 BERT再次制霸GLUE排行榜!BERT王者歸來了!
BERT再次制霸GLUE排行榜!BERT王者歸來了!
BERT再次制霸GLUE排行榜!今天,Facebook公開一個“強力優化”版的基于BERT預訓練模型,名為RoBERTa,在GLUE、SQuAD和RACE三個排行榜上全部實現了最先進的結果。距被XLNet超越沒過多久,BERT再次回到了最強NLP預訓練模型的王座。
BERT王者歸來了!
前不久,CMU和谷歌大腦提出的XLNet預訓練模型在 20 項任務上全面碾壓曾有“最強NLP預訓練模型”之稱的BERT,可謂風光無限,吸足了眼球。
不過,XLNet的王座沒坐太久。就在今天,Facebook公布一個基于BERT開發的加強版預訓練模型RoBERTa——在GLUE、SQuAD和RACE三個排行榜上全部實現了最先進的結果!
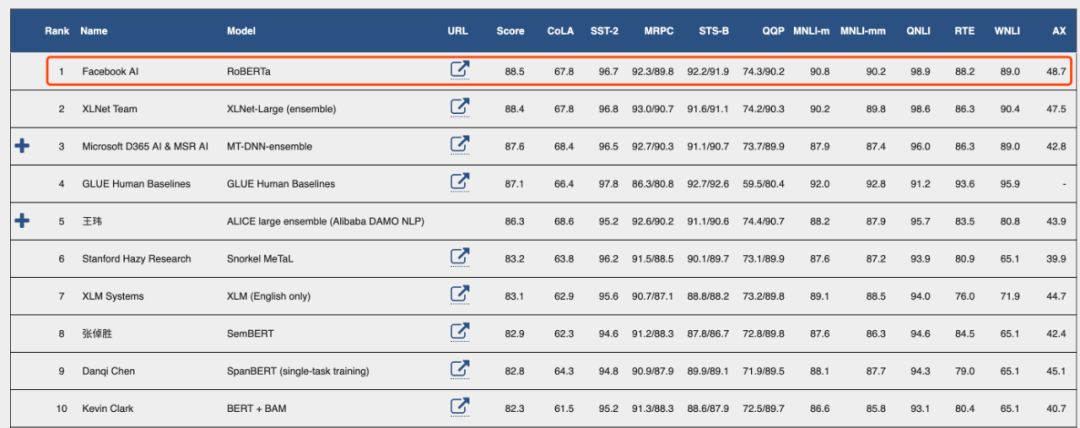
GLUE最新排行榜
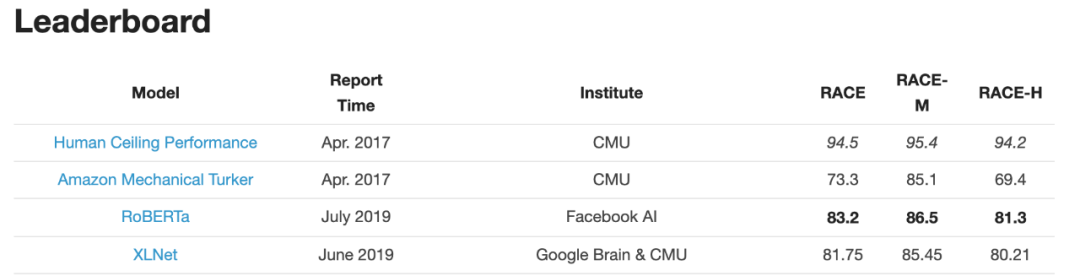
RACE排行榜
RoBERTa的名稱來"RobustlyoptimizedBERTapproach",強力優化的BERT方法,真是相當簡單粗暴呢~
這項研究由Facebook AI和華盛頓大學的研究團隊共同完成,而且第一作者是華人研究員Yinhan Liu,此外還有Jingfei Du和Danqi Chen。
作者之一的Veselin Stoyanov在推特上公布了該結果
Facebook AI負責人Yann LeCun推薦:
要說RoBERTa是如何制霸3個benchmark排行榜的,簡言之,用更多的數據,采取更精妙的訓練技巧,訓練更久一些。
作者在論文中寫道:“我們對BERT預訓練(Devlin et al. , 2019)進行了一項復制研究,仔細衡量了許多關鍵超參數和訓練數據大小對結果的影響。我們發現BERT的訓練明顯不足,并且可以匹配或超過之后發布的每個模型的性能。我們最好的模型在GLUE,RACE 和 SQuAD上都實現了最先進的結果。”
作者表示,超參數的選擇對最終結果的影響很大。
他們發布了模型和代碼:https://github.com/pytorch/fairseq
接下來,新智元帶來對這篇論文的詳細解讀:
只要訓練得好,BERT可以超過所有后續方法的性能
自我訓練的方法,比如ELMo, GPT,BERT,XLM 以及XLNet等,帶來了顯著的性能提升,但要想確定這些方法的哪些方面對性能提升貢獻最多是相當有挑戰性的。由于訓練在計算上成本很高,限制了可執行的調優量,而且常常使用不同大小的私有訓練數據進行調優,限制了對建模進展效果的測量。
