 電子發(fā)燒友App
電子發(fā)燒友App


在搭建Hadoop大數(shù)據(jù)平臺(tái)時(shí),我們常常會(huì)遇到硬件選擇的問(wèn)題,到底什么才是我們最需要的硬件呢?小編列舉了幾條,可以助你參考一下哦。
雖然Hadoop被設(shè)計(jì)為可以運(yùn)行在標(biāo)準(zhǔn)的X86硬件上,但在選擇具體服務(wù)器配置的時(shí)候其實(shí)沒(méi)那么簡(jiǎn)單。為已知的工作負(fù)載或者應(yīng)用場(chǎng)景選擇硬件時(shí),往往都要綜合考慮性能因素和性價(jià)比,才能選擇合適的硬件。比如,對(duì)于IO密集型的工作負(fù)載,用戶往往需要為每個(gè)CPU core匹配更多的存儲(chǔ)或更高的吞吐(more spindles per core)。
通過(guò)本文,您將學(xué)習(xí)到如何根據(jù)工作負(fù)載來(lái)選擇硬件,包括一些其他您需要考慮的因素。
1.計(jì)算和存儲(chǔ)
過(guò)去的十年,業(yè)界基本已經(jīng)形成了刀片和SANs(Storage Area Networks)的標(biāo)準(zhǔn),從而滿足網(wǎng)格和處理密集型的工作負(fù)載。這種模式對(duì)于許多標(biāo)準(zhǔn)應(yīng)用(比如Web服務(wù)器,應(yīng)用服務(wù)器,較小的結(jié)構(gòu)化數(shù)據(jù)和數(shù)據(jù)搬運(yùn))還都是適用的,但是隨著數(shù)據(jù)量和用戶數(shù)據(jù)的增長(zhǎng),基礎(chǔ)設(shè)施的需求也發(fā)生了變化。Web服務(wù)器現(xiàn)在已經(jīng)有了緩存層,數(shù)據(jù)庫(kù)借助本地磁盤(pán)開(kāi)始支持海量并發(fā),數(shù)據(jù)搬運(yùn)的壓力迫使我們需要更多的在本地處理數(shù)據(jù)。
“很多人在搭建Hadoop集群時(shí)都沒(méi)有去真正了解過(guò)工作負(fù)載”
硬件供應(yīng)商更新了對(duì)應(yīng)的產(chǎn)品來(lái)滿足相應(yīng)的需求,包括存儲(chǔ)刀片,SAS(Serial Attached SCSI)交換機(jī),外掛的SATA陣列和容量更大的機(jī)架。然而,Hadoop是基于一個(gè)全新的存儲(chǔ)和處理數(shù)據(jù)的方式,盡量避免數(shù)據(jù)傳輸。Hadoop通過(guò)軟件層來(lái)實(shí)現(xiàn)大數(shù)據(jù)的處理以及可靠性,而不像一個(gè)SAN存儲(chǔ)所有數(shù)據(jù),如果計(jì)算則傳輸?shù)揭幌盗械镀M(jìn)行計(jì)算。
Hadoop將數(shù)據(jù)分布式存儲(chǔ)在各臺(tái)服務(wù)器上,使用文件副本來(lái)保證數(shù)據(jù)不丟以及容錯(cuò)。這樣一個(gè)計(jì)算請(qǐng)求可以直接分發(fā)到存儲(chǔ)數(shù)據(jù)的相應(yīng)服務(wù)器并開(kāi)始進(jìn)行本地計(jì)算。由于Hadoop集群的每臺(tái)節(jié)點(diǎn)都會(huì)存儲(chǔ)和處理數(shù)據(jù),所以你就需要考慮怎樣為集群里的這些服務(wù)器選擇合適的配置。
2.為什么跟工作負(fù)載有關(guān)系
在很多情況下,MapReduce/Spark都會(huì)遭遇瓶頸,比如從磁盤(pán)或者網(wǎng)絡(luò)讀取數(shù)據(jù)(IO-bound的作業(yè)),或者在CPU處理大量數(shù)據(jù)時(shí)(CPU-bound的作業(yè))。IO-bound的作業(yè)的一個(gè)例子是排序,一般需要很少的處理(簡(jiǎn)單的比較)卻需要大量的讀寫(xiě)磁盤(pán)。CPU-bound的作業(yè)的一個(gè)例子是分類(classification),一些數(shù)據(jù)往往需要很復(fù)雜的處理。
典型的IO-bound的工作負(fù)載如下:
索引(Indexing)
分組(Grouping)
數(shù)據(jù)導(dǎo)入導(dǎo)出
數(shù)據(jù)傳輸和轉(zhuǎn)換
典型的CPU-bound工作負(fù)載如下:
聚類和分類(Clustering/Classification)
復(fù)雜的文本挖掘
自然語(yǔ)言處理
特征提取
