 電子發燒友App
電子發燒友App


? ?日志結構存儲在當今存儲系統中被廣泛使用,然而其中的垃圾回收會將有效數據重新寫入導致寫放大現象。現有最佳的數據放置策略是通過知道未來每個塊的無效時間進行數據放置,然而無法在現實中實現。本篇工作提出一個新型的數據放置策略SepBIT,通過推測每個塊的無效時間,來將無效時間相似的塊放在一起,從而減少寫放大并提高了I/O帶寬。SepBIT目前已經被部署在了阿里云上。
01?背景
? ? 在基于日志結構存儲中,數據被分為很多個段,而段中含有很多個塊。當向其中寫入數據時,會以塊的粒度進行追加。當其中的數據進行更新的時候,也將會通過往后追加塊的方式寫入數據來實現異地更新。當一個段中數據寫滿的時候,數據將會寫到下一個段中。由于采用了異地更新,因此當存儲中的段都寫滿的時候,需要選擇其中一個段,將其中的有效數據重新寫入并進行擦除,通過這個方式來回收無效數據所占用的空間,這個過程就叫做垃圾回收(GC)。在這個過程中重新寫入的有效頁就是造成寫放大的原因。為了降低寫放大,現在最優的數據放置策略是通過預先知道所有數據的失效信息,從而將失效時間相似的數據放到一起。然而這個策略在現實中無法實現,這是因為1. 需要預先知道所有數據的失效時間是無法做到的;2. 同時需要維護很多可供寫入的段地址,因此會帶來很高的內存和存儲開銷。同時此時的隨機寫會帶來性能下降。
02?動機
? ? 本文根據對阿里云和騰訊云真實負載的分析,探索其中有關于數據無效時間的發現。本文中的數據無效時間(壽命)定義為在兩次數據寫入中寫入的數據量。其中選取了騰訊云的4995個負載,以及從阿里云1000個負載中篩選的186個以寫為主的負載。本文得到了3個發現:
1. 用戶寫入的數據通常壽命較短。
據統計,超過一半的負載中超過79.5%的數據壽命低于負載集大小的80%,同時47.6%的數據壽命低于負載集大小的10%。其中負載集大小的定義為數據邏輯地址的范圍。而通過GC重新寫入的數據往往壽命較長。
2. 頻繁更新的數據之間壽命差異較大。
發現2中統計了每個負載中更新頻率最高的20%的數據,并分為四個區間1%,1-5%,5-10%和10-20%。據統計,有25%的負載中四個區間的變異系數(CV)分別為4.34,3.20,2.14和1.82,即他們之間壽命的差異性較大。其中變異系數的定義為(標準差/平均值)。這個發現也論證了現在有些根據數據更新頻繁程度進行數據放置的策略并不能夠很好的將具有相似失效時間的數據放到一起。
3. 很少更新的數據占主流,并且其中壽命的差距也很大。
發現3中將很少更新的數據定義為更新次數小于4次的數據。據統計,超過一半的負載中有超過72.4%的數據很少被更新。同時將很少更新數據通過無效時間劃分為五個區間,小于0.5倍的負載集大小,0.5-1倍的負載集大小,1-1.5倍的負載集大小,1.5-2倍的負載集大小和大于2倍的負載集大小。據統計其中25%的工作負載中,超過71.5%的數據的壽命低于0.5倍的負載集大小。位于其余四個區間壽命數據量的均值為24.9%,8.1%,3.3%和2.2%。這就表示對于很少更新的數據,他們之間的壽命差異也較大。同樣證明了以數據更新頻繁度進行數據放置策略并不是十分有效的。
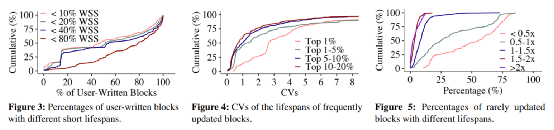