我們對BERT預訓練模型(Devlin et al., 2019)進行了一項復制研究,包括仔細評估了超參數調優效果和訓練集大小的影響。我們發現BERT明顯訓練不足,并提出了一個改進的訓練BERT模型的方法,我們稱之為RoBERTa,它可以達到或超過所有BERT后續方法(post-BERT)的性能。
我們做的修改很簡單,包括:
(1)對模型進行更長時間、更大批量、更多數據的訓練;
(2)刪除下一句預測的目標;
(3)對較長序列進行訓練;
(4)動態改變應用于訓練數據的masking模式。
我們還收集了一個與其他私有數據集大小相當的新數據集(CC-NEWS),以便更好地控制訓練集大小效果。
在對訓練數據進行控制時,我們的升級版訓練程序進一步提升了BERT在GLUE和SQuAD排行榜上公布的結果。
經過長時間的訓練,我們的模型在公共 GLUE排行榜上的得分為88.5分,與Yang等人(2019)報告的88.4分相當。我們的模型在GLUE 9個任務的其中4個上達到了state-of-the-art的水平,分別是:MNLI, QNLI, RTE 和 STS-B。此外,我們還在SQuAD 和 RACE 排行榜上達到了最高分。
總結而言,本文的貢獻有:
(1)我們提出了一套重要的BERT設計選擇和訓練策略,并引入了能夠提高下游任務成績的備選方案;
(2)我們使用一個新的數據集CCNEWS,并確認使用更多的數據進行預訓練可以進一步提高下游任務的性能;
(3)我們的訓練改進表明,在正確的設計選擇下,預訓練的masked language model與其他所有最近發表的方法相比都更具有競爭力。我們發布了在PyTorch中實現的模型、預訓練和微調代碼。
模型架構:Transformer
BERT使用了現在已經十分流行的transformer架構,這里我們不會詳細討論它。我們使用的是L層的transformer 架構,每個block 都使用一個self-attention head和隱藏維度H。
在訓練前,BERT使用了兩個目標:masked language modeling和下一句預測。
Masked Language Mode(MLM)選擇輸入序列中的隨機token樣本,并用特殊的token[MASK]替換。MLM的目標是預測遮擋token時的交叉熵損失。BERT一致選擇15%的輸入token作為可能的替換。在所選的token中,80%替換為[MASK], 10%保持不變,10%替換為隨機選擇的詞匯表token。
