 電子發(fā)燒友App
電子發(fā)燒友App


我們現(xiàn)在的所有系統(tǒng)上,大部分都引入了數(shù)據(jù)庫中間件。但很多人都不明白,引入中間間的作用是什么,可以采取不引入的方式嗎。今天小編就來討論一下究竟為什么要引入數(shù)據(jù)庫中間件。
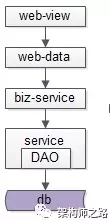
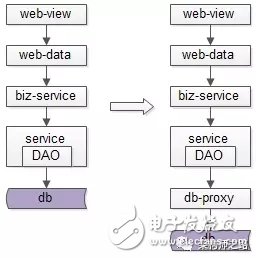
經(jīng)過連續(xù)分層架構(gòu)演進,DAO層,基礎(chǔ)數(shù)據(jù)服務(wù)化,通用業(yè)務(wù)服務(wù)化,前后端分離之后,一個業(yè)務(wù)系統(tǒng)的后端結(jié)構(gòu)如上:
web-view層通過http接口,從web-data獲取json數(shù)據(jù)(前后端分離)
web-data層通過RPC接口,從biz-service獲取數(shù)據(jù)(通用業(yè)務(wù)服務(wù))
biz-service層通過RPC接口,從base-service獲取數(shù)據(jù)(基礎(chǔ)數(shù)據(jù)服務(wù))
base-service層通過DAO,從db獲取數(shù)據(jù)(DAO)
db存儲數(shù)據(jù)
隨著時間的推移,數(shù)據(jù)量會越來越大,base-service通過DAO來訪問db的性能會越來越低,需要開始考慮對db進行水平切分,一旦db進行水平切分,原來很多SQL可以支持的功能,就需要base-service層來進行特殊處理:
有些數(shù)據(jù)需要路由到特定的水平切分庫
有些數(shù)據(jù)不確定落在哪一個水平切分庫,就需要訪問所有庫
有些數(shù)據(jù)需要訪問全局的庫,拿到數(shù)據(jù)的全局視野,到service層進行額外處理
…
更具體的,對于前臺高并發(fā)的業(yè)務(wù),db水平切分后,有這么幾類典型的業(yè)務(wù)場景及應(yīng)對方案。特別強調(diào)一下,此處應(yīng)對的是“前臺”“高并發(fā)”“db水平切分”的場景,對于后臺的需求,將通過前臺與后臺分離的架構(gòu)處理,不在此處討論。
一:partition key上的單行查詢
典型場景:通過uid查詢user
場景特點:
通過patition key查詢
每次只返回一行記錄
解決方案:base-service層通過patition key來進行庫路由
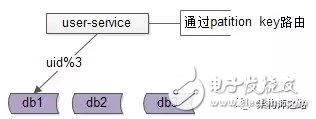
如上圖:
user-service底層user庫,分庫patition key是uid
uid上的查詢,user-service可以直接定位到庫
二、非patition key上的單行查詢
典型場景:通過login_name查詢user
場景特點:
通過非patition key查詢
每次只返回一行記錄
解決方案1:base-service層訪問所有庫
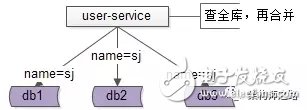
如上圖:
user-service通過login_name先查全庫
結(jié)果集在user-service再合并,最終返回一條記錄
解決方案2:base-service先查mapping庫,再通過patition key路由
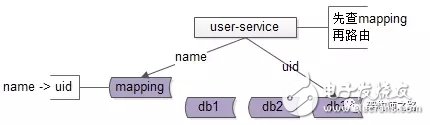
如上圖:
新建mapping庫,記錄login_name到uid的映射關(guān)系
當(dāng)有非 patition key的查詢時,先通過login_name查詢uid
再通過patition key進行路由,最終返回一條記錄
解決方案3:基因法
關(guān)于“基因法”解決非patition key上的查詢需求詳見《分庫后,非patition key上訪問的多種解決辦法》。
三、patition key上的批量查詢
典型場景:用戶列表uid上的IN查詢
場景特點:
通過patition key查詢
每次返回多行記錄
解決方案1:base-service層訪問所有庫,結(jié)果集到base-service合并
解決方案2:base-service分析路由規(guī)則,按需訪問

如上圖:
base-service根據(jù)路由規(guī)則分析,判斷出有些數(shù)據(jù)落在庫1,有些數(shù)據(jù)落在庫2
base-service按需訪問相關(guān)庫,而不是訪問全庫
base-service合并結(jié)果集,返回列表數(shù)據(jù)
四、非patition key上的夸庫分頁需求
關(guān)于分庫后,夸庫分頁的查詢需求,詳見《業(yè)界難題,夸庫分頁的四種方案》。
五、其他需求…
本文寫到這里,上述一、二、三、四、五其實都不是重點,base-service層通過各種各樣的奇技淫巧,能夠解決db水平切分后的數(shù)據(jù)訪問問題,只不過:
base-service層的復(fù)雜度提高了
數(shù)據(jù)的獲取效率降低了
當(dāng)需要進行db水平切分的base-service越來越多以后,此時分層架構(gòu)會變成下面這個樣子:
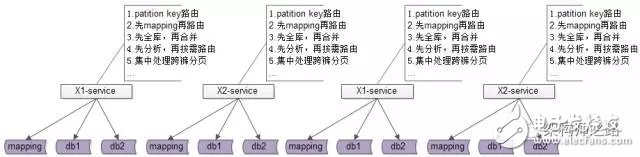
底層的復(fù)雜性會擴散到各個base-service,所有的base-service都要關(guān)注:
patition key路由
非patition key查詢,先mapping,再路由
先全庫,再合并
先分析,再按需路由
夸庫分頁處理
…
這個架構(gòu)圖是不是看上去很別扭?如何讓數(shù)據(jù)的獲取更加高效快捷呢?
數(shù)據(jù)庫中間件的引入,勢在必行。
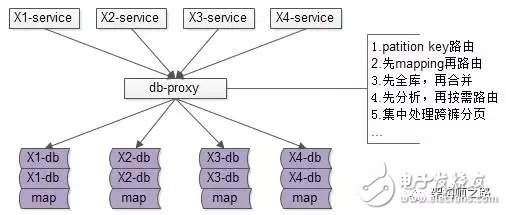
這是“基于服務(wù)端”的數(shù)據(jù)庫中間件架構(gòu)圖:
base-service層,就像訪問db一樣,訪問db-proxy,高效獲取數(shù)據(jù)
所有底層的復(fù)雜性,都屏蔽在db-proxy這一層
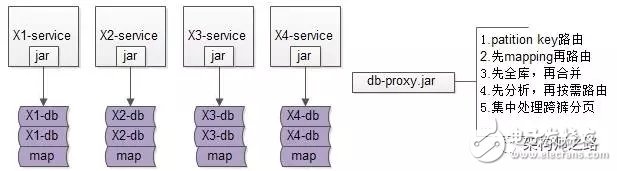
這是“基于客戶端”的數(shù)據(jù)庫中間件架構(gòu)圖:
base-service層,通過db-proxy.jar,高效獲取數(shù)據(jù)
所有底層的復(fù)雜性,都屏蔽在db-proxy.jar這一層
結(jié)論:
當(dāng)數(shù)據(jù)庫水平切分,base-service層獲取db數(shù)據(jù)過于復(fù)雜,成為通用痛點的時候,就應(yīng)該抽象出數(shù)據(jù)庫中間件,簡化數(shù)據(jù)獲取過程,提高數(shù)據(jù)獲取效率,向上游屏蔽底層的復(fù)雜性。













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論