 簡要分析AI芯片的性能分析和應用介紹
簡要分析AI芯片的性能分析和應用介紹
各大半導體廠商紛紛發布了人工智能相關產品。九月初,先是華為的麒麟970集成了寒武紀的人工智能加速器IP。之后,蘋果在其發布會上展示了新一代的A11 Bionic SoC,其中集成了neural engine加速器。Imagination也不甘落后,在蘋果之后也發布了PowerVR NNA神經網絡處理器IP。九月底,Nvidia的開源深度學習加速器(DLA)正式上線,幾乎與之同時,Intel也公布了Loihi芯片。本文將盤點以上幾款產品,分析異同。
華為、蘋果、Imagination:面向手機的成熟產品發布,移動端AI時代的敲門磚
2016年初,以Eyeriss為代表的深度學習加速器芯片乘著人工智能興起的東風紛紛破土而出。目前基于深度學習的人工智能算法需要很大的計算量,而傳統CPU芯片上用于計算的ALU數目并不多,性能不足以支持深度學習算法的流暢執行。
另外,GPU雖然在云端服務器獲得大規模應用,但是一方面GPU架構的功耗太大,無法在移動端廣泛使用;另一方面GPU最適合的是深度學習訓練,在深度學習的推理應用中因為GPU基于batch運算的模式導致延遲過大,也不適合在移動端使用。
深度學習加速器目前主打的是性能和能效比,其性能能幫助深度學習的推理流暢執行,而其能效比則保證了算法加速過程中不會消耗太多電池,可以在移動端長時間使用。目前在移動領域,智能攝像頭、無人機、手機等都是深度學習加速器潛在的應用領域,其中以手機的應用市場最大。
關于深度學習加速器的用法,一般分為芯片和IP兩種。芯片的代表如Movidius的Myriad系列(以及基于Myriad芯片的neural stick產品)和,用戶可以把芯片集成到自己的系統中來做深度學習加速。然而,在BOM可謂寸土寸金的手機領域,額外加一塊芯片加速深度學習幾乎不可能,可行的做法是在手機SoC里面集成一塊深度學習加速器IP,在手機執行深度學習應用的時候可以把計算放到加速器模塊去執行。

華為、蘋果和Imagination紛紛發布人工智能加速IP
華為、蘋果和Imagination發布的深度學習加速器產品都是這樣的IP模塊。這些模塊經過長期設計和驗證,已經非常成熟,可以進入大規模生產階段。產品能進入量產階段意味著之前已經經過了長期的技術積累,正如蘋果和華為透露他們的人工智能加速IP至少在兩年前就已經立項了,可見這些手機巨頭對于人工智能的遠見和拿下市場的決心。
目前手機上的人工智能應用應該說還處于非常初期的階段,硬件和軟件屬于“先有雞還是先有蛋”的境況:在沒有深度學習加速硬件的情況下開發手機端的人工智能應用,會導致硬件限制執行速度,用戶體驗不好;
而如果沒有手機端的人工智能相關應用,硬件廠商往往就不會想到要去做專門的深度學習加速器。而華為、蘋果和Imagination推出的手機端深度學習加速器IP可謂是打破了這個僵局,成為手機端人工智能應用普及的敲門磚。
華為、蘋果和Imagination公布的加速器峰值性能分別是1.96 TOPS、0.6 TOPS和4TOPS,而實測的性能麒麟970可以到300 GOPS(執行VGG-16模型),Imagination約750 GOPS(執行GoogleNet模型),蘋果的實測數據還沒有公布,估計也是在100 GOPS的數量級。這樣的數字能夠支持基礎的深度學習算法:
目前,蘋果宣稱其A11中的neural engine主要是加速Face ID應用,而華為的展示項目則是實時物體辨識。預期在未來,這些人工智能加速器的應用場景會遠遠多于這些,同時也促成移動端人工智能應用的井噴式發展。
另一方面,我們也應該看到,100GOPS數量級的算法運行計算量更大的實時物體檢測(object detection,從畫面中同時定位并識別多個物體)還不夠流暢,因此深度學習IP還有不少進步的空間。
Nvidia DLA:為AI生態鋪路的前瞻性產品
與華為、蘋果等定制深度學習IP模塊不同,Nvidia選擇了開源其深度學習加速架構DLA。目前,DLA已經在github上發布了其RTL代碼可供編譯、仿真以及驗證,預計在未來Nvidia將進一步公布其C模型等重要設計組件。
Nvidia DLA最主要的部分是計算單元,據悉目前DLA會使用Winograd算法來減小卷積的計算開銷,同時也會使用數據壓縮技術,來減少DRAM訪問時的數據流量。
Nvidia同時給出了NVDLA構成的兩種系統,在比較復雜的大系統中, DLA的接口包括與處理器交互的IRQ/CSB,與片外DRAM交互的DBBIF,以及與SRAM交互的SRAMIF,而在小系統的例子中,則省去了SRAMIF,因為小系統中的SRAM比較寶貴可能沒有可供NVDLA使用的部分。
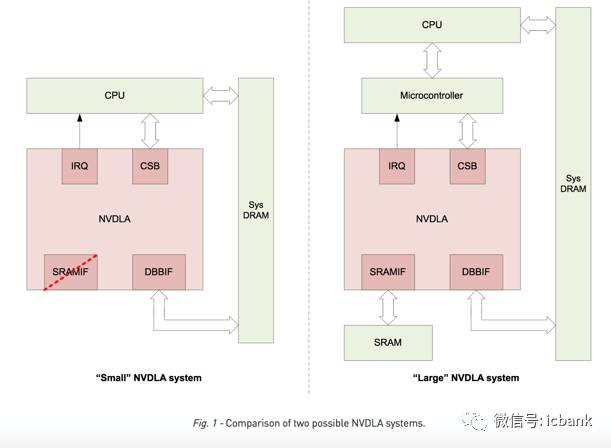
在性能方面,NVDLA在使用2048個MAC的時候可以每秒完成269次ResNet-50推理,相當于2.1TOPS的性能,當然其對于內存的帶寬要求也達到了20GB/s,接近DDR4系列的最高帶寬。