在最初的實現中,隨機遮擋和替換在開始時執行一次,并保存到訓練期間,但是在實際操作中,由于數據是重復的,所以每個訓練語句的mask并不總是相同的。
下一句預測(NSP)是一種二分類損失,用于預測兩個片段在原文中是否相互跟隨。通過從文本語料庫中提取連續的句子來創建積極的例子。反例是通過對來自不同文檔的段進行配對來創建的。正、負樣本的抽樣概率相等。
NSP的目標是為了提高下游任務的性能,比如自然語言推理,這需要對句子對之間的關系進行推理。
實驗設計
在本節中,我們描述了用于BERT復制研究的實驗設置。
我們在FAIRSEQ中重新實現了BERT。我們主要遵循第2節中給出的原始BERT優化超參數,除了峰值學習率和warmup步驟的數量,這兩個參數分別針對每個設置進行調優。
此外,我們還發現訓練對Adam epsilon項非常敏感,在某些情況下,在對其進行調優后,我們獲得了更好的性能或更好的穩定性。同樣地,我們發現設置β2 = 0.98時可以提高大的batch size訓練時的穩定性。
我們在DGX-1機器上進行混合精度浮點運算的訓練,每臺機器上有8個32GB Nvidia V100 GPU,通過Infiniband互連。
哪些選擇對于成功地訓練BERT模型至關重要
本節探討和量化哪些選擇對于成功地訓練BERT模型至關重要。我們保持模型架構不變。具體地說,我們首先以與BERTBASE相同的配置(L = 12, H = 768, A = 12, 110M params)開始訓練BERT模型。
靜態masking vs. 動態masking
正如在前文討論的,BERT依賴于隨機遮擋和預測token。原始的BERT實現在數據預處理期間執行一次遮擋,從而產生一個靜態遮擋(static mask)。為了避免在每個epoch中對每個訓練實例使用相同的mask,我們將訓練數據重復10次,以便在40個訓練epoch中以10種不同的方式對每個序列進行遮擋。因此,在訓練過程中,每個訓練序列都使用相同的mask四次。
我們將此策略與動態遮擋(dynamic masking)進行比較,在dynamic masking)中,每次向模型提供序列時都會生成masking模式。當對更多步驟或更大的數據集進行預訓練時,這一點變得至關重要。
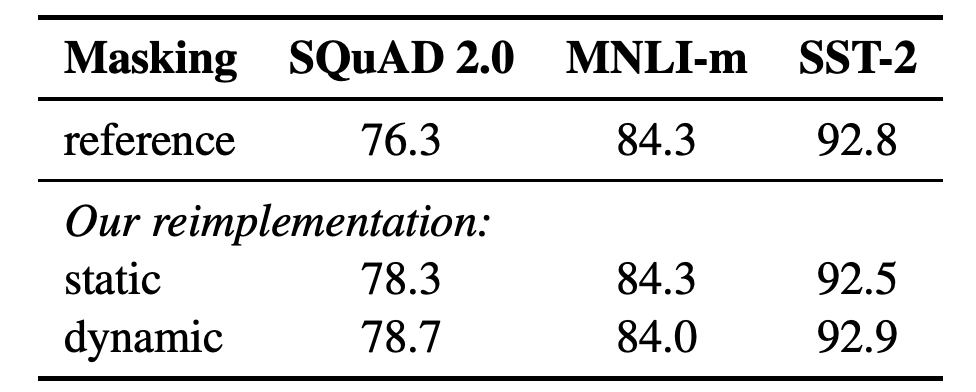
表1:SEBERTBASE的靜態和動態masking的比較。我們報告了SQuAD 的F1分數和MNLI-m 以及 SST-2的準確性結果。報告的結果是超過5個隨機初始化的中值。參考結果來自Yang et al. (2019).
