 簡介AI芯片功耗和應用分析和發展
簡介AI芯片功耗和應用分析和發展
近一年各種深度學習平臺和硬件層出不窮,各種xPU的功耗和面積數據也是滿天飛,感覺有點亂。在這里我把我看到的一點情況做一些小結,順便列一下可能的市場。在展開之前,我想強調的是,深度學習的應用無數,我能看到的只有能在千萬級以上的設備中部署的市場,各個小眾市場并不在列。
深度學習目前最能落地的應用有兩個方向,一個是圖像識別,一個是語音識別。這兩個應用可以在如下市場看到:個人終端(手機,平板),監控,家庭,汽車,機器人,服務器。
先說手機和平板。這個市場一年的出貨量在30億顆左右(含功能機),除蘋果外總值300億刀。手機主要玩家是蘋果(3億顆以下),高通(8億顆以上),聯發科(7億顆以上),三星(一億顆以下),海思(一億顆),展訊(6億顆以上),平板總共4億顆左右。而28納米工藝,量很大的話(1億顆以上),工程費用可以攤的很低,平均1平方毫米的成本是8美分左右,低端4G芯片(4核)的面積差不多是50平方毫米以下,成本就是4刀。中端芯片(8核)一般在100平方毫米左右,成本8刀。16納米以及往上,同樣的晶體管數,單位成本會到1.5倍。
一般來說,手機的物料成本中,處理器芯片(含基帶)價格占了1/6左右。一個物料成本90刀的手機,用的處理器一般在15刀以下,甚至只有10刀。這個10刀的芯片,包含了處理器,圖形處理器,基帶,圖像信號處理器,每一樣都是高科技的結晶,卻和肯德基全家桶一個價,真是有點慘淡。然而生產成本只是一部分,人力也是很大的開銷。一顆智能機芯片,軟硬開發,測試,生產,就算全用的成熟IP,也不會少于300人,每人算10萬刀的開銷,量產周期兩年,需要6000萬刀。外加各種EDA工具,IP授權和開片費,芯片還沒影子,1億刀就下去了。
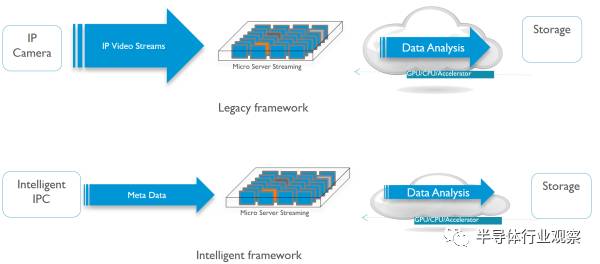
言歸正傳,手機上的應用,最直接的就是美顏相機,AR和語音助手。這些需求翻譯成硬件指令就是對8位整數點乘(INT8)和16位浮點運算(FP16)的支持。具體怎么支持?曾經看到過一張圖,我覺得較好的詮釋了這一點:
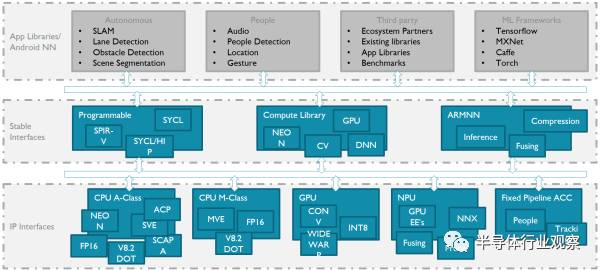
智能手機和平板上,是安卓的天下,所有獨立芯片商都必須跟著谷歌爸爸走。谷歌已經定義了Android NN作為上層接口,可以支持它的TensorFlow以及專為移動設備定義的TensorFlow Lite。而下層,針對各種不同場景,可以是CPU,GPU,DSP,也可以是硬件加速器。它們的能效比如下圖:
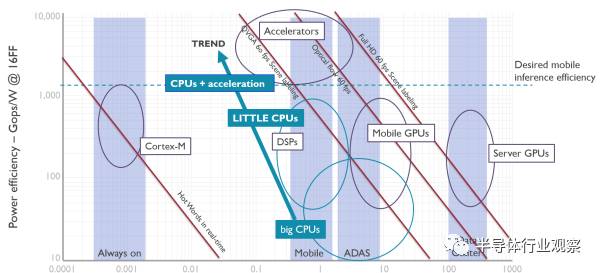