那么,Nvidia為什么選擇了開源的形態呢?通過觀察,我們不難發現目前在人工智能硬件領域,Nvidia已經成為云端人工智能加速的主宰者,而在發展潛力巨大的無人車領域,Nvidia也接連推出多款GPU產品布局,在競爭中也處于領跑地位。
在這些Nvidia具有競爭優勢的領域,Nvidia的GPU都是作為一種性能強勁的計算加速器存在的。然而,對于產品種類多樣而更適合使用SoC產品形態的移動領域,Nvidia一直沒有打開局面。
之前Nvidia曾經推出過TK系列和TX系列作為帶有深度學習和機器視覺硬件加速特性的SoC來試水移動市場,可惜這些產品的功耗都在10W左右,而且成本很高,導致一直無法占領移動端人工智能加速市場。Nvidia最擔心的恐怕就是有一家芯片廠商在移動端人工加速市場脫穎而出,由下至上挑戰Nvidia在人工智能加速硬件領域的地位。
因此,Nvidia開源其DLA加速模塊,其實是讓全球的SoC廠商幫Nvidia一起優化DLA加速模塊,并且幫助Nvidia搶占移動端市場。另一方面,開源DLA也能加速移動端人工智能加速硬件的成熟,這樣當硬件不再成為瓶頸后,移動端人工智能應用將迎來爆發。而Nvidia作為深度學習模型訓練(GPU)以及優化(TensorRT)工具鏈生態環境的實際掌控者,在移動端人工智能市場真正蓬勃發展后,即使DLA不帶來收入也能從人工智能產業鏈的上游獲得大量收益,因此開源DLA的舉動是Nvidia布局人工智能生態的重要一步。
Intel Loihi:神經擬態芯片,試驗性產品
與前述的幾家公司不同,Intel推出的Loihi是一款基于神經擬態(neuromorphic)的芯片。目前最流行的深度學習神經網絡中,神經網絡把人類的神經系統的統計行為抽象為一系列運算(高維卷積以及非線性運算)的數學系統,與真正的生物神經工作并不相同,而之前介紹的幾款產品(以及絕大多數其他人工智能加速器硬件)都是加速這類經典神經網絡結構的。
神經擬態則是幾乎完全照搬生物神經系統,試圖在模型中完全重現生物神經的工作方式(例如引入神經元電勢可以充放電,在電勢超過一定閾值后神經元就會放出電脈沖到其他相鄰的神經元)。理論上,這種神經擬態芯片可以由異步系統實現,并且有很低的功耗。然而,目前神經擬態結構如何訓練仍然是學術界沒有解決的問題。
Intel發布的Loihi聲稱可以自我學習,然而學習的效果如何還不得而知。應該說在模型訓練問題還沒有解決前,神經擬態就基本無法與經典的深度學習在主流人工智能應用里正面競爭,而主要會用在一些實驗性的應用,例如利用神經擬態芯片去完成腦科學研究,或者做一些專用場合的高效數據處理(例如三星就使用過IBM的True North神經擬態芯片來實現動態視覺傳感器,只有在畫面發生變化的時候該傳感器才會記錄)。而Intel發布的Loihi,也更多是一款試驗性質的產品。
為什么大家紛紛推出AI芯片產品?
在一個月中,幾家大公司相繼發布AI芯片,這首先說明人工智能應用真正獲得了市場的認可。如果我們回顧芯片市場,會發現總是先有軟件應用出現,該應用在得到認可后快速發展很快遇到硬件瓶頸,于是推動相應硬件的開發,而在硬件瓶頸突破后,該應用又會獲得更快速的普及,從而形成一個正循環。目前人工智能正處于該循環的第二步,即硬件限制了人工智能應用的普及,尤其是在移動端的普及,而各大硬件廠商正是看到了人工智能的巨大潛力,于是紛紛開發相關芯片并爭相發布。
在未來的移動人工智能市場,由于移動產品的多樣性(如要求高性能但是允許高功耗的智能攝像頭市場,要求高性能但是同時要求低延遲和低功耗的無人機市場,要求中等性能但是對成本和功耗要求很高的手機市場,以及要求超低功耗但是對于性能要求也不高的物聯網市場),預計還是會有多家公司分別占領不同的市場,而不太會出現一家獨大通吃所有市場的情況。未來人工智能芯片預計會進入群雄逐鹿的時代。
-
人工智能
+關注
關注
1792文章
47429瀏覽量
238969 -
深度學習
+關注
關注
73文章
5507瀏覽量
121293 -
AI芯片
+關注
關注
17文章
1893瀏覽量
35102
發布評論請先 登錄
相關推薦
什么是半導體芯片的失效切片分析?
FIB技術:芯片失效分析的關鍵工具

云端AI開發環境分析
深蕾半導體HDMI AI分析盒子






 工商網監
工商網監
評論