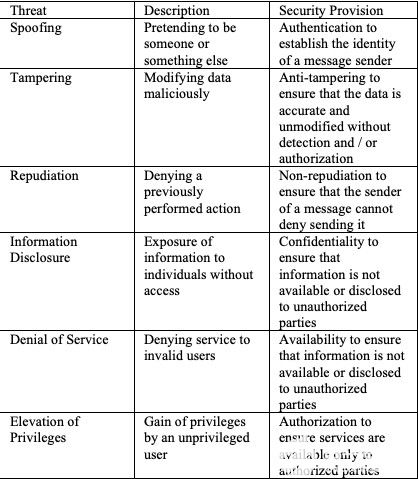
 電子發(fā)燒友App
電子發(fā)燒友App


Source: Shao-Peng Yang, Minjae Kim, Sanghyun Nam, Juhyung Park, Jin-yong Choi, Eyee Hyun Nam, Eunji Lee, Sungjin Lee, Bryan S. Kim, Overcoming the MemoryWall with CXL-Enabled SSDs, July 10, 2023
本文探討了使用廉價閃存內(nèi)存(flash memory)在新型互連技術(shù)(如CXL)上以應(yīng)對“內(nèi)存墻”的可行性。我們探索了CXL啟用的閃存設(shè)備的設(shè)計(jì)空間,并展示了緩存和預(yù)取等技術(shù)可以幫助緩解有關(guān)閃存性能和壽命的擔(dān)憂。我們通過使用真實(shí)世界的應(yīng)用程序跟蹤數(shù)據(jù)展示,這些技術(shù)使得CXL設(shè)備的估計(jì)壽命至少為3.1年,并能在微秒級內(nèi)滿足68-91%的內(nèi)存請求。我們分析了現(xiàn)有技術(shù)的局限性,并提出了系統(tǒng)層面的變更來實(shí)現(xiàn)使用閃存的DRAM級性能。
01.?引言
在計(jì)算系統(tǒng)中,計(jì)算能力和內(nèi)存容量需求之間的日益不平衡發(fā)展成為一個稱為“內(nèi)存墻”的挑戰(zhàn)[23,34,52]。圖1基于Gholami等人的數(shù)據(jù)[34],并擴(kuò)展了更多的最新數(shù)據(jù)[11,30,43],展示了自然語言處理(NLP)模型的快速增長(每年14.1倍),遠(yuǎn)遠(yuǎn)超過了內(nèi)存容量的增長(每年1.3倍)。“內(nèi)存墻”迫使現(xiàn)代數(shù)據(jù)密集型應(yīng)用,如數(shù)據(jù)庫[8,10,14,20]、數(shù)據(jù)分析[1,35]和機(jī)器學(xué)習(xí)(ML)[45,48,66],要么意識到它們的內(nèi)存使用情況[61],要么實(shí)現(xiàn)用戶級內(nèi)存管理[66]以避免昂貴的頁面交換[37,53]。因此,在透明處理應(yīng)用程序的情況下突破“內(nèi)存墻”是一個活躍的研究領(lǐng)域;已經(jīng)積極探索了一些方法,如創(chuàng)建面向ML系統(tǒng)[45,48,61],構(gòu)建內(nèi)存解耦合框架[36,37,52,69]和設(shè)計(jì)新的內(nèi)存架構(gòu)[23,42]。
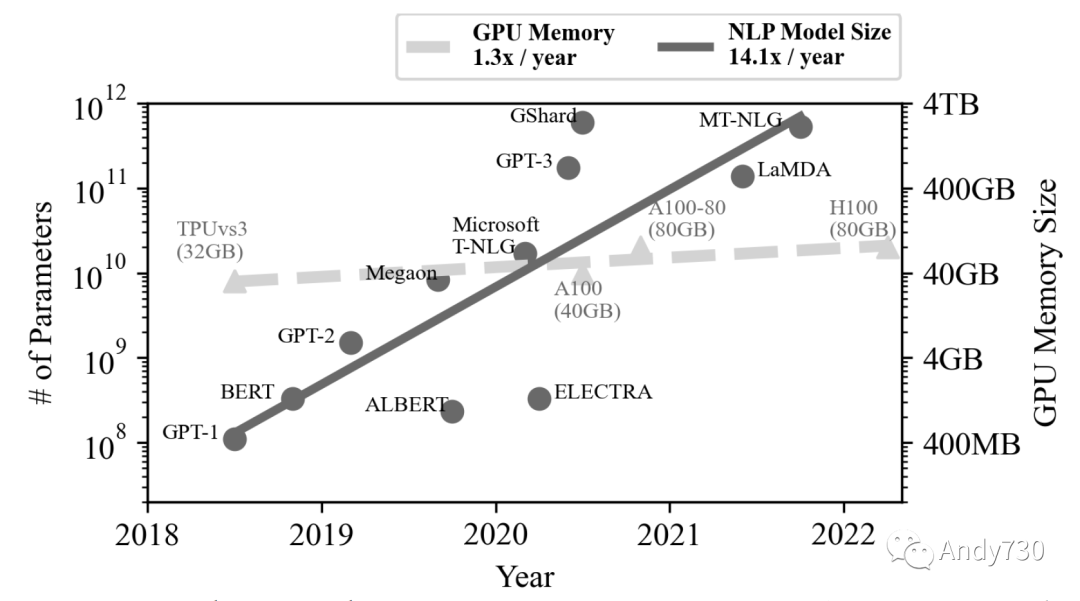
圖1: NLP應(yīng)用程序內(nèi)存需求的趨勢 [11,30,34,43]。每年參數(shù)數(shù)量增加了14.1倍,而GPU的內(nèi)存容量每年只增長了1.3倍
我們探討了是否可以使用閃存內(nèi)存來突破“內(nèi)存墻”——這是一種通常用于存儲的內(nèi)存技術(shù),因?yàn)槠渚哂懈呙芏群腿萘繑U(kuò)展性[59]。雖然DRAM只能擴(kuò)展到幾GB的容量,但基于閃存的固態(tài)硬盤(SSD)可達(dá)到TB級的容量[23],足夠大以應(yīng)對“內(nèi)存墻”的挑戰(zhàn)。閃存內(nèi)存作為主內(nèi)存的使用得益于最近出現(xiàn)的諸如CXL[3]、Gen-Z[7]、CCIX[2]和OpenCAPI[12]的互連技術(shù),它們允許通過load/store指令直接由CPU訪問PCIe(Peripheral Component Interconnect Express)設(shè)備。此外,這些技術(shù)承諾具有出色的可擴(kuò)展性,因?yàn)榭梢酝ㄟ^交換機(jī)連接更多的PCIe設(shè)備[13],而不像用于DRAM的DIMM(雙列直插式內(nèi)存模塊)。
然而,將閃存內(nèi)存作為CPU可訪問的主內(nèi)存面臨著三個主要挑戰(zhàn)。
首先,內(nèi)存請求與閃存內(nèi)存之間存在顆粒度不匹配。這導(dǎo)致了在閃存上需要存在明顯的流量放大,除了已有的閃存間接性需求[23,33]之外:例如,將64B的緩存行刷新到CXL啟用的閃存,將導(dǎo)致16KiB的閃存內(nèi)存頁面讀取、64B更新和16KiB的閃存程序?qū)懭氲搅硪粋€位置(假設(shè)16KiB的頁面級映射)。
其次,閃存內(nèi)存的速度仍然比DRAM慢幾個數(shù)量級(幾微秒對比幾納秒)[5,24]。因此,雖然兩種技術(shù)之間的峰值數(shù)據(jù)傳輸速率相似[4,15],但長時間的閃存內(nèi)存延遲阻礙了持續(xù)性性能,因?yàn)閿?shù)據(jù)密集型應(yīng)用最多只能容忍微秒級的延遲[53]。
最后,閃存內(nèi)存具有有限的耐久性,在經(jīng)過多次寫入后會磨損[24,44]。這限制了內(nèi)存技術(shù)的可用性,因?yàn)槌^耐久性限制的閃存內(nèi)存塊會表現(xiàn)出不可靠的行為和高錯誤率[44]。 ?
我們通過探索設(shè)計(jì)選擇來解決上述閃存內(nèi)存的挑戰(zhàn),特別是與緩存和預(yù)取相關(guān)的選項(xiàng),從而使得CXL啟用的閃存設(shè)備(或稱為CXL-flash)能夠克服“內(nèi)存墻”。盡管之前的研究已經(jīng)探討了多個CXL設(shè)備的可擴(kuò)展性方面 [36,42],并且已經(jīng)證明了CXL-flash的可行性 [9,42],但據(jù)我們所知,我們是第一個對CXL-flash設(shè)備的設(shè)計(jì)選擇以及現(xiàn)有優(yōu)化技術(shù)的有效性進(jìn)行深入開源研究的工作。由于設(shè)計(jì)空間很大,我們首先在第4節(jié)中探索了CXL-flash硬件設(shè)計(jì),然后在第5節(jié)中對詳細(xì)策略和算法進(jìn)行評估和分析。我們發(fā)現(xiàn)可以使用真實(shí)應(yīng)用程序的內(nèi)存跟蹤數(shù)據(jù)設(shè)計(jì)CXL-flash,使得68-91%的請求可以在微秒級內(nèi)實(shí)現(xiàn)延遲,并具有至少3.1年的估計(jì)壽命。在探索各種設(shè)計(jì)和策略的同時,我們進(jìn)行了七項(xiàng)觀察,這些觀察共同表明現(xiàn)代預(yù)取算法不適合預(yù)測CXL-flash的內(nèi)存訪問模式。更具體地說,虛擬地址到物理地址的轉(zhuǎn)換使得現(xiàn)有的預(yù)取器無法足夠有效地執(zhí)行。為了解決這個問題,我們探索了從內(nèi)核向CXL-flash傳遞內(nèi)存訪問提示來進(jìn)一步提高性能。本工作的貢獻(xiàn)如下:
我們開發(fā)了一種新型工具,用于收集應(yīng)用程序的物理內(nèi)存訪問軌跡,并用這些軌跡模擬了CXL-flash的行為。內(nèi)存跟蹤工具和CXL-flash模擬器的代碼都可以在(https://github.com/spypaul/MQSim_CXL.git)上獲取。
通過使用合成工作負(fù)載,我們展示了將各種系統(tǒng)設(shè)計(jì)技術(shù)(如緩存和預(yù)取)集成到CXL-flash中,有潛力顯著減少延遲,同時突顯了優(yōu)化的機(jī)會。(第4節(jié))
使用真實(shí)世界的工作負(fù)載,我們分析了當(dāng)前預(yù)取器的局限性,并提出了用于未來CXL-flash的系統(tǒng)級變更,以實(shí)現(xiàn)接近DRAM的性能,特別是設(shè)備的子微秒級延遲。(第5節(jié))
02.?背景
在本節(jié)中,我們首先描述了CXL(Compute Express Link)[3]作為基于PCIe的內(nèi)存一致性互連技術(shù)(包括Gen-Z [7]、CCIX [2]和OpenCAPI [12])所帶來的機(jī)遇。然后,我們討論了在CXL中使用閃存內(nèi)存的挑戰(zhàn)。 2.1 CXL帶來的機(jī)遇 CXL是一種建立在PCIe之上的新型互連協(xié)議,將CPU、加速器和內(nèi)存設(shè)備集成到單一計(jì)算域中 [42]。這種集成的主要好處有兩個。
首先,它允許CPU和PCIe設(shè)備之間進(jìn)行一致的內(nèi)存訪問。這減少了通常需要在CPU和設(shè)備之間進(jìn)行數(shù)據(jù)傳輸時所需的同步開銷。
其次,CXL設(shè)備的數(shù)量可以很容易地進(jìn)行擴(kuò)展:通過CXL交換機(jī),可以連接另一組CXL設(shè)備到CPU。 ?
