 電子發燒友App
電子發燒友App


? ? ? ? 人們常常使用HDFS作為存儲服務的核心,大數據的實用性和發展對于企業來講都是很重要的。而在大數據發展之初,最主要的應用場景仍然是離線批處理場景,對存儲的需求追求的是吞吐量,HDFS正是針對這樣的場景而設計的,而隨著技術不斷的發展,越來越多的場景會對存儲提出新的需求,HDFS也面臨著新的挑戰。主要包括幾個方面:
1、數據量問題
一方面隨著業務的增長和新的應用接入,會給HDFS帶來更多的數據,另一方面隨著深度學習,人工智能等技術的發展,用戶通常希望能保存更長時間的數據,以提升深度學習的效果。數據量的快速增加會使集群不斷面臨擴容需求,從而導致存儲成本不斷增加。
2、小文件問題
眾所周知,HDFS的設計是針對離線批處理大文件的,處理小文件并非傳統HDFS擅長的場景。HDFS小文件問題的根源在于文件的元數據信息都是維護在單點Namenode的內存中,單臺機器的內存空間始終是有限的。據估算,單臺namenode集群能容納系統文件數量極限大約在1.5億左右。實際上,HDFS平臺通常作為底層存儲平臺服務于上層多種計算框架,多個業務場景,所以小文件問題從業務的角度也難以避免。目前也有方案例如HDFS-Federation解決Namenode單點擴展性問題,但同時也會帶來巨大的運維管理難度。
3、冷熱數據問題
隨著數據量的不斷增長積累,數據也會呈現出訪問熱度不同的巨大差異。例如一個平臺會不斷地寫入最新的數據,但通常情況下最近寫入的數據訪問頻率會比很久之前的數據高很多。如果無論數據冷熱情況,都采用同樣的存儲策略,是對集群資源的一種浪費。如何根據數據冷熱程度對HDFS存儲系統進行優化是一個亟待解決的問題。
????????? 現有HDFS優化技術
從Hadoop誕生到今天也有超過10年的時間,在此期間HDFS技術本身也在不斷優化演進。HDFS現有一些技術能夠一定程度上解決上述一些問題。這里簡要介紹一下HDFS異構存儲和HDFS糾刪碼技術。
HDFS異構存儲:
Hadoop從2.6.0版本開始支持異構存儲功能。我們知道HDFS默認的存儲策略,對于每個數據塊,采用三個副本的存儲方式,保存在不同節點的磁盤上。異構存儲的作用在于利用服務器不同類型的存儲介質(包括HDD硬盤、SSD、內存等)提供更多的存儲策略(例如三個副本一個保存在SSD介質,剩下兩個仍然保存在HDD硬盤),從而使得HDFS的存儲能夠更靈活高效地應對各種應用場景。
HDFS中預定義支持的各種存儲包括:
ARCHIVE:高存儲密度但耗電較少的存儲介質,例如磁帶,通常用來存儲冷數據
DISK:磁盤介質,這是HDFS最早支持的存儲介質
SSD:固態硬盤,是一種新型存儲介質,目前被不少互聯網公司使用
RAM_DISK :數據被寫入內存中,同時會往該存儲介質中再(異步)寫一份
![]()
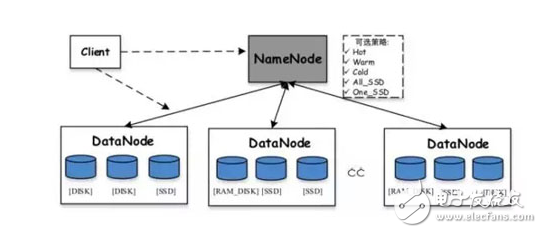
HDFS中支持的存儲策略包括:
Lazy_persist:一個副本保存在內存RAM_DISK中,其余副本保存在磁盤中
ALL_SSD:所有副本都保存在SSD中
One_SSD:一個副本保存在SSD中,其余副本保存在磁盤中
