2011)中數字51代表類別數量。它是從各種互聯網資源和數字化電影中收集形成,此數據集的動作主要是日常行為,如圖 3所示。該數據集包含6 849個視頻,分為51個動作類別,每種動作包含101個視頻片段。該數據集的干擾因素主要是攝像機視角和運動的變化、背景雜亂、志愿者位置和外觀的變化。

UCF101(Soomro等,2012)是由美國中佛羅里達大學計算機視覺研究中心發布的數據集,是UCF50數據集的擴展,收集自YouTube,提供了包含101個動作類別的13 320個視頻樣本數據。UCF101在動作方面提供了最大的多樣性,在攝像機運動、對象的外觀和姿態、對象規模、視點、雜亂的背景以及照明條件等方面有很大的變化。Kinetics(Carreira和Zisserman,2017)是一個大規模、高質量的YouTube視頻數據集,其中包括各種各樣的以人為中心的動作。該數據集由大約300 000個視頻片段組成,涵蓋400種動作類別,每個動作至少有400個視頻片段。每個片段持續大約10 s,并標記為一個動作類別。所有片段都經過多輪人工標注,都是從一個獨特的YouTube視頻中獲得。這些動作涵蓋了廣泛的動作類別,包括人與物的交互,如演奏樂器;以及人與人的交互,如握手和擁抱。發布者先后在2016年、2017年、2018年相繼發布了Kinetics-400、Kinetics-600(Carreira等,2018)和Kinetics-700(Carreira等,2019)系列,代表視頻中的動作可分為400、600、700個類別。Something-Something數據集(Goyal等,2017)是一個中等規模的數據集,它與一般數據集的最大區別在于,其內容定義的是原子動作,并且該數據集特別注重時序上的關系。第1版本和第2版本數據集由108 499個和220 847個視頻組成,均可分為174個動作類別。MSR-Action3D(Li等,2010)是微軟研究院利用Kinect深度相機捕獲的動作數據集。它包含20種與人類運動相關的活動,如慢跑、高爾夫揮桿等。圖 4為其中3個動作的深度圖實例。這個數據集中的每個動作由10個人執行2~3次,總共包含567個樣本。因為動作的高度相似性,該數據集具有一定的挑戰性。

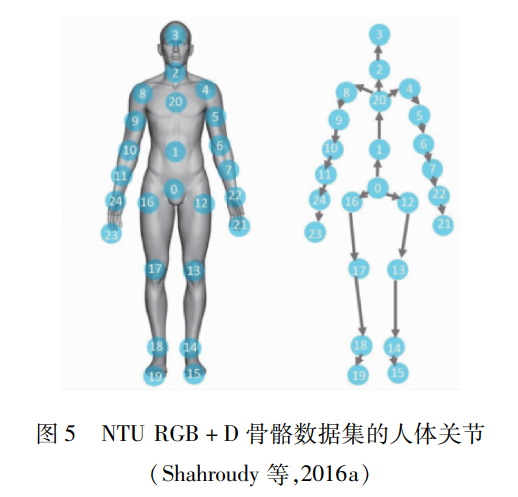
MSR-Daily Activity(Wang等,2012)是微軟研究院(MSR)利用Kinect相機拍攝日常活動采集而成的數據集,共有16種動作類別,320個活動樣本。其中,骨骼跟蹤器提取的3維關節位置信息非常嘈雜,大部分活動都涉及人與物的交互。因此,動作的識別難度較大。UTD-MHAD(Chen等,2015a)數據集是美國得克薩斯大學達拉斯分校(The University of Texas at Dallas,UTD)發布的多模態人體行為識別數據集(MHAD),由8個表演者執行27個類別的動作組成。每個表演者重復動作4次,總共包括861個視頻序列。該數據集包含RGB模態、深度模態、骨架模態和慣性傳感器信號。NTU RGB+D(Shahroudy等,2016a)數據集由新加坡南洋理工大學創建,包含RGB模態和深度模態。它是迄今為止最大的動作數據集,包含56 880個樣本數據和超過400萬幀的視頻。該數據集一共有60個動作類別,基于3臺攝像機,在3個不同的視角,拍攝表演者的動作過程。這個數據集對于不同的視頻序列具有可變的序列長度,并且表現出很高的類內變化。該數據集包含了RGB模態、深度模態和骨骼模態。骨骼模態的數據集包含了25個關節記錄信息,圖 5為人體的25個關節示意圖。NTU RGB+D 120(Liu等,2020a)是NTU RGB+D數據集的擴展,添加了另外60個類別動作和57 600個視頻樣本,與之前的工作疊加形成120個動作類別和114 480個樣本的大型數據集。
02 基于RGB數據的行為識別方法
RGB數據的優點在于成本低、易獲取,缺點在于對外觀的變化(如光線變化)缺少魯棒性。當識別目標與背景具有相似顏色和紋理時,僅用RGB數據很難處理這個問題,這些局限妨礙了基于RGB數據的行為識別技術在復雜環境中的應用。基于RGB的行為特征的生成方式可分為手工制作和機器學習。