在CXL支持的三種類型的設(shè)備中,對于內(nèi)存擴(kuò)展的Type 3設(shè)備對本工作是感興趣的。Type 3設(shè)備公開了主機(jī)管理的設(shè)備內(nèi)存(HDM,host-managed device memory),CXL協(xié)議允許主機(jī)CPU通過load/store指令直接操作設(shè)備內(nèi)存 [3]。雖然CXL目前只考慮DRAM和PMEM作為主要的內(nèi)存擴(kuò)展設(shè)備,但由于CXL的一致性內(nèi)存訪問特性[42],使用SSD也是可能的。 此外,基于閃存的SSD的高容量和更好的擴(kuò)展性,通過3D堆疊[59]和在一個單元中存儲多位[24],可以有效地解決現(xiàn)代數(shù)據(jù)密集型應(yīng)用所面臨的“內(nèi)存墻”問題。受之前關(guān)于CXL的工作的啟發(fā)[36,42],本文研究了使用閃存內(nèi)存作為CXL內(nèi)存擴(kuò)展設(shè)備的可行性。 2.2 閃存的挑戰(zhàn) 我們討論以下三個閃存的特點(diǎn),這使得將其用作系統(tǒng)的主內(nèi)存具有挑戰(zhàn)性。 粒度不匹配。閃存不是隨機(jī)訪問的:其數(shù)據(jù)以頁粒度寫入和讀取,每個頁的大小約為幾千字節(jié)[33],導(dǎo)致大量的流量放大。此外,頁不能被覆蓋寫入。相反,必須首先擦除一個包含數(shù)百個頁的塊,然后才能寫入數(shù)據(jù)到已擦除的頁[33]。這種受限的接口導(dǎo)致任何64B緩存行刷新通過讀取-修改-寫入操作產(chǎn)生大量的寫放大。作為一個塊設(shè)備,其訪問粒度要大得多(4KiB)的SSD擁有更少的開銷。 微秒級延遲。閃存的速度比DRAM慢幾個數(shù)量級,其讀取速度仍在幾十微秒范圍內(nèi),而較慢的編程和擦除操作則在幾百微秒到幾千微秒之間[5,24]。此外,閃存的延遲還取決于其單元技術(shù)[24]。例如,表1中所示,隨著每個單元存儲的位數(shù)增加,從SLC(單級單元)到TLC(三級單元),延遲也會增加。超低延遲(ULL)閃存是SLC的一種變體,以性能為代價提高了密度[46,76]。然而,即使是ULL技術(shù),其速度仍比DRAM慢幾個數(shù)量級。作為一個塊設(shè)備,微秒級的延遲是可以容忍的,因?yàn)榇鎯V写嬖谲浖_銷。然而,對于直接使用load/store指令訪問的內(nèi)存設(shè)備來說,微秒級延遲是一個挑戰(zhàn)。

表1: 內(nèi)存技術(shù)特性概述
有限的耐久性。編程和擦除操作期間施加在閃存上的高電壓會慢慢使單元失效,使它們隨著時間的推移無法使用[44,72]。存儲器制造商規(guī)定了耐久性極限作為一個指導(dǎo),表示閃存塊可以被擦除的次數(shù)。這個限制也取決于閃存技術(shù),如表1所示。雖然這仍然是一個軟限制,閃存超過限制后仍然可以繼續(xù)使用[72],但是磨損的塊表現(xiàn)出不可靠的行為,并且不能保證正確存儲數(shù)據(jù)[44]。由于應(yīng)用程序級和內(nèi)核級的緩存和緩沖,SSD的塊接口的寫入量減少,因此當(dāng)前的耐久性限制在SSD的壽命內(nèi)通常是足夠的。然而,作為內(nèi)存設(shè)備,頻繁的內(nèi)存寫入會使閃存內(nèi)存快速變得無法使用。 我們注意到,雖然這些閃存的挑戰(zhàn)在存儲領(lǐng)域中也存在,但是它們由SSD的內(nèi)部固件處理。然而,對于CXL-flash,由于時間尺度更細(xì),這些挑戰(zhàn)應(yīng)該由硬件來解決,這使得實(shí)現(xiàn)靈活和優(yōu)化的算法變得困難。因此,我們預(yù)期將閃存內(nèi)存從存儲領(lǐng)域移動到內(nèi)存領(lǐng)域時,這些挑戰(zhàn)會加劇。
03.?工具和方法
為了理解CPU到CXL設(shè)備的物理內(nèi)存訪問行為,我們使用頁面錯誤事件構(gòu)建了一個物理內(nèi)存跟蹤工具(第3.1節(jié))。然后,我們通過與一組虛擬內(nèi)存跟蹤(第3.2節(jié))進(jìn)行比較,展示了這個工具的必要性。本工作中生成的工具和數(shù)據(jù)可供公眾使用。 3.1 跟蹤內(nèi)存訪問 主內(nèi)存和CXL-flash通過物理內(nèi)存地址進(jìn)行訪問。不幸的是,據(jù)我們所知,沒有公開可用的工具能夠在沒有硬件修改的情況下跟蹤最后一級緩存(LLC)和內(nèi)存控制器之間的物理內(nèi)存事務(wù)。跟蹤C(jī)PU中的load/store指令是不夠的,因?yàn)椋?)它只收集虛擬地址訪問,(2)最終對CXL-flash的訪問被緩存層次結(jié)構(gòu)過濾掉。
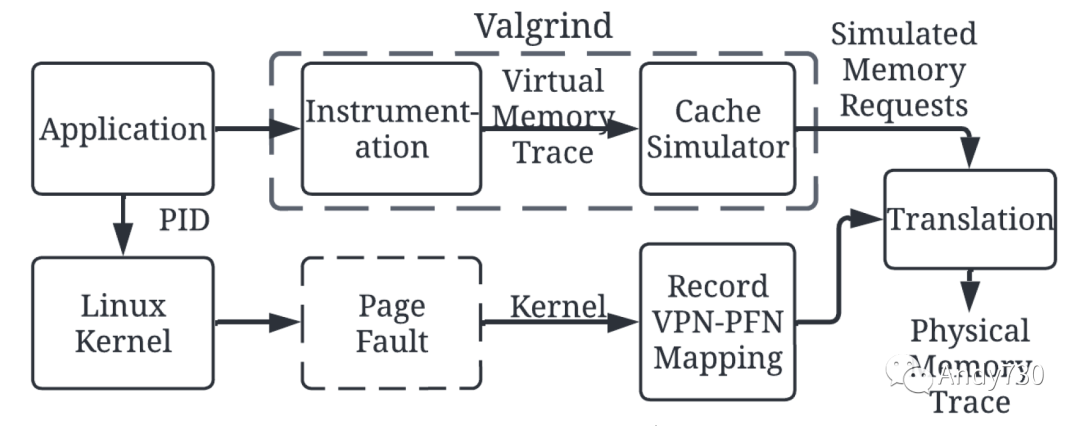
圖2: 收集物理內(nèi)存跟蹤的工作流程。我們使用Valgrind收集虛擬內(nèi)存跟蹤,并在緩存中模擬其行為。同時,我們捕獲頁面故障事件以跟蹤頁面表的更新,并用此生成物理內(nèi)存跟蹤 我們通過結(jié)合來自Valgrind [19,57]的內(nèi)存跟蹤和頁面錯誤事件信息來跟蹤物理內(nèi)存訪問。圖2說明了這個工作流程。如圖頂部路徑所示,我們使用 Valgrind 對應(yīng)用程序進(jìn)行l(wèi)oad/store指令的工具化,并使用其緩存模擬器 (Cachegrind) 來過濾對內(nèi)存的訪問。更具體地說,我們修改了Cachegrind以收集由LLC缺失或替換引起的內(nèi)存訪問。然而,Cachegrind產(chǎn)生的這些內(nèi)存訪問仍然是虛擬地址,因此需要虛擬到物理(V2P)映射信息來生成物理內(nèi)存跟蹤。為此,如圖2底部路徑所示,我們收集應(yīng)用程序運(yùn)行時由頁面錯誤引起的頁表更新。我們修改安裝頁面表項(xiàng)的內(nèi)核函數(shù)(do_anonymous_page()和do_set_pte()),并將目標(biāo)應(yīng)用程序的PID的V2P轉(zhuǎn)換存儲在/proc文件系統(tǒng)中。這捕獲了應(yīng)用程序執(zhí)行過程中頁面表更新的動態(tài)特性,并且開銷很小。我們將來自Valgrind的虛擬訪問和頁面表更新結(jié)合起來生成物理內(nèi)存跟蹤。 3.2 虛擬內(nèi)存與物理內(nèi)存訪問 我們使用基于預(yù)取技術(shù)的前期工作[25, 56]中的五個合成應(yīng)用程序來展示我們的物理內(nèi)存跟蹤工具。所收集的跟蹤特性總結(jié)如表2所示。我們收集了前2000萬次內(nèi)存訪問:請注意這些不是load/store指令,而是LLC和內(nèi)存之間的內(nèi)存事務(wù)。

