 關于AI芯片格局分析和介紹
關于AI芯片格局分析和介紹
如果說2016年3月份AlphaGo與李世石的那場人機大戰只在科技界和圍棋界產生較大影響的話,那么2017年5月其與排名第一的世界圍棋冠軍柯潔的對戰則將人工智能技術推向了公眾視野。阿爾法狗(AlphaGo)是第一個擊敗人類職業圍棋選手、第一個戰勝圍棋世界冠軍的人工智能程序,由谷歌(Google)旗下DeepMind公司戴密斯·哈薩比斯領銜的團隊開發,其主要工作原理是“深度學習”。
其實早在2012年,深度學習技術就已經在學術界引起了廣泛地討論。在這一年的ImageNet大規模視覺識別挑戰賽ILSVRC中,采用5個卷積層和3個全連接層的神經網絡結構AlexNet,取得了top-5(15.3%)的歷史最佳錯誤率,而第二名的成績僅為26.2%。從此以后,就出現了層數更多、結構更為復雜的神經網絡結構,如ResNet、GoogleNet、VGGNet和MaskRCNN等,還有去年比較火的生成式對抗網絡GAN。
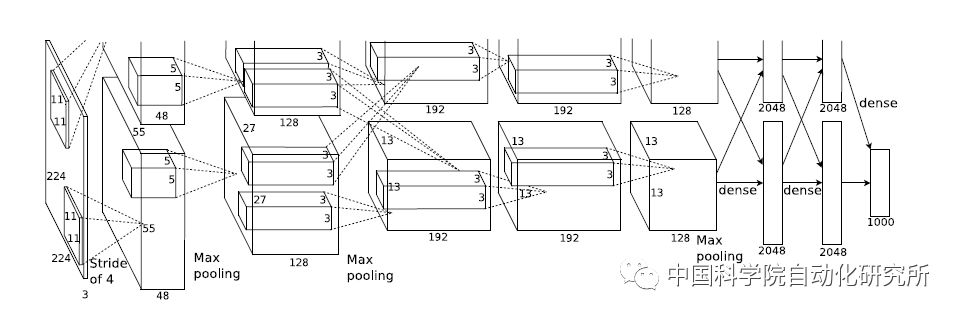
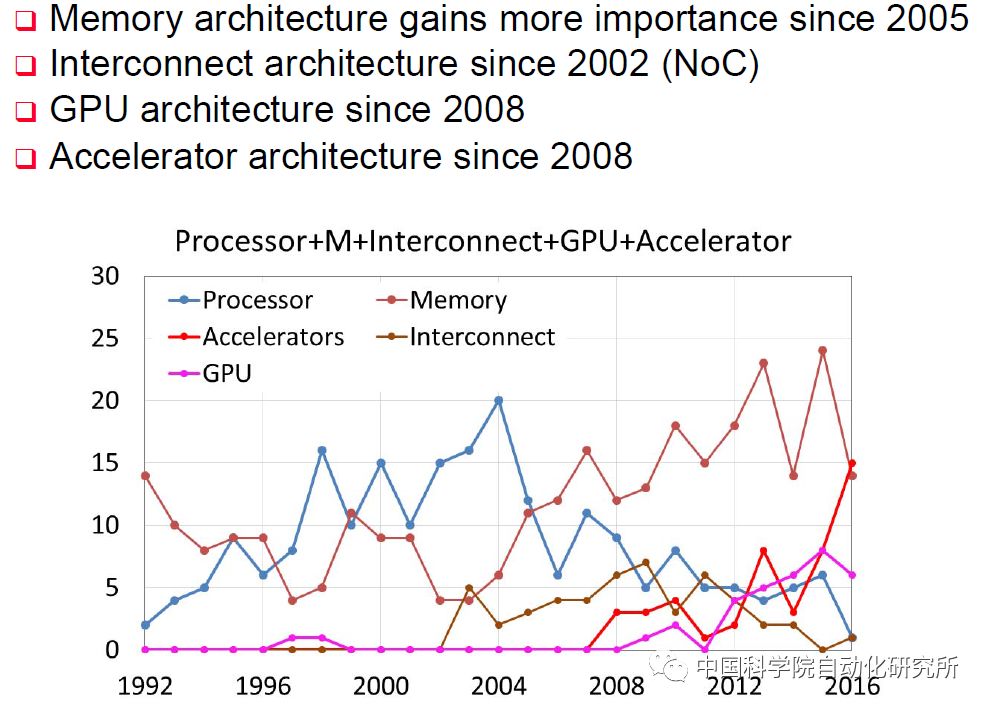
不論是贏得視覺識別挑戰賽的AlexNet,還是擊敗圍棋冠軍柯潔的AlphaGo,它們的實現都離不開現代信息技術的核心——處理器,不論這個處理器是傳統的CPU,還是GPU,還是新興的專用加速部件NNPU(NNPU是Neural Network Processing Unit的簡稱)。在計算機體系結構國際頂級會議ISCA2016上有個關于體系結構2030的小型研討會,名人堂成員UCSB的謝源教授就對1991年以來在ISCA收錄的論文進行了總結,專用加速部件相關的論文收錄是在2008年開始,而在2016年達到了頂峰,超過了處理器、存儲器以及互聯結構等三大傳統領域。而在這一年,來自中國科學院計算技術研究所的陳云霽、陳天石研究員課題組提交的《一種神經網絡指令集》論文,更是ISCA2016最高得分論文。
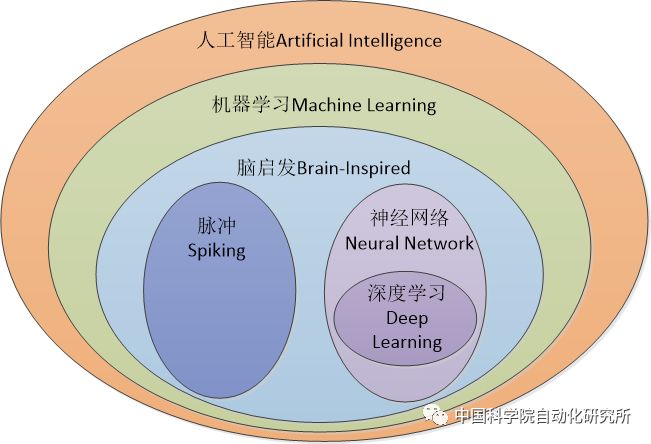
在具體介紹AI芯片國內外之前,看到這里有部分讀者或許會產生這樣的疑惑:這不都是在說神經網絡和深度學習嗎?那么我覺得有必要對人工智能和神經網絡的概念進行闡述,特別是2017年工信部發布的《促進新一代人工智能產業發展三年行動計劃(2018-2020年)》中,對發展目標的描述很容易讓人覺得人工智能就是神經網絡,AI芯片就是神經網絡芯片。
人工智能整體核心基礎能力顯著增強,智能傳感器技術產品實現突破,設計、代工、封測技術達到國際水平,神經網絡芯片實現量產并在重點領域實現規模化應用,開源開發平臺初步具備支撐產業快速發展的能力。