我們需要完全了解工作負(fù)載,才能夠正確的選擇合適的Hadoop硬件。很多人因?yàn)閺膩?lái)沒(méi)有研究過(guò)工作負(fù)載,往往會(huì)導(dǎo)致Hadoop運(yùn)行的作業(yè)是基于不合適的硬件。此外,一些工作負(fù)載往往會(huì)受到一些其他的限制。比如因?yàn)檫x擇了壓縮,本應(yīng)該是IO-bound的工作負(fù)載實(shí)際卻是CPU-bound的,或者因?yàn)?a href="http://www.1cnz.cn/v/tag/2562/" target="_blank">算法選擇不同而使MapReduce或者Spark作業(yè)受限。由于這些原因,當(dāng)您不熟悉未來(lái)將要運(yùn)行的工作負(fù)載時(shí),可以選擇一些較為均衡的硬件配置來(lái)搭建Hadoop集群。
接下來(lái)我們就可以在集群中運(yùn)行一些MapReduce/Spark作業(yè)進(jìn)行基準(zhǔn)測(cè)試,來(lái)分析它們的bound方式。可以通過(guò)一些監(jiān)控工具來(lái)確定工作負(fù)載的瓶頸。當(dāng)然Cloudera Manager提供了這個(gè)功能,包括CPU,磁盤(pán)和網(wǎng)絡(luò)負(fù)載的實(shí)時(shí)統(tǒng)計(jì)信息。通過(guò)Cloudera Manager,當(dāng)集群在運(yùn)行作業(yè)時(shí),系統(tǒng)管理員可以通過(guò)dashboard很直觀的查看每臺(tái)機(jī)器的性能表現(xiàn)。
“第一步是了解運(yùn)維部門管理的硬件。”
除了根據(jù)工作負(fù)載來(lái)選擇硬件外,還可以與硬件廠商一起了解耗電和散熱以節(jié)省額外的開(kāi)支。由于Hadoop是運(yùn)行在數(shù)十,數(shù)百甚至數(shù)千個(gè)節(jié)點(diǎn)上,盡可能多的考慮方方面面都可以節(jié)省成本。每個(gè)硬件廠商都提供了專門的工具來(lái)監(jiān)控耗電和散熱,以及如何改良的最佳實(shí)踐。
3.為CDH集群挑選硬件
在挑選硬件的時(shí)候,第一步是了解您的運(yùn)維部門所管理的硬件類型。運(yùn)維部門往往傾向于選擇他們熟悉的硬件。但是,如果您是在搭建一個(gè)新的集群,并且無(wú)法準(zhǔn)確的預(yù)測(cè)集群未來(lái)的工作負(fù)載,我們建議您還是選擇適合Hadoop較為均衡的硬件。
一個(gè)Hadoop集群通常有4個(gè)角色:NameNode(和Standby NameNode),ResourceManager,NodeManager和DataNode。集群中的絕大多數(shù)機(jī)器同時(shí)是NodeManager和DataNode,既用于數(shù)據(jù)存儲(chǔ),又用于數(shù)據(jù)處理。
以下是較為通用和主流的NodeManager/DataNode配置:
12-24塊1-6TB硬盤(pán), JBOD (Just a Bunch Of Disks)
2 路8核,2路10核,2路12核的CPU, 主頻至少2-2.5GHz
64-512GB內(nèi)存
綁定的萬(wàn)兆網(wǎng) (存儲(chǔ)越多,網(wǎng)絡(luò)吞吐就要求越高)
NameNode負(fù)責(zé)協(xié)調(diào)集群上的數(shù)據(jù)存儲(chǔ),ResourceManager則是負(fù)責(zé)協(xié)調(diào)數(shù)據(jù)處理。Standby NameNode不應(yīng)該與NameNode在同一臺(tái)機(jī)器,但應(yīng)該選擇與NameNode配置相同的機(jī)器。我們建議您為NameNode和ResourceManager選擇企業(yè)級(jí)的服務(wù)器,具有冗余電源,以及企業(yè)級(jí)的RAID1或RAID10磁盤(pán)配置。
NameNode需要的內(nèi)存與集群中存儲(chǔ)的數(shù)據(jù)塊成正比。我們常用的計(jì)算公式是集群中100萬(wàn)個(gè)塊(HDFS blocks)對(duì)應(yīng)NameNode的1GB內(nèi)存。常見(jiàn)的10-50臺(tái)機(jī)器規(guī)模的集群,NameNode服務(wù)器的內(nèi)存配置一般選擇128GB,NameNode的堆棧一般配置為32GB或更高。另外建議務(wù)必配置NameNode和ResourceManager的HA。