表2: 合成工作負(fù)載特性概述
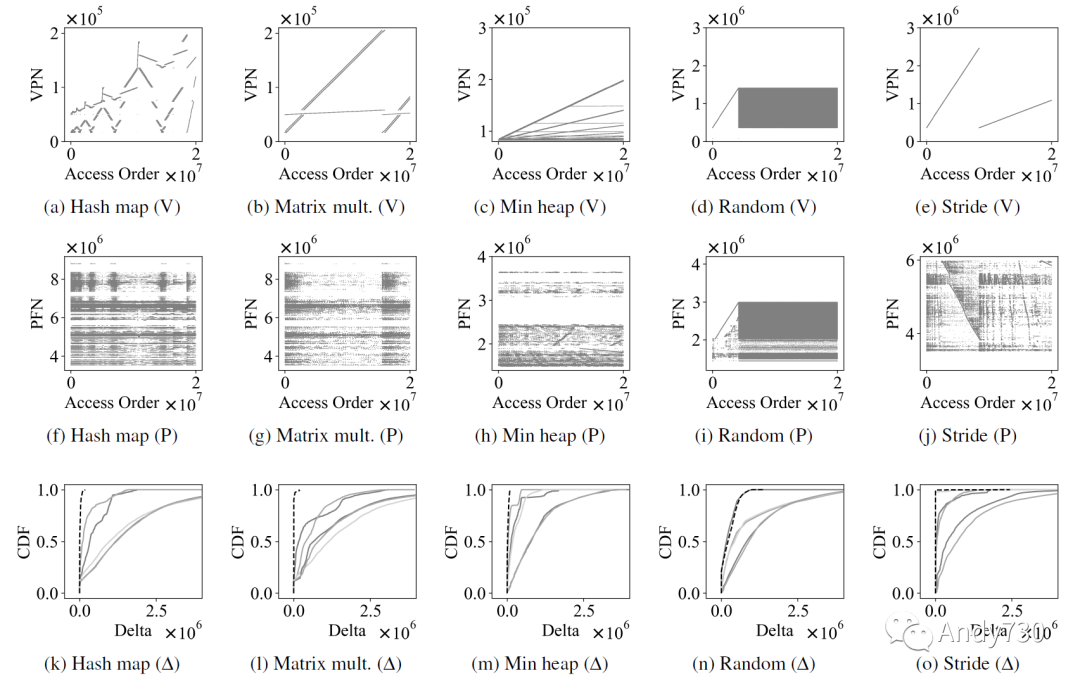
圖3: 顯示五個合成應(yīng)用程序(哈希映射、矩陣乘法、最小堆、隨機(jī)訪問和步幅訪問)的訪問模式的散點(diǎn)圖。頂行(圖3a–3e)顯示虛擬地址訪問,第二行(圖3f–3j)顯示物理訪問。最后一行(圖3k–3o)顯示連續(xù)訪問之間差異的累積分布函數(shù)。我們觀察到由于地址轉(zhuǎn)換,物理內(nèi)存訪問與虛擬內(nèi)存訪問不同 圖3a-3e(圖3的第一行)繪制了這五個合成跟蹤的虛擬頁號(VPN,virtual page number)。我們可以觀察到虛擬地址訪問模式與我們對應(yīng)用程序的期望相匹配。然而,如圖3f-3j(圖3的第二行)所示,相應(yīng)的物理幀號(PFN)并不類似于VPN。我們在圖3k-3o(圖3的最后一行)中顯示了連續(xù)訪問之間的差異(?,delta)。黑色虛線是虛擬地址的delta,而灰色實(shí)線是五次迭代的物理地址的delta,其中兩次迭代是在運(yùn)行其他應(yīng)用程序時運(yùn)行的,以增加內(nèi)存利用率。我們做出兩個觀察。 首先,虛擬訪問模式(黑色虛線)平均具有較小的delta值。然而,物理訪問模式(灰色實(shí)線)可能具有非常大的delta值,這是由于虛擬到物理地址轉(zhuǎn)換所致。 其次,灰色實(shí)線很少彼此重疊,突顯物理內(nèi)存模式是動態(tài)的,并取決于影響內(nèi)存分配的各種運(yùn)行時因素。因此,物理和虛擬地址之間的觀察到的不匹配可能受到動態(tài)因素的影響,如系統(tǒng)的內(nèi)存利用率。 為了證明捕獲物理內(nèi)存跟蹤的必要性,我們通過使用虛擬地址和物理地址跟蹤作為輸入來測量CXL-flash的性能。CXL-flash的配置是具有8個通道和每個通道8個路的閃存后端以及512MiB DRAM緩存,并實(shí)現(xiàn)Next-N-line預(yù)取器[41](更多詳細(xì)信息見第4節(jié))。我們測量了五個合成應(yīng)用程序的內(nèi)存請求在小于1微秒的延遲下的百分比,并在表3中報(bào)告了結(jié)果。使用虛擬內(nèi)存跟蹤生成了一個過于樂觀的結(jié)果,相較于運(yùn)行物理內(nèi)存跟蹤的結(jié)果,更多的請求在1微秒以下完成。虛擬地址和物理地址之間的誤差顯著較高:所有的矩陣乘法實(shí)驗(yàn)的誤差都超過了25%。隨機(jī)和步幅訪問負(fù)載的誤差率較低,使得無論是虛擬還是物理尋址,都很難或者太容易預(yù)測訪問模式。

表3: 使用虛擬和物理地址跟蹤的合成應(yīng)用程序在CXL閃存中的亞微秒延遲百分比。我們重復(fù)五次物理跟蹤生成,其中第4和第5次具有更高的系統(tǒng)內(nèi)存利用率(因此,內(nèi)存布局更加碎片化)。我們計(jì)算虛擬跟蹤性能相對于物理跟蹤的誤差,并用黃色(黃色)標(biāo)記超過10%的錯誤,用紅色(紅色 )標(biāo)記超過25%的錯誤。 減輕地址轉(zhuǎn)換過程中信息的變化的一種技術(shù)是利用大頁面,這可以顯著減少地址轉(zhuǎn)換的數(shù)量[54, 58]以保留內(nèi)存訪問模式。然而,這種方法只能部分減少對系統(tǒng)的影響,并且地址轉(zhuǎn)換是不可避免的。隨著應(yīng)用程序內(nèi)存需求的快速增長(如圖1所示,年均增長率為14.1倍),在幾年內(nèi),大頁面將面臨與較小頁面相同的挑戰(zhàn)。因此,我們決定保持配置的通用性,以探索CXL-flash的設(shè)計(jì)選項(xiàng)。
04.?CXL-flash 的設(shè)計(jì)空間
我們探索構(gòu)建CXL-flash的設(shè)計(jì)空間,特別是其中的硬件模塊;我們稍后在第5節(jié)中評估算法和策略。為了模擬硬件,我們基于MQSim [68]及其擴(kuò)展MQSim-E [49]構(gòu)建了一個CXL-flash模擬器,并使用五個合成應(yīng)用程序的物理內(nèi)存跟蹤(表2)來評估設(shè)計(jì)選項(xiàng)的效果。我們的CXL-flash的整體架構(gòu)如圖4所示,并在表4中展示了初始配置。 本節(jié)中,我們回答以下研究問題。
緩存在提高性能方面的效果如何?(第4.1節(jié))
如何有效地減少閃存內(nèi)存流量?(第4.2節(jié))
預(yù)取在隱藏長閃存內(nèi)存延遲方面的效果如何?(第4.3節(jié))
CXL-flash的合適閃存技術(shù)和并行性是什么?(第4.4節(jié))
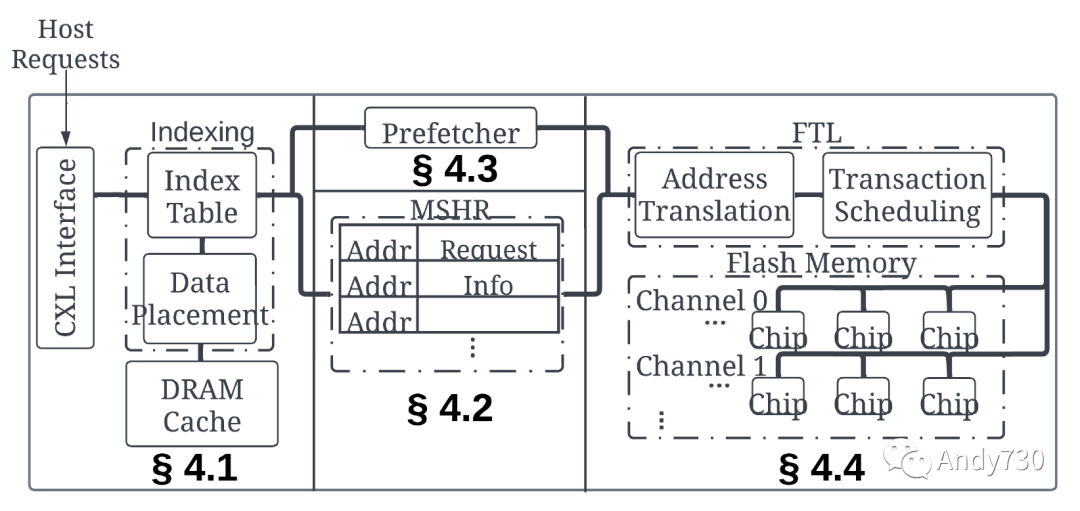
圖4: CXL閃存的體系結(jié)構(gòu)。

表4: §4中CXL閃存的初始配置。
4.1 緩存對性能的影響
我們首先探索在閃存前添加DRAM緩存的效果。緩存主要有兩個作用。
首先,它通過從更快的DRAM中提供頻繁訪問的數(shù)據(jù)來提高CXL-flash的性能。
其次,它在緩存命中時減少對閃存的整體流量。 ?