其實則不然。人工智能是一個很老很老的概念,而神經網絡只不過是人工智能范疇的一個子集。早在1956年,被譽為“人工智能之父”的圖靈獎得主約翰·麥卡錫就這樣定義人工智能:創造智能機器的科學與工程。而在1959年,Arthur Samuel給出了人工智能的一個子領域機器學習的定義,即“計算機有能力去學習,而不是通過預先準確實現的代碼”,這也是目前公認的對機器學習最早最準確的定義。而我們日常所熟知的神經網絡、深度學習等都屬于機器學習的范疇,都是受大腦機理啟發而發展得來的。另外一個比較重要的研究領域就是脈沖神經網絡,國內具有代表的單位和企業是清華大學類腦計算研究中心和上海西井科技等。
好了,現在終于可以介紹AI芯片國內外的發展現狀了,當然這些都是我個人的一點觀察和愚見,管窺之見權當拋磚引玉。
國外
技術寡頭,優勢明顯
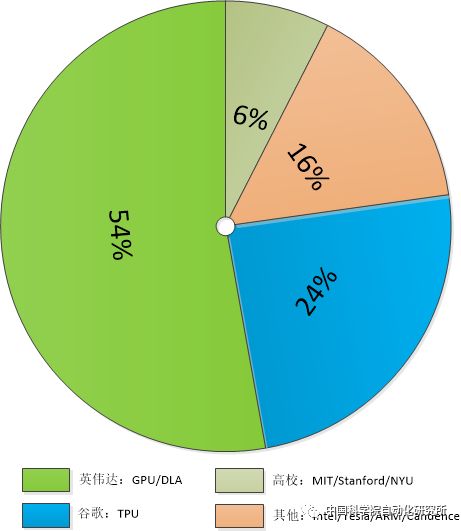
由于具有得天獨厚的技術和應用優勢,英偉達和谷歌幾乎占據了人工智能處理領域80%的市場份額,而且在谷歌宣布其Cloud TPU開放服務和英偉達推出自動駕駛處理器Xavier之后,這一份額占比在2018年有望進一步擴大。其他廠商,如英特爾、特斯拉、ARM、IBM以及Cadence等,也在人工智能處理器領域占有一席之地。
當然,上述這些公司的專注領域卻不盡相同。比如英偉達主要專注于GPU和無人駕駛領域,而谷歌則主要針對云端市場,英特爾則主要面向計算機視覺,Cadence則以提供加速神經網絡計算相關IP為主。如果說前述這些公司還主要偏向處理器設計等硬件領域,那么ARM公司則主要偏向軟件,致力于針對機器學習和人工智能提供高效算法庫。
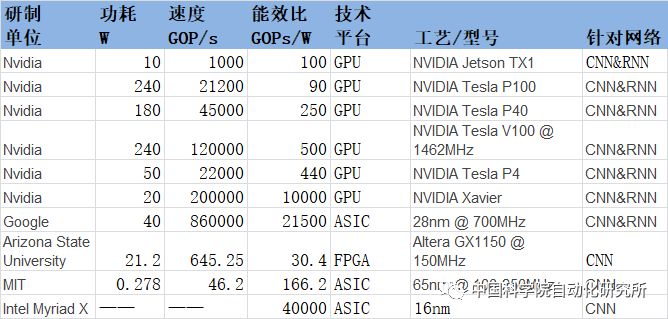
注:上述表格中所給為截止到2017年各研制單位公開可查的最新數據。
獨占鰲頭——英偉達
在人工智能領域,英偉達可以說是目前涉及面最廣、市場份額最大的公司,旗下產品線遍布自動駕駛汽車、高性能計算、機器人、醫療保健、云計算、游戲視頻等眾多領域。其針對自動駕駛汽車領域的全新人工智能超級計算機Xavier,用NVIDIA首席執行官黃仁勛的話來說就是“這是我所知道的 SoC 領域非常了不起的嘗試,我們長期以來一直致力于開發芯片。”
Xavier是一款完整的片上系統(SoC),集成了被稱為 Volta 的全新 GPU 架構、定制 8 核 CPU 架構以及新的計算機視覺加速器。該處理器提供 20 TOPS(萬億次運算/秒)的高性能,而功耗僅為 20 瓦。單個 Xavier 人工智能處理器包含 70 億個晶體管,采用最前沿的 16nm FinFET 加工技術進行制造,能夠取代目前配置了兩個移動 SoC 和兩個獨立 GPU 的 DRIVE PX 2,而功耗僅僅是它的一小部分。
而在2018年拉斯維加斯CES展會上,NVIDIA又推出了三款基于Xavier的人工智能處理器,包括一款專注于將增強現實(AR)技術應用于汽車的產品、一款進一步簡化車內人工智能助手構建和部署的DRIVE IX和一款對其現有自主出租車大腦——Pegasus的修改,進一步擴大自己的優勢。
產學研的集大成者——谷歌