2.1 基于手工特征的方法
手工制作的目的是得到人體行為動作的運動和時空變化,包括基于時空體積的動作表示法、基于時空興趣點的方法和基于骨骼關節軌跡的方法。基于時空體積的動作表示法利用3維的時空模板進行動作識別,關鍵在于匹配模板的構造和編碼運動信息。Bobick和Davis(2001)提出了MEI(motion-energy images)和MHI(motion-history images)分別表示動作發生的空間位置和動作發生的時間過程,如圖 6所示,MEI提取空間特征,MHI提取時間特征。在前期階段,運動歷史圖和運動能量圖十分相似,但在后期階段兩者有較大的區別。Klaser等人(2008)在2D HOG(histogram of oriented gradient)的基礎上,拓展出3D HOG特征來描述人體行為,提高了識別準確率。上述文獻的創新在于特征的表示,新穎的特征表示思想十分具有參考價值。但背景的噪聲和遮擋會使特征提取十分困難,并且忽略了一些局部特征,對近似動作識別具有局限性。

基于時空興趣點的方法較時空體積法對背景的要求降低,它通過提取運動變化明顯的關鍵區域來表示動作,重點在于關鍵興趣點的檢測方法、描述的特征和分類方法。最常見的方法是基于3D-Harris時空特征點來檢測關鍵區域。Chakraborty等人(2012)提出了一種改進后的3D-Harris方法,將局部特征檢測技術從圖像擴展到3維時空域,然后計算特征描述子,并利用描述行為的視覺詞袋模型來構建視覺單詞詞匯表,用于加強對行為的描述。Nguyen等人(2015)提出了一種基于時空注意機制的關鍵區域提取方法,將密集采樣與視頻顯著信息驅動的時空特征池相結合,構造視覺詞典和動作特征。密集采樣能更好地表示動作,但是增加了算法的復雜度,因此平衡采樣密集度和算法復雜度的關系是時空興趣點方法的重點之一。上述方法易受遮擋和相機視角變化的干擾,所以提出了基于骨骼和關節軌跡的動作表示方法,用于分析人體的局部運動信息。該方法從RGB圖像中提取骨骼關鍵點或者跟蹤人體骨骼運動的軌跡,根據關鍵點和軌跡判斷動作的類別。該方法的關鍵在于使用何種算法和模型從RGB圖像中提取關鍵點或者軌跡。Gaidon等人(2014)基于分裂聚類法表示局部運動軌跡,計算軌跡特征并用聚類結果表示不同運動類別。Wang和Schmid(2013)借鑒興趣點密集采樣的思想,通過采集密集點云和光流法跟蹤特征點,獲取密集軌跡(iDT),然后計算位移信息進行識別。RGB模態的骨骼和關節軌跡方法仍然存在背景和遮擋的干擾。但是識別動作的準確性提高,促使之后的科研人員依靠傳感器采集骨骼模態形成數據集,從骨骼模態的角度研究行為識別。
2.2 基于深度學習的方法
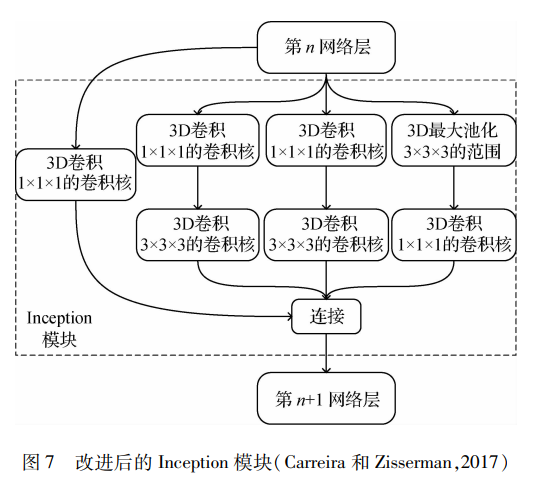
深度學習的崛起逐漸影響了行為識別領域。基于深度學習網絡提取的高層次特征,信息量豐富、有區分性,優于傳統手工特征,應用于行為識別領域取得了重大的突破。在2D-CNN的基礎上,Carreira和Zisserman(2017)提出了一種I3D模型,將卷積從2維擴展到3維,并提出了雙流3D卷積網絡用于動作識別,雙流網絡也成為后人模仿借鑒的經典方法。圖 7為I3D中改進后的Inception模塊,其中大小為1的3D卷積作用為減少參數量,尺寸都為3的最大池化和3D卷積提取不同尺度的特征,同時殘差連接輸入與輸出,保持模型的穩定性。同時Carreira和Zisserman(2017)提出了Kinetics數據集,將許多經典算法在此數據集上進行實驗對比,分析各算法的優缺點。Zhu等人(2018)提出了一種名為隱式雙流神經網絡結構的CNN體系結構,將原始視頻幀作為輸入并直接預測動作類別,通過隱式捕獲相鄰幀之間的運動信息,使用端到端的方法解決了需要計算光流的問題。研究者通過改進卷積網絡的模塊和深度,行為識別的準確率大幅提升。雖然加深網絡能更有效地提取特征,但網絡也會變得臃腫和訓練緩慢。