圖1:SepBIT的三個發現
03?SepBIT設計
????SepBIT是一個推測數據的無效時間來對數據進行放置的策略。根據發現1,SepBIT首先將數據分為用戶數據和GC寫入數據,因為它們之間的壽命差異較大。SepBIT將段分為六類,其中1類和2類用于分別存放壽命短和壽命長的用戶數據,3類-6類用于存放GC寫入的數據。其中3類存放的是通過GC寫入的1類中的數據,而4-6類則存放的是通過GC寫入的2類中的數據。
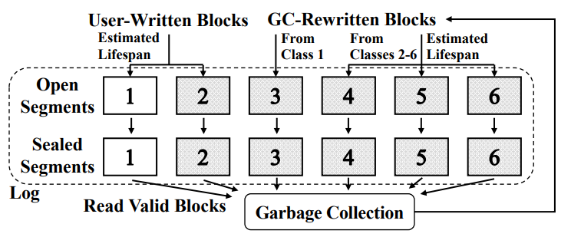
圖2:SepBIT工作流程圖
??? SepBIT通過對用戶數據上一次寫入與這一次寫入之間的壽命,來推測這一次數據寫入到下一次數據寫入的壽命。同時通過對GC重寫入數據與上一次用戶寫入數據的壽命,來推測下一次用戶寫入與這次GC重寫入數據之間的壽命。以下分別通過數學模型和實驗真實負載運行的結果來進行論證推測方法的有效性。
1. 推測用戶數據的數據無效時間
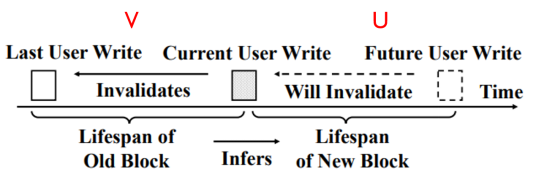
圖3:推測用戶數據的數據無效時間
數學分析: V為上一次和這次用戶寫入之間的壽命,U為這一次和下一次用戶寫入之間的壽命。通過計算條件概率公式,當V<=V0時,U<=U0時的概率,證明當V小的時候U也較小。則條件概率公式為:
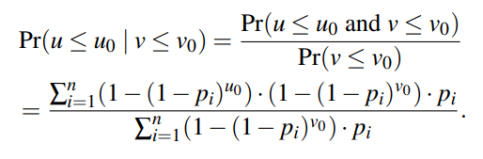
其中Pi為頁面滿足Zipf分布,即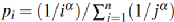 ,其中α越大,則表示工作負載越傾斜。通過調整U0,V0和α觀察結果得出結論。
,其中α越大,則表示工作負載越傾斜。通過調整U0,V0和α觀察結果得出結論。
1)設定α為1時,將U0和V0的閾值在短壽命范圍內進行波動,即0.25-4GB之間,發現得到的條件概率最低為77.1%。即證明了V小的時候,U大概率也是較小的。
2)設定U0為1GB時,調整α和V0,發現當負載越傾斜時,條件概率越大,結論才越成立。
圖4:通過數學分析推測用戶數據寫入無效時間的條件概率
負載分析:通過對真實負載進行運行,并對不同的V0和U0進行統計。發現在大多數的情況下條件概率都比較高。

圖5:通過負載分析推測用戶數據寫入無效時間的條件概率
2. 推測GC重寫入數據的數據無效時間
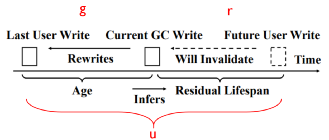
圖6:推測GC重寫入數據的數據無效時間
數學分析: g為上一次用戶寫入和這次GC重寫入之間的壽命,r為這一次GC重寫入和下一次用戶寫入之間的壽命,u為數據在上一次用戶寫入和下一次用戶寫入之間的壽命。通過計算條件概率公式,當u>=g=g0時,u<=g0+r0時的概率,證明壽命大于g0的數據剩余壽命(r)小于r0的概率。則條件概率公式為:
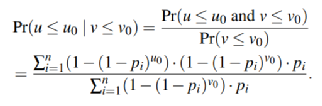
其中Pi也同樣滿足Zipf分布。通過調整g0,r0和α,得出結論如下。
1)設定α為1時,對于每一個r0來說,g0越小,條件概率越大。即不同年齡(g)的數據,其剩余壽命(r)的概率不同,即證明可以通過g來推測r的大小。