如果你只是知道谷歌的AlphaGo、無人駕駛和TPU等這些人工智能相關的產品,那么你還應該知道這些產品背后的技術大牛們:谷歌傳奇芯片工程師Jeff Dean、谷歌云計算團隊首席科學家、斯坦福大學AI實驗室主管李飛飛、Alphabet董事長John Hennessy和谷歌杰出工程師David Patterson。
時至今日,摩爾定律遇到了技術和經濟上的雙重瓶頸,處理器性能的增長速度越來越慢,然而社會對于計算能力的需求增速卻并未減緩,甚至在移動應用、大數據、人工智能等新的應用興起后,對于計算能力、計算功耗和計算成本等提出了新的要求。與完全依賴于通用CPU及其編程模型的傳統軟件編寫模式不同,異構計算的整個系統包含了多種基于特定領域架構(Domain-Specific Architecture, DSA)設計的處理單元,每一個DSA處理單元都有負責的獨特領域并針對該領域做優化,當計算機系統遇到相關計算時便由相應的DSA處理器去負責。而谷歌就是異構計算的踐行者,TPU就是異構計算在人工智能應用的一個很好例子。
2017年發布的第二代TPU芯片,不僅加深了人工智能在學習和推理方面的能力,而且谷歌是認真地要將它推向市場。根據谷歌的內部測試,第二代芯片針對機器學習的訓練速度能比現在市場上的圖形芯片(GPU)節省一半時間;第二代TPU包括了四個芯片,每秒可處理180萬億次浮點運算;如果將64個TPU組合到一起,升級為所謂的TPU Pods,則可提供大約11500萬億次浮點運算能力。
計算機視覺領域的攪局者——英特爾
英特爾作為世界上最大的計算機芯片制造商,近年來一直在尋求計算機以外的市場,其中人工智能芯片爭奪成為英特爾的核心戰略之一。為了加強在人工智能芯片領域的實力,不僅以167億美元收購FPGA生產商Altera公司,還以153億美元收購自動駕駛技術公司Mobileye,以及機器視覺公司Movidius和為自動駕駛汽車芯片提供安全工具的公司Yogitech,背后凸顯這家在PC時代處于核心位置的巨頭面向未來的積極轉型。
Myriad X就是英特爾子公司Movidius在2017年推出的視覺處理器(VPU,vision processing unit),這是一款低功耗的系統芯片(SoC),用于在基于視覺的設備上加速深度學習和人工智能——如無人機、智能相機和VR / AR頭盔。Myriad X是全球第一個配備專用神經網絡計算引擎的片上系統芯片(SoC),用于加速設備端的深度學習推理計算。該神經網絡計算引擎是芯片上集成的硬件模塊,專為高速、低功耗且不犧牲精確度地運行基于深度學習的神經網絡而設計,讓設備能夠實時地看到、理解和響應周圍環境。引入該神經計算引擎之后,Myriad X架構能夠為基于深度學習的神經網絡推理提供1TOPS的計算性能。
執“能效比”之牛耳——學術界
除了工業界和廠商在人工智能領域不斷推出新產品之外,學術界也在持續推進人工智能芯片新技術的發展。
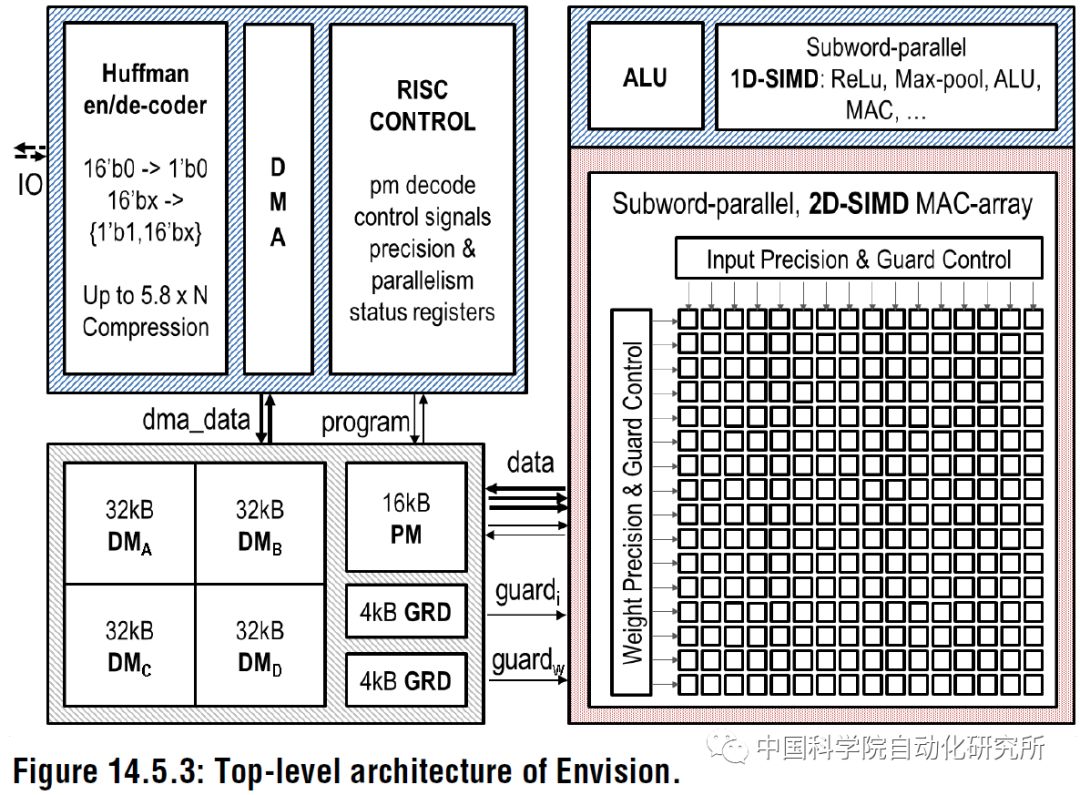
