 關于人工智能和機器學習在醫學應用的重要性和作用分析
關于人工智能和機器學習在醫學應用的重要性和作用分析
經美國食品藥品監督管理局(FDA)批準后,第一批可穿戴式數字健康監測儀目前剛剛上市,并集成在諸如智能手表之類的消費產品中。醫學傳感器技術的不斷快速發展,使得小巧、經濟且精度越來越高的生理傳感器被應用在現有的可穿戴設備中。
前沿的機器學習和人工智能算法正是這種轉變的驅動力之一,它們能夠從海量數據中提取和解讀有價值的信息。這些數據往往包含噪聲和不太完美的信號(比如智能手表上的心電圖數據),并被各種偽信號所破壞,傳統算法常常是基于規則和確切性的,因此難以妥善處理這類數據。
直到最近,解開這些傳感器發出的生理信號中的秘密,并做出足夠準確的決策,從而被申報監管機構接受仍然非常困難,有時甚至是不可能的。而機器學習和人工智能算法的進步,正使得工程師和科學家能夠克服許多這樣的挑戰。
通過這篇文章,讓我們一同來仔細看看生理信號處理算法的總體架構,理解背后的運算過程,并將其轉化為經過數十年研究建立起來的現實中的工程技術。
機器學習算法的開發主要包括兩個步驟(圖 1)。
第一步是特征工程,從相應的數據集中提取特定數值/數學特征。
第二步,將提取的特征輸入一個廣為人知的統計分類或回歸算法,如支持向量機或適當設定后的傳統神經網絡(訓練好的模型可用于對新的數據集進行預測)。利用一個合理標記過的數據集對該模型進行迭代訓練,在達到令人滿意的準確度后,就可以在生產環境中作為預測引擎在新數據集上使用。
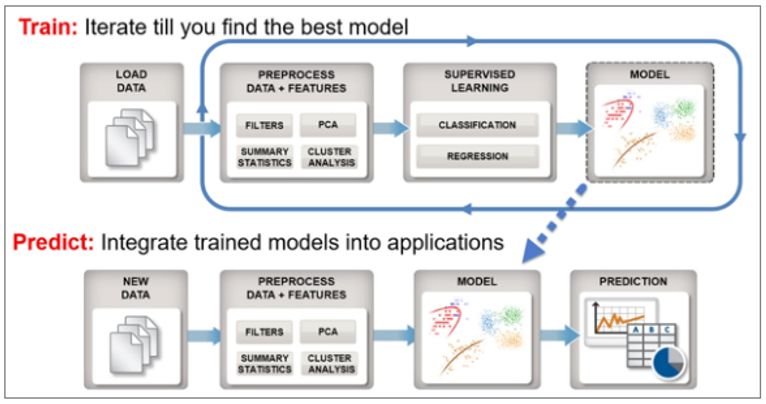
圖 1. 典型的機器學習工作流程包括訓練和測試階段。
那么,對于心電信號的分類問題,這個工作流程是如何實現的呢?
