 圖書館機器人利用視覺進行書脊識別問題展開研究
圖書館機器人利用視覺進行書脊識別問題展開研究
針對無人圖書館中機器人利用視覺進行書脊識別問題展開研究。根據書脊圖像本身較復雜、單本書輪廓難以提取的特點,提出了運用小波分析作書脊輪廓增強的圖像預處理方案,通過實驗比較了運用Sobel算子和Canny算子法作書脊輪廓檢測的效果,用累計概率霍夫變換法作書脊線段查找,用VC++和OpenCV開發了應用程序,借鑒模糊計算思想,針對厚、較厚、中等厚度、較薄、薄、混合等幾種類型的書脊進行了分類試驗和研究,再經輔助優化處理,基本可有效識別出不同情況下每本書的書脊輪廓,檢測出每本書的厚度,為機械手利用視覺進行圖書取放操作奠定了基礎。
1 引言
目前,世界上成功應用圖書館機器人的有德國洪堡大學、美國猶他州大學、日本早稻田大學等,這些圖書館機器人的應用大大節省了圖書管理成本,同時使讀者借還圖書更加便捷。2002年,美國Johns Hopkins大學的Jackrit Suthakom等人研制了一種完整意義上的圖書館機器人實驗裝置,它由移動機器人、機械手及其升降裝置、攝像頭等幾部分組成,可以實現圖書的自動存取。同年,新加坡國立大學KHO.Hao Yuan等人研究了基于RFID定位技術的無人化圖書館系統,可利用機器人完成圖書存取工作。以往圖書館機器人的研究已經很好的解決了機器人圖書搬運、裝卸及輔助圖書管理員完成圖書管理等工作,但在圖書上下架時機械手如何利用機器視覺進行書脊正確快速識別問題并未得到很好的解決[1-4]。書脊視覺識別的難點在于書脊圖像本身比較復雜,每本書的輪廓與圖像細節部分不易區分,且在實際應用中,機械手與書脊之間存在相對運動,這也給視覺識別增加了難度。美國的D. J. Lee等人對自動化圖書館中書脊的視覺識別問題曾進行過深入的探討[5]。本文結合實際項目,針對書脊視覺識別的特點,將小波分析、Hough變換等多種算法相結合,提出一種新的書脊視覺識別方法,該方法的有效性已在實驗中得到較好的驗證。
2機器人視覺識別系統框架
機械手移動到確定的位置區間后,便可利用視覺系統通過圖像處理算法精確識別出每本書的厚度,進而完成機械手的抓取操作。
通過反復實驗,確定出如圖1所示的圖書視覺識別流程:

Figure 1 Book-Spine Visual Recognition Process
圖1書脊視覺識別流程
圖像采集時本系統選擇的是MDC-D80 2 自由度云臺攝像機,470 線高分辨率,采用SONY HAD CCD,10倍光學變焦,可通過RS-232控制,標準視頻輸出;旋轉120度/秒,俯仰60度/秒,具有自動回復中位功能。
3 運動圖像去模糊處理
由于機械手靠近書架時與書之間存在相對運動,因此會造成獲取的圖像模糊。本系統中機械手的運動速度并不要求很快且可以通過控制使其保持勻速,因此模糊后圖像f(x,y)上任意點的值為
將模糊圖像近似認為是由攝像機在x方向上作水平勻速直線運動引起的,上式可簡化為
將機械手攝像機拍攝到的書脊圖像信號近似看作平穩隨機過程。Wienier濾波器的基本原理是將原始圖像f和對原始圖像的估計看作隨機變量,按照使f和對估計值之間的均方誤差達到最小的準則實現圖像復原。運用Wienier濾波去書脊圖像模糊,結果如圖2所示:


(a)運動造成的模糊圖像 (b)Wienier濾波去圖像模糊
Figure 2Experimental Results of Eblurringby Wienier Filter
圖2 Wienier濾波去書脊圖像模糊實驗效果圖
實驗表明,運用Wienier濾波時運動位移和運動角度兩個參數需根據機械手的實際運動情況合理設置,才可得到好的濾波結果。
4 小波分析法增強書脊輪廓
4.1 小波圖像分解原理
設Vk為張量積多分辨率分析,Wk為小波空間。圖像為f(x,y),f(x,y)L2(R2),fN(x,y)是f(x,y)在空間VN中的投影。對fk(x,y)Vk與gk(x,y)Wk,有[6]
fk+1(x,y) = fk(x,y) + gk(x,y)
而gk(x,y)Wk還可進一步分解為
gk= gk(1)+ gk(2)+ gk(3)
其中,,i=1,2,3。
設{al,j}{}(i=1,2,3)是由兩個一元分解序列生成的二元分解序列
記
則圖像分解算法為
圖像分解示意圖如圖3所示:
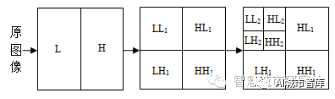
Figure 3Two Level Wavelet Decompositionof Pictures
圖3 圖像小波兩層分解
可得重構算法為
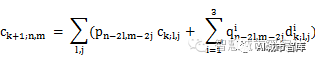
圖像作小波變換后,可得到一系列不同分辨率的子圖像,不同子圖像對應的頻率不同。
4.2 設計與實驗
小波變換將一幅圖像分解為大小、位置、方向均不相同的分量,圖像經二維小波分解后,輪廓主要體現在低頻部分,細節主要體現在在高頻部分[7]。由于機械手抓取圖書時需要知道的是每本書的厚度,因此在作圖像識別時應更多關注書脊的外部輪廓而非書脊上的文字細節信息。這可以通過對圖像作小波增強處理來實現,本系統的做法是:對書脊圖像進行2層分解,對分解系數進行處理,即使低頻分解系數增強以突出輪廓,高頻分解系數衰減以弱化細節,再對處理后的系數進行小波重構,最終得到輪廓增強的圖像。為得到理想的圖像,小波分解系數的閾值選取是關鍵,即如何界定高低頻分解系數問題。設系數閾值為T。對大于T的系數進行加權處理,設此權值為;對小于T的系數也進行加權處理,設此權值為。書脊輪廓增強實驗效果如圖4所示:

圖4小波書脊輪廓增強實驗效果
比較處理后的圖像效果可知,系數閾值的大小對圖像的灰度有直接影響,權值的選擇對輪廓與細節的保留程度有影響,只有在適中的情況下,才可獲得想要的結果。選擇圖4中(e)作為進一步檢測和識別的對象。
5視覺檢測與識別實驗5.1 書脊邊緣檢測實驗
機器人圖書視覺檢測系統對邊緣檢測的要求是:
(1)能檢測出預抓取的目標書籍的完整外部輪廓;
(2)盡可能少檢測出書脊上文字的輪廓;
(3)對當前機器視野中所有書脊的輪廓能夠很好的區分開。
圖5為調整到最佳閾值后對同一幅圖像分別用Sobel算子和Canny算子所做的書脊邊緣檢測效果。

(a)原始圖像 (b)Sobel算子 (c)Canny算子
Figure 5 Experimental Results of Book-Spine Edge Detection
圖5書脊邊緣檢測實驗效果圖
比較后發現,運用Canny算子對書脊邊緣進行檢測的效果更好,可以更加完整的檢測出書脊輪廓,有利于后續的Hough算法提取書脊線段。除邊緣檢測算法外,檢測效果與攝像機拍攝圖像時的位置及拍攝到的圖像角度、范圍都有關。
Canny 算法采用雙閾值法從候選邊緣點中檢測和連接出最終的邊緣。OpenCV中通過函數cvCanny訪問Canny算子邊緣檢測算法,其函數原型為cvCanny( const CvArr* image, CvArr* edges, double threshold1, double threshold2, int aperture_size ),參數threshold1為第一個閾值,參數threshold2為 第二個閾值。運用Canny算子對書脊進行邊緣檢測時應恰當設置閾值參數,閾值設置的目的是盡量使圖像的細節部分邊緣減少,盡可能多的保留每本書的外部輪廓邊緣,以利于外部輪廓的直線查找。圖6是選用不同閾值時的邊緣檢測效果,顯然(b)的閾值設定值更符合圖像分割需求。
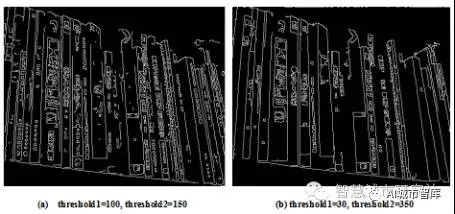
Figure 6 CannyAlgorithm Threshold Setting Results Compare
圖6Canny算法閾值設定結果比較
通過實驗“試湊法”得到合理的Canny算法閾值是一種有效方法,但對于動態的移動機器人視覺系統來講并不實用。移動機器人視覺系統應能在每次采集圖像并進行預處理時自適應的調整邊緣檢測算法的閾值。常用的自適應閾值選取方法有:雙峰法、迭代法、大津法(OTSU法)及其改進算法。在以上實驗的基礎上,本文采用迭代法選取最佳閾值,解決不同書脊圖像分割時的閾值自動切換與識別問題。迭代法的公式是:

迭代法的實現步驟是:
(1)根據實驗結果求出圖像的最大灰度值和最小灰度值,分別記為ZMAX和ZMIN,令初始閾值T0=(ZMAX+ZMIN)/2;
(2)根據閾值Ti(i=0,1,2,…)將圖象分割為前景和背景,分別求出兩者的平均灰度值ZO和ZB;
(3)求出新閾值Ti+1=(ZO+ZB)/2;
(4)若Ti =Ti+1,則所得即為閾值;否則轉2,迭代計算直至迭代收斂于某個穩定的閾值時,此閾值即為最終結果。
5.2書脊線段查找實驗
本系統采用累計概率霍夫變換(PPHT)算法實現書脊線段的查找。
采用霍夫變換檢測直線,其基本思想是利用點-線的對偶性,點-線在兩個坐標系中的對偶關系如圖7所示:

Figure 7Hough Transform for Line Detection Principle
圖7 霍夫變換檢測直線原理
Hough變換采用一種“投票機制”,輸入空間(x-y空間)中的每一個點對對應的輸出空間(p-q空間)的某些參數組合(由q,p組成的數組)進行投票,獲得票數最多的參數組合(如某對(p,q)值)勝出。
在OpenCV中通過函數cvHoughLines2訪問PPHT算法。cvHoughLines2的函數原型是:
CvSeq* cvHoughLines2(CvArr* image, void* line_storage,int method,double rho,doubletheta,int threshold,double param1, double param2 )[8]。將參數method設置成CV_HOUGH_PROBABILISTIC 表示選擇PPHT算法。實驗表明,參數threshold、param1、param2 的設置對檢測結果有直接影響,恰當的配置這些參數才可得到能使機械手臂準確定位的目標圖像。Threshold是閾值參數,如果相應的累計值大于 threshold, 則認定為一條直線。param1設置將要返回的線段的最小長度,param2表示在同一條直線上進行碎線段連接的最大間隔值(gap), 即當同一條直線上的兩條碎線段之間的間隔小于param2時,將其合二為一。
圖8為修改各參數時值得到的不同檢測結果(為簡便,用f1表示原始圖像,用f2表示小波輪廓增強后的圖像,th表示threshold,p1表示param1,p2表示param2):
Figure 8 Parameter Selection Experiments byPPHT Aalgorithm
圖8PPHT算法參數選擇實驗
實驗結果表明,Threshold固定時,當param2偏大時,Hough變換連成的直線太多,很多直線是不想要的,這些直線的干擾使書脊邊界無法提取;當param2偏小時,連成的直線又太少,檢測不出相對較長的書脊直線,也不好提取書脊邊界。Threshold的設置對書脊的判定影響較大。由于該圖書館機器人工作在自主作業模式,因此需根據作業對象自適應的調整Threshold的設定值以達到環境適應性強的目的。為加快系統計算速度,這里仍采用迭代法自適應的設定閾值參數。
5.3 識別結果優化處理
攝像頭拍攝角度、距離以及書本身的高度不等等客觀事實會帶來所拍攝圖像的某些區域檢測結果有較大失真,此時應放棄對此部分區域的處理結果,圈定出檢測效果相對完善的區域,即能夠有效分離出每一本書并確定出每一本書厚度的區域,將此區域定義為有效檢測區域,如圖9中矩形R所包圍的區域。在有效檢測區域內再做下一步的計算與處理。