可以看到,在TSMC16納米工藝下,大核能效比是10-100Gops/W(INT8),小核可以做到100G-1Tops/W,手機GPU是300Gops/W,而要做到1Tops/W以上,必須使用加速器。這里要指出的是,小核前端設計思想與大核完全不同,在后端實現上也使用不同的物理單元,所以看上去和大核的頻率只差50%,但是在邏輯運算能效比上會差4倍以上,在向量計算中差的就更多了。
手機的長時間運行場景下,芯片整體功耗必須小于2.5瓦,分給深度學習任務的,不會超過1.5瓦。相對應的,如果做到1Tops/W,那這就是1.5T(INT8)的處理能力。對于照片識別而言,情況要好些,雖然對因為通常不需要長時間連續的處理。這時候,CPU是可以爆發然后休息的。語音識別對性能要求比較低,100Gops可以應付一般應用,用小核也足夠。但有些連續的場景,比如AR環境識別,每秒會有30-60幀的圖像送進來,如果不利用前后文幫助判斷,CPU是沒法處理的。此時,就需要GPU或者加速器上場。
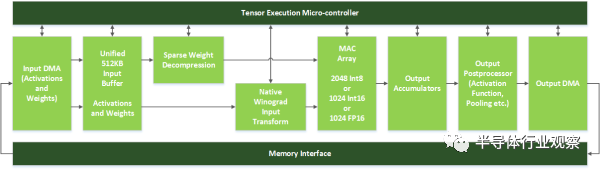
上圖是NVidia的神經網絡加速器DLA,它只有Inference的功能。前面提到在手機上的應用,也只需要Inference來做識別,訓練可以在服務端預先處理,訓練好的數據下載到手機就行,識別的時候無需連接到服務端。
DLA綠色的模塊形成類似于固定的流水線,上面有一個控制模塊,可以用于動態分配計算單元,以適應不同的網絡。我看到的大多數加速器其實都是和它大同小異,除了這了幾百K字節的SRAM來存放輸入和權值(一個273x128, 128x128, 128x128 ,128x6 的4層INT8網絡,需要70KBSRAM)外,而有些加速器增加了一個SmartDMA引擎,可以通過簡單計算預取所需的數據。根據我看到的一些跑分測試,這個預取模塊可以把計算單元的利用率提高到90%以上。
至于能效比,我看過的加速器,在支持INT8的算法下,可以做到1.2Tops/W (1Ghz@T16FFC),1Tops/mm^2,并且正在向1.5Tops/W靠近。也就是說,1.5W可以獲得2Tops(INT8)的理論計算能力。這個計算能力有多強呢?我這目前處理1080p60FPS的圖像中的60x60及以上的像素大小的人臉識別,大致需要0.5Tops的計算能力,2Tops完全可以滿足。當然,如果要識別復雜場景,那肯定是計算力越高越好。
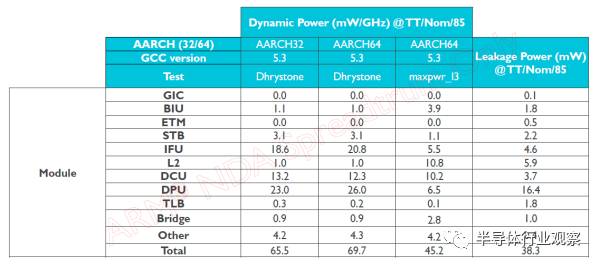
為什么固定流水的能效比能做的高?ASIC的能效比遠高于通用處理器已經是一個常識,更具體一些,DLA不需要指令解碼,不需要指令預測,不需要亂序執行,流水線不容易因為等待數據而停頓。下圖是某小核各個模塊的動態功耗分布,計算單元只占1/3,而指令和緩存訪問占了一半。