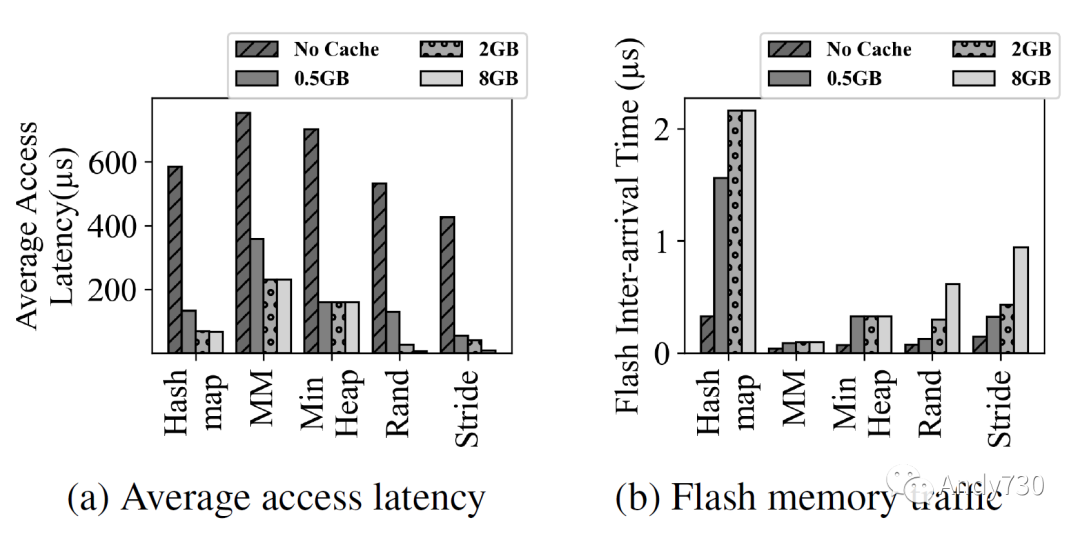
圖5: 隨著DRAM緩存大小變化的64B讀寫請求的平均訪問延遲(圖5a)和閃存內(nèi)存流量(圖5b)。通常情況下,緩存可以提高性能并減少對閃存的流量。然而,即使有足夠大的緩存,平均延遲仍然遠(yuǎn)高于DRAM,這是由于內(nèi)存訪問的高強(qiáng)度造成的。 圖5定量展示了使用緩存的好處。我們將緩存大小從0變化到8GiB,并測量物理內(nèi)存訪問的平均延遲(圖5a)和發(fā)送給后端的閃存內(nèi)存請求的間隔時間(圖5b)。當(dāng)沒有緩存時,由于排隊(duì)延遲,平均延遲遠(yuǎn)高于閃存的讀取和編程延遲。即使閃存后端的配置是每個通道32個通道和每個通道32個路的豐富并行性,但它仍不足以處理具有短間隔時間的內(nèi)存請求。添加緩存顯著減少了對閃存后端的流量,并改善了整體性能。然而,我們觀察到圖5a中,矩陣乘法和最小堆的平均延遲仍遠(yuǎn)高于DRAM的延遲,盡管這些工作負(fù)載的內(nèi)存占用小于緩存。這是由于短間隔時間的請求導(dǎo)致了超負(fù)荷的閃存后端獲取數(shù)據(jù)(圖5b)。這個實(shí)驗(yàn)表明,僅僅使用緩存是不足以降低CXL-flash的延遲的,我們需要額外的輔助結(jié)構(gòu)來減少對閃存的流量。
4.2 減少閃存內(nèi)存流量
內(nèi)存訪問以64B的粒度進(jìn)行,而閃存后端以4KiB為單位進(jìn)行尋址。因此,在緩存未命中時,將從閃存中獲取4KiB的數(shù)據(jù),并且屬于同一4KiB的后續(xù)64B緩存未命中將在閃存讀取正在進(jìn)行時產(chǎn)生額外的閃存內(nèi)存讀取請求。這種情況在具有高空間局部性的內(nèi)存訪問中非常常見,并且由于更長的閃存延遲而加劇。我們將其稱為重復(fù)讀取,圖6說明了哈希圖,矩陣乘法和堆工作負(fù)載中重復(fù)讀取的嚴(yán)重性:超過90%的閃存讀取是重復(fù)讀取!
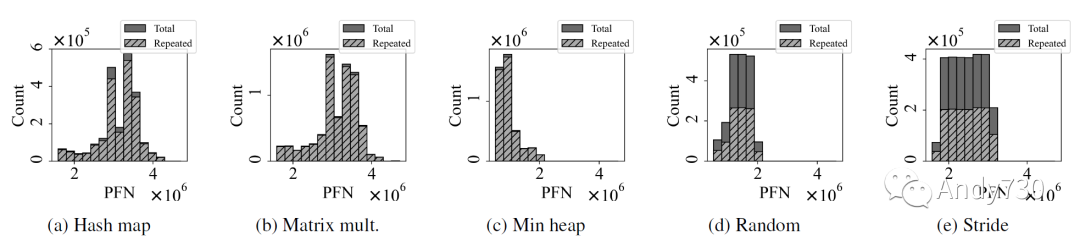
圖6: 物理內(nèi)存幀的閃存讀取次數(shù)。實(shí)心條表示總的讀取次數(shù),而陰影條表示重復(fù)讀取次數(shù)。重復(fù)讀取是對尚未完成的讀取請求的讀取請求。

圖7: 使用(實(shí)線)和不使用(虛線)MSHR的延遲分布。 受到CPU緩存的啟發(fā),我們向CXL-flash中添加了一組MSHR(miss status holding registers)[29, 47],如圖4所示。MSHR跟蹤當(dāng)前未完成的閃存內(nèi)存請求,并從單個閃存內(nèi)存讀取服務(wù)多個64B內(nèi)存訪問。我們注意到,在SSD中MSHR很少見:在存儲領(lǐng)域中,軟件棧合并具有重疊地址的塊I/O,因此不需要底層設(shè)備實(shí)現(xiàn)MSHR。然而,對于CXL-flash,沒有軟件層來執(zhí)行此任務(wù),因?yàn)樗苯訌腖LC接收內(nèi)存事務(wù)。我們觀察到,圖7中的MSHR顯著降低了長尾延遲,特別是對于具有大量重復(fù)讀取的三個工作負(fù)載。我們還觀察到,通過添加MSHR,對于其他兩個工作負(fù)載(隨機(jī)和步幅),也會有輕微的改進(jìn)。然而,MSHR只能減少閃存內(nèi)存流量,并不能通過在需要數(shù)據(jù)之前將數(shù)據(jù)帶入緩存來主動提高緩存命中率。
4.3 從閃存預(yù)取數(shù)據(jù)
預(yù)取(Prefetching)是一種隱藏較慢技術(shù)長延遲的有效技術(shù)。通常,預(yù)取器在需要未命中或預(yù)取命中時獲取額外的數(shù)據(jù)。為了了解這種技術(shù)的有效性,我們在CXL-flash中實(shí)現(xiàn)了一個簡單的Next-N-line預(yù)取器[41],如圖4所示。該預(yù)取器有兩個可配置的參數(shù):度和偏移量。度控制獲取的額外數(shù)據(jù)量,而偏移量決定了觸發(fā)地址的預(yù)取地址。換句話說,度參數(shù)表示預(yù)取器的侵略性,偏移量控制預(yù)取器提前獲取數(shù)據(jù)的距離。
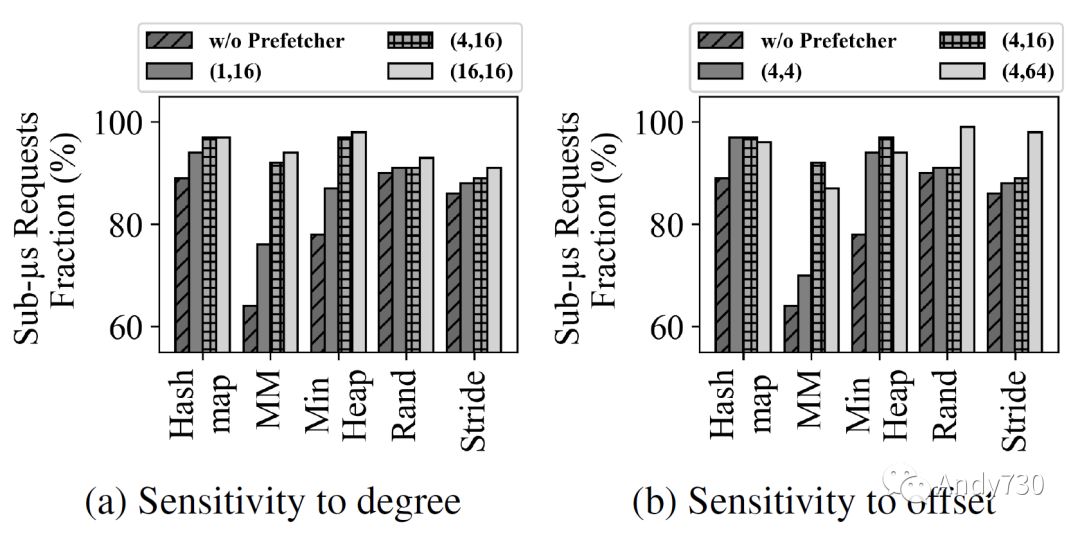
圖8: 具有不同預(yù)取器配置的CXL閃存的性能。
(X, Y)表示Next-N-line預(yù)取器的度和偏移。 圖8顯示了不同度和偏移量對預(yù)取器的影響。在一個以4KiB頁數(shù)為單位的(X,Y)符號中,X表示度,Y表示偏移量。如圖8a所示,增加度或者預(yù)取器的侵略性通常會提高性能。即使是小的度數(shù)1,也會將矩陣乘法工作負(fù)載中的小于一微秒請求的比例從64%提高到76%,凸顯了CXL-flash的預(yù)取的必要性。然而,改進(jìn)效果會達(dá)到平臺,進(jìn)一步增加度數(shù)可能只會污染緩存。另一方面,增加偏移量會導(dǎo)致兩種不同的行為,這取決于工作負(fù)載。對于哈希圖,矩陣乘法和最小堆工作負(fù)載,增加偏移量從4增加到16時性能首先會有所改善。然而,偏移量為64時性能下降,因?yàn)樗A(yù)取了太遠(yuǎn)的數(shù)據(jù)。隨機(jī)工作負(fù)載對偏移量不敏感,除非它足夠大,而步幅工作負(fù)載則隨著偏移量的增加逐漸改善。