結果表1比較了Devlin等人(2019)發布的BERTBASE結果與我們使用靜態或動態masking重新實現的結果。我們發現,使用靜態masking的重新實現的性能與原始的BERT模型相似,而動態masking可以與靜態masking的結果相當,甚至略好于靜態masking。
考慮到這些結果和動態masking的額外效率優勢,我們在其余的實驗中使用動態masking。
模型輸入格式和下一句預測
在原始的BERT預訓練過程中,模型觀察到兩個連接的文檔片段,它們要么是從相同的文檔連續采樣(p = 0.5),要么是從不同的文檔采樣。除了masked language modeling 目標外,該模型還通過輔助下一句預測(NSP)損失訓練模型來預測觀察到的文檔片段是來自相同還是不同的文檔。
NSP損失被認為是訓練原始BERT模型的一個重要因素。Devlin等人(2019)觀察到,去除NSP會損害性能,QNLI、MNLI和SQuAD的性能都顯著下降。然而,最近的一些工作對NSP損失的必要性提出了質疑。
為了更好地理解這種差異,我們比較了幾種替代訓練格式:
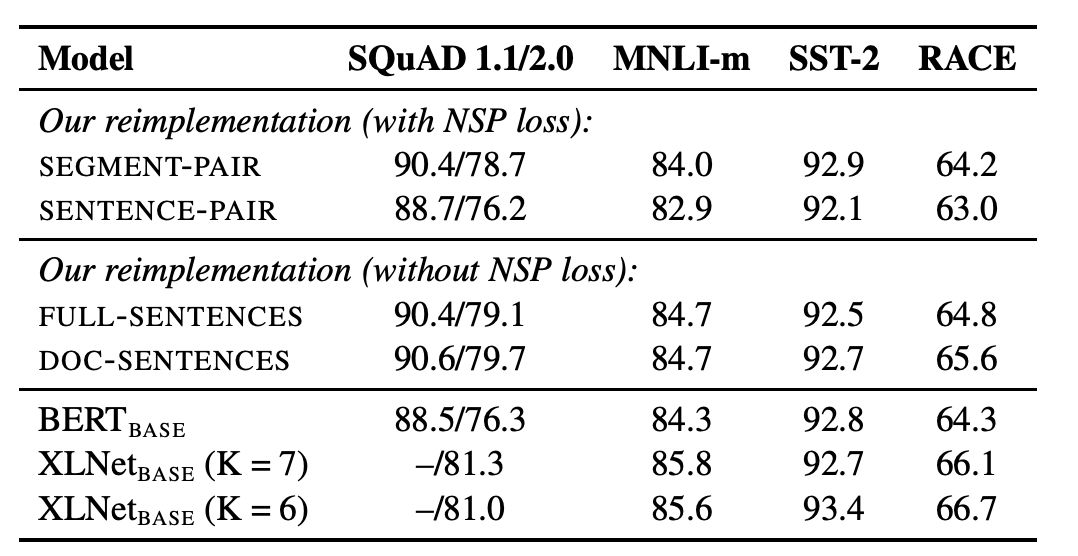
表2:在BOOKCORPUS和WIKIPEDIA上預訓練的基本模型的開發集結果。
表2顯示了四種不同設置的結果。我們發現,使用單獨的句子會影響下游任務的性能,我們假設這是因為該模型無法學習長期依賴關系。
接下來,我們將無NSP損失的訓練與來自單個文檔(doc - sentence)的文本塊的訓練進行比較。我們發現,與Devlin等人(2019)相比,該設置的性能優于最初發布的BERTBASE結果,消除NSP損失達到或略微提高了下游任務性能。
最后,我們發現將序列限制為來自單個文檔(doc - sentence)的性能略好于打包來自多個文檔(全句)的序列。但是,由于doc - sentence格式會導致不同的batch sizes,所以我們在其余的實驗中使用完整的句子,以便與相關工作進行比較。
large batches訓練
以往的神經機器翻譯研究表明,當學習率適當提高時,非常大的mini-batches的訓練既可以提高優化速度,又可以提高最終任務性能。最近的研究表明,BERT也可以接受 large batch訓練。
Devlin等人(2019)最初訓練BERTBASE只有100萬步, batch size為256個序列。
在表3中,我們比較了BERTBASE在增大 batch size時的復雜性和最終任務性能,控制了通過訓練數據的次數。我們觀察到,large batches訓練提高了masked language modeling 目標的困惑度,以及最終任務的準確性。通過分布式數據并行訓練,large batches也更容易并行化,在后續實驗中,我們使用8K序列的batches進行并行訓練。