但是移動端僅僅有神經網絡加速器是遠遠不夠的。比如要做到下圖效果,那首先要把人體的各個細微部位精確識別,然后用各種圖像算法來打磨。而目前主流圖像算法和深度學習沒有關系,也沒看到哪個嵌入式平臺上的加速器在軟件上有很好的支持。目前圖像算法的支持平臺還主要是PC和DSP,連嵌入式GPU做的都一般。
那這個問題怎么解決?我看到兩種思路:
第一種,GPU內置加速器。下圖是Verisilicon的Vivante改的加速器,支持固定流水的加速器和可編程模塊Vision core(類似GPU中的著色器單元),模塊數目可配,可以同時支持視覺和深度學習算法。不過在這里,傳統的圖形單元被砍掉了,以節省功耗和面積。只留下調度器等共用單元,來做異構計算的調度。
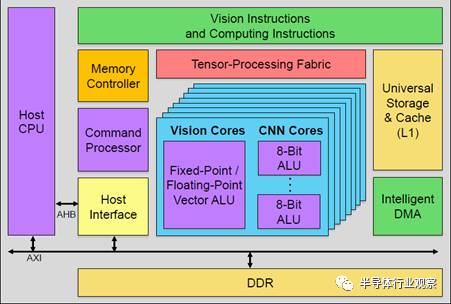
這類加速器比較適合于低端手機,自帶的GPU和CPU本身并不強,可能光支持1080p的UI就已經耗盡GPU資源了,需要額外的硬件模塊來完成有一定性能需求的任務。
對于中高端手機,GPU和CPU的資源在不打游戲的時候有冗余,那么就沒有必要去掉圖形功能,直接在GPU里面加深度學習加速器就可以,讓GPU調度器統一調度,進行異構計算。
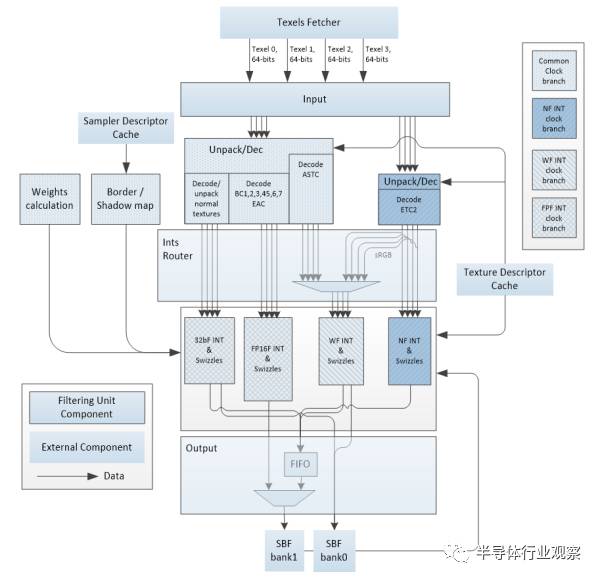
上圖是某款GPU的材質計算單元,你有沒有發現,其實它和神經網絡加速器的流水線非常類似?都需要權值,都需要輸入,都需要FP16和整數計算,還有數據壓縮。所不同的是計算單元的密度,還有池化和激活。稍作改動,完全可以兼容,從而進一步節省面積。
但是話說回來,據我了解,目前安卓手機上各種圖像,視頻和視覺的應用,80%其實都是用CPU在處理。而谷歌的Android NN,默認也是調用CPU匯編。當然,手機芯片自帶的ISP及其后處理,由于和芯片綁的很緊,還是能把專用硬件調動起來的。而目前的各類加速器,GPU,DSP,要想和應用真正結合,還有挺長的路要走。
終端設備上還有一個應用,AR。據說iPhone8會實現這個功能,如果是的話,那么估計繼2015的VR/AR,2016的DL,2017的NB-IOT之后,2018年又要回鍋炒這個了。
那AR到底用到哪些技術?我了解的如下,先是用深度傳感器得到場景深度信息,然后結合攝像頭拍到的2維場景,針對某些特定目標(比如桌子,面部)構建出一個真實世界的三維物體。這其中需要用到圖像識別來幫助判斷物體,還需要確定物體邊界。有了真實物體的三維坐標,就可以把所需要渲染的虛擬對象,貼在真實物體上。然后再把攝像頭拍到的整個場景作為材質,貼到背景圖層,最后把所有這些圖層輸出到GPU或者硬件合成器,合成最終輸出。這其中還需要判斷光源,把光照計算渲染到虛擬物體上。這里每一步的計算量有多大?