2)設定r0為8GB時,調整α和g0。發現,當負載越傾斜的時候,不同g0之間的條件概率差距越大,即越能夠根據g來推測r的大小。
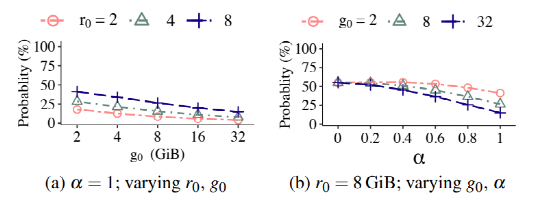
圖7:通過數學分析推測GC數據寫入無效時間的條件概率
負載分析:通過對真實負載進行運行,并對不同的g0和r0進行統計。發現固定r0時,對于不同的g0,條件概率差距較大。故而可以證明推論,可以根據g來推測r的大小。
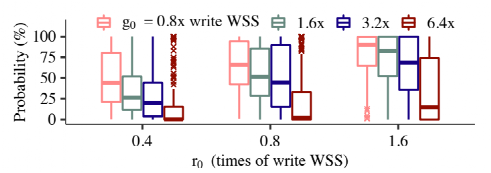
圖8:通過負載分析推測GC數據寫入無效時間的條件概率
最后,簡單介紹下SepBIT的工作流程。
1. 垃圾回收:當剩余空間達到閾值的時候,垃圾回收將被觸發。對于每個回收的1類段將計算該段的無效時間,每16個段計算一次平均段的無效時間作為閾值L。段中的有效數據將進行GC重寫入。
2. 用戶寫入:對于用戶寫入數據,判斷其上一次的壽命是否低于閾值L,若低于則寫入1類段,否則寫入2類段。
3. GC重寫入:如果該數據是1類段中的數據,則寫入3類段中。否則判斷該數據的壽命。若其介于0-4L之間,則寫入4類段;若介于4L-16L之間,則寫入5類段;否則寫入6類段中。
04?實驗效果
????論文作者團隊將SepBIT實現在了基于ZenFS的zoned storage模擬平臺上。其中后端使用的存儲介質為Intel傲騰持久內存。并在其中使用真實的阿里云和騰訊云負載進行測試。其中段的大小和垃圾回收閾值設置為512MB和15%。
????在實驗中,本文與8個基于溫度的數據放置策略進行比較,同時與無數據放置策略,本文的SepBIT和理想化的基于每個數據無效時間的FK進行比較。
????通過最后的實驗結果可以得出以下結論:
1.SepBIT對于不同GC策略、不同段大小下以及不同GC閾值下,均可以達到除FK以外最低的寫放大。
2.SepBIT對于數據無效時間的推測較為精準。
3.通過消融實驗,證明了SepBIT對于用戶數據和GC數據分類的有效性。
4.SepBIT在騰訊云負載下的表現也是最好的。
5.SepBIT在高傾斜度負載下降低了較多的寫放大。
6.SepBIT在大多數負載下對于內存的開銷較低。
7.SepBIT對于大多數負載達到了較高的帶寬。
????基于空間限制,以下展示對于不同GC策略下,各個數據放置策略的寫放大比較,如圖9所示;以及SepBIT對于數據無效時間推測的準確性,如圖10所示,其中縱坐標為累計分布,橫坐標為垃圾回收時無效數據的比例,對于相同累計分布時,其無效數據比例越大說明預測越準確。
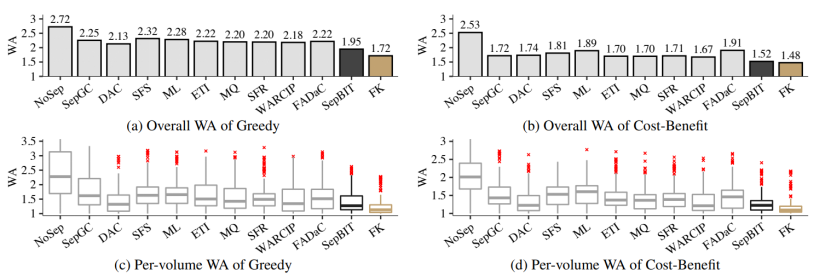
圖9:不同GC策略下,各數據放置策略的寫放大
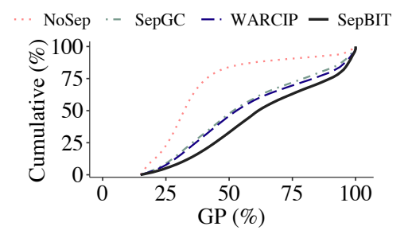
圖10:不同策略對于數據無效時間推測的準確性
05?總結
????SepBIT通過對真實負載的分析發現了用戶寫數據和GC重寫入數據壽命的差異性,同時發現發現并驗證了根據數據過去壽命推測數據接下來壽命的有效性。進而通過將具有相似壽命的數據放在一起從而降低寫放大并提升I/O帶寬。
審核編輯:劉清

















 工商網監
工商網監
評論