以下是NameNode/ResourceManager及其Standby節(jié)點(diǎn)的推薦配置。磁盤(pán)的數(shù)量取決于你想冗余備份元數(shù)據(jù)的份數(shù)。
4–6個(gè)1TB的硬盤(pán),JBOD(1個(gè)是OS, 2個(gè)是NameNode的FS image [RAID 1], 1個(gè)配置給Apache ZooKeeper, 還一個(gè)是配置給Journal node)
2路6核,2路8核的CPU, 主頻至少2-2.5GHz
64-256GB的內(nèi)存
綁定的萬(wàn)兆網(wǎng)
“記住,Hadoop生態(tài)系統(tǒng)的設(shè)計(jì)需考慮并行環(huán)境。”
如果預(yù)期你的Hadoop集群未來(lái)會(huì)超過(guò)20臺(tái)機(jī)器,建議集群初始規(guī)劃就跨兩個(gè)機(jī)架,每個(gè)機(jī)柜都配置柜頂(TOR,top-of-rack)的10GigE交換機(jī)。隨著集群規(guī)模的擴(kuò)大,跨越多個(gè)機(jī)架時(shí),我們?cè)跈C(jī)架之上還要配置冗余的核心交換機(jī),帶寬一般為40GigE,用來(lái)連接所有機(jī)柜的柜頂(TOR)交換機(jī)。擁有兩個(gè)機(jī)架,可以讓運(yùn)維團(tuán)隊(duì)更好的了解機(jī)架內(nèi)以及跨機(jī)架的網(wǎng)絡(luò)通信需求。Hadoop網(wǎng)絡(luò)要求可以參考Fayson之前的文章CDH網(wǎng)絡(luò)要求(Lenovo參考架構(gòu))。
當(dāng)搭建好Hadoop集群后,我們就可以開(kāi)始識(shí)別和整理運(yùn)行在集群之上的工作負(fù)載,并且為這些工作負(fù)載準(zhǔn)備基準(zhǔn)測(cè)試,以定位硬件的瓶頸在哪里。經(jīng)過(guò)一段時(shí)間的基準(zhǔn)測(cè)試和監(jiān)控,我們就可以了解需要如何增加什么樣配置的新機(jī)器。異構(gòu)的Hadoop集群是比較常見(jiàn)的,特別是隨著數(shù)據(jù)量和用例數(shù)量的增加,集群需要擴(kuò)容時(shí)。所以如果因?yàn)榍捌诓⒉皇煜すぷ髫?fù)載,選擇了一些較為通用的服務(wù)器,也并不是不能接受。Cloudera Manager支持服務(wù)器分組,從而使異構(gòu)集群配置變的很簡(jiǎn)單。
以下是不同的工作負(fù)載的常見(jiàn)機(jī)器配置:
Light Processing Configuration,1U的機(jī)器,一般為測(cè)試,開(kāi)發(fā)或者低要求的場(chǎng)景:2個(gè)hex-core CPUs,24-64GB內(nèi)存,8個(gè)磁盤(pán)(1TB或者2TB)
Balanced Compute Configuration,均衡或主流的配置,1U/2U的機(jī)器:2個(gè)hex-core CPUs,48-256GB的內(nèi)存,12-16塊磁盤(pán)(1TB-4TB),硬盤(pán)為直通掛載
Storage Heavy Configuration,重存儲(chǔ)的配置,2U的機(jī)器:2個(gè)hex-core CPUs,48-128GB的內(nèi)存,16-24塊磁盤(pán)(2TB-6TB)。這種配置一旦多個(gè)節(jié)點(diǎn)或者機(jī)架故障,將對(duì)網(wǎng)絡(luò)流量造成很大的壓力
Compute Intensive Configuration,計(jì)算密集型的配置,2U的機(jī)器:2個(gè)hex-core CPUs,64-512GB memory,4-8塊磁盤(pán)(1TB-4TB)
注意:以上2路6核為最低的CPU配置,推薦的CPU選擇一般為2路8核,2路10核,2路12核
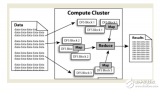
下圖顯示如何根據(jù)工作負(fù)載來(lái)選擇你的機(jī)器:

4.其他注意事項(xiàng)
Hadoop生態(tài)系統(tǒng)是一個(gè)并行環(huán)境的系統(tǒng)。在選擇購(gòu)買處理器時(shí),我們不建議選擇主頻(GHz)最高的芯片,這樣一般都代表了更高電源瓦數(shù)(130W+)。因?yàn)檫@會(huì)產(chǎn)生兩個(gè)問(wèn)題:更高的功率消耗和需要更多的散熱。較為均衡的選擇是在主頻,價(jià)格和核數(shù)之間做一個(gè)平衡。