為了保證時空流之間的可分辨性和探索互補信息,Zhang等人(2019)提出了一種新穎的協同跨流網絡,該網絡調查多種不同模式中的聯合信息,通過端到端的學習方式提取共同空間和時間流的網絡特征,探索出不同流特征之間的相關性,從中提取不同模態的互補信息。神經網絡方便了特征提取的方法,但不能拘泥于網絡深度等方面,更應該從多個角度(幀選擇和跨流網絡的想法)優化識別過程。為了解決光流的計算復雜度問題,Kwon等人(2020)用運動特征的內部信息和輕量級學習代替對光流的繁重計算,提出了一種名為MotionSqueeze的可訓練神經模塊,用于有效的運動特征提取。該模塊即插即用,能插入任何神經網絡的中間來學習幀間關系,并將其轉換為運動特征,然后送到下一個網絡層進行更好的預測。
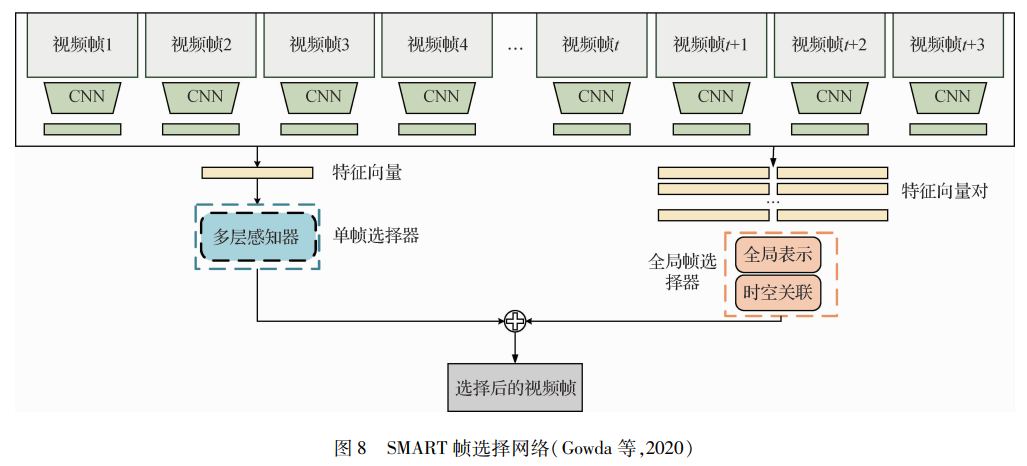
學者的創新曾經局限在提取特征的技術,Gowda等人(2020)從幀選擇的角度出發,保留行為特征在時間序列上區別明顯的“好”幀,剔除特征類似和無法分類的幀,提出一種名為SMART的智能幀選擇網絡,如圖 8所示,綜合考慮單個幀和多個幀的質量,而不是一次僅考慮一個幀。在降低計算量的同時,提高了識別準確率。Qiu等人(2019)注意到視頻是具有復雜時間變化的信息密集型媒體,而神經網絡中的卷積濾波器都是局部操作,忽略了視頻幀之間的相關性,提出了一種新的基于局部和全局擴散的時空表示學習框架,并行學習局部和全局表示。每個塊建模這兩種表示方式,并且兩者之間交換信息來更新局部和全局特征,多個塊組成此網絡結構,有效地保持了信息的局部性和整體性,獲得了強大的特征學習方式。這些行為識別技術的革新都是在其他研究的基礎上,保留優點,減弱負面影響或者解決存在的問題,最終實現行為識別技術的突破。
03 基于深度數據的行為識別方法
RGB數據受干擾性較大,促使了深度數據的產生。深度圖中的紋理和顏色信息少,將圖像采集器到場景中各點的距離(深度)作為像素值,對光照的魯棒性強。深度傳感器的產生極大地擴展了計算機系統感知3D視覺世界和獲取視覺信息的能力。深度數據的信息與RGB數據本質上不同,它對場景的距離信息進行編碼,而不是對顏色強度進行編碼。因此,深度數據可以更簡單精確地獲取關鍵區域。但深度信息也不是一直具有魯棒性,遮擋物和閃爍噪聲可能會對行為識別造成誤差。
3.1 基于運動變化和外觀信息的方法
基于深度數據的行為識別方法主要利用人體深度圖中的運動變化來描述動作。動作的特征由深度變化的外觀或運動信息進行描述。Yang等人(2012)通過深度運動圖(DMM)來投影和壓縮時空深度結構,再從正面,側面和俯視圖形成3個運動歷史圖。然后,利用HOG特征表示這些運動歷史圖,并將生成的HOG特征串聯起來以描述動作。除了計算運動變化來描述動作的方法外,另一種流行的方法是通過外觀信息來描述動作。Yang等人(2012)基于深度序列構造一個超向量特征來表示動作,通過連接來自深度視頻的局部相鄰超曲面法線來擴展HON4D,聯合局部形狀和運動信息,引入了一種自適應時空金字塔,將深度視頻細分為一組時空單元,以獲得更具鑒別力的特征。為了剔除噪聲影響,Xia和Aggarwal(2013)提出了一種新的深度長方體相似性特征,用來描述具有自適應支撐尺寸的3維深度長方體,從而獲得更可靠的時空興趣點。Chen和Guo(2015)通過分析前、側和上方向的時空結構,提取時空興趣點的運動軌跡形狀和邊界直方圖特征,以及每個視圖中的密集樣本點和關節點來描述動作。深度模態較RGB模態多了深度這一信息,因此如何充分利用深度相關信息,如大小、變化等,是基于深度模態的行為識別的關鍵。這一思想不但適用于手工特征法,也適用于深度學習法。
3.2 基于深度學習的方法
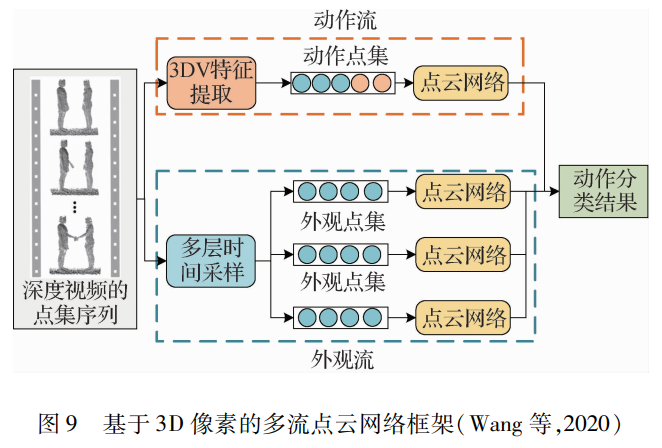
