

隨著計算機視覺的發展,2D目標檢測在精度和速度方面已經得到了巨大的提升,并在各個領域取得了令人矚目的成績。但2D檢測卻忽視了物體的三維信息。目前的3D形狀預測研究主要基于合成數據集和當個目標的預測。
為了解決這一問題,來自Facebook的研究人員提出了Mesh R-CNN模型,可以從單張輸入圖像中檢測不同物體,并預測出每個物體對應的三角網格,將二維目標檢測的能力成功地拓展到了三維目標檢測和形狀預測。

三維目標檢測與形狀預測
近年來深度學習在三維形狀理解領域有了很大的提升,研究人員們利用神經網絡對體素、點云、網格等三維表示進行學習,推進了三維世界表示和理解的發展。但這些技術主要基于合成數據集進行開發和研究,缺乏復雜的形狀和條件,相比二維圖像的大型數據集還遠遠不夠。研究人員認為三維研究領域需要開發新的識別與理解系統,可以在非限制環境、復雜形狀、多物體以及光照條件變化的情境下穩定運行。
為了實現這一目標,研究人員開發了2D感知和3D形狀預測的方法,可以在單張RGB輸入的情況下實現目標檢測、實例分割以及目標3D三角網格預測的功能。這一方法基于Mask R-CNN改進而來,增加了網格預測分支來輸出高分辨的目標三角網格。這種方法預測出的網格不僅能夠捕捉不同的3D結構中,同時可以適用于不同的幾何復雜度。Mesh R-CNN克服了先前固定網格模板的形態預測方法,利用多種三維表示方法完成預測。
Mesh R-CNN首先預測出目標粗糙的體素、隨后轉換為網格并利用精確的網格預測分支進行優化,最后實現了對于任意幾何結構的精細預測。
Mesh R-CNN
這一研究的目標是通過單張圖像輸入,對圖像中的物體進行檢測、獲取不同物體的類別、掩膜和對應的三維網格,并對真實世界中的復雜模型進行有效處理。在2D深度網絡的基礎上,研究人員改進并提出了新的架構。

這一模型主要分為三個部分,包括了預測box和mask的檢測分支、預測體素的分支和mesh優化分支。受到RoIAlign的啟發,研究人員在網格預測中加入了VertAlign將輸入圖像與特征進行對應。
體素預測分支與box/mask預測分支的輸入相同,都使用了與圖像對齊的特征。模型最后將目標檢測、語義分割損失與網格預測損失結合起一同對網絡進行端到端的訓練和優化。Mesh R-CNN的核心是網格預測器,它將對齊的圖像特征進行輸入,并輸出目標的三維網格。與二維圖像的處理相似,研究人員同時也維護了特征在不同階段的對齊,包括區域和體素對應的對齊操作(RoIAlign和VertAlign),并捕捉圖像中所有實例的3D形狀。
這意味著每一個預測出的網格都具有自己的拓撲結構(包括網格種類、一定數量的頂點、邊和面)以及幾何形狀。這一模型可以預測不同形狀和拓撲結構的網格。
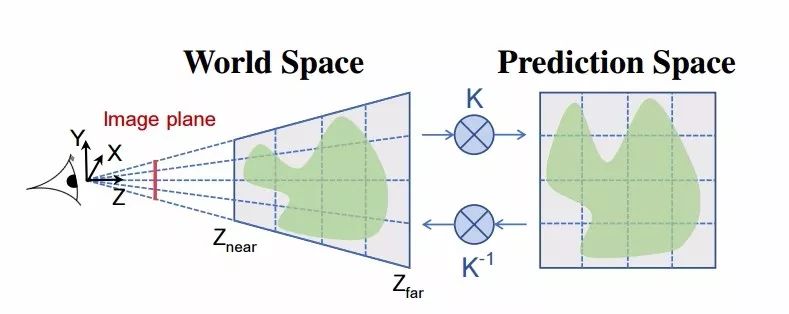
模型的體素分支將針對每一個檢測到的物體預測柵格在空間中的占據概率,并得到三維模型最終的形狀結果。可以將其視為3D版的Mask R-CNN,利用GxGxG的柵格在三維空間中預測出目標的外形。
同樣和Mask R-CNN類似的是,對于體素的預測同樣適用了來自RoIAlign的特征,并得到G個通道特征,其中的體素表示了輸入位置的占據分數,在實驗中研究人員使用了24x24x24大小的體素表示。

隨后立方體化方法(Cubify)將3D體素的占據概率轉換為三角網格模型。它將輸入的占據概率二進制輸出,每一個體素占據點被一個立方體的三角網格代替,包含了8個頂點、18條邊和12個面。相鄰立方體共享邊,緊鄰的面被消除,最終得到與體素形態學相同的網格表示。
最后需要將得到的網格進一步優化以獲取更為精確的結果。與很多體素/網格的優化方法相同,首先需要將頂點與圖像特征對齊,隨后利用圖網絡卷積的方法在每一條mesh邊上對信息進行傳播,最后將得到的結果用于更新每一個頂點的位置。
上面三個步驟在優化過程中不斷進行。最后為了給mesh優化分支建立損失,研究人員在網格表面進行稠密的采樣得到點云來計算網格優化分支的損失。
結果
最終研究人員在ShapeNet 數據集和Pix3D數據集上驗證了這種方法的有效性。可以看到新提出的方法可以有效地預測帶有孔洞的物體。
同時對于復雜環境中的三維物體也有良好的預測效果:
文章附錄里給出了包括立方體化、網格采樣、消融性分析以及與各種方法的比較,如果想要了解更多的實現細節,請參看:
https://arxiv.org/pdf/1906.02739.pdf
ref:
paper:https://arxiv.org/pdf/1906.02739.pdf
logopicture:https://dribbble.com/shots/1143435-Pikachu-Polymon
-
圖像
+關注
關注
2文章
1092瀏覽量
41035 -
Facebook
+關注
關注
3文章
1432瀏覽量
56200 -
數據集
+關注
關注
4文章
1223瀏覽量
25281
原文標題:Facebook研究員提出Mesh R-CNN,向三維進擊的目標檢測!
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
介紹目標檢測工具Faster R-CNN,包括它的構造及實現原理

什么是Mask R-CNN?Mask R-CNN的工作原理
手把手教你操作Faster R-CNN和Mask R-CNN
研究人員們提出了一系列新的點云處理模塊

JD和OPPO的研究人員們提出了一種姿勢引導的時尚圖像生成模型
研究人員提出了一個名為CommPlan的框架
Facebook向研究人員發布友誼數據
基于改進Faster R-CNN的目標檢測方法
華裔女博士提出:Facebook提出用于超參數調整的自我監督學習框架
基于Mask R-CNN的遙感圖像處理技術綜述
用于實例分割的Mask R-CNN框架
PyTorch教程14.8之基于區域的CNN(R-CNN)

PyTorch教程-14.8。基于區域的 CNN (R-CNN)






 工商網監
工商網監

評論