Hot:所有副本保存在磁盤中,這也是默認的存儲策略
Warm:一個副本保存在磁盤上,其余副本保存在歸檔存儲上
Cold:所有副本都保存在歸檔存儲上
總體上HDFS異構存儲的價值在于,根據數據熱度采用不同策略從而提升集群整體資源使用效率。對于頻繁訪問的數據,將其全部或部分保存在更高訪問性能的存儲介質(內存或SSD)上,提升其讀寫性能;對于幾乎不會訪問的數據,保存在歸檔存儲介質上,降低其存儲成本。但是HDFS異構存儲的配置需要用戶對目錄指定相應的策略,即用戶需要預先知道每個目錄下的文件的訪問熱度,在實際大數據平臺的應用中,這是比較困難的一點。
HDFS糾刪碼:
傳統HDFS數據采用三副本機制保證數據的可靠性,即每存儲1TB數據,實際在集群各節點上占用的數據達到3TB,額外開銷為200%。這給節點磁盤存儲和網絡傳輸帶來了很大的壓力。
在Hadoop3.0開始引入支持HDFS文件塊級別的糾刪碼,底層采用Reed-Solomon(k,m)算法。RS是一種常用的糾刪碼算法,通過矩陣運算,可以為k位數據生成m位校驗位,根據k和m的取值不同,可以實現不同程度的容錯能力,是一種比較靈活的糾刪碼算法。
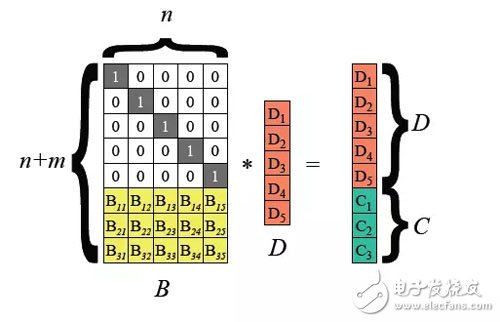
常見的算法為RS(3,2)、RS(6,3)、RS(10,4),k個文件塊和m個校驗塊構成一個組,這個組內可以容忍任意m個數據塊的丟失。
HDFS糾刪碼技術能夠降低數據存儲的冗余度,以RS(3,2)為例,其數據冗余度為67%,相比Hadoop默認的200%大為減少。但是糾刪碼技術存儲數據和數據恢復都需要消耗cpu進行計算,實際上是一種以時間換空間的選擇,因此比較適用的場景是對冷數據的存儲。冷數據存儲的數據往往一次寫入之后長時間沒有訪問,這種情況下可以通過糾刪碼技術減少副本數。
大數據存儲優化:SSM
前面介紹的無論HDFS異構存儲還是糾刪碼技術,前提都是需要用戶對特定的數據指定存儲的行為,就是說用戶需要知道哪些數據是熱點數據,哪些是冷數據。那有沒有一種方法可以自動對存儲進行優化呢?
答案是有的,這里介紹的SSM(Smart Storage Management)系統,它從底層存儲(通常是HDFS)中獲取元數據信息,并通過數據讀寫訪問信息分析獲取數據熱度情況,針對不同熱度的數據,按照預先制定的一系列規則,采用相應的存儲優化策略,從而提升整個存儲系統的效率。SSM是一個由Intel主導的開源的項目,中國移動也參與其中的研發,項目可以在Github中獲取到:https://github.com/Intel-bigdata/SSM 。
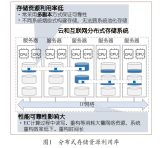
SSM定位是一個存儲外圍優化的系統,整體上采用Server-Agent-Client的架構,其中Server負責SSM整體邏輯的實現,Agent用于對存儲集群執行各種操作,Client是提供給用戶的數據訪問接口,通常其中包含了原生HDFS的接口。
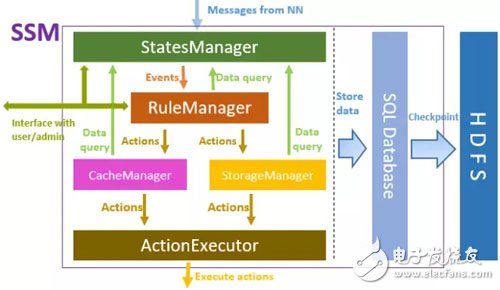