4.4 探索閃存技術(shù)和并行性
在之前的子章節(jié)中,我們使用SLC閃存技術(shù)和豐富的閃存并行性(每個通道32個通道和每個通道32個路,32×32)檢驗(yàn)了CXL-flash的性能。在本節(jié)中,我們研究技術(shù)(ULL,SLC,MLC和TLC)和并行性(8×4,8×8,16×16和32×32)對整體CXL-flash性能的敏感性。 首先,我們通過使用步幅工作負(fù)載(如圖9所示)來研究閃存技術(shù)和緩存大小的影響。我們選擇這個工作負(fù)載是因?yàn)樗谀J(rèn)配置下表現(xiàn)良好,因此我們期望它代表了具有最小改進(jìn)空間的工作負(fù)載。圖9a說明了不同內(nèi)存技術(shù)的平均延遲。我們觀察到,即使ULL和SLC閃存的延遲存在顯著差異(3微秒對25微秒),在存在緩存的情況下,兩者之間的性能差異是可以忽略的。只有當(dāng)沒有DRAM緩存時,ULL閃存的性能明顯更好。我們還觀察到使用MLC和TLC技術(shù)會顯著降低性能。圖9b顯示了基于閃存寫入流量估算的CXL-flash的預(yù)計(jì)壽命。這個估算考慮了耐用性限制、容量和數(shù)據(jù)寫入量;它樂觀地假設(shè)閃存后端的寫放大可以忽略。我們觀察到,通過使用ULL和SLC技術(shù)以及一些緩存,CXL-flash的壽命可以達(dá)到4年以上。增加緩存大小進(jìn)一步提高壽命,因?yàn)殚W存寫入流量減少。對于基于MLC和TLC的CXL-flash來說,只有使用足夠大的緩存才是可行的:只有1GiB的緩存,其壽命不會超過一年。
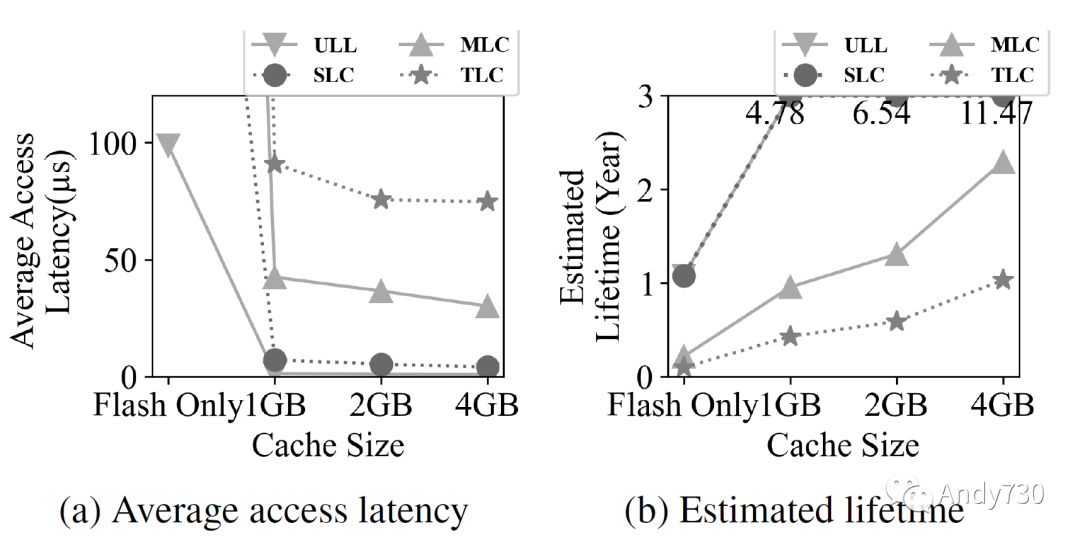
圖9: 對CXL閃存性能和壽命的閃存技術(shù)和緩存大小敏感性測試。
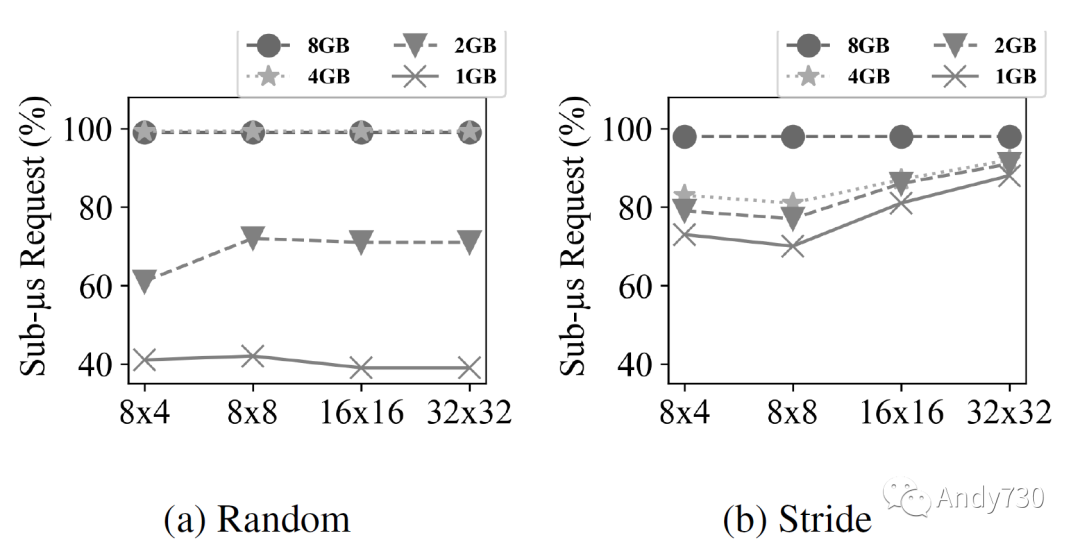
圖10: 不同閃存并行性和緩存大小的亞微秒請求百分比。x軸表示閃存內(nèi)存并行性(通道數(shù)×路數(shù))。線表示不同緩存大小的值。 接下來,我們通過使用隨機(jī)(圖10a)和步幅(圖10b)工作負(fù)載來研究不同閃存并行性和緩存大小對整體性能的影響。我們選擇這兩個工作負(fù)載,因?yàn)樗鼈兙哂凶畲蟮膬?nèi)存占用(分別為8GiB和4GiB)。這里閃存技術(shù)是SLC。我們觀察到,對于足夠大的緩存,減少并行性為(8×4)并不會對性能產(chǎn)生不利影響。然而,對于較小的緩存,閃存并行性很重要。有趣的是,這兩個工作負(fù)載表現(xiàn)出略微不同的行為。隨機(jī)工作負(fù)載對緩存大小非常敏感。另一方面,步幅工作負(fù)載對緩存大小不敏感,但對并行性更敏感。這是由于步幅工作負(fù)載中的預(yù)取器的有效性。
4.5 結(jié)論摘要
我們簡要總結(jié)以下研究結(jié)果:
僅僅使用緩存無法隱藏較長的閃存內(nèi)存延遲(§4.1),我們需要輔助結(jié)構(gòu)來減少閃存內(nèi)存流量(§4.2)。
預(yù)取數(shù)據(jù)可以提高CXL-flash的性能,但最佳配置(甚至算法)取決于工作負(fù)載(§4.3)。
在性能和壽命方面,使用ULL和SLC之間的性能差距僅微不足道,而利用MLC和TLC閃存具有挑戰(zhàn)性(§4.4)。
05.?策略評估
在上一節(jié)(§4)對CXL-flash架構(gòu)的設(shè)計(jì)空間進(jìn)行探索的基礎(chǔ)上,本節(jié)中我們評估了高級緩存和預(yù)取策略。我們選擇了五個來自各個領(lǐng)域的內(nèi)存密集型真實(shí)應(yīng)用程序:自然語言處理[18,70]、圖處理[6,27]、高性能計(jì)算[17,62]、SPEC CPU[16,21]和KV存儲[22,31]。我們使用我們的工具(§3)收集物理內(nèi)存訪問追蹤,并在表5中總結(jié)了工作負(fù)載特性。

表5: 實(shí)際應(yīng)用程序的工作負(fù)載特性。空間和時間局部性值的范圍在0到1之間,并使用棧和塊親和性度量[32]計(jì)算:較高的值表示較高的局部性。 然而,真實(shí)應(yīng)用程序的內(nèi)存占用比我們預(yù)期的要小,盡管它們是在64GiB內(nèi)存的計(jì)算機(jī)上收集的。因此,我們故意將緩存配置為較小(64MiB),以便實(shí)驗(yàn)結(jié)果能夠擴(kuò)展到更大的工作負(fù)載。我們還將閃存并行性縮小到更現(xiàn)實(shí)的設(shè)置,并使用ULL閃存。本節(jié)中CXL-flash的默認(rèn)參數(shù)在表6中總結(jié)。
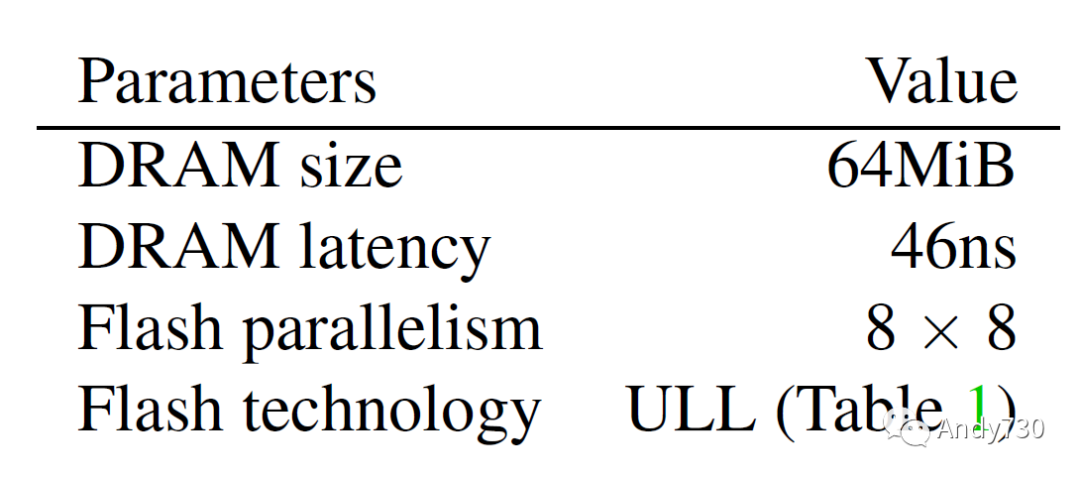
表6: §5中CXL閃存的默認(rèn)參數(shù)。
5.1 緩存替換策略
與先前對性能的緩存大小檢查(§4.1)不同,這里我們固定緩存大小,評估不同緩存替換策略在不同的集合關(guān)聯(lián)性下的影響。特別地,我們實(shí)現(xiàn)了以下四種策略。
FIFO:剔除最舊的數(shù)據(jù)。
隨機(jī):隨機(jī)選擇數(shù)據(jù)剔除。
LRU:剔除最近最少使用的數(shù)據(jù)。
CFLRU [60]:優(yōu)先剔除干凈數(shù)據(jù)而不是已修改的數(shù)據(jù)。 ?