比利時魯汶大學的Bert Moons等在2017年頂級會議IEEE ISSCC上面提出了能效比高達10.0TOPs/W的針對卷積神經網絡加速的芯片ENVISION,該芯片采用28nm FD-SOI技術。該芯片包括一個16位的RISC處理器核,1D-SIMD處理單元進行ReLU和Pooling操作,2D-SIMD MAC陣列處理卷積層和全連接層的操作,還有128KB的片上存儲器。
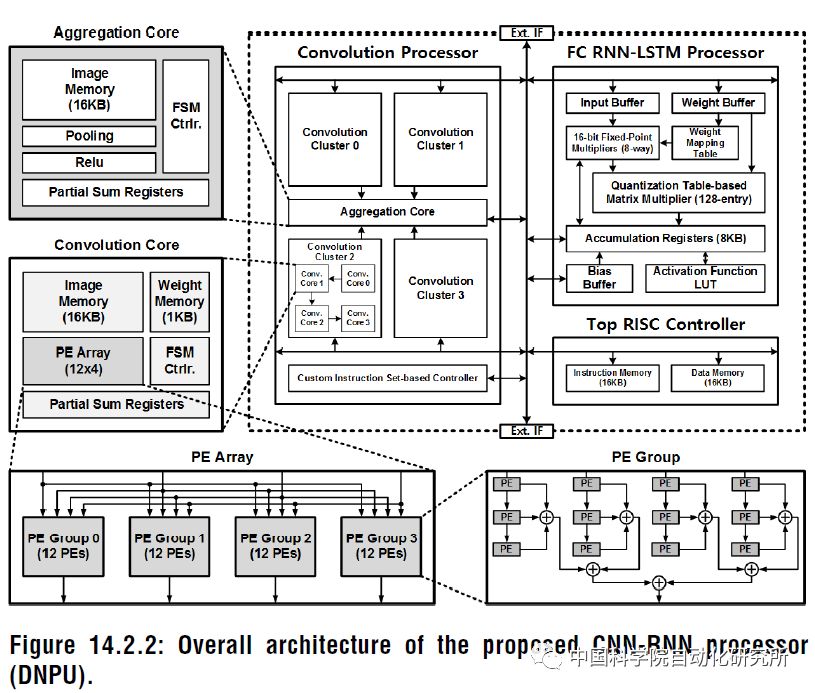
韓國科學技術院KAIST的Dongjoo Shin等人在ISSCC2017上提出了一個針對CNN和RNN結構可配置的加速器單元DNPU,除了包含一個RISC核之外,還包括了一個針對卷積層操作的計算陣列CP和一個針對全連接層RNN-LSTM操作的計算陣列FRP,相比于魯汶大學的Envision,DNPU支持CNN和RNN結構,能效比高達8.1TOPS/W。該芯片采用了65nm CMOS工藝。
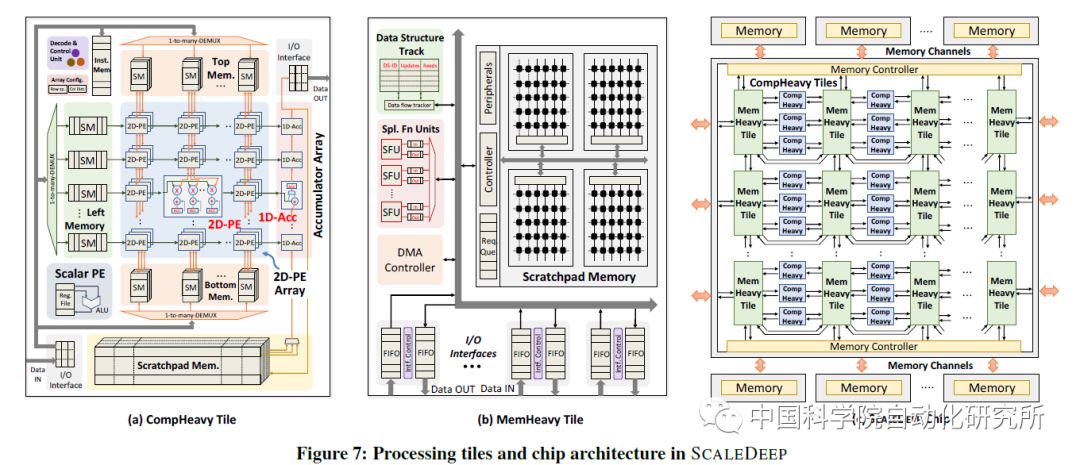
相比較于魯汶大學和韓國科學技術院都針對神經網絡推理部分的計算操作來說,普渡大學的Venkataramani S等人在計算機體系結構頂級會議ISCA2017上提出了針對大規模神經網絡訓練的人工智能處理器SCALLDEEP。
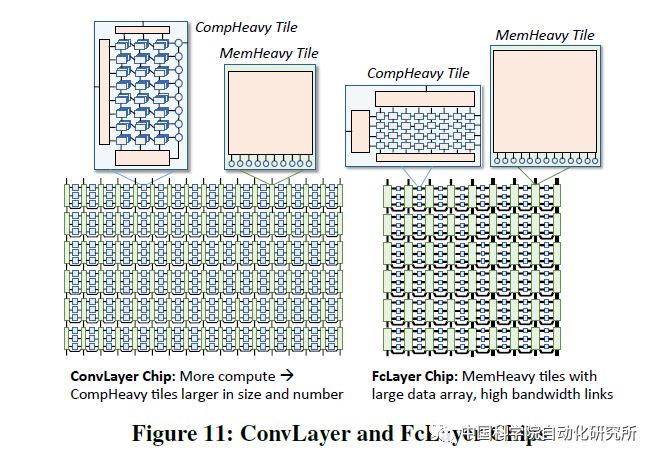
該論文針對深度神經網絡的訓練部分進行針對性優化,提出了一個可擴展服務器架構,且深入分析了深度神經網絡中卷積層,采樣層,全連接層等在計算密集度和訪存密集度方面的不同,設計了兩種處理器core架構,計算密集型的任務放在了comHeavy核中,包含大量的2D乘法器和累加器部件,而對于訪存密集型任務則放在了memHeavy核中,包含大量SPM存儲器和tracker同步單元,既可以作為存儲單元使用,又可以進行計算操作,包括ReLU,tanh等。而一個SCALEDEEP Chip則可以有不同配置下的兩類處理器核組成,然后再組成計算簇。
論文中所用的處理平臺包括7032個處理器tile。論文作者針對深度神經網絡設計了編譯器,完成網絡映射和代碼生成,同時設計了設計空間探索的模擬器平臺,可以進行性能和功耗的評估,性能則得益于時鐘精確級的模擬器,功耗評估則從DC中提取模塊的網表級的參數模型。該芯片僅采用了Intel 14nm工藝進行了綜合和性能評估,峰值能效比高達485.7GOPS/W。
國內
百家爭鳴,各自為政
可以說,國內各個單位在人工智能處理器領域的發展和應用與國外相比依然存在很大的差距。由于我國特殊的環境和市場,國內人工智能處理器的發展呈現出百花齊放、百家爭鳴的態勢,這些單位的應用領域遍布股票交易、金融、商品推薦、安防、早教機器人以及無人駕駛等眾多領域,催生了大量的人工智能芯片創業公司,如地平線、深鑒科技、中科寒武紀等。盡管如此,國內起步較早的中科寒武紀卻并未如國外大廠一樣形成市場規模,與其他廠商一樣,存在著各自為政的散裂發展現狀。
除了新興創業公司,國內研究機構如北京大學、清華大學、中國科學院等在人工智能處理器領域都有深入研究;而其他公司如百度和比特大陸等,2017年也有一些成果發布。