首先是深度信息計算。獲取深度信息目前有三個方法,雙目攝像頭,結構光傳感器還有TOF。他們分別是根據光學圖像差異,編碼后的紅外光模板和反射模板差異,以及光脈沖飛行時間來的得到深度信息。
第一個的缺點是需要兩個攝像頭之間有一定距離并且對室內光線亮度有要求,第二個需要大量計算并且室外效果不佳,第三個方案鏡頭成本較高。據說蘋果會用結構光方案,主要場景是室內,避免了缺點。結構光傳感器的成本在2-3刀之間,也是可以接受的。
而對于計算力的要求,最基本的是對比兩個經過偽隨機編碼處理過的發射模板以及接受模板,計算出長度差,然后用矩陣倒推平移距離,從而得到深度信息。這可以用專用模塊來處理,我看到單芯片的解決方案,720p60FPS的處理能力,需要10GFLOPS的計算量以上。換成CPU,就是4-8核。
當然,我們完全可以先識別出目標物體,用圖像算法計算出輪廓,還可以降低深度圖的精度(通常不需要很精確),從而大大降低計算量。而識別本身的計算量前文已經給出,計算輪廓是經典的圖像處理手段,針對特定區域的話計算量非常小,1-2個核就可以搞定。
接下去是根據深度圖,計算真實物體的三維坐標,并輸出給GPU。這個其實就是GPU渲染的第一階段的工作,稱作頂點計算。在移動設備上,這部分通常只占GPU總計算量的10%,后面的像素計算才是大頭。產生虛擬物體的坐標也在這塊,同樣也很輕松。
接下去是生成背景材質,包括產生minimap等。這個也很快,沒什么計算量,把攝像頭傳過來的原始圖像放到內存,告訴GPU就行。
稍微麻煩一些的是計算虛擬物體的光照。背景貼圖的光照不需要計算,使用原圖中的就可以。而虛擬物體需要從背景貼圖抽取亮度和物體方向,還要計算光源方向。我還沒有見過好的算法,不過有個取巧,就是生成一個光源,給一定角度從上往下照,如果對AR要求不高也湊合了。
其他的渲染部分,和VR有些類似,什么ATW啊,Front Buffer啊,都可以用上,但是不用也沒事,畢竟不是4K120FPS的要求。總之,AR如果做的不那么復雜,對CPU和GPU的性能要求并不高,搞個圖像識別模塊,再多1-2個核做別的足矣。
有了計算量,深度學習加速器對于帶寬的需求是多少?大部分數據都是只需要一次,1Tops的計算量需要5GB/s以下的帶寬。連接方法可以放到CPU的加速口ACP(跑在1.8GHz的ARMv8.2內部總線可以提供9GB/s帶寬)。只用一次的數據可以設成非共享類型,需要和CPU交換或者常用的數據使用Cacheable和Shareable類型,既可以在三級緩存分配空間,還可以更高效的做監聽操作,免掉刷緩存。
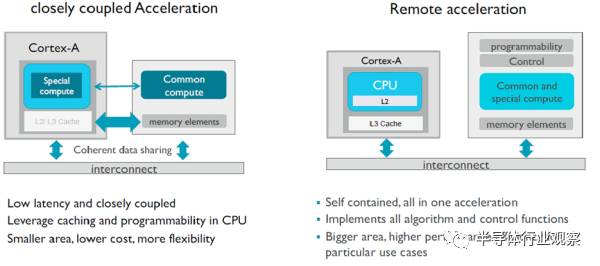
如果加速器在GPU上,那么還是得用傳統的ACE口,一方面提高帶寬,一方面與GPU的核交換數據在內部進行,當然,與CPU的交互必然會慢一些。
在使用安卓的終端設備上,深度學習可以用CPU/DSP/GPU,也可以是加速器,但不管用哪個,一定要跟緊谷歌爸爸。谷歌以后會使用Vulkan Compute來替代OpenCL,使用Vulkan 來替代OpenGL ES,做安卓GPU開發的同學可以早點開始熟悉了。