我們選擇隨機(jī)作為基準(zhǔn)線,F(xiàn)IFO和LRU是兩種可以在硬件中實(shí)現(xiàn)的標(biāo)準(zhǔn)CPU緩存策略。為了進(jìn)一步減少流量并延長設(shè)備的壽命,我們實(shí)現(xiàn)了CFLRU,以探索優(yōu)先選擇剔除干凈緩存行以減少閃存寫入活動的好處。 圖11衡量了具有小于一微秒延遲的CXL-flash內(nèi)存請求的百分比,圖12顯示了閃存內(nèi)存寫入次數(shù)。從這些圖表中我們得出五個觀察結(jié)果。 首先,增加關(guān)聯(lián)性會提高性能,因?yàn)樗鼤黾泳彺婷新省τ诰彺嫦到y(tǒng),其失效開銷很高,增加命中率比減少命中時間對性能影響更大。 其次,CFLRU的表現(xiàn)優(yōu)于其他替換策略,特別是在BERT,XZ和YCSB中(圖11a,圖11d和圖11e)。這得到了圖12a,圖12d和圖12e中顯示的寫流量的顯著減少的支持。 第三,具有高局部性的工作負(fù)載,如Radiosity,對緩存替換策略不敏感(圖11c和圖12c):至少有83%的請求具有小于一微秒的延遲,無論采用何種策略。 第四,以讀為主的工作負(fù)載通常比以寫為主的工作負(fù)載表現(xiàn)更好,因?yàn)殚W存內(nèi)存編程延遲相對于讀取延遲偏大。BERT和Radiosity只產(chǎn)生了0.7M和1.0M閃存寫入次數(shù)(圖12a和圖12c),因此其小于一微秒延遲的占比分別達(dá)到了84%和85%(圖11a和圖11c)。 最后,局部性較低的工作負(fù)載不僅性能較差,而且對緩存策略的敏感性較低。特別是,如圖11b所示,僅有最多65%的請求在頁面排名工作負(fù)載中實(shí)現(xiàn)小于一微秒的延遲,因?yàn)槠渚植啃暂^低且內(nèi)存占用較大。圖11d中的XZ跟蹤也表現(xiàn)出較低的局部性,但對于CFLRU的敏感性比頁面排名工作負(fù)載高,因?yàn)楣ぷ髫?fù)載具有較高的寫入比例。
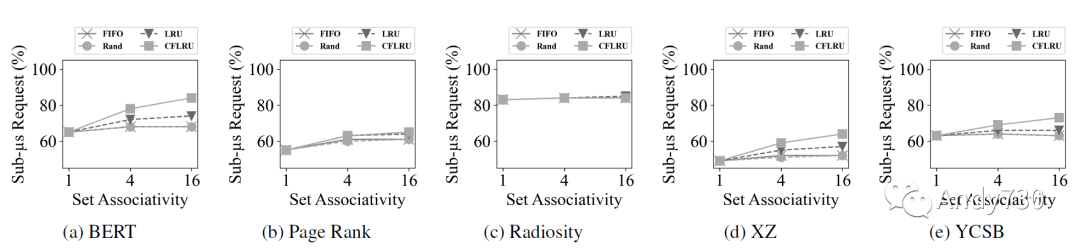
圖11: 基于緩存替換策略和關(guān)聯(lián)性的CXL閃存亞微秒延遲百分比。通常情況下,增加關(guān)聯(lián)性可以減少延遲,而CFLRU表現(xiàn)比其他策略更好。
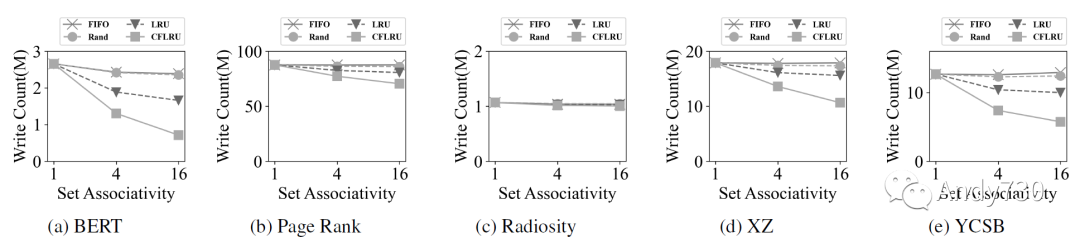
圖12: 基于緩存替換策略和關(guān)聯(lián)性的閃存寫請求數(shù)量。隨著關(guān)聯(lián)性的增加,CFLRU顯著減少寫入次數(shù)。 在存儲領(lǐng)域,通過各種軟件層面的技術(shù),包括操作系統(tǒng)級別的頁緩存,可以減少寫入SSD的數(shù)據(jù)量。然而,CXL-flash的緩存管理行為類似于CPU緩存,并且可能存在其接近最優(yōu)狀態(tài)的限制。
5.2 預(yù)取策略
在 §4.3 中,我們測量了一個簡單的Next-N-line預(yù)取器在大型8GiB緩存下的有效性。在本節(jié)中,我們將緩存縮小為64MiB,并將其關(guān)聯(lián)性設(shè)置為16,并使用CFLRU算法進(jìn)行管理,并測量以下五種預(yù)取器設(shè)置的性能。
NP(無預(yù)取)不預(yù)取任何數(shù)據(jù)。
NL(Next-N-line)[41]在需要缺失或預(yù)取命中時帶來下N個數(shù)據(jù)。
FD(反饋導(dǎo)向)[65]通過跟蹤預(yù)取器的準(zhǔn)確性,及時性和污染來動態(tài)調(diào)整預(yù)取器的攻擊性。
BO(最佳偏移)[55]通過跟蹤最近請求歷史記錄中的連續(xù)訪問之間的差異來學(xué)習(xí)。它還具有禁用預(yù)取的置信度概念。
LP(Leap)[53]實(shí)施基于多數(shù)的預(yù)取,并具有動態(tài)窗口大小調(diào)整。它還根據(jù)預(yù)取器的準(zhǔn)確性逐漸調(diào)整攻擊性。 ?
我們選擇這些算法是因?yàn)樗鼈円驯蛔C明是有效的,可以在硬件中實(shí)現(xiàn),并且適用于CXL-flash的設(shè)計(jì)空間。特別是,NL,F(xiàn)D和BO是用于CPU緩存的預(yù)取器,其中BO是NL的改進(jìn)版本,而FD利用我們將在后面討論的性能指標(biāo)。LP主要用于從遠(yuǎn)程內(nèi)存預(yù)取數(shù)據(jù),其中緩存命中和緩存缺失之間的延遲差異與我們的設(shè)計(jì)空間相似。
觀察1:盡管68-91%的請求延遲小于一微秒,但使用預(yù)取器可能會對真實(shí)世界的應(yīng)用性能產(chǎn)生不利影響。如圖13a所示,最先進(jìn)的預(yù)取器對BERT、XZ和YCSB工作負(fù)載的性能產(chǎn)生了負(fù)面影響,而對另外兩個工作負(fù)載則有所幫助。特別是,在使用最佳偏移預(yù)取器時,Radiosity顯示出36%的子微秒延遲增加。為了理解其中原因,我們檢查了緩存命中率、緩存命中-未命中(HUM)率和缺失率(圖13b)。緩存命中-未命中指的是MSHR中的命中,在此之前由于先前的缺失而正在獲取數(shù)據(jù)的情況。我們觀察到在Radiosity上,BO將25%的緩存命中-未命中轉(zhuǎn)換為命中,表明預(yù)取對局部性因子高的工作負(fù)載(參見表5)具有很高的有效性。我們的觀察結(jié)果表明,預(yù)取器的性能取決于工作負(fù)載的特性,并且它們可能對應(yīng)用產(chǎn)生不利影響。
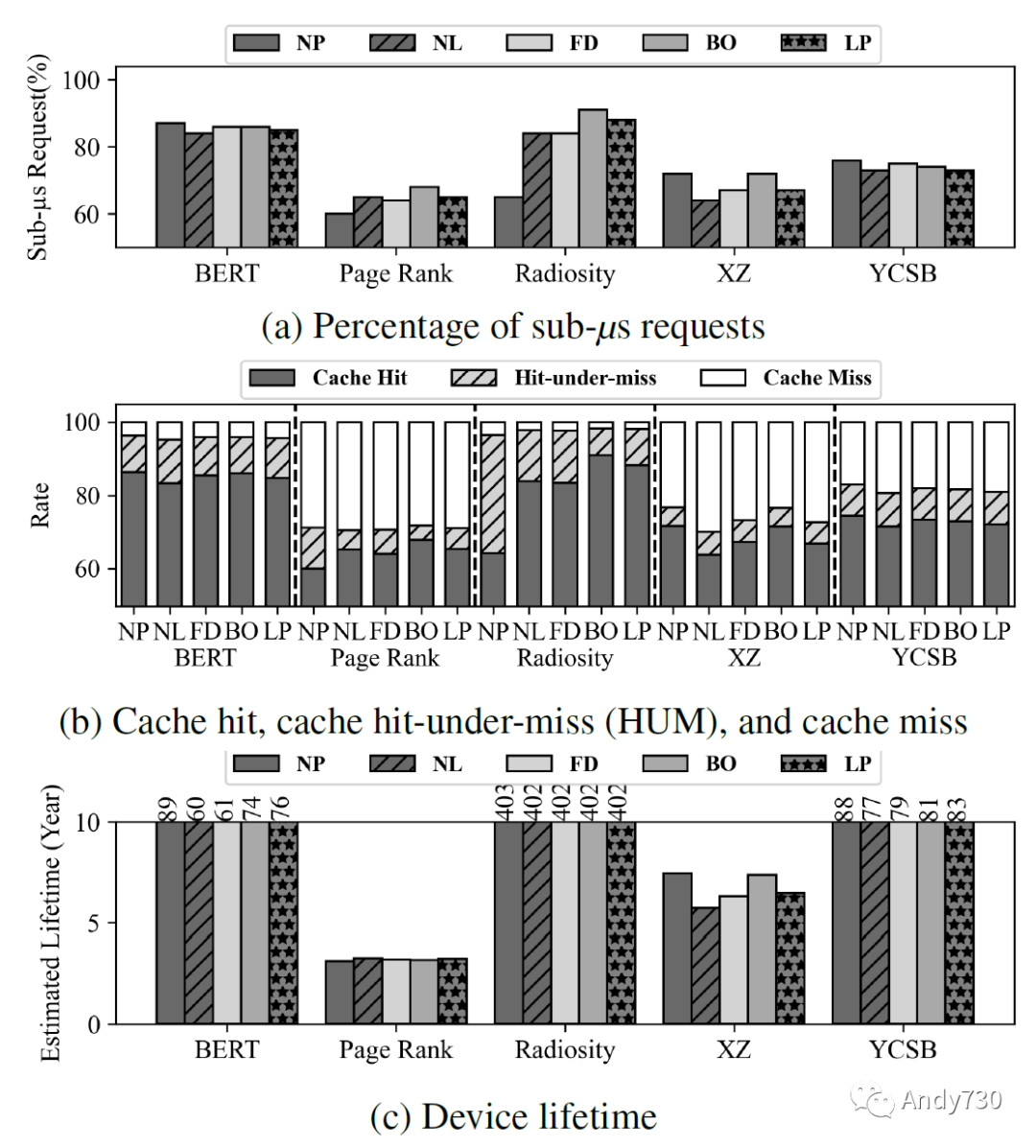
圖13: 具有不同預(yù)取器的CXL閃存性能和壽命。圖13a顯示延遲小于一微秒的請求占比。圖13b顯示CXL閃存內(nèi)64MiB緩存的命中、命中下未命中和未命中率。圖13c繪制了估計(jì)的壽命。
觀察2:即使在高強(qiáng)度的工作負(fù)載下,CXL-flash的壽命至少為3.1年。我們根據(jù)寫入閃存的數(shù)據(jù)量、耐用限制和1TiB容量估計(jì)了CXL-flash在真實(shí)工作負(fù)載下的壽命,如圖13c所示。我們觀察到,在最壞的情況下,設(shè)備在Page Rank下可持續(xù)使用3.1年,但在Radiosity等工作負(fù)載下可達(dá)403年。壽命取決于三個因素:工作負(fù)載強(qiáng)度、讀寫比例和局部性;Page Rank具有最高的工作負(fù)載強(qiáng)度、高寫入比例和低局部性。即使在這種不利條件下,CXL-flash提供了合理的壽命;因此,CXL-flash的耐久性可以滿足內(nèi)存請求的強(qiáng)度。
