 深度學習全新打開方式Google Brain提出概念激活向量新方法
深度學習全新打開方式Google Brain提出概念激活向量新方法
可解釋性仍然是現代深度學習應用的最大挑戰之一。計算模型和深度學習研究的最新進展使我們能夠創建極度復雜的模型,包括數千隱藏層和數千萬神經元。效果驚人的前沿深度神經網絡模型構建相對簡單,但了解這些模型如何創造和使用知識仍然是一個挑戰。
最近,Google Brain團隊的研究人員發表了一篇論文,提出了一種名為概念激活向量(Concept Activation Vectors, CAV)的新方法,它為深度學習模型的可解釋性提供了一個新的視角。
可解釋性 vs 準確性
要理解CAV技術,需要了解深度學習模型中可解釋性難題的本質。在當今一代深度學習技術中,模型的準確性與可解釋性之間存在著永恒的矛盾。可解釋性-準確性矛盾存在于完成復雜知識任務的能力和理解這些任務是如何完成能力之間。知識與控制,績效表現與可核查性,效率與簡便性...任意一項抉擇其實都是準確性和可解釋性之間的權衡。
你是關心獲得最佳結果,還是關心結果是如何產生的?這是數據科學家在每個深度學習場景中都需要回答的問題。許多深度學習技術本質上非常復雜,盡管它們在許多場景中都很準確,解釋起來卻非常困難。如果我們在一個準確性-可解釋性圖表中繪制一些最著名的深度學習模型,我們將得到以下結果:
深度學習模型中的可解釋性不是一個單一的概念。我們可以從多個層次理解它:
要得到上圖每層定義的可解釋性,需要幾個基本的構建模塊。在最近的一篇論文中,谷歌的研究人員概述了他們看來的一些可解釋性的基本構建模塊。
Google總結了如下幾項可解釋性原則:
- 了解隱藏層的作用:深層學習模型中的大部分知識都是在隱藏層中形成的。在宏觀層面理解不同隱藏層的功能對于解釋深度學習模型至關重要。
- 了解節點的激活方式:可解釋性的關鍵不在于理解網絡中各個神經元的功能,而在于理解同一空間位置被一起激發的互連神經元群。通過互連神經元群對神經網絡進行分割能讓我們從一個更簡單的抽象層面來理解其功能。
-理解概念的形成過程:理解深度神經網絡如何形成組成最終輸出的單個概念,這是可解釋性的另一個關鍵構建模塊。
這些原則是Google新CAV技術背后的理論基礎。
概念激活向量
遵循前文討論的想法,通常所認為的可解釋性就是通過深度學習模型的輸入特征來描述其預測。邏輯回歸分類器就是一個典型的例子,其系數權重通常被解釋為每個特征的重要性。然而,大多數深度學習模型對諸如像素值之類的特征進行操作,這些特征與人類容易理解的高級概念并不對應。此外,模型的內部值(例如,神經元激活)也很晦澀難懂。雖然諸如顯著圖之類的技術可以有效測量特定像素區域的重要性,但是它們無法與更高層級的概念相關聯。
CAV背后的核心思想是衡量一個概念在模型輸出中的相關性。概念的CAV就是一組該概念的實例在不同方向的值(例如,激活)構成的向量。在論文中,Google研究團隊概述了一種名為Testing with CAV(TCAV)的線性可解釋方法,該方法使用偏導數來量化預測CAV表示的潛在高級概念的敏感度。他們構想TCAV定義有四個目標:
- 易懂:使用者幾乎不需要機器學習專業知識。
- 個性化:適應任何概念(例如,性別),并且不限于訓練中涉及的概念。
- 插入即用:無需重新訓練或修改機器學習模型即可運作。
- 全局量化:可以使用單一定量測度來解釋所有類或所有實例,而非僅僅解釋單個數據輸入。