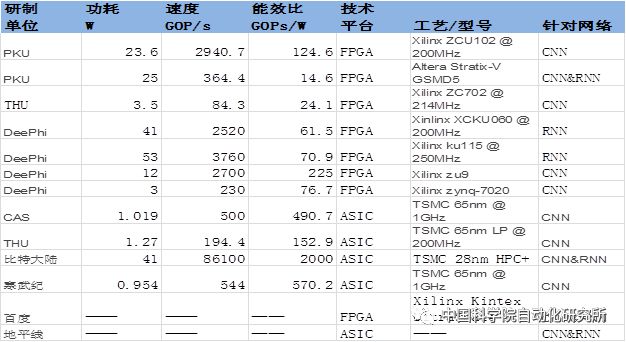
注:上述表格中所給為截止到2017年各研制單位公開可查的最新數據。
全球AI芯片界首個獨角獸——寒武紀
2017年8月,國內AI芯片初創公司寒武紀宣布已經完成1億美元A輪融資,戰略投資方可謂陣容豪華,阿里巴巴、聯想、科大訊飛等企業均參與投資。而其公司也成為全球AI芯片界首個獨角獸,受到國內外市場廣泛關注。
寒武紀科技主要負責研發生產AI芯片,公司最主要的產品為2016年發布的寒武紀1A處理器(Cambricon-1A),是一款可以深度學習的神經網絡專用處理器,面向智能手機、無人機、安防監控、可穿戴設備以及智能駕駛等各類終端設備,在運行主流智能算法時性能功耗比全面超越傳統處理器。目前已經研發出1A、1H等多種型號。與此同時,寒武紀也推出了面向開發者的寒武紀人工智能軟件平臺 Cambricon NeuWare,包含開發、調試和調優三大部分。
軟硬件協同發展的典范——深鑒科技
深鑒科技的聯合創始人韓松在不同場合曾多次提及軟硬件協同設計對人工智能處理器的重要性,而其在FPGA領域頂級會議FPGA2017最佳論文ESE硬件架構就是最好的證明。該項工作聚焦于使用LSTM 進行語音識別的場景,結合深度壓縮(Deep Compression)、專用編譯器以及 ESE 專用處理器架構,在中端的 FPGA 上即可取得比 Pascal Titan X GPU 高 3 倍的性能,并將功耗降低 3.5 倍。
在2017年10月的時候,深鑒科技推出了六款AI產品,分別是人臉檢測識別模組、人臉分析解決方案、視頻結構化解決方案、ARISTOTLE架構平臺,深度學習SDK DNNDK、雙目深度視覺套件。而在人工智能芯片方面,公布了最新的芯片計劃,由深鑒科技自主研發的芯片“聽濤”、“觀海”將于2018年第三季度面市,該芯片采用臺積電28nm工藝,亞里士多德架構,峰值性能 3.7 TOPS/W。
對標谷歌TPU——比特大陸算豐
作為比特幣獨角獸的比特大陸,在2015年開始涉足人工智能領域,其在2017年發布的面向AI應用的張量處理器算豐Sophon BM1680,是繼谷歌TPU之后,全球又一款專門用于張量計算加速的專用芯片(ASIC),適用于CNN / RNN / DNN的訓練和推理。
BM1680單芯片能夠提供2TFlops單精度加速計算能力,芯片由64 NPU構成,特殊設計的NPU調度引擎(Scheduling Engine)可以提供強大的數據吞吐能力,將數據輸入到神經元核心(Neuron Processor Cores)。BM1680采用改進型脈動陣列結構。2018年比特大陸將發布第2代算豐AI芯片BM1682,計算力將有大幅提升。
百家爭鳴——百度、地平線及其他
在2017年的HotChips大會上,百度發布了XPU,這是一款256核、基于FPGA的云計算加速芯片,用于百度的人工智能、數據分析、云計算以及無人駕駛業務。在會上,百度研究員歐陽劍表示,百度設計的芯片架構突出多樣性,著重于計算密集型、基于規則的任務,同時確保效率、性能和靈活性的最大化。