觀察3:CXL-flash比純DRAM設(shè)備具有更好的性能成本比。盡管CXL-flash在子微秒請求方面稍遜于DRAM,但我們的分析顯示它有潛力為內(nèi)存密集型應(yīng)用程序提供優(yōu)勢。由于CXL-flash可以在小于一微秒的延遲下為68-91%的內(nèi)存請求提供服務(wù),而最近DRAM的價格點(diǎn)比NAND閃存高17-100倍[39,64,77],我們預(yù)計(jì)CXL-flash比純DRAM設(shè)備具有11-91倍的性能成本效益,如圖14所示。雖然在某些情況下,當(dāng)需要最佳性能時,仍然可能更喜歡純DRAM設(shè)備,但根據(jù)工作負(fù)載的不同,CXL-flash可能是一種具有成本效益的內(nèi)存擴(kuò)展選項(xiàng)。 有趣的是,我們觀察到,雖然預(yù)取器對Page Rank有益,但其性能總體上是最差的,只有最多68%的請求在一微秒內(nèi)完成。為了進(jìn)一步了解預(yù)取器的性能,我們測量了以下四個指標(biāo)。
準(zhǔn)確性衡量預(yù)取器實(shí)際使用的預(yù)取數(shù)據(jù)比例。較高的準(zhǔn)確性越好。
覆蓋度是內(nèi)存請求中預(yù)取數(shù)據(jù)緩存命中的部分。較高的覆蓋度意味著緩存命中歸功于預(yù)取器,而較低的覆蓋度則表示預(yù)取器沒有發(fā)揮作用。
延遲是所有預(yù)取數(shù)據(jù)中遲到的比例。較低的延遲越好。
污染是由預(yù)取器引起的緩存缺失中的緩存缺失次數(shù)。較低的污染越好。
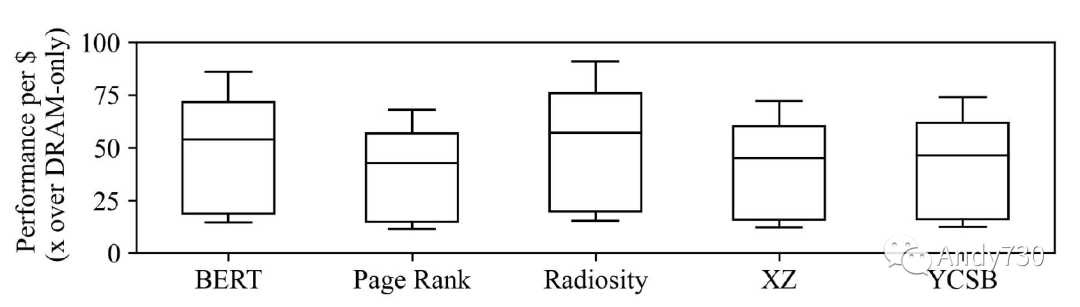
圖14: 使用BO預(yù)取器的CXL閃存相對于僅DRAM設(shè)備的性能-成本收益。估計(jì)是根據(jù)圖13a的性能結(jié)果、DRAM的最新價格點(diǎn)為5 $/GB [77],NAND閃存的價格范圍從0.05到0.30 $/GB [39, 64]得出的。 觀察4:在預(yù)取器改進(jìn)性能的情況下,其成功歸功于實(shí)現(xiàn)高準(zhǔn)確性。我們在圖15中繪制了評估的預(yù)取器的四個指標(biāo)。延遲和污染是負(fù)指標(biāo)(越低越好),因此我們倒置了它們的條形圖,以使所有指標(biāo)都越高越好。我們觀察到,預(yù)取器對預(yù)取器有所幫助的工作負(fù)載(Page Rank和Radiosity)的定義特征是準(zhǔn)確性高。例如,Leap(LP)預(yù)取器在Radiosity下達(dá)到85%的準(zhǔn)確性,而在BERT下只達(dá)到27%。此外,最佳偏移(BO)預(yù)取器在XZ下實(shí)現(xiàn)了48%的準(zhǔn)確性;但是,它僅有4%的覆蓋度,表明盡管準(zhǔn)確性相對較高,但預(yù)取器并未主動獲取數(shù)據(jù)以改善性能。 我們進(jìn)一步分析了Page Rank,以了解為什么預(yù)取器能夠?qū)崿F(xiàn)相對較高的準(zhǔn)確性,即使工作負(fù)載具有最低的局部性(使用堆棧和塊親和性指標(biāo)[32]計(jì)算)。如圖16所示,Page Rank在其工作負(fù)載中呈現(xiàn)出明顯的階段。在第一階段,Page Rank加載圖信息并表現(xiàn)出很高的局部性(圖16a)。最佳偏移預(yù)取器也能夠?qū)崿F(xiàn)很高的覆蓋度和準(zhǔn)確性(圖16b)。然而,在第二階段,Page Rank構(gòu)建圖,并且此處的訪問模式具有非常低的局部性。因此,最佳偏移預(yù)取器變得更不活躍(覆蓋率低),因?yàn)槠錅?zhǔn)確性下降。在最后階段,Page Rank計(jì)算每個頂點(diǎn)的分?jǐn)?shù)。雖然其訪問局部性不高,但預(yù)取器表現(xiàn)良好,并且大部分訪問都在緩存中命中。請注意,雖然污染很嚴(yán)重,但緩存失效率非常低,因此對性能的影響可以忽略不計(jì)。該分析表明,雖然預(yù)取器對第一階段和最后階段有益,但第二階段的低局部性限制了性能。
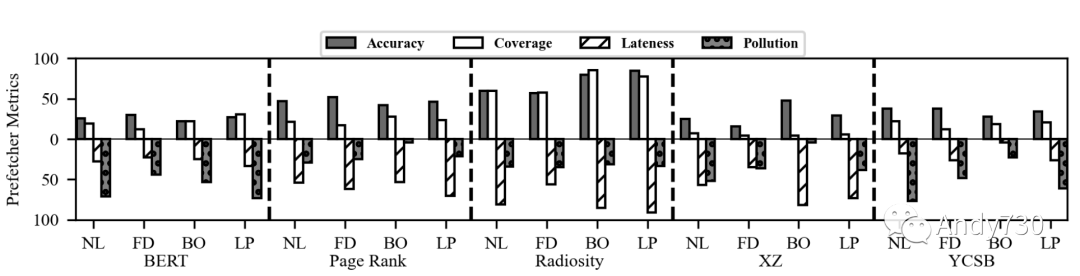
圖15: 預(yù)取器的準(zhǔn)確率、覆蓋率、延遲和污染度指標(biāo)。
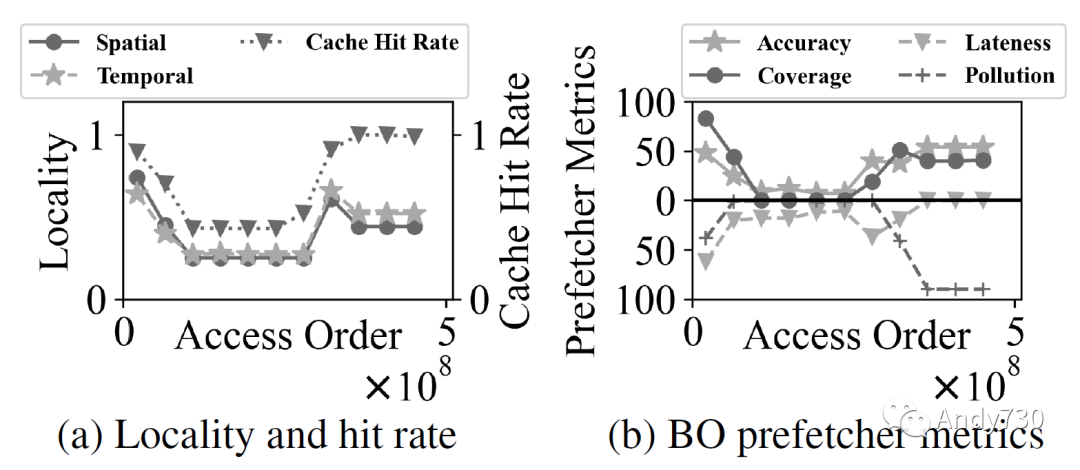
圖16: Page Rank隨時間的行為。
?觀察5:當(dāng)準(zhǔn)確性低時,緩存污染是性能下降的主要原因。如圖15所示,BERT和YCSB具有較低的準(zhǔn)確性,而它們的污染率很高,導(dǎo)致預(yù)取器的啟用會降低性能(圖13a)。對于XZ,盡管最佳偏移(BO)預(yù)取器的準(zhǔn)確性較低,但它與沒有預(yù)取器一樣,因?yàn)樗鼛缀鯖]有污染。我們將這歸因于BO根據(jù)其準(zhǔn)確性的能力禁用預(yù)取。對于Page Rank和Radiosity,預(yù)取器污染率較低,盡管它們的延遲很高。緩存污染降低了CXL-flash的性能,預(yù)取器應(yīng)該注意這種影響,以避免對設(shè)備產(chǎn)生不利影響。
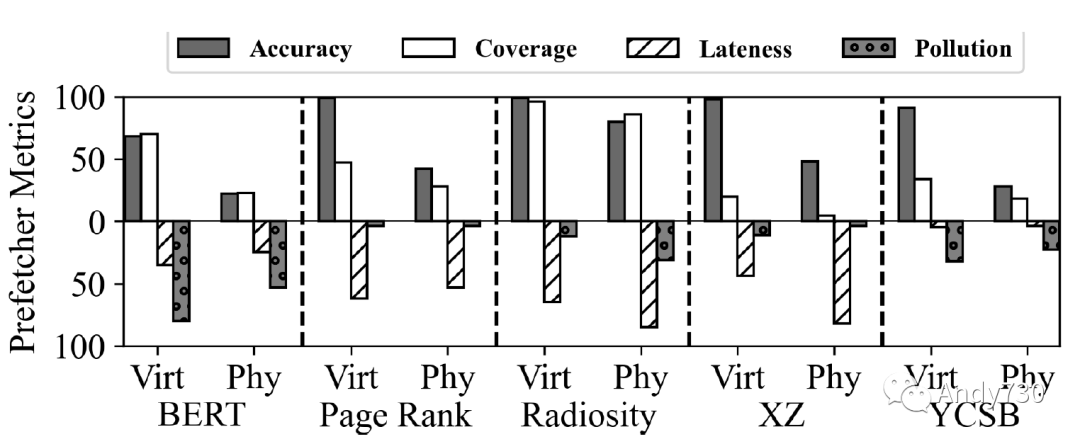
圖17: BO預(yù)取器虛擬與物理指標(biāo)比較。 觀察6:虛擬到物理地址轉(zhuǎn)換使CXL-flash難以預(yù)取數(shù)據(jù)。為了了解虛擬內(nèi)存地址轉(zhuǎn)換的影響,我們使用最佳偏移預(yù)取器模擬CXL-flash,使用5個應(yīng)用程序工作負(fù)載的虛擬內(nèi)存跟蹤數(shù)據(jù),圖17比較了虛擬和物理跟蹤之間的四個預(yù)取器指標(biāo)。我們得出兩個觀察結(jié)果。首先,除了Radiosity之外,我們觀察到從虛擬跟蹤到物理跟蹤的準(zhǔn)確性顯著下降。最佳偏移預(yù)取器在Page Rank的虛擬內(nèi)存跟蹤下的準(zhǔn)確性為99%,但在物理跟蹤下,準(zhǔn)確性下降到42%。其次,覆蓋率也降低,表明預(yù)取器在物理內(nèi)存訪問下變得不太活躍:例如,在BERT下,覆蓋率從76%降至26%。對于物理跟蹤,準(zhǔn)確性和覆蓋率的下降顯示CXL-flash在虛擬尋址下的性能將更好。
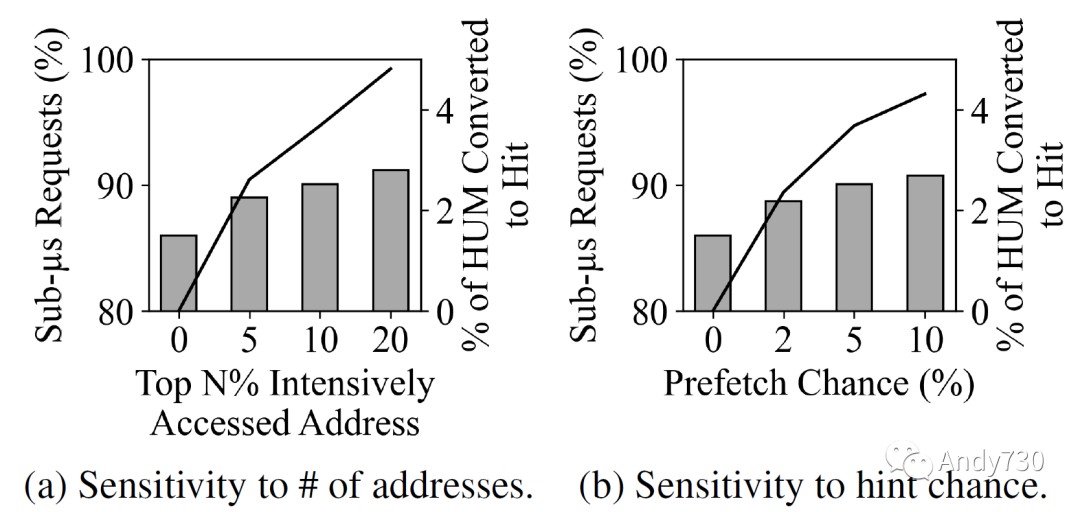
圖18: 使用內(nèi)存訪問模式提示提高BERT性能。圖18a是對提供提示的地址數(shù)量敏感性測試。圖18b顯示隨著添加更多提示的性能改進(jìn)。在兩個圖中,線表示使用提示前的命中下未命中轉(zhuǎn)換為使用提示后的命中次數(shù)。