深度模態下基于深度學習的方法可分為兩類:一類是深度特征圖和卷積神經網絡的結合;另一類是提取深度信息的點集與點云網絡的結合。為了充分利用深度序列中的空間、時間和結構信息進行不同時間尺度的動作識別,Wang等人(2018a)提出了3種簡單、緊湊而有效的深度序列表示方法,分別稱為動態深度圖像(DDI)、動態深度法線圖像(DDNI)和動態深度運動法線圖像(DDMNI),用于孤立和連續動作識別。其中,DDI記錄了隨時間變化的動態姿勢,DDNI和DDMNI記錄了深度圖捕獲的3維結構信息。然后將3種特征圖輸入神經網絡,提取不同的特征。Trelinski和Kwolek(2019)提出了一種基于深度圖序列的動作識別算法。首先,在單個深度圖中提取描述人形的特征,然后,對每個類單獨訓練提取單個類的特征,同時對每個深度圖中代表人形的像素計算手工的特征。最后,所有動作共用的手工特征和特定動作的特征連接在一起,形成動作特征向量。深度圖和點云可以相互轉換,并且點云的表示簡單,有非常統一的結構,避免組合的不規則性和復雜性。因此,Wang等人(2020)提出了3維動態像素(3DV)作為新穎的3維運動表示。通過時間順序池化將深度視頻中的3維運動信息壓縮成規則的3DV像素點集,每個可用的3DV像素本質上涉及3維空間和運動功能,然后將3DV抽象為一個點集。由于3維點集的不規則,常規的卷積神經網絡不適合處理不規則的信息形狀,將點集輸入點云網絡(PointNet++),保持了點集的置換不變形。如圖 9所示,動作流提取3D像素表示的人體動作特征,外觀流提取人體的外觀特征,結合兩個特征的信息進行行為識別。Wang等人(2015)將卷積網絡與深度圖結合起來,通過卷積網絡來學習深度圖像序列的動作特征。利用分層深度運動映射(HDMMs)來提取人體的形狀和運動信息,然后在HDMMs上訓練一個卷積神經網絡進行人體動作識別。在此基礎上,Liu和Xu(2021)設計一個端到端的幾何運動網絡(GeometryMotion-Net),分別利用點云網絡提取運動特征和幾何特征,而3DV PointNet不能進行端到端的訓練。3DV PointNet并沒有充分考慮時間信息,而GeometryMotion-Net將每個點云序列表示為一個虛擬整體幾何點云和多個虛擬運動點云來明確時間信息。兩項改進措施使得識別準確率有了較大提升。
04 基于骨骼數據的行為識別方法
該方法通過骨骼關節實時對3D人體關節位置進行編碼,實現人體行為的動作識別。由于人體骨骼的運動可以區分許多動作,利用骨骼數據進行動作識別是一個有前景的方向。骨骼數據包含的時空信息豐富,關節節點與其相鄰節點之間存在著很強的相關性,使得骨架數據不但能在同一幀中發現豐富的人體結構信息,幀與幀之間也存在著強相關性。同時考慮骨骼和幀序列、時域和空域之間的共現關系能準確地描述動作。
4.1 基于骨骼特征提取的方法
對現有的基于骨骼數據的特征提取方法進行分析,根據其所對應的識別位置可分為基于關節和基于身體部位的行為識別方法。Vemulapalli等人(2014)提出了一種新的骨骼表示法,利用3維空間中的旋轉和平移來模擬身體各個部位之間的3維幾何關系。人體骨骼作為李群中的一點,人的行為可以被建模為這個李群中的曲線,將李群中的動作曲線映射到它的李代數上,形成一個向量空間。然后結合線性支持向量機進行分類。Koniusz等人(2016)使用張量表示來捕捉3維人體關節之間的高階關系,用于動作識別,該方法采用兩種不同的核,稱為序列相容核和動態相容核。前者捕捉關節的時空相容性,后者則模擬序列的動作動力學。然后在這些核的線性化特征映射上訓練支持向量機進行動作分類。
4.2 基于深度學習的方法
Liu等人(2016)通過對骨架序列進行樹結構的遍歷,獲得了空間域的隱藏關系。其他方法進行關節遍歷只是把骨架作為一條鏈,忽略了相鄰關節之間存在的依賴關系,而此遍歷方法不會增加虛假連接。同時使用帶信任門的長短期記憶網絡(LSTM)對輸入進行判別,通過潛在的空間信息來更新存儲單元。Caetano等人(2019)提出了一種基于運動信息的新表示,稱為SkeleMotion。它通過計算骨骼關節的大小和方向值來編碼形成每行的動作信息和每列的描述時間信息,形成調整后的骨骼圖像。然而,人類3維骨骼數據是一個拓撲圖,而不是基于RNN或CNN的方法處理的序列向量或偽圖像,而圖卷積網絡(GCN)具有天生處理圖結構的優勢,使得它在基于骨骼的行為識別技術取得了重大突破。基于圖卷積的行為識別技術關鍵在于骨骼的表示,即如何將原始數據組織成拓撲圖。Yan等人(2018)首先提出了一種新的基于骨架的動作識別模型,即時空圖卷積網絡(ST-GCN),該網絡首先將人的關節作為時空圖的頂點,將人體物理關節連接和時間作為圖的邊;然后使用ST-GCN網絡進行信息的傳遞匯集,獲取高級的特征圖,并用Softmax分類器劃分為對應的類別。在此基礎上,Li等人(2019)提出的AS-GCN不僅可以識別人的動作,而且可以利用多任務學習策略輸出對物體下一個可能姿勢的預測。