高通推過用手機做訓練,然后手機間組網,形成強大的計算力。從我的角度看,這個想法問題多多,先不說實際應用,誰會沒事開放手機給別人訓練用?耗電根本就吃不消。并且,要是我知道手機偷偷的上傳我的圖像和語音模板到別人那里,絕對不會買。
第二個市場是家庭,包括機頂盒/家庭網關(4億顆以下),數字電視(3億顆以下),電視盒子(1億以下)三大塊。整個市場出貨量在7億片,電器里面的MCU并沒有計算在內。這個市場公司比較散,MStar/海思/博通/Marvell/Amlogic都在里面,小公司更是無數。如果沒有特殊要求,拿平板的芯片配個wifi就可以用。當然,中高端的對畫質還是有要求,MTK現在的利潤從手機移到了電視芯片,屏幕顯示這塊有獨到的技術。很多機頂盒的網絡連接也不是以太網,而是同軸電纜等,這種場合也得專門的芯片。最近,這個市場里又多了一個智能音箱,各大互聯網公司又拿出當年追求手機入口的熱情來布局,好不熱鬧。
家庭電子設備里還有一個成員,游戲機。Xbox和PS每年出貨量均在千萬級別。VR/AR和人體識別早已經用在其中。
對于語音設別,100Gops的性能需求對于無風扇設計引入的3瓦功耗限制,CPU/DSP和加速器都可以選。不過工藝就得用28納米了或者更早的了,畢竟沒那么多量,撐不起16納米。最便宜的方案,可以使用RISC-V+DLA,沒有生態系統綁定的情況下最省成本。獨立的加速器本身對CPU要求并不高,不像GPU那樣需要支持OpenCL/OpenGL ES。8核G71@900Mhz差不多需要一個2GHz的A73來支持。并且由于OpenGL ES的限制,還不能使用小核來分擔任務。而100Gops的語音處理我估計幾百兆赫茲的處理器就可以了。
圖像方面的應用,主要還是人臉識別和播放內容識別,不過這還沒有成為一個硬需求。之前提過,0.5Tops足以搞定簡單場景,4K分辨率的話,性能需求是1080p的四倍。
接下去是監控市場。監控市場上的圖像識別是迄今為止深度學習最硬的需求。監控芯片市場本身并不大,有1億顆以上的量,銷售額20億刀左右。主流公司有安霸,德州儀器和海思,外加幾個小公司,OEM自己做芯片的也有。
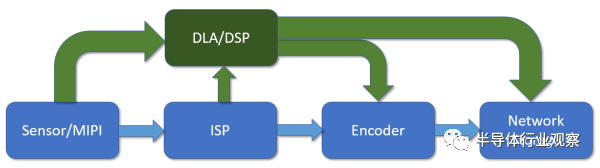
傳統的監控芯片數據流如上圖藍色部分,從傳感器進來,經過圖像信號處理單元,然后送給視頻編碼器編碼,最后從網絡輸出。如果要對圖像內容進行識別,那可以從傳感器直接拿原始數據,或者從ISP拿處理過的圖像,然后進行識別。
中高端的監控芯片中還會有個DSP,做一些后處理和識別的工作。現在深度學習加速器進來,其實和DSP是有些沖突的。以前的一些經典應用,比如車牌識別等,DSP其實就已經做得很好了。如果要做識別以外的一些圖像算法,這顆DSP還是得在通路上,并不能被替代。并且,DSP對傳統算法的軟件庫支持要好得多。這樣,DSP替換不掉,額外增加處理單元在成本上就是一個問題。