觀察7:如果內(nèi)核能夠?yàn)樵O(shè)備提供內(nèi)存訪問模式提示,則CXL-flash的性能將通過將命中-未命中轉(zhuǎn)換為緩存命中而得到改善。我們考慮了一個假設(shè)的具有洞察力的內(nèi)核,它知道物理內(nèi)存訪問模式。這不是太牽強(qiáng),因?yàn)閿?shù)據(jù)密集型應(yīng)用程序通常進(jìn)行多次迭代,它們的行為可以進(jìn)行分析。更具體地說,我們假設(shè)內(nèi)核具有有關(guān)頂部密集訪問的物理幀的信息,并可以在實(shí)際訪問之前向設(shè)備傳遞提示。為了限制內(nèi)核參與的開銷,我們模擬了對訪問提示的概率性生成。圖18a顯示了在前N%的密集訪問地址的10%處生成提示時,BERT的性能改進(jìn)情況。我們觀察到,通過將命中-未命中(HUM)轉(zhuǎn)換為緩存命中,隨著對更多地址生成訪問提示,子微秒延遲的百分比從86%增加到91%。圖18b考慮了變量的提示生成概率,從前10%的密集訪問地址的0%到10%。同樣,我們看到整體性能有所改善,但在91%處平穩(wěn)。我們的實(shí)驗(yàn)表明,利用主機(jī)的知識來生成訪問模式提示,可能會提高CXL-flash的性能。
06.?相關(guān)工作
評估的緩存策略和預(yù)取算法在之前的研究中得到了深入探討。然而,大多數(shù)研究都是針對管理和優(yōu)化CPU緩存的,其中緩存命中和緩存未命中之間的延遲差異要小得多,而在CXL-flash中則要大得多。CFLRU [60] 和 Leap [53] 與我們的設(shè)備共享類似的設(shè)計(jì)空間,但它們所面臨的內(nèi)存訪問強(qiáng)度并不像CXL-flash需要處理的那樣極端。因此,必須在CXL-flash的設(shè)計(jì)空間下評估這些策略和算法的有效性。 先前的研究探索了緩解地址轉(zhuǎn)換和閃存限制導(dǎo)致性能下降的技術(shù)。利用大頁面可以減少地址轉(zhuǎn)換次數(shù) [54,58]。
FlashMap [40] 和 FlatFlash [23] 將SSD的地址轉(zhuǎn)換與頁表結(jié)合以減少開銷。eNVY [73] 采用寫入緩沖、頁面重映射和清理策略,實(shí)現(xiàn)直接內(nèi)存尋址并保持性能。CXL主機(jī)系統(tǒng)的未來研究應(yīng)進(jìn)一步探索利用主機(jī)生成提示的潛在好處,并結(jié)合先前的工作來減少開銷。 內(nèi)存解聚將內(nèi)存資源組織在服務(wù)器之間作為網(wǎng)絡(luò)附加的內(nèi)存池,滿足數(shù)據(jù)密集型應(yīng)用的高內(nèi)存需求 [37,38,52,69]。雖然我們的工作不直接研究內(nèi)存解聚系統(tǒng),但使用CXL-flash作為解聚內(nèi)存有助于克服內(nèi)存墻的問題。 先前的研究探索了利用非DRAM擴(kuò)展內(nèi)存的方法 [28,40,63,74]。HAMS [75] 通過以O(shè)S透明的方式管理主機(jī)和內(nèi)存硬件之間的數(shù)據(jù)路徑,將持久性內(nèi)存和ULL閃存聚合成內(nèi)存擴(kuò)展。
Suzuki等人 [67] 提出了一種基于輕量級DMA的接口,繞過NVMe協(xié)議,實(shí)現(xiàn)與DRAM類似性能的閃存讀取訪問。SSDAlloc [26] 是一個內(nèi)存管理器和運(yùn)行時庫,允許應(yīng)用程序通過操作系統(tǒng)分頁機(jī)制將閃存用作內(nèi)存設(shè)備,但訪問SSD中的數(shù)據(jù)可能導(dǎo)致開銷。FlatFlash [23] 則通過整合操作系統(tǒng)分頁機(jī)制和SSD的內(nèi)部映射表,將DRAM和閃存內(nèi)存暴露為一個平坦的內(nèi)存空間。雖然這些先前的工作主要關(guān)注操作系統(tǒng)級管理和主機(jī)設(shè)備交互,但我們的工作在此基礎(chǔ)上,研究了內(nèi)存擴(kuò)展設(shè)備內(nèi)部的設(shè)計(jì)決策。
使用CXL Type 3設(shè)備進(jìn)行內(nèi)存擴(kuò)展是一個活躍的研究領(lǐng)域 [36, 42, 50, 71]。Pond [50] 利用CXL來改進(jìn)云環(huán)境中的DRAM內(nèi)存池,并提出了機(jī)器學(xué)習(xí)模型來管理本地和池化內(nèi)存。雖然該工作研究了如何在云環(huán)境中使用CXL Type 3設(shè)備,但我們的工作研究了如何使用閃存內(nèi)存實(shí)現(xiàn)CXL Type 3設(shè)備。
DirectCXL [36] 成功地在實(shí)際硬件中通過CXL將主機(jī)處理器與外部DRAM連接,并開發(fā)了軟件運(yùn)行時庫來直接訪問資源。最后,CXL-SSD [42] 倡導(dǎo)將CXL和SSD結(jié)合起來擴(kuò)展主機(jī)內(nèi)存。雖然我們與該工作有著相同的目標(biāo),但它主要討論了CXL互聯(lián)和CXL-SSD的可擴(kuò)展性潛力。 專為機(jī)器學(xué)習(xí)設(shè)計(jì)的系統(tǒng)致力于解決內(nèi)存墻挑戰(zhàn) [45,48,51]。MC-DLA [48] 提出了一種架構(gòu),聚合內(nèi)存模塊以擴(kuò)展加速器的訓(xùn)練ML模型的內(nèi)存容量。Behemoth [45] 發(fā)現(xiàn)許多NLP模型需要大量內(nèi)存,但不需要大量帶寬,并提出了一個以閃存為中心的訓(xùn)練框架,管理內(nèi)存和SSD之間的數(shù)據(jù)移動,以克服內(nèi)存墻。
07.?結(jié)論
本文探索了CXL-flash設(shè)備的設(shè)計(jì)空間,并評估了現(xiàn)有的優(yōu)化技術(shù)。通過使用物理內(nèi)存跟蹤,我們發(fā)現(xiàn)68-91%的內(nèi)存訪問可以在CXL-flash設(shè)備上實(shí)現(xiàn)亞微秒的延遲,而且該設(shè)備的壽命至少可以達(dá)到3.1年。我們發(fā)現(xiàn),對于虛擬內(nèi)存的地址轉(zhuǎn)換使得CXL-flash的預(yù)取器特別難以發(fā)揮作用,建議通過傳遞內(nèi)核級別的訪問模式提示來進(jìn)一步提高性能。 雖然我們試圖通過測試多種工作負(fù)載和設(shè)計(jì)參數(shù)來概括結(jié)果,但還需要承認(rèn)一些限制。本文所探索的CXL-flash的當(dāng)前設(shè)計(jì)并未考慮閃存的內(nèi)部任務(wù),如垃圾收集和磨損均衡。此外,所考慮的主機(jī)系統(tǒng)可能并未完全反映CXL引入的新系統(tǒng)特性。因此,我們認(rèn)為在CXL-flash研究領(lǐng)域還需要做更多的工作,而我們的工作可以為未來的研究提供一個平臺。
編輯:黃飛
?
















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論