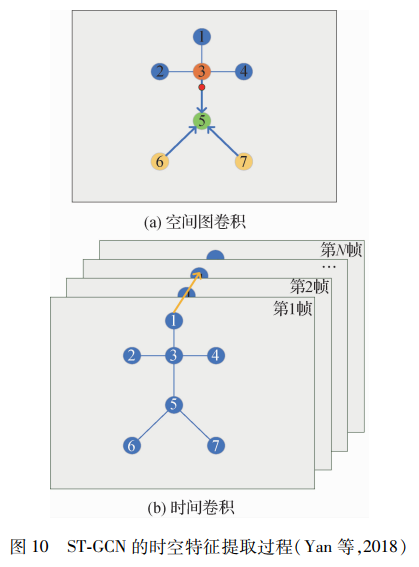
構造的拓撲圖通過動作連接和結構連接的兩個模塊來捕捉關節之間更豐富的相關性。Shi等人(2020)提出了一種新的多流注意增強自適應圖卷積神經網絡來進行基于骨架的動作識別。模型中的圖拓撲可以基于輸入數據以端到端的方式統一或單獨地學習。這種數據驅動的方法增加了圖形構造模型的靈活性,使其更具有通用性,以適應各種數據樣本。同時關節差值和幀間差值的數據構造多流網絡,在決策階段融合,實現識別率的進一步提升。Obinata和Yamamoto (2021)從另一角度注意到幀間的拓撲圖,不僅僅在幀間同一關節對應的頂點之間進行連接,在幀間多個相鄰頂點之間添加連接,并提取額外的特征,實現識別率的提高。改進拓撲圖后的識別效果理想,使得后續的許多研究都著重于這一點,如設計動態可訓練拓撲圖(Ye等,2020)、各通道獨享的拓撲圖(Cheng等,2020a)以及結合全局和局部的拓撲圖(Chen等,2021a)。如圖 10所示,空間圖卷積過程是離重心(3號下方的最小點)近的3號近心點和離重心遠的6號和7號遠心點通過骨骼連接向5號根節點傳遞信息,如此反復,獲得提取空間特征;時間卷積是將同一關節在時間維度上進行信息匯集,即同一關節的部分幀序列進行信息匯集,得到時間特征。骨架序列的時空圖表示是圖卷積網絡(GCN)的擴展,專門用于執行人類行為識別。首先,通過在人體骨架的相鄰身體關節之間以及沿時間方向插入邊來構造時空圖。然后,應用GCN和分類器來推斷圖中的依賴關系并進行分類。
圖卷積作為基于骨骼數據的行為識別的熱點研究之一,其數據形式——拓撲圖十分契合人體骨骼圖,特征和信息的獲取與傳遞在物理結構和語義層面都符合圖結構,因此取得了較為理想的效果。但圖結構也成為行為識別的限制,如坐標的分布會影響圖卷積的魯棒性,缺失一些重要的關節點會降低識別的效果。另外,圖卷積將每個關節點視為圖中的一個點,其復雜性和人數成正比,而現實中的許多動作涉及多人以及相關物體。成倍增加的計算消耗量使得圖卷積難以在多人動作的任務上實現較好的應用。
05 基于數據融合的行為識別方法
RGB數據、深度數據和骨骼數據具有各自的優點。RGB數據的優點是外觀信息豐富,深度數據的優點是不易受光照影響,骨骼數據的優點是通過關節能更準確地描述動作。所以,選擇哪種模態進行行為識別也是研究人員權衡的方面之一。根據匯集的文獻資料,本文總結了各類模態的特點和適用場景,如表 2所示。

由于單模態始終存在一些問題,研究者嘗試使用多種方式進行特征融合,克服這些問題。
融合方式有3種:特征層融合、決策層融合和混合融合。不同的方式融合結果具有各自的優點,彌補缺點,得到對運動的動作有更好的描述。
5.1 基于RGB模態與深度模態的融合方法
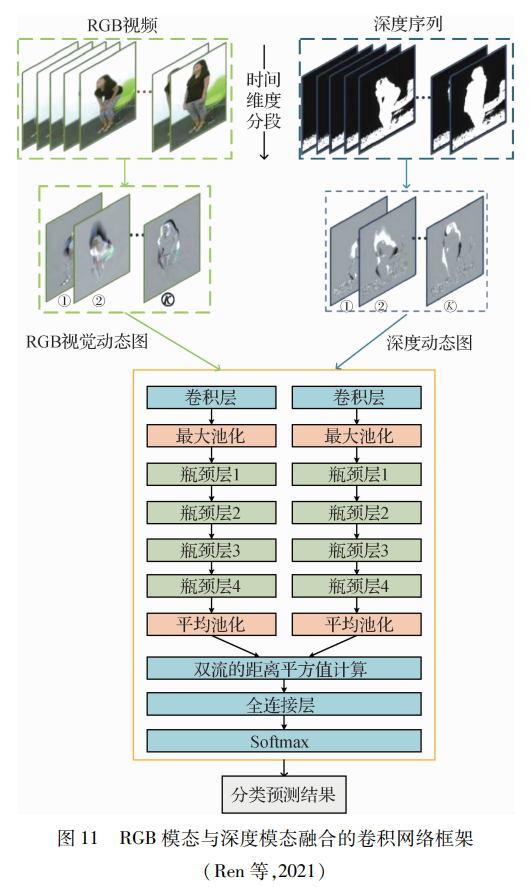
根據模態產生的時間順序,RGB模態與深度模態的融合是最先提出也是最為普遍的組合方式。Jalal等人(2017)從連續的深度圖序列中分割人體深度輪廓,并提取4個骨骼關節特征和一個體形特征形成時空多融合特征,利用多融合特征的編碼向量進行模型訓練。Yu等人(2020)使用卷積神經網絡分別訓練多模態數據,并在適當位置進行RGB和深度特征的實時融合,通過局部混合的合成獲得更具代表性的特征序列,提高了相似行為的識別性能。同時引入了一種改進的注意機制,實時分配不同的權值來分別關注每一幀。Ren等人(2021)設計了一個分段協作的卷積網絡SC-ConvNets)來學習RGB-D模式的互補特征,整個網絡框架如圖 11所示。首先將整個RGB和深度數據序列壓縮成動態圖像分別輸入雙流卷積網絡中,再計算距離的平方值獲得融合的特征。與先前基于卷積網絡的多通道特征學習方法不同,這個分段協作的網絡能夠聯合學習,通過優化單個損失函數,縮小了RGB和深度模態之間的差異, 進而提高了識別性能。