當(dāng)存在產(chǎn)生大量中間結(jié)果的應(yīng)用程序 – 輸出結(jié)果數(shù)據(jù)與輸入數(shù)據(jù)相當(dāng),或者需要較多的網(wǎng)絡(luò)交換數(shù)據(jù)時(shí),建議使用綁定的萬(wàn)兆網(wǎng),而不是單個(gè)萬(wàn)兆網(wǎng)口。
當(dāng)計(jì)算對(duì)內(nèi)存要求比較高的場(chǎng)景,請(qǐng)記住,Java最多使用10%的內(nèi)存來(lái)管理虛擬機(jī)。建議嚴(yán)格配置Hadoop使用的堆大小的限制,從而避免內(nèi)存交換到磁盤(pán),因?yàn)榻粨Q會(huì)大大影響計(jì)算引擎如MapReduce/Spark的性能。
優(yōu)化內(nèi)存通道寬度也同樣重要。比如,當(dāng)使用雙通道內(nèi)存時(shí),每臺(tái)機(jī)器都應(yīng)配置一對(duì)DIMM。使用三通道內(nèi)存時(shí),每個(gè)機(jī)器都應(yīng)該具有三倍的DIMM。同樣,四通道DIMM應(yīng)該被分為四組。
5.Hadoop其他組件的考慮
Hadoop遠(yuǎn)遠(yuǎn)不止HDFS和MapReduce/Spark,它是一個(gè)全面的數(shù)據(jù)平臺(tái)。CDH平臺(tái)包含了很多Hadoop生態(tài)圈的其他組件。我們?cè)谧鋈杭?guī)劃的時(shí)候往往還需要考慮HBase,Impala和Solr等。它們都會(huì)運(yùn)行在DataNode上運(yùn)行,從而保證數(shù)據(jù)的本地性。
HBase是一個(gè)可靠的,列存儲(chǔ)數(shù)據(jù)庫(kù),提供一致的,低延遲的隨機(jī)讀/寫(xiě)訪問(wèn)。Cloudera Search通過(guò)Solr實(shí)現(xiàn)全文檢索,Solr是基于Lucene,CDH很好的集成了Solr Cloud和Apache Tika,從而提供更多的搜索功能。Apache Impala則可以直接運(yùn)行在HDFS和HBase之上,提供交互式的低延遲SQL查詢,避免了數(shù)據(jù)的移動(dòng)和轉(zhuǎn)換。
由于GC超時(shí)的問(wèn)題,建議的HBase RegionServer的heap size大小一般為16GB,而不是簡(jiǎn)單的越大越好。為了保證HBase實(shí)時(shí)查詢的SLA,可以通過(guò)Cgroups的的方式給HBase分配專門的靜態(tài)資源。
Impala是內(nèi)存計(jì)算引擎,有時(shí)可以用到集群80%以上的內(nèi)存資源,因此如果要使用Impala,建議每個(gè)節(jié)點(diǎn)至少有128GB的內(nèi)存。當(dāng)然也可以通過(guò)Impala的動(dòng)態(tài)資源池來(lái)對(duì)查詢的內(nèi)存或用戶進(jìn)行限制。
Cloudera Search在做節(jié)點(diǎn)規(guī)劃時(shí)比較有趣,你可以先在一個(gè)節(jié)點(diǎn)安裝Solr,然后裝載一些文檔,建立索引,并以你期望的方式進(jìn)行查詢。然后繼續(xù)裝載,直到索引建立以及查詢響應(yīng)超過(guò)了你的預(yù)期,這個(gè)時(shí)候你就需要考慮擴(kuò)展了。單個(gè)節(jié)點(diǎn)Solr的這些數(shù)據(jù)可以給你提供一些規(guī)劃時(shí)的參考,但不包括復(fù)制因子因素。
6.總結(jié)
選擇并采購(gòu)Hadoop硬件時(shí)需要一些基準(zhǔn)測(cè)試,應(yīng)用場(chǎng)景測(cè)試或者Poc,以充分了解你所在企業(yè)的工作負(fù)載情況。但Hadoop集群也支持異構(gòu)的硬件配置,所以如果在不了解工作負(fù)載的情況下,建議選擇較為均衡的硬件配置。還需要注意一點(diǎn),Hadoop平臺(tái)往往都會(huì)使用多種組件,資源的使用情況往往都會(huì)不一樣,專注于多租戶的設(shè)計(jì)包括安全管理,資源隔離和分配,將會(huì)是你成功的關(guān)鍵。














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論