對于某些低功耗的場景,我看到有人在走另外一條路。那就是完全扔掉DSP,放棄存儲和傳輸視頻及圖像,加入加速器,只把特征信息和數據通過NB-IOT上傳。這樣整個芯片功耗可以控制在500毫瓦之下。整個系統結合傳感器,只在探測到有物體經過的時候打開,平時都處于幾毫瓦的待機狀態。在供電上,采用太陽能電池,10mmx20mm的面板,輸出功率可以有幾瓦。不過這個產品目前應用領域還很小眾。
做識別的另一個途徑是在局端。如果用顯卡做,GFX1080的FP32 GLOPS是9T,180瓦,1.7Ghz,16納米,320mm。而一個Mali G72MP32提供1T FP32的GFLOPS,16納米,850Mhz,8瓦,9T的話就是72瓦,666mm。當然,如果G72設計成跑在1.7Ghz,我相信不會比180瓦低。此外桌面GPU由于是Immediate rendering的,帶寬大,但對緩存沒有很大需求,所以移動端的GPU面積反而大很多,但相對的,它對于帶寬需求小很多,相應的功耗少很多
GPU是拿來做訓練的,而視頻識別只需要做Inference,如果用固定流水的加速器,按照之前給的數據,9T FP32 GLOPS換算成36Tops的INT8,只需要36mm。9Tops對應的識別能力是20路1080p60fps,20路1080p60fps視頻解碼器對應的面積差不多是 10mm,加上SRAM啥的,估計100mm以下。如果有一千萬的量,那芯片成本可以做到20美金以下,而一塊GFX1080板子的售價是1000美金(包括DDR顆粒),暴利。國內現在不少小公司拿到了投資在做這塊的芯片。
第四個市場是機器人/無人機。機器人本身有多少量我沒有數據,手機和平板的芯片也能用在這個領域。無人機的話全球一年在200萬左右,做視覺處理的芯片也應該是這個量級。。用到的識別模塊目前看還是DSP和CPU為主,因為DSP還可以做很多圖像算法,和監控類似。這個市場對于ISP和深度信息的需求較高,雙攝和結構光都可以用來算深度計算,上文提過就不再展開。
在無人機上做ISP和視覺處理,除了要更高的清晰度和實時性外,還比消費電子多了一個要求,容錯。無人機的定位都靠視覺,如果給出的數據錯誤或者模塊無反應都不符合預期。解決這個問題很簡單,一是增加各種片內存儲的ECC和內建自檢,二是設兩個同樣功能的模塊,錯開時鐘輸入以避免時鐘信號引起的問題,然后輸出再等相同周期,同步到一個時鐘。如果兩個結果不一致,那就做特殊處理,避免擴散數據錯誤。
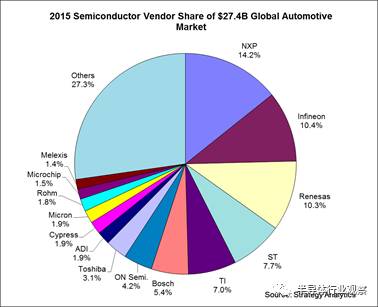
第五個市場是汽車,整個汽車芯片市場近300億刀,玩家眾多:
在汽車電子上,深度學習的應用就是ADAS了。在ADAS里面,語音和視覺從技術角度和前幾個市場差別不大,只是容錯這個需求進一步系統化,形成Function Safety,整個軟硬件系統都需要過認證,才容易賣到前裝市場。Function Safety比之前的ECC/BIST/Lock Step更進一步,需要對整個芯片和系統軟件提供詳細的測試代碼和文檔,分析在各類場景下的錯誤處理機制,連編譯器都需要過認證。認證本身分為ASIL到A-ASIL-D四個等級,最高等級要求系統錯誤率小于1%。我對于這個認證并不清楚,不過國內很多手機和平板芯片用于后裝市場的ADAS,提供語音報警,出貨量也是過百萬的。
最后放一張ARM的ADAS參考設計框圖。
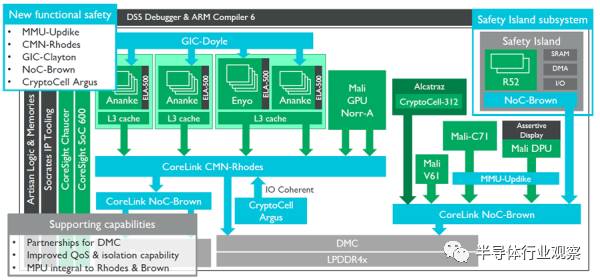
可能不會有人照著這個去設計ADAS芯片,不過有幾處可以借鑒:
右方是安全島,內涵Lock Step的雙Cortex-R52,這是為了能夠保證在左邊所有模塊失效的情況下復位整個系統或者進行異常中斷處理的。中部藍色和綠色的CryptoCell模塊是對整個系統運行的數據進行保護,防止惡意竊取的。關于Trustzone設計我以前的文章有完整介紹這里就不展開了。
以上幾個市場基本都是Inference的需求,其中大部分是對原有產品的升級,只有ADAS,智能音箱和服務器端的視頻識別檢測是新的市場。其中智能音箱達到了千萬級別,其它的兩個還都在擴張。
接下去的服務端的訓練硬件,可以用于訓練的移動端GPU每個計算核心面積是1.5mm(TSMC16nm),跑在1Ghz的時候能效比是300Gops/W。其他系統級的性能數據我就沒有了。雖然這個市場很熱,NVidia的股票也因此很貴,但是我了解到全球用于深度學習訓練的GPU銷售額,一年只有1億刀不到。想要分一杯羹,可能前景并沒有想象的那么好。
最近970發布,果然上了寒武紀。不過2T ops FP16的性能倒是讓我吃了一驚,我倒推了下這在16nm上可能是10mm的面積,A73MP4+A53MP4+3MB二級緩存也就是這點大小。麒麟芯片其實非常強調面積成本,而在高端特性上這么舍得花面積,可見海思要在高端機上走出自己的特色之路的決心,值得稱道。不過寒武紀既然是個跑指令的通用處理器,那除了深度學習的計算,很多其他場合也能用上,比如ISP后處理,計算結構光深度信息等等,能效可能比DSP還高些。
-
處理器
+關注
關注
68文章
19348瀏覽量
230269 -
神經網絡
+關注
關注
42文章
4774瀏覽量
100898 -
AI芯片
+關注
關注
17文章
1893瀏覽量
35102
發布評論請先 登錄
相關推薦
恒玄科技研發AI眼鏡專用芯片
UWB模塊的功耗分析
Orin芯片功耗分析
RISC-V在AI領域的發展前景怎么樣?
AM62A Edge AI零售掃描儀演示:SoC選型和功耗分析

低功耗芯片的市場發展前景怎么樣?
RISC-V在中國的發展機遇有哪些場景?
后摩智能引領AI芯片革命,推出邊端大模型AI芯片M30

risc-v多核芯片在AI方面的應用
一鍵消原音智能AI芯片PTN1118芯片簡介
使用cube-AI分析模型時報錯的原因有哪些?
NanoEdge AI的技術原理、應用場景及優勢






 工商網監
工商網監
評論