深度模態沒有RGB模態的紋理和顏色信息,RGB模態比深度模態在空間上少一個深度信息的維度,因此兩者的數據模態可以很好地互補對方缺失的特征信息。大量研究結果表明了此種融合方法的合理性和優越性。因此提取另一個模態缺少的信息,避免相同信息的冗余,是模態融合的重點和難點。
5.2 其他模態的融合方法
其他模態的關系,如骨骼模態與深度模態互補關系,稍弱于RGB和深度模態的互補關系。但不同模態仍有互補信息的存在,所以不同模態融合也是研究人員的研究方向之一。Elmadany等人(2018)使用規范相關分析(CCA)來最大化從不同傳感器提取的特征的相關性。此論文研究的特征包括從骨架數據中提取的角度數據、從深度視頻中提取的深度運動圖和從RGB視頻提取的光流數據,通過學習這些特征共享的子空間,再使用平均池化來獲取最終的特征描述符。Rahmani等人(2014)提出一種稱為深度梯度直方圖的描述子,結合深度圖像和3維關節位置提取的4種局部特征來處理局部遮擋,分別計算深度、深度導數和關節位置差的直方圖,將每個關節運動量的變化并入全局特征向量中,形成時空特征,并使用兩個隨機決策森林,一個用于特征修剪,另一個用于分類,提高識別的精度。特征可以在初級階段融合,也可以在高級階段形成語義信息的時期融合。前者相當于對數據進行補充增廣,后者形成新的語義信息。融合也可以發生在決策階段,聯合不同模態的預測結果后得到一個綜合的預測結果。一般而言,越早期的模態融合需要的計算量越小,越后期的模態融合復雜度越大。研究者常常使用混合折中的方法,保持兩者優勢的同時,也克服了一些缺點。融合的具體方式及其優缺點如表 3所示。對于神經網絡,不同模態的融合可以在特征提取階段,可以將多流網絡的輸出匯集到單個網絡中實現特征融合。融合的關鍵在于數據模態的選擇和融合的時間。研究者需要思考一種模態融入另一種模態后的特征是否克服了原有模態的缺點,否則融合操作只會增加計算量。

06 行為識別方法對比
對不同數據模態下的行為識別方法進行比較,通過表格和柱狀圖等方式的對比,以期得出一些行為識別技術的結論。Top-1代表概率最大的結果是正確答案的準確率,Top-5代表概率排名前5的結果是正確答案的準確率。交叉主題(cross subject)和交叉視角(cross view)是NTU RGB+D 60數據集中訓練集和測試集的劃分。交叉主題將40個志愿者劃分為訓練和測試兩個隊伍。每個隊伍包含20個志愿者,其中1,2,4,5,8,9,13,14,15,16,17,18,19,25,27,28,31,34,35,38為訓練集,其余為測試集。交叉視角將3個視角的相機中,相機2號和3號作為訓練集,相機1號為測試集。NTU RGB+D 120中的訓練集和測試集劃分方式包括交叉主題(cross subject)和交叉設置(cross setup)兩種。交叉主題表示訓練集包含53個主題,測試集包含另外53個主題。交叉設置表示訓練集樣本來自偶數編號,測試集樣本來自奇數編號。6.1 RGB模態的方法對比
RGB模態數據集選取了經典的UCF101數據集和HMDB-51數據集,以及新穎的Something-Something數據集,對比了經典方法和新發表的效果最佳的方法,如表4和表5所示。
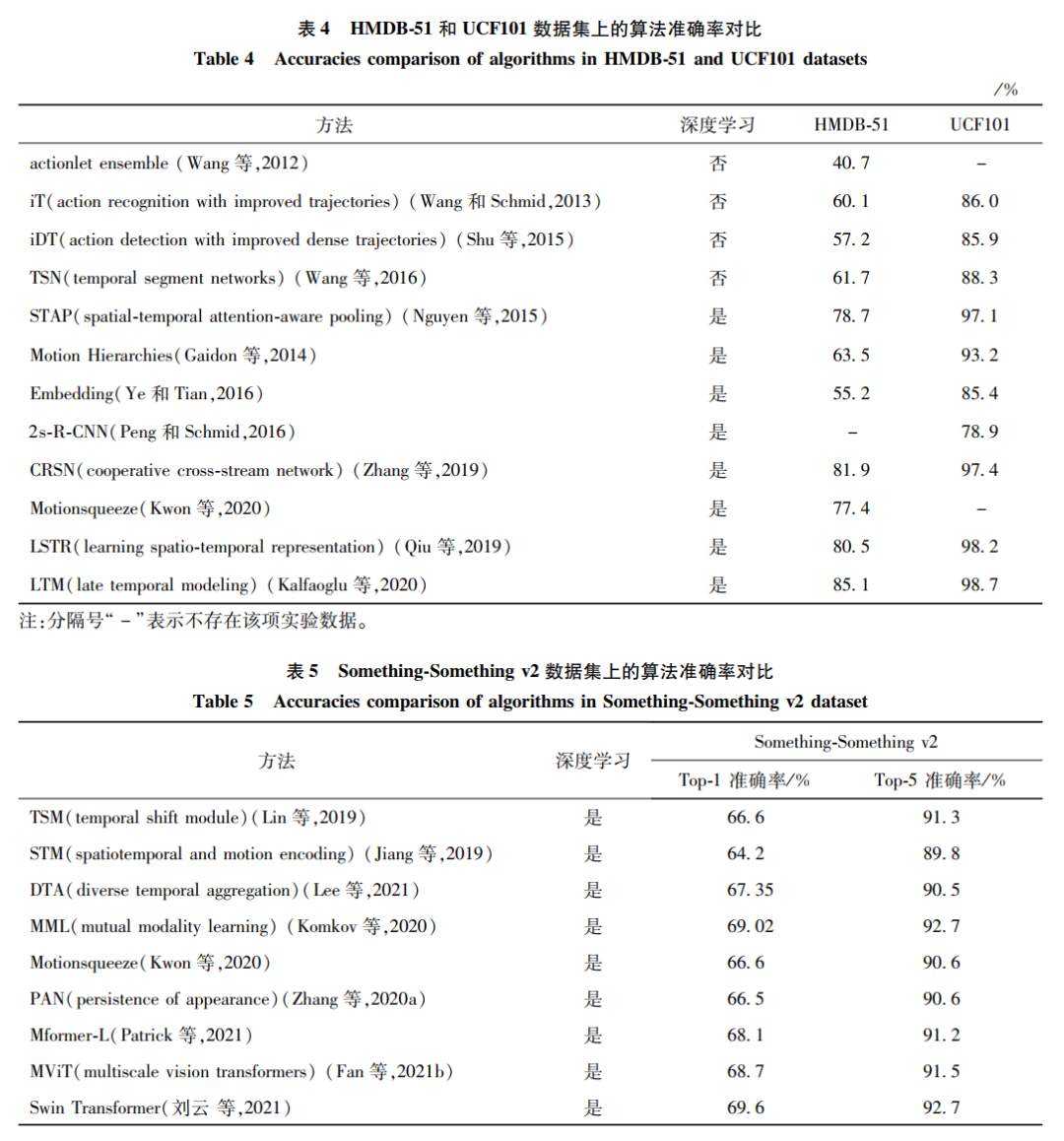
對于HMDB-51數據集,手工特征方法的準確率最高僅有61.7%,而深度學習方法的最低準確率是55.2%。基于深度學習的方法將該數據集的最高準確率提高到85.1%。對于UCF101數據集,手工特征方法的最高準確率88.3%,基于深度學習的方法將準確率提高到98.7%,已經基本符合應用的要求。在Something-Something數據集上,手工特征法鮮有研究,大都是基于深度學習方法的開展。原因是該數據集規模較大,手工制作的特征已經無法準確地描述動作。而且動作類別多,使得Top-1的最高識別率僅有69%,是RGB模態的行為識別方向下一個需要攻克的數據集。根據大量文獻和實驗的依據,本文總結了兩類方法的優缺點如表 6所示。