進一步的計算與處理包括兩個方面:1)在有效檢測區域中劃出虛擬的兩條線段a和b,使a、b之間為最有利于提取出書脊直線特征的區域。2)消除多余線段帶來的檢測誤差,如圖中書脊上的文字可能被誤檢測成書之間的分割線段(圖中的線段①、②),這會給機械手控制器發出抓取指令時帶來強干擾,解決此問題的方法是:對同一幅圖像進行多次采集,將每次的處理結果相比較,采用表決融合準則,降低誤判率。為減少計算量,最多采集3次。
為驗證方法的有效性和普遍適用性,借鑒模糊智能計算思想,對書脊厚度類別作如下模糊劃分:{厚、較厚、中等厚度、較薄、薄、混合},其中“混合”是指厚、薄書脊隨機混放情況。在以上6種情況下分別采集不同書脊圖像100幅,用文中提出的方法進行書脊識別試驗,得到書脊位置有效檢出率分類統計結果,如表1所示。
Table 1 Storage space analysis of OBDDs data structure (Byte)
表1 書脊位置有效檢出率分類統計表
| 厚度類別 | 霍夫變換的閾值 | 有效檢出率(%) | 耗時(s) |
| 厚(每本書厚度>1000頁) | 50 | 100 | 1.0 |
| 較厚(500<=每本書厚度<=1000頁) | 50 | 99 | 1.2 |
| 中等厚度(300<=每本書厚度<500頁) | 60 | 95 | 1.8 |
| 較薄(100<=每本書厚度<300頁) | 60 | 90 | 1.9 |
| 薄(每本書厚度<100頁) | 80 | 85 | 2.0 |
| 混合(厚、薄隨機混放) | 80 | 70 | 2.5 |
從表1中可看出,當書脊厚度較大且均勻時,有效檢出率較高,且算法耗時較少,基本可滿足魯棒實時識別的需求;當書脊厚度較小且均勻時,有效檢出率相對低一些,但仍能滿足實時識別需求;當書脊厚度不一即隨機混合時,檢出率最低 ,耗時也最大,這種情況為最難識別的極端情況。
6 結束語
圖書館機器人機械手的圖書識別問題實際上屬于攝像機運動、目標靜止的移動機器人視覺系統問題,這也是目前運動視覺研究的一個重要方向。常用的處理方法是分析運動過程中獲得的圖像序列,可能是對某一感興趣區域的各個角度的觀察圖像序列,來建立目標的3D結構信息[9]。考慮到此種方法在程序處理時的復雜性,本文采取了一種新型綜合處理方法,實驗結果已充分表明,該方法可通過編程實現,且計算量較小、識別率較高、實時性較強,已成功應用到我們研制的圖書館機器人裝置中。
-
機器人
+關注
關注
211文章
28512瀏覽量
207505 -
Canny
+關注
關注
0文章
14瀏覽量
9709
原文標題:杜明芳 | 基于小波分析的無人圖書館機器視覺識別研究
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人大模型
【「具身智能機器人系統」閱讀體驗】+初品的體驗
如何保障圖書館用電安全?——安科瑞 丁佳雯

智慧圖書館能耗監測優化管理系統方案
聚徽-什么是智能圖書館
OBOO鷗柏智能化臥式觸控查詢一體機在大學圖書館的創新應用案例展覽展示

工業機器人視覺技術的應用分為哪幾種?
雷拓科技云廣播助力江西省蘆溪縣新圖書館打造沉浸式觀展體驗!
基于FPGA EtherCAT的六自由度機器人視覺伺服控制設計
視覺機器人焊接的研究現狀

如果通過物聯網技術提升學校圖書館管理水平
RFID智能書架:圖書館智能化管理的新趨勢
淺談限流式保護器在高校圖書館電氣火災預防中的應用
基于智能定位功能的座位預約卡 解決圖書館找座難題的理想方案






 工商網監
工商網監
評論