 關于新版 ISO 26262-6 之基于模型的設計的分析和應用
關于新版 ISO 26262-6 之基于模型的設計的分析和應用
為什么ISO26262這樣的國際標準里會頻頻提到基于模型設計?
原因非常簡單——基于模型設計在汽車行業已經被廣泛應用了。作為國際標準,ISO26262的目的之一應該是通過標準的方式規范行業開發行為,所以制定標準的基礎就是這種開發行為在行業的廣泛應用。這在民航領域的DO-178也可以得到印證,早在1992年發布的DO-178B,標準里沒有任何關于基于模型設計的討論——因為那個年代沒有公司使用基于模型設計開發民航軟件,而到2011年發布DO-178C的時候,同時發布了附件DO-331專門討論基于模型的設計在民航軟件開發中的應用,因為在2011年,基于模型設計已經在民航領域廣泛應用了。
基于模型設計的討論在ISO26262-6里面,跟第一版一樣,除了標準正文的各種條款里提到基于模型設計模式下應該如何要求之外,還專門有附錄B討論基于模型設計。本篇主要介紹附錄B的一些變化。
線下交流
ISO 26262研討會
主要介紹MathWorks工具鏈對于ISO26262和SOTIF的支持情況,涵蓋滿足ISO26262要求的模型驗證和代碼驗證、符合ISO26262軟件開發過程中的工具審核問題,以及針對無人駕駛應用的場景建模仿真等方向。掃描二維碼注冊>>
跟第一版不同的是,第一版的附錄B基本上只提到了基于模型設計如何如何的好,而第二版除了保留了這些優勢的陳述之外,還提到了在這種開發模式下的注意事項。主要優勢如標準所言,基于模型設計將“軟件生命周期的各個階段實現了更強的聚合(Strongercoalescence),并且認為:
“Thispotentialbenefitsofthisapproach(e.g.continuity,informationsharingacrossthesoftwarelifecycle,consistency)areappealing.”
同時跟了一句:
“butthisapproachmayalsointroduceissuescausingsystematicfaults(SeeB.3).”
于是就有了B.3,下面我們就對照B.3著重看一下可能有哪些風險以及如何應對。
一. 文本性描述
標準對單一的建模語言可能不足以充分描述需求、架構以及單元設計有所顧慮。確實如此,如果你認為既然選擇了基于模型設計,所有的需求、設計都使用圖形化描述,完全沒有文字說明的話,那的確是有問題的。標準要求在圖形化描述不足以完整描述需求、設計的時候,增加文字性描述。
這部分內容不僅僅在附錄里有體現,在標準正文里也有改變,Table2中的1a,就是新增的內容,并且針對不同的ASIL等級,都給出了++的要求。
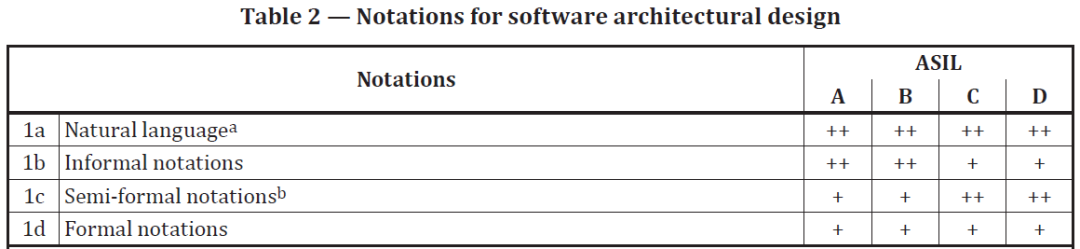
從本人的開發經驗,以及這些年接觸到的客戶來看,沒遇到有用戶僅依賴于模型而不使用文字描述的案例,標準里對這部分內容的增加,或許是制定標準的人或者做標準認證的人遇到了這種情況。
其實Simulink模塊有很幾種方式可以增加文字性的描述,比如簡單的文字注釋,或者正式的需求文檔,如下圖:

實現這部分要求,難度不大。
二. 背靠背(back-to-back)測試
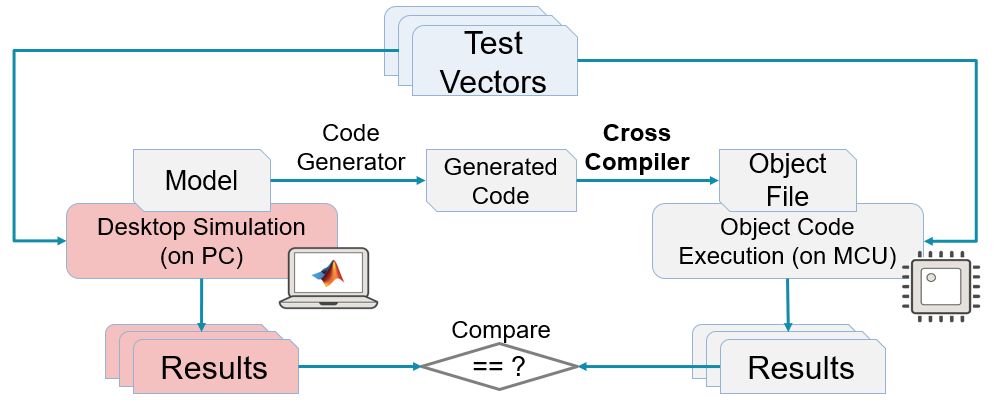
上圖就是一種背靠背測試的實現方式,這里的目標代碼運行在MCU上,我們稱之為PIL。PIL之外,SIL測試也是一種背靠背測試,前面也有介紹(為什么一定要做SIL測試)。
顯然上述圖中的PIL測試是為了檢查模型生成的代碼在MCU上運行,從行為上講,跟模型是否一致。
如果同樣的測試向量(TestVectors)在兩邊運行的結果一致,那么我們可以認為代碼和模型在行為上一致。注意,需要有個前提,那就是測試數據足夠多,可以覆蓋所有軟件結構以及信號范圍,那是最好的。通常,我們在這個時候除了重用功能測試的測試用例之外,還可以通過工具自動生成一些測試用例,以便可以達到更高的覆蓋要求。SimulinkDesignVerifier提供測試數據自動生成功能可以用于這個階段。
代碼和模型之間的背靠背測試,主要是為了防止模型到代碼的轉換過程中出現錯誤,標準還提到了其他兩種轉化的過程中也可能出錯:
一是從連續模型往離散模型轉換的過程(離散化)中引入錯誤;
二是從浮點模型往定點模型轉換過程(定點化)中可能出現的錯誤。
這種擔心是有必要的,在這兩種轉換過程中確實可能引入錯誤,實踐中,建議對離散化、定點化前后的模型做一個背靠背測試。
對于定點化,除了明顯的定點錯誤會導致出錯之外,還可能會隱藏一些測試數據或者測試場景覆蓋不到的溢出。所以,定點化之后的模型建議通過SimulinkDesignVerifier檢查一下是否有溢出問題。
另外,標準提到了仿真或者驗證的工具依賴問題,其實從SIL和PIL測試中,算法的運行平臺已經是完全不同的了,模型仿真的時候,是Simulink引擎解析模型運行,SIL測試的時候,運行的是生成代碼編譯之后的動態鏈接庫,PIL更是運行到了目標處理器之上。
三. 安全相關的代碼設置
代碼的安全相關設置,可以通過代碼生成設置和建模實現,比如,標準提到的溢出問題,在生成代碼的設置里,就有默認的優化設置如下:

當然,如果你非常關心代碼效率,并且能夠確保數據不會發生溢出,也可以通過勾選上述選項達到代碼優化的目的,切記,前提是確保數據不會發生溢出!
如何確保?人工確保非常困難,可以通過形式化工具SimulinkDesignVerifier實現。
另外,還有一些對代碼的保護要求,比如,有安全要求的代碼要放到專屬的Flash區域。通常,代碼上可以通過在這段代碼前后增加#pragma的方式實現,這可以通過自定義存儲類的方式實現。
還有一類要求,比如在運行某段代碼的時候不響應中斷:

這可以通過建模實現,比如,模型中增加SystemOutputs模塊,設置相關參數得以實現。
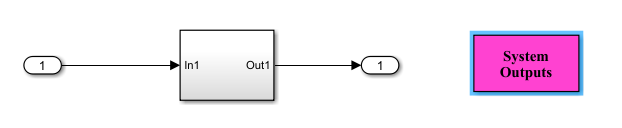
如果還有其他的安全要求,也可以跟我們交流。
四. 代碼優化問題
針對不同的優化目標,代碼可以做不同的優化,比如說,在新能源汽車領域,BMS開發中可能更關心代碼的RAM占用,而電機控制器開發中更關心代碼的執行速度。對于這兩種情況,顯然優化目標不同,選擇的優化設置也會有所區別。
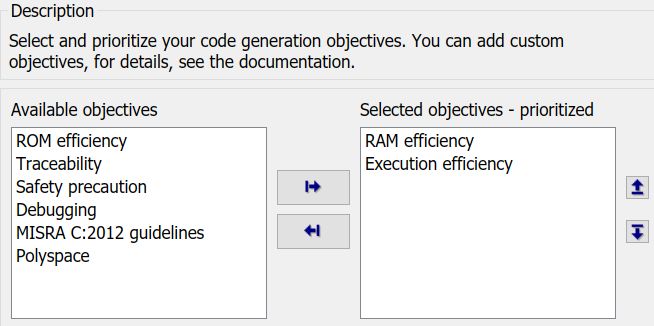
對應不同的目標,會有很多相關的優化選項需要設置。幸運的是,代碼生成工具提供了上圖的功能,用戶只需設置目標,工具會根據你設定的目標給出相應的建議。
五. 組件模型代碼生成問題
到底在單元模型級別還是集成模型級別(包括組件級集成和系統級集成)上做代碼生成這樣的問題,我一直認為要慎重,基礎軟件對于應用軟件的調度應該是我們要考慮的。對于簡單的調度,不同任務之間不存在搶占,不存在中斷,在集成模型上做代碼生成會更加方便,而如果任務之間可能存在搶占或者中斷,那么就要仔細評估了,因為,Simulink目前并不能仿真搶占或者中斷行為。
六. 被控對象模型的精度問題
這個問題會出現在MIL和HIL測試中,通過被控對象模型實現模型級閉環測試。理論上講,精度越高越好,但實踐上,我們可能很難有高精度并且非常完善的模型。這不影響我們利用MIL和HIL測試給我們帶來的便利。如果有理想中的高精度模型,我們完全可以在模型階段把標定做完,而事實上,我們沒有那樣的模型,我們也不期望這個階段完成標定工作。我們希望可以通過這些模型實現驗證算法,這已經給我們帶來很大便利了。
當然,也有辦法讓被控對象模型變得精度更高,比如可以通過臺架測試數據或者實車數據去優