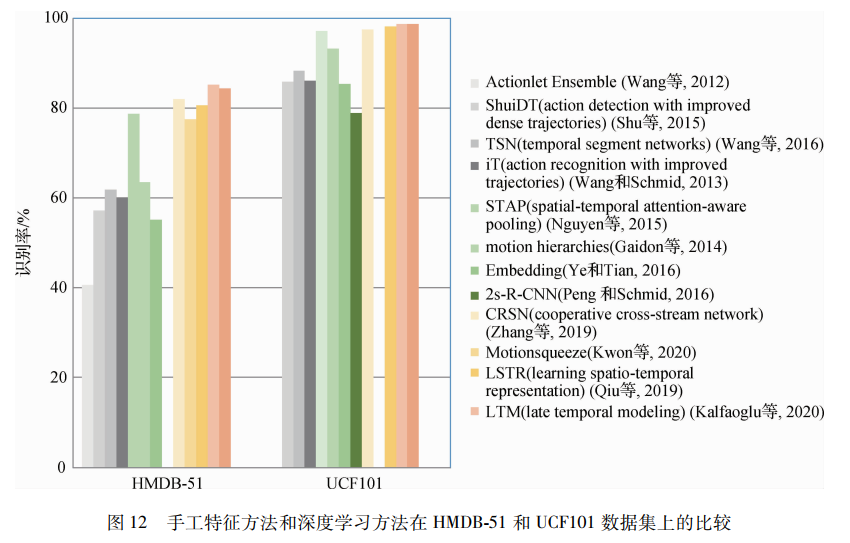
本文將統計的數據繪制成柱狀圖,從圖12中能明顯觀察出,基于手工特征的方法(灰色表示的柱狀)基本低于深度學習方法的識別率(灰色以外的其他顏色),說明深度學習的方法一般具有更好的識別性能。類似的情況也發生在其他模態中。
6.2 深度模態的方法對比深度模態數據集選取了經典的MSR-Action3D數據集與當前主流的NTU RGB+D深度數據集,和RGB模態的實驗思路相同,比較了經典算法和最新卓越方法,結果如表 7和表 8所示。
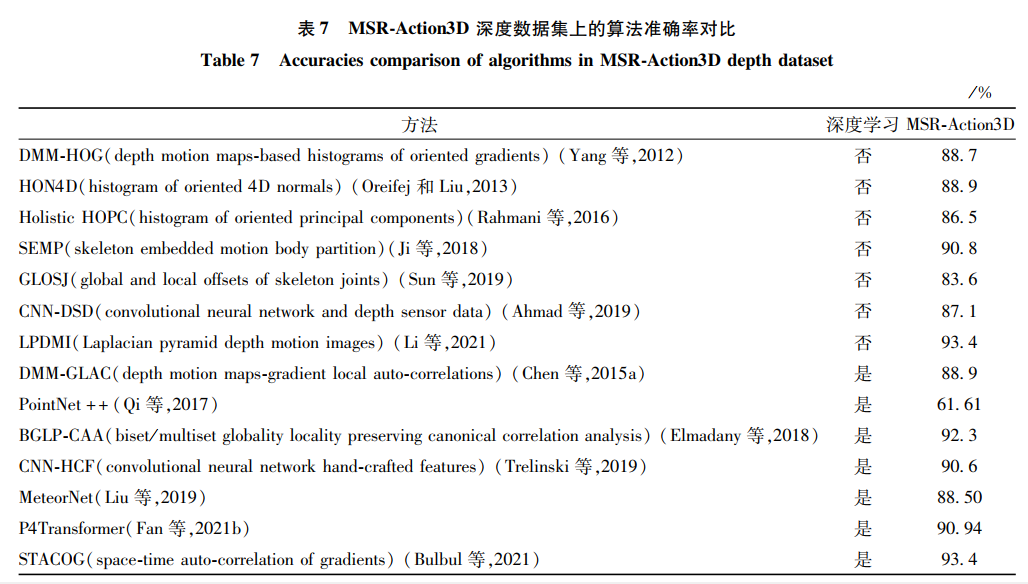
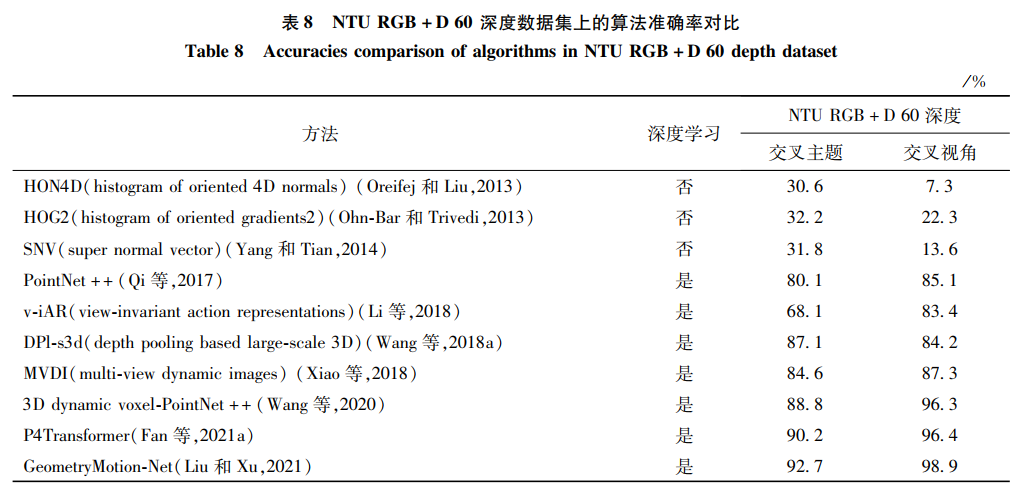
當前的多數方法已經在MSR-Action3D深度數據集上達到了90%的準確率,說明該數據集的大部分價值已被挖掘,但MSR-Action3D仍然是評價一個算法好壞的經典數據集之一。近期主流的數據集是NTU RGB+D數據集中的深度模態部分,深度數據模態的人體行為數據集相較其他兩個模態發布較少,在這方面還有很大的進步空間。在NTU RGB+D數據集的深度模態部分,手工特征的方法在這個大型數據集上效果較差。原因與RGB模態的情況相似,該數據集規模大、樣本多、類別多,手工制作的特征能表示部分動作信息,但難以覆蓋整個數據集的動作范圍。兩個新發布的網絡的變體:點云網絡(PointNet++)和Transformer網絡,在NTU RGB+D深度模態部分的識別率達到了近90%和90.2%的高度。研究者可以從不同的角度改進這兩個網絡,可能會達到新的性能高度。這也給了研究者另一種想法,通過移植或者改進領域外的新穎網絡,適配到行為識別方向中,或許能取得意想不到的效果。
6.3 骨骼模態的方法對比
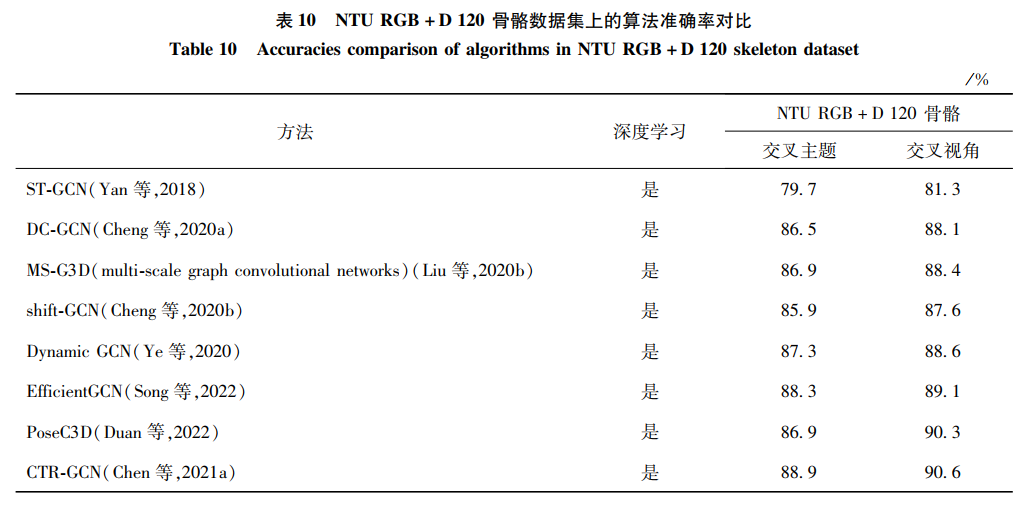
骨骼模態是近年越發流行的模態,本文選取了主流的NTU RGB+D skeleton骨骼數據集,對比了許多算法的差異。在NTU RGB+D 60和120數據集的實驗設置下,手工特征和深度學習的方法對比如表 9和表 10所示。深度學習的方法全面超越了手工特征方法。從中可發現,基于深度學習的方法幾乎占據了全部范圍。其中,早期研究者多使用標準卷積網絡將骨骼數據編碼成像素排列的偽圖像,借鑒圖像分類和視頻分類的思想提取特征。這種方式取得的效果并不理想,因為它割裂了骨骼內在的連接性。之后,提出了卷積網絡的變體——圖卷積。由于圖的結構十分符合人體骨骼連接,取得了理想的效果,也促進了圖卷積在行為識別領域中快速發展。本文發現,初期研究者往往僅考慮識別率的高低,忽略了算法和模型的復雜度。
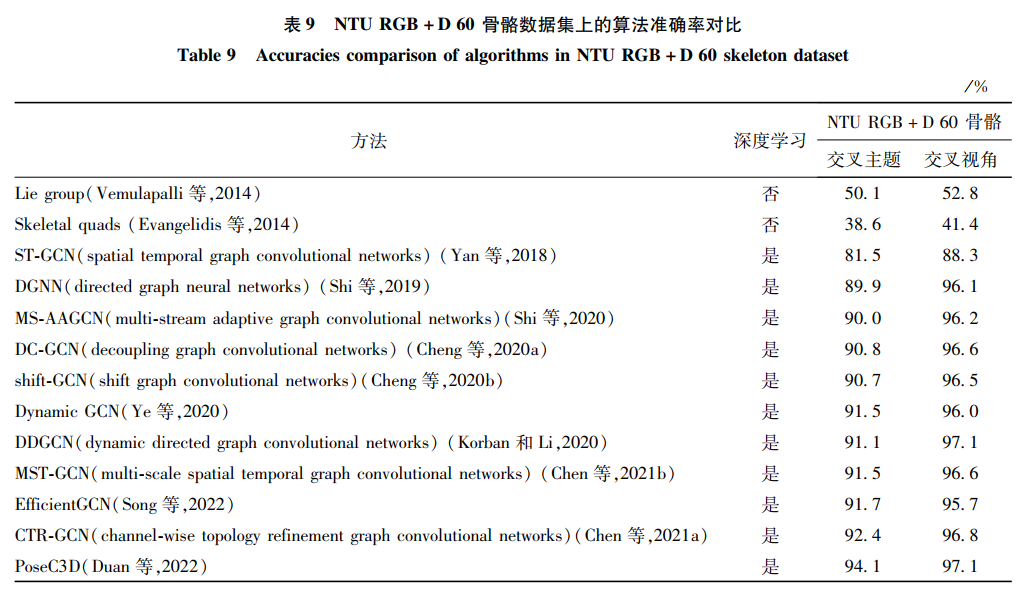
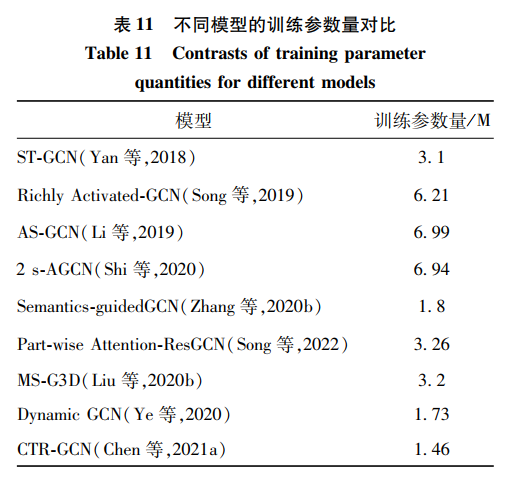
統計在骨骼模態上相關模型的訓練參數量后如表 11所示。以ST-GCN為基礎,科研人員通過加深模型層次和改進模型結構,設計出AS-GCN、2S-GCN等優秀模型。雖然提高了識別性能,但是模型越來越龐大,識別率也達到了瓶頸。意識到這一問題后,研究人員開始設計更輕量的網絡,如MS-G3D、Dynamic GCN、CTR-GCN等。在達到相同識別效果的同時,設計了復雜度更小、訓練速度更快的網絡。從模型優化的角度進一步發展了行為識別技術。
圖卷積的應用將NTU RGB+D 60骨骼數據庫的交叉識別率從50%快速提升至88%。經過科研人員的不斷努力研究,目前交叉主題和交叉視角的最高識別率已經達到94.1%和97.1%。在NTU RGB+D 60數據集上已經基本完成行為識別的任務。在NTU RGB+D 120數據集,動作類別數更多,更加有挑戰性和難度。目前的最高識別率只有90%左右。所以,NTU RGB+D 120數據集是目前最全面和權威評價一個算法和模型好壞的數據集。希望相關人員能首先考慮以該數據集作為基準,通過數據驅動行為識別的進一步發展。本文發現,越高的識別率增長的幅度越小。這也從側面反映了圖卷積在行為識別領域達到了一定的瓶頸期。從本文數據模態的角度出發,有以下兩點建議:1)融合其他模態的數據,補充骨骼數據的信息,進而獲得更好的結果。2)使用一種新的方式代替拓撲圖表示骨骼的信息,便于提取更多的動作特征。