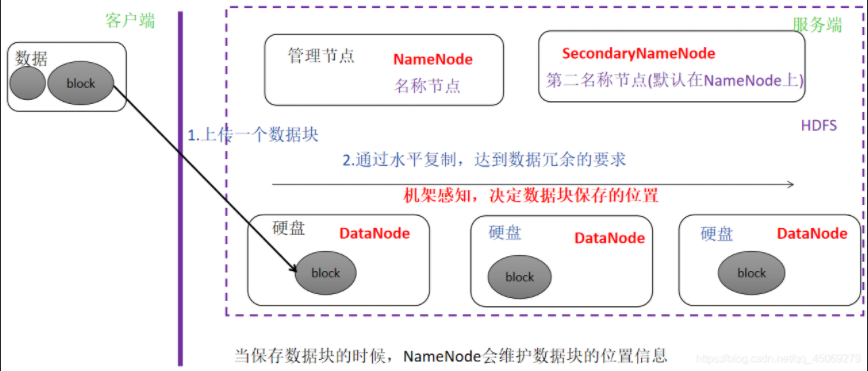
SSM-Server的主要框架如上圖所示,從上到下,StatesManager與HDFS集群進行交互,用于獲取HDFS元數據信息,并維護每個文件的訪問熱度信息。StatesManager中的信息會持久化到關系型數據庫中。在SSM中采用TiDB作為底層存儲的數據庫。RuleManager維護和管理規則相關信息,用戶通過前臺界面為SSM定義一系列存儲規則,RuleManger負責規則的解析和執行。CacheManager/StorageManager根據熱度和規則,生成具體的action任務。ActionExecutor 負責具體的action任務,把任務分配給Agent,并在Agent節點執行。

SSM-Server內部邏輯實現依賴于規則的定義,需要管理員通過前臺web頁面為SSM系統制定一系列規則。一條規則包括幾部分組成:
操作對象,通常是指符合特定條件的文件。
觸發器,指規則觸發的時間點,例如每天定時觸發。
執行條件,定義一系列基于熱度的條件,例如文件在一段時間訪問次數計數要求。
執行操作,對符合執行條件的數據進行相關操作,通常是指定其存儲策略等。
一個實際的規則示例:
file.path matchs ”/foo/*”: accessCount(10min) 》= 3 | one-ssd
這條規則表示對于在/foo目錄下的文件,滿足10分鐘內被訪問次數不低于三次,則對其采用One-SSD的存儲策略,即數據一個副本保存在SSD上,剩余2個副本保存在普通磁盤上。
SSM應用場景
SSM能夠針對數據的冷熱程度,采用不同存儲策略進行優化,以下是一些典型的應用場景:
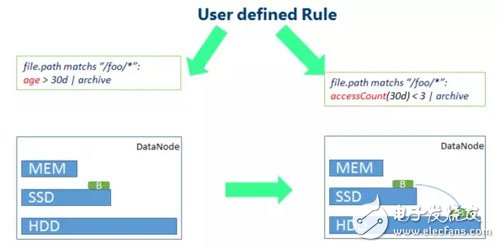
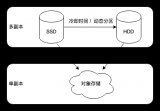
最典型的場景就是針對冷數據,如上圖所示,定義相關規則,將較長時間為沒有訪問的數據采用更低成本的存儲。例如原先的數據塊,從SSD存儲退化到HDD存儲。
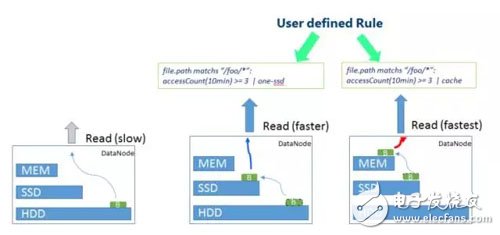
與此類似,對于熱點的數據,同樣可以根據不同的規則,對其采用更快速的存儲策略,如上圖所示,短時間內訪問此處較多的熱點數據,會從HDD存儲上升至SSD存儲,更熱點的數據會采用內存存儲的策略。
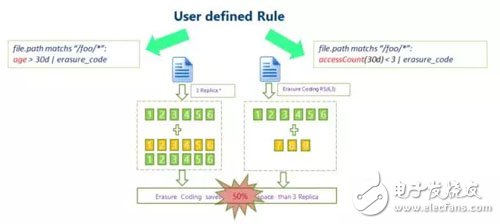
針對冷數據的場景,SSM也可以采用糾刪碼的優化,通過定義相應規則,對于訪問次數很少的冷數據,對其執行erasure code操作,降低數據副本冗余。

另外值得一提的是SSM針對小文件也有相應優化手段,這個功能仍然處于開發過程中。大體邏輯是SSM會對HDFS上一系列小文件執行合并成大文件的操作,同時,在SSM的元數據中記錄下原始小文件和合并后大文件的映射關系以及每個小文件在大文件中的偏移量。當用戶需要訪問小文件時,通過SSM特定的客戶端(SmartClient),根據SSM元數據中的小文件映射信息,從合并后的文件中獲取到原始小文件。









 工商網監
工商網監
評論