歐陽劍表示:“FPGA是高效的,可以專注于特定計算任務,但缺乏可編程能力。傳統CPU擅長通用計算任務,尤其是基于規則的計算任務,同時非常靈活。GPU瞄準了并行計算,因此有很強大的性能。XPU則關注計算密集型、基于規則的多樣化計算任務,希望提高效率和性能,并帶來類似CPU的靈活性。
在2018年百度披露更多關于XPU的相關信息。
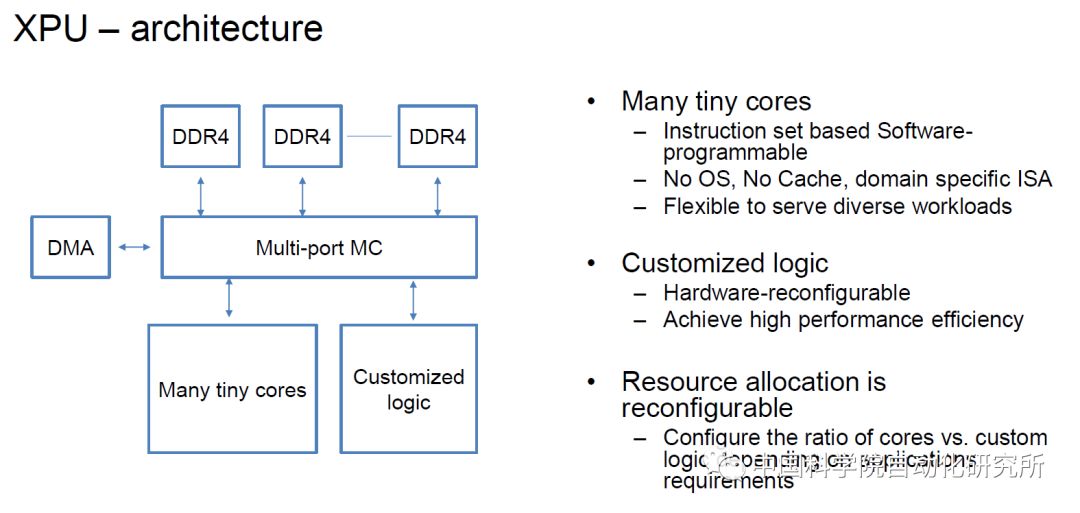
2017年12月底,人工智能初創企業地平線發布了中國首款全球領先的嵌入式人工智能芯片——面向智能駕駛的征程(Journey)1.0處理器和面向智能攝像頭的旭日(Sunrise)1.0處理器,還有針對智能駕駛、智能城市和智能商業三大應用場景的人工智能解決方案。“旭日 1.0”和“征程 1.0”是完全由地平線自主研發的人工智能芯片,具有全球領先的性能。
為了解決應用場景中的問題,地平線將算法與芯片做了強耦合,用算法來定義芯片,提升芯片的效率,在高性能的情況下可以保證它的低功耗、低成本。具體芯片參數尚無公開數據。
除了百度和地平線,國內研究機構如中國科學院、北京大學和清華大學也有人工智能處理器相關的成果發布。
北京大學聯合商湯科技等提出一種基于 FPGA 的快速 Winograd 算法,可以大幅降低算法復雜度,改善 FPGA 上的 CNN 性能。論文中的實驗使用當前最優的多種 CNN 架構(如 AlexNet 和 VGG16),從而實現了 FPGA 加速之下的最優性能和能耗。在 Xilinx ZCU102 平臺上達到了卷積層平均處理速度 1006.4 GOP/s,整體 AlexNet 處理速度 854.6 GOP/s,卷積層平均處理速度 3044.7 GOP/s,整體 VGG16 的處理速度 2940.7 GOP/s。
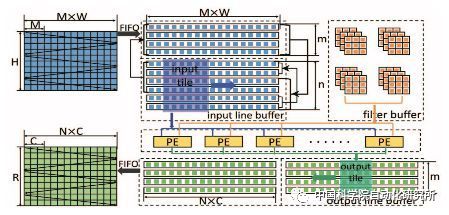
中國科學院計算機體系結構國家重點實驗室在頂級會議HPCA2017上提出了一種基于數據流的神經網絡處理器架構,以便適應特征圖、神經元和突觸等不同層級的并行計算,為了實現這一目標,該團隊對單個處理單元PE進行重新設計,使得操作數可以直接通過橫向或縱向的總線從片上存儲器獲取,而非傳統PE只能從上至下或從左至右由相鄰單元獲取。該芯片采用了TMSC 65nm工藝,峰值性能為490.7 GOPs/W。
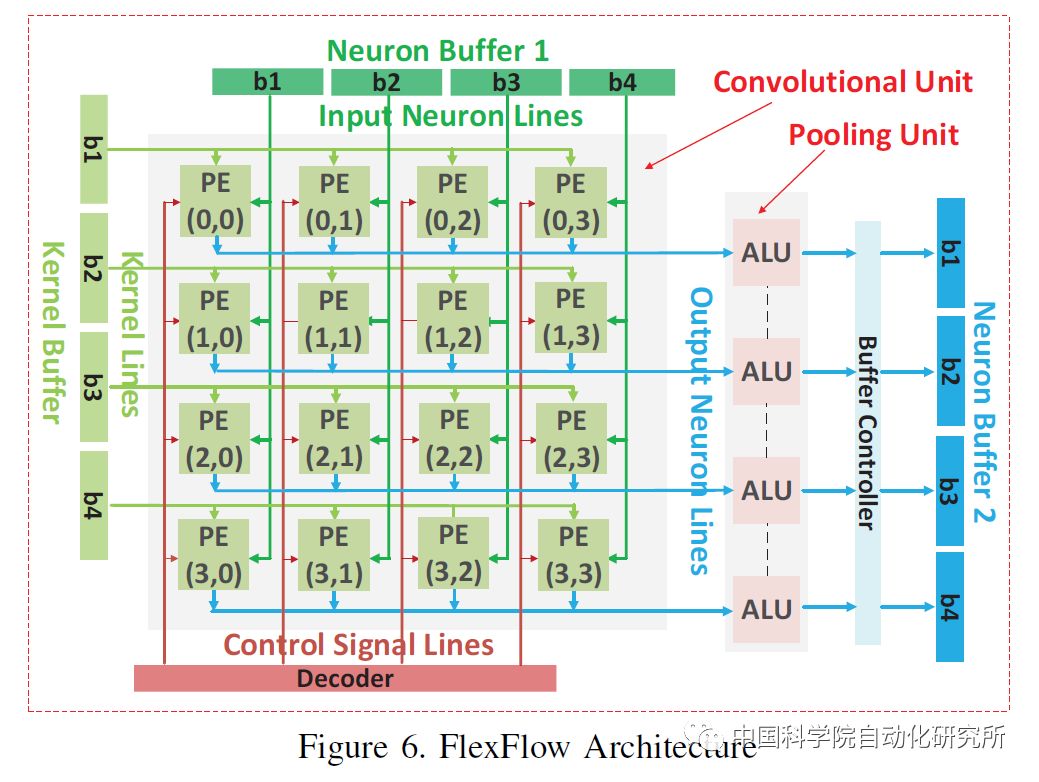
清華大學微納電子系魏少軍等2017年的VLSI國際研討會上提出了基于可重構多模態混合的神經計算芯片Thinker。Thinker芯片基于該團隊長期積累的可重構計算芯片技術,采用可重構架構和電路技術,突破了神經網絡計算和訪存的瓶頸,實現了高能效多模態混合神經網絡計算。Thinker芯片具有高能效的突出優點,其能量效率相比目前在深度學習中廣泛使用的GPU提升了三個數量級。Thinker芯片支持電路級編程和重構,是一個通用的神經網絡計算平臺,可廣泛應用于機器人、無人機、智能汽車、智慧家居、安防監控和消費電子等領域。該芯片采用了TSMC 65nm工藝,片上存儲為348KB,峰值性能為5.09TOPS/W。