6.4 多模態融合的方法對比
NTU RGB+D包括了RGB、深度和骨骼模態,選擇該數據集作為基準對比不同的算法,結果如表 12所示。
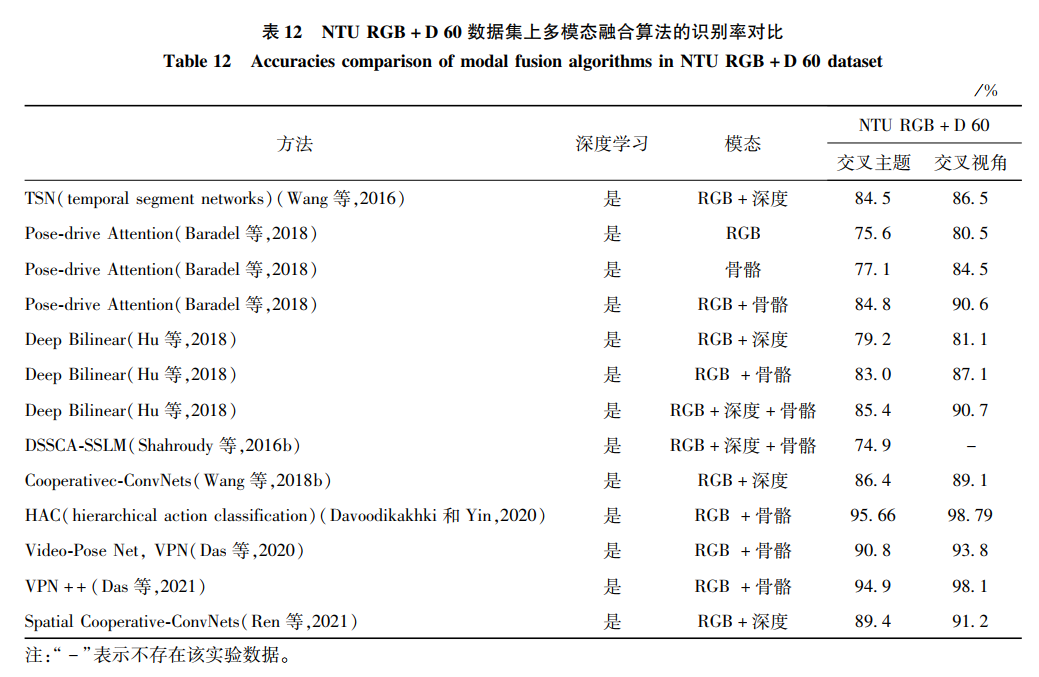
選取其中的兩個方法Pose-drive Attention和Deep Bilinear作為代表,比較其在不同模態下的識別率。從表 13中可以清楚地觀察到,對于Pose-drive Attention模型,RGB和骨骼模態融合的識別率明顯高于RGB或者骨骼單個模態的識別率。對于Deep Bilinear模型,3個模態融合后的識別率高于兩個模態融合的識別率。因此,融合多個模態的方法十分有利于行為識別的效果提升。
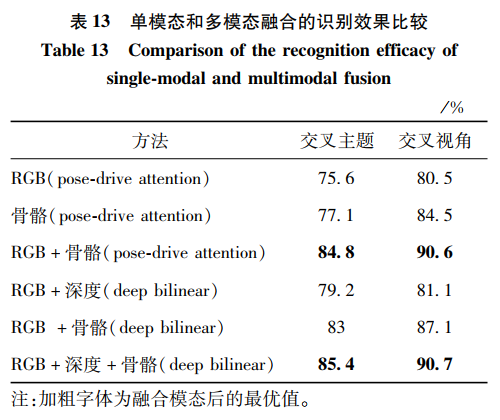
最常用的組合是RGB模態和深度模態,原因是由于深度模態比RGB模態多了深度信息,而RGB模態比深度模態多了顏色紋理信息,兩者能較好地互補信息,從而提取到描述更好的特征,達到提高識別率的效果。其次是骨骼和其他模態的組合,由于骨骼數據在早期較難與其他模態融合,研究者一般都選擇在高維特征階段進行融合,實現信息的互補。最后,本文從各類模態內部比較和各類模態之間比較發現了一些規律和特點。骨骼模態數據和RGB模態數據是人體行為識別中使用較多的模態。在各類模態下,深度學習的方法一般都優于手工特征的方法,這是因為深度學習提取的特征基于數據集本身的數據信息,相較于手工特征,深度學習獲得的特征更加準確地描述了動作。通過融合不同數據模態的特征或者決策層融合,實現信息互補,達到更優異的效果。
07 結語
目前,行為識別在一些數據集上的識別率已經很高,在日常生活中也有一些應用。但是行為識別仍然存在許多挑戰。1)數據集的規模越來越大,環境越來越復雜,愈發符合現實場景。物體遮擋、視頻的像素值和幀數、交互運動以及圖像的多尺寸等因素,都會極大地影響識別過程。2)盡管目前有許多模態的數據,但并非所有模態的數據都易采集。RGB模態是能夠利用一般相機直接獲得,深度模態需要深度傳感器(如Kinect相機)獲得,而骨骼模態是從前兩者模態中抽象得到的一種描述人體行為的模態數據。3)特殊動作的識別包括相似動作的識別、多人動作的識別以及高速動作的識別。對于這些挑戰,研究者還需不斷探索,尋找解決問題的方案。本文總結了一些行為識別領域在未來可行的研究方向:1)多模態融合是一個具有前景的研究方向。無論是在特征層的特征融合,或者在預測階段的決策融合,都已經被證明是一個可行的方案。除了上述所提的主流模態外,一些模態(如紅外線、聲音)等信息也能夠融合其中,實現信息補充,提高識別性能。2)深度學習網絡已經成為主流,符合數據集規模增加的趨勢。手工制作的特征并非完全舍棄。研究人員依然可以借鑒制作特征的思想,從視頻中提取去除無關信息的手工特征后再輸入深度學習的網絡中,減少了網絡參數,也提高了識別效果。3)設計和移植新型網絡,增加注意力模塊。自從2D卷積神經網絡應用在行為識別領域,識別效果大幅提升。然后,3D卷積神經網絡、圖卷積網絡的應用使識別效果又提升了一個層次。所以,設計新型的網絡或者移植其他領域的網絡是有參考價值的。同時,注意力模塊在網絡中愈發廣泛應用。注意力模塊能夠較好地去除時間和空間特征中的無關信息,將重點放在顯著區域,進而提升識別準確率。本文從多模態的角度對行為識別的研究進行了綜述,整理了主流的數據集,全面分析了各類模態的行為識別方法,重點分析了特征的設計和網絡的結構,最后對比不同算法或網絡的效果,總結出一些存在的問題和未來可行的方向。本文的分類結構希望能給初學者提供一個完整的行為識別領域的知識,使相關研究人員能從中獲得一些創新的思路和啟發。
編輯:黃飛











 工商網監
工商網監
評論