在本案例中,我們采用了 2017 年的 PhysioNet Challenge dataset,其中使用了真實的單導聯心電圖數據。目標是將病人的心電信號分為四類:正常、房顫、其他心律和雜音過多。
在 MATLAB 中處理這個問題的整個流程和各個步驟如圖 2 所示。
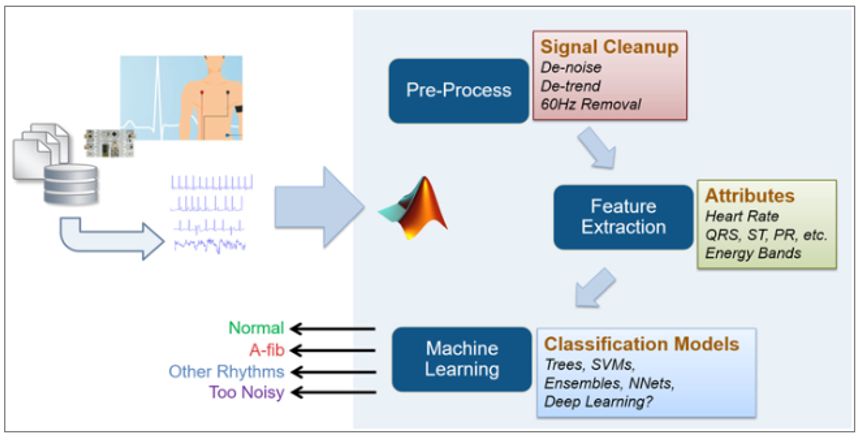
圖 2. MATLAB用于開發心電信號分類的機器學習算法的工作流程。
預處理和特征工程
特征工程可能是開發一套魯棒的機器學習算法中最難的部分。這類問題不能簡單地視為“數據科學”問題,因為在探究解決方法時,掌握生物醫學工程領域的專業知識,了解不同類型的生理信號和數據非常重要。
MATLAB 等工具為領域專家提供了數據分析和高級機器學習功能,使他們能夠更容易地將“數據科學”功能(如高級機器學習功能)應用于他們正在解決的問題,從而專注于特征工程。在本例中,我們使用先進的小波技術對信號進行處理,以去除數據集中的噪聲和漸變趨勢,如呼吸偽影,并從信號中提取各種需要關注的特征。
開發分類模型
統計和機器學習工具箱中的分類學習應用程序,對于對機器學習不太熟悉的工程師和科學家來說,是一個特別有效的切入點。
一旦從信號中提取到足夠多實用的相關特征,我們就能使用這個應用程序來快速探究各種分類器及其性能,從而縮小模型選擇范圍,用于進一步優化。這些分類器包括決策樹、隨機森林、支持向量機和 K 近鄰(KNN)。您能夠嘗試并選擇出能夠為特征集提供最佳分類性能的策略(通常使用混淆矩陣或 AUC 等指標進行評估)。在示例中,我們只采用這種方法就快速實現了所有類別約 80% 的總體準確率(本次比賽的獲獎項目得分大約為 83%)。注意,我們沒有在特征工程或分類器調試上花費太多時間,因為重點是驗證方法。
通常,花時間進行特征工程和分類器調試,可以顯著提高分類準確度。深度學習等更先進的技術也可以應用于此類問題,其中,特征工程、特征提取和分類步驟會被整合到單一訓練步驟中,然而與傳統的機器學習技術相比,這種方法通常需要大很多的訓練數據集,以達到期望的效果。
挑戰、法規和對未來的承諾
雖然許多常見的可穿戴設備還不能完全取代 FDA 批準并經醫學驗證的對應設備,但所有的技術和消費趨勢都明確地指向這個方向。FDA 已經開始在多方面積極發揮作用,例如簡化法規,通過諸如“數字健康軟件預認證計劃”這樣的舉措,鼓勵管理科學的發展,和設備開發的建模仿真等。
人們希望,將從日常可穿戴設備中收集到的人體生理信號轉換為一種新型數字生物標記,以全面反映我們的健康狀況。如今,這一愿景比以往任何時候都更加真實,這在很大程度上要歸功于信號處理、機器學習和深度學習算法的進步。MATLAB 等工具所支持的工作流程,使醫療設備領域的專家,在即使不成為數據科學家的情況下,也能夠采取并利用機器學習等數據科學技術。
-
人工智能
+關注
關注
1792文章
47376瀏覽量
238877 -
機器學習
+關注
關注
66文章
8423瀏覽量
132752 -
數據分析
+關注
關注
2文章
1452瀏覽量
34075
發布評論請先 登錄
相關推薦
【「具身智能機器人系統」閱讀體驗】+數據在具身人工智能中的價值
具身智能與機器學習的關系
人工智能、機器學習和深度學習存在什么區別






 工商網監
工商網監
評論