新架構新技術——憶阻器
2017年清華大學微電子所錢鶴、吳華強課題組在《自然通訊》(Nature Communications)在線發表了題為“運用電子突觸進行人臉分類”(“Face Classification using Electronic Synapses”)的研究成果,將氧化物憶阻器的集成規模提高了一個數量級,首次實現了基于1024個氧化物憶阻器陣列的類腦計算。該成果在最基本的單個憶阻器上實現了存儲和計算的融合,采用完全不同于傳統“馮·諾依曼架構”的體系,可以使芯片功耗降低到原千分之一以下。憶阻器被認為是最具潛力的電子突觸器件,通過在器件兩端施加電壓,可以靈活地改變其阻值狀態,從而實現突觸的可塑性。此外,憶阻器還具有尺寸小、操作功耗低、可大規模集成等優勢。因此,基于憶阻器所搭建的類腦計算硬件系統具有功耗低和速度快的優勢,成為國際研究熱點。
在神經形態處理器方面,最為著名的就是IBM在2014年推出的TrueNorth芯片,該芯片包括4096個核心和540萬個晶體管,功耗70mW,模擬了一百萬個神經元和2.56億個突觸。而在2017年,英特爾也推出一款能模擬大腦工作的自主學習芯片Loihi,Loihi由128個計算核心構成,每個核心集成了1024個人工神經元,整個芯片擁有超過個13萬個神經元與1.3億個突觸連接,與人腦超過800億個神經元相比,簡直是小巫見大巫,Loihi的運算規模僅比蝦腦復雜一點點而已。英特爾認為該芯片適用于無人機與汽車自動駕駛,紅綠燈自適應路面交通狀況,用攝像頭尋找失蹤人口等任務。
而在神經形態芯片研究領域,清華大學類腦計算研究中心施路平等在2015年就推出了首款類腦芯片—“天機芯”,該芯片世界首次將人工神經網絡(Artificial Neural Networks, ANNs)和脈沖神經網絡(Spiking Neural Networks,SNNs)進行異構融合,同時兼顧技術成熟并被廣泛應用的深度學習模型與未來具有巨大前景的計算神經科學模型,可用于諸如圖像處理、語音識別、目標跟蹤等多種應用開發。在類腦“自行”車演示平臺上,集成32個天機一號芯片,實現了面向視覺目標探測、感知、目標追蹤、自適應姿態控制等任務的跨模態類腦信息處理實驗。據悉,基于TSMC 28nm工藝的第二代天機芯片也即將推出,性能將會得到極大提升。
從ISSCC2018看人工智能芯片發展趨勢
在剛剛結束的計算機體系結構頂級會議ISSCC2018,“Digital Systems: Digital Architectures and Systems”分論壇主席Byeong-Gyu Nam對人工智能芯片,特別是深度學習芯片的發展趨勢做了概括。深度學習依然今年大會最為熱門的話題。相比較于去年大多數論文都在討論卷積神經網絡的實現問題,今年則更加關注兩個問題:其一,如果更高效地實現卷積神經網絡,特別是針對手持終端等設備;其二,則是關于全連接的非卷積神經網絡,如RNN和LSTM等。