為實現上述目標,TCAV方法分為三個基本步驟:
1)為模型定義相關概念。
2)理解預測對這些概念的敏感度。
3)推斷每個概念對每個模型預測類的相對重要性的全局定量解釋。
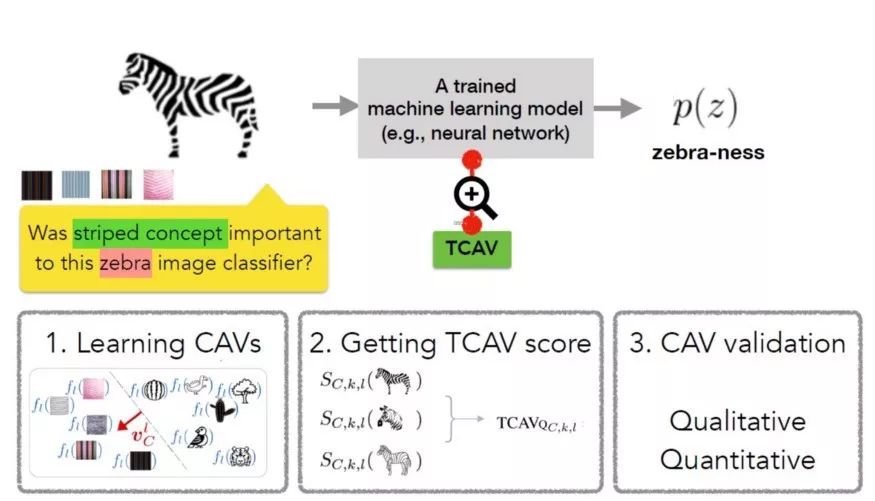
TCAV方法的第一步是定義相關的概念(CAV)。為實現此目的,TCAV選擇一組代表該概念的實例或尋找標記為該概念的獨立數據集。我們可以通過訓練線性分類器區分概念實例產生的激活和各層中的實例來學習CAV。
第二步是生成一個TCAV分數,用于量化預測對特定概念的敏感度。TCAV使用了用于衡量ML預測值在某一概念方向、在激活層對輸入敏感度的偏導數。
最后一步嘗試評估學到的CAV的全局相關性,避免依賴不相關的CAV。畢竟TCAV技術的一個缺陷就是可能學到無意義的CAV,因為使用隨機選擇的一組圖像仍然能得到CAV,在這種隨機概念上的測試不太可能有意義。為了應對這一難題,TCAV引入了統計顯著性檢驗,該檢驗以隨機的訓練次數(通常為500次)評估CAV。其基本思想是,有意義的概念應該在多次訓練中得到一致的TCAV分數。
TCAV的運作
團隊進行了多次實驗來評估TCAV相比于其他可解釋性方法的效率。在一項最引人注目的測試中,團隊使用了一個顯著圖,嘗試預測出租車這一概念與標題或圖像的相關性。顯著圖的輸出如下所示:
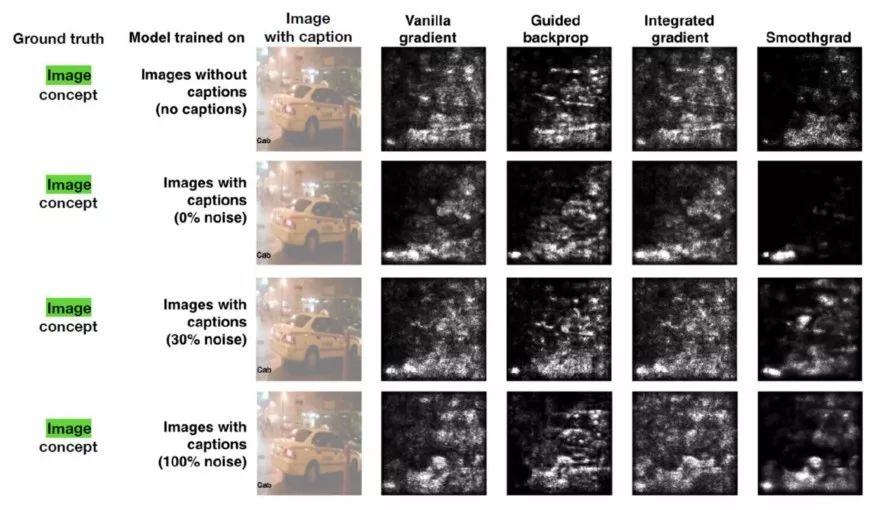
使用這些圖像作為測試數據集,Google Brain團隊在Amazon Mechanical Turk上邀請50人進行了實驗。每個實驗人員執行一系列共六個針對單個模型的隨機順序任務(3類對象 x 2種顯著圖)。
在每項任務中,實驗人員首先會看到四幅圖片和相應的顯著性蒙版。然后,他們要評估圖像對模型的重要程度(10分制),標題對模型的重要程度(10分制),以及他們對答案的自信程度(5分制)。實驗人員總共評定了60個不同的圖像(120個不同的顯著圖)。
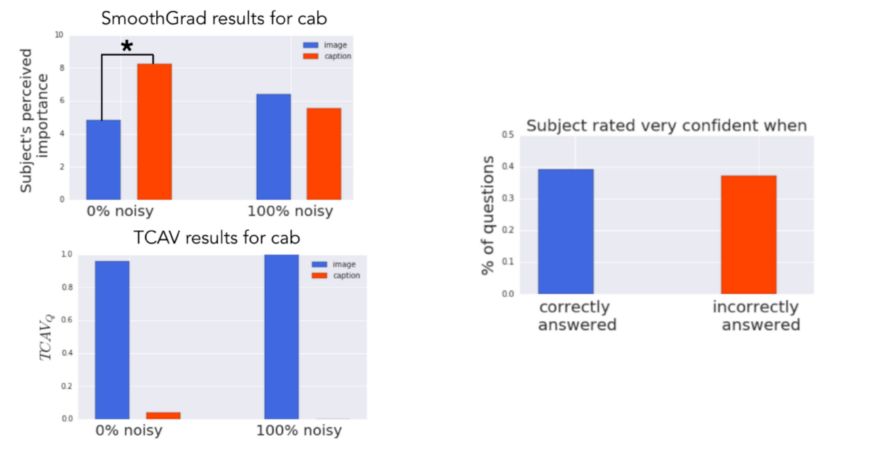
實驗的基本事實是圖像概念比標題概念更相關。然而,看顯著圖時,人們認為標題概念更重要(0%噪聲的模型),或者辨別不出差異(具有100%噪聲的模型)。相比之下,TCAV結果正確地表明圖像概念更重要。
TCAV是這幾年最具創新性的神經網絡解釋方法之一。初始的代碼可以在GitHub上看到。許多主流深度學習框架可能會在不久的將來采用這些想法。
-
谷歌
+關注
關注
27文章
6164瀏覽量
105322 -
深度學習
+關注
關注
73文章
5500瀏覽量
121117
原文標題:谷歌大腦發布概念激活向量,了解神經網絡的思維方式
文章出處:【微信號:BigDataDigest,微信公眾號:大數據文摘】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于遺傳算法的QD-SOA設計新方法

一種降低VIO/VSLAM系統漂移的新方法
大華股份榮獲2024年中國創新方法大賽一等獎
利用全息技術在硅晶圓內部制造納米結構的新方法

上海光機所提出強激光產生高能量子渦旋態電子新方法


實踐JLink 7.62手動增加新MCU型號支持新方法
NVIDIA推出全新深度學習框架fVDB
一種無透鏡成像的新方法

新品|酷暑的新打開方式:SXB3568主板






 工商網監
工商網監
評論