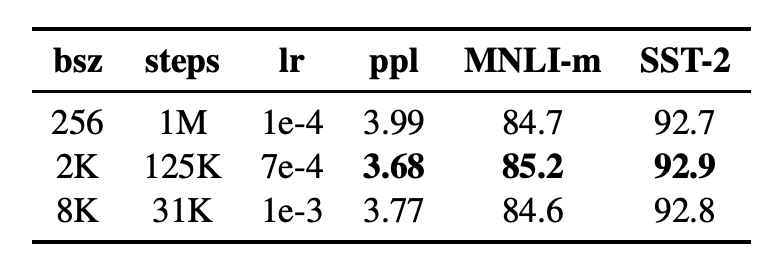
表3:不同批大小上訓練的基本模型的未完成訓練數據(ppl)和開發集準確性的困惑度。
RoBERTa:制霸三大基準數據集
在上一節中,我們建議修改BERT預訓練程序,以改善最終任務的性能。我們現在匯總這些改進并評估它們的綜合影響。我們將這種配置稱為RoBERTa,即“RobustlyoptimizedBERTapproach”,強力優化的BERT方法。
具體來說,RoBERTa采用了dynamic masking、沒有NSP損失的完整句子、large mini-batches和更大的字節級BPE的訓練。
此外,我們還研究了以前工作中未被強調的另外兩個重要因素:(1)用于預訓練的數據,以及(2)通過數據的訓練次數。例如,最近提出的XLNet架構使用的數據比原始BERT多近10倍。它還以8倍大的批量進行訓練,以獲得一半的優化步驟,因此在預訓練中看到的序列數是BERT的4倍。
為了將這些因素與其他建模選擇(例如,預訓練目標)的重要性區分開來,我們首先按照BertLarge架構(L=24,H=1024,A=16355m)對Roberta進行訓練。正如在Devlin et al. 中使用的一樣,我們用BOOKCORPUS和WIKIPEDIA數據集進行了100K步預訓練。我們使用1024V100GPU對我們的模型進行了大約一天的預訓練。
結果如表4所示,當控制訓練數據時,我們觀察到RoBERTa比最初報告的BERTLARGE結果有了很大的改進,再次證實我們在第4節中探討的設計選擇的重要性。
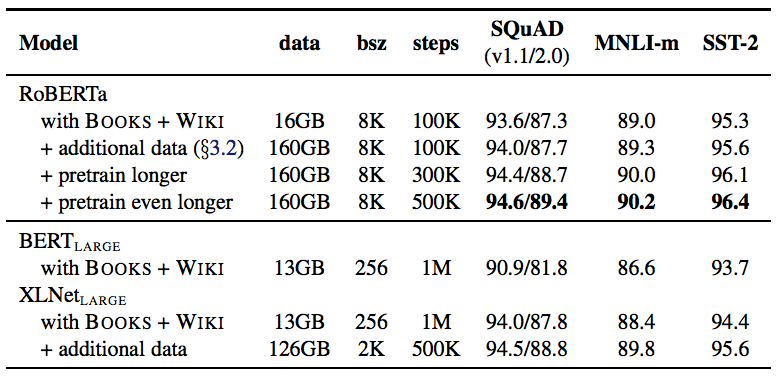
表4:當我們預先訓練了更多數據(16GB→160GB文本)和預訓練更久(100K→300K→500K步),RoBERTa的開發集(Development set)結果。每行累積上述行的改進。RoBERTa匹配BERTLARGE的架構和訓練目標。BERTLARGE和XLNetLARGE的結果分別來自Devlin et al.和Yang et al. 附錄中有所有GLUE任務的完整結果。
接下來,我們將此數據與第3.2節中描述的三個附加數據集相結合。我們用與之前相同數量的訓練步(100K)對RoBERTa進行綜合數據訓練。我們總共預處理了超過160GB的文本。我們觀察到所有下游任務的性能進一步提高,驗證了數據大小和多樣性在預訓練中的重要性。