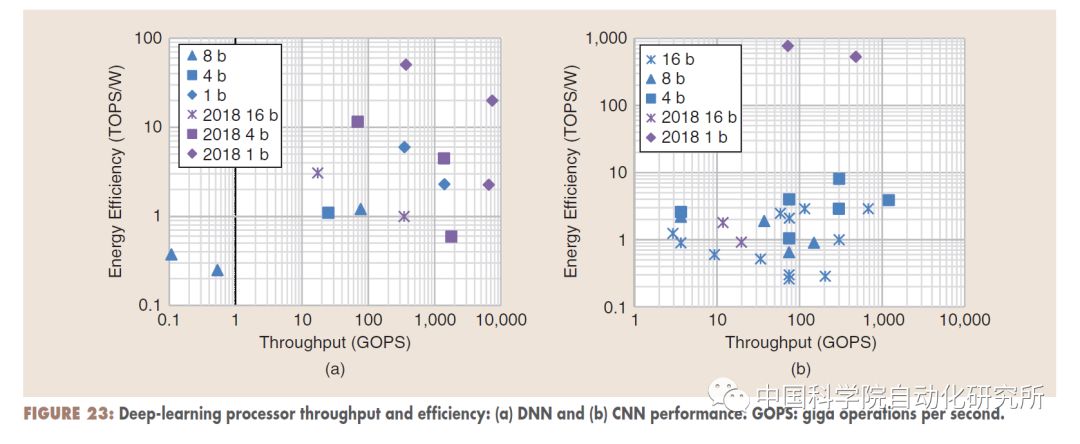
同時,為了獲得更高的能效比,越來越多的研究者把精力放在了低精度神經網絡的設計和實現,如1bit的神經網絡。這些新型技術,使得深度學習加速器的能效比從去年的幾十TOPS/W提升到了今年的上百TOPS/W。有些研究者也對數字+模擬的混合信號處理實現方案進行了研究。對數據存取具有較高要求的全連接網絡,有些研究者則借助3-D封裝技術來獲得更好的性能。
總結
對國產人工智能芯片的一點愚見
正如前文所述,在人工智能芯片領域,國外芯片巨頭占據了絕大部分市場份額,不論是在人才聚集還是公司合并等方面,都具有絕對的領先優勢。而國內人工智能初創公司則又呈現百家爭鳴、各自為政的紛亂局面;特別是每個初創企業的人工智能芯片都具有自己獨特的體系結構和軟件開發套件,既無法融入英偉達和谷歌建立的生態圈,又不具備與之抗衡的實力。
國產人工智能芯片的發展,一如早年間國產通用處理器和操作系統的發展,過份地追求完全獨立、自主可控的怪圈,勢必會如眾多國產芯片一樣逐漸退出歷史舞臺。借助于X86的完整生態,短短一年之內,兆芯推出的國產自主可控x86處理器,以及聯想基于兆芯CPU設計生產的國產計算機、服務器就獲得全國各地黨政辦公人員的高度認可,并在黨政軍辦公、信息化等國家重點系統和工程中已獲批量應用。
當然,投身于X86的生態圈對于通用桌面處理器和高端服務器芯片來說無可厚非,畢竟創造一個如Wintel一樣的生態鏈已絕非易事,我們也不可能遇見第二個喬布斯和蘋果公司。而在全新的人工智能芯片領域,對眾多國產芯片廠商來說,還有很大的發展空間,針對神經網絡加速器最重要的就是找到一個具有廣闊前景的應用領域,如華為海思麒麟處理器之于中科寒武紀的NPU;否則還是需要融入一個合適的生態圈。另外,目前大多數國產人工智能處理器都針對于神經網絡計算進行加速,而能夠提供單芯片解決方案的很少;微控制器領域的發展,ARM的Cortex-A系列和Cortex-M系列占據主角,但是新興的開源指令集架構RISC-V也不容小覷,完全值得眾多國產芯片廠商關注。
-
神經網絡
+關注
關注
42文章
4774瀏覽量
100898 -
人工智能
+關注
關注
1792文章
47428瀏覽量
238969 -
AI芯片
+關注
關注
17文章
1893瀏覽量
35102
發布評論請先 登錄
相關推薦
3D異構集成重塑芯片格局

AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第二章AI for Science的技術支撐學習心得
AI時代的芯片革命:GPU、FPGA與TPU競相涌現

2024年全球AI芯片收入將達712.52億美元

為什么用CubeIDE導入AI模型進行分析會報錯?
risc-v多核芯片在AI方面的應用

院士稱全球芯片產業格局即將重構
使用cube-AI分析模型時報錯的原因有哪些?







 工商網監
工商網監
評論