最后,我們預先訓練RoBERTa的時間要長得多,將預訓練步數從100K增加到300K,再進一步增加到500K。我們再次觀察到下游任務性能的顯著提升,300K和500K步模型在大多數任務中的表現優于XLNetLARGE。我們注意到,即使是我們訓練時間最長的模型似乎也不會超出我們的數據范圍,而且可能會從額外的訓練中受益。
在本文的其余部分,我們根據三個不同的基準評估我們最好的RoBERTa模型:GLUE,SQuaD和RACE。具體來說,我們認為RoBERTa在第3.2節中介紹的所有五個數據集上都進行了500K步的訓練。
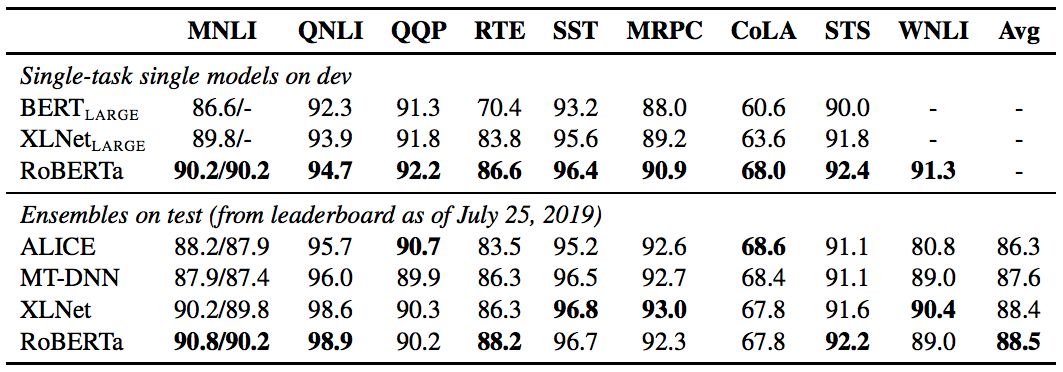
表5:GLUE的結果。所有結果均基于24層架構。BERTLARGE和XLNetLARGE結果分別來自Devlin et al.和Yang et al. 開發集上的RoBERTa結果是五次運行的中間數。測試集上的RoBERTa結果是單任務模型的集合。對于RTE,STS和MRPC,我們從MNLI模型而不是基線預訓練模型開始微調。平均值從GLUE leaderboard獲得。
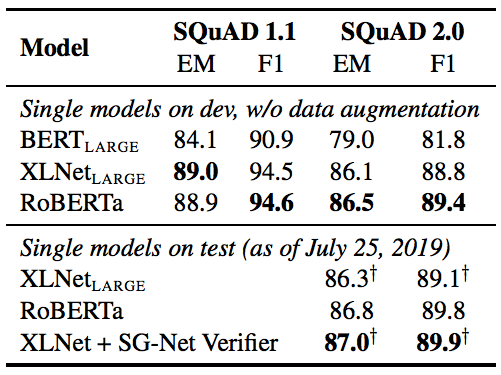
表6:SQuAD的結果。+表示依賴于額外外部訓練數據的結果。RoBERTa在開發和測試中僅使用了提供的SQuAD數據。BERTLARGE和XLNetLARGE結果分別來自Devlin et al.和Yang et al.
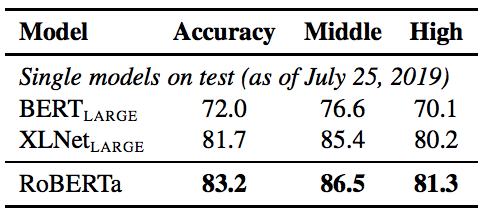
表7:RACE測試集的結果。BERTLARGE和XLNetLARGE的結果來自Yang et al.
-
Facebook
+關注
關注
3文章
1429瀏覽量
54722 -
模型
+關注
關注
1文章
3226瀏覽量
48809
原文標題:BERT王者歸來!Facebook推出RoBERTa新模型,碾壓XLNet 制霸三大排行榜
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
潤和軟件榮登2024智慧金融企業排行榜單
內置誤碼率測試儀(BERT)和采樣示波器一體化測試儀器安立MP2110A

調用云數據庫更新排行榜單
M8020A J-BERT 高性能比特誤碼率測試儀
AWG和BERT常見問題解答
博泰車聯網五度蟬聯“世界物聯網排行榜500強企業”
安全光幕十大品牌排行榜最新2024年


HarmonyOS開發案例:【排行榜頁面】
2023工業機器人排行榜發布

銳成芯微再次榮登中國IC設計排行榜TOP 10 IP公司榜單

敏芯股份再次入選中國IC設計排行榜TOP10傳感器公司

中穎電子入選Fabless 100排行榜TOP10微控制器公司榜單







 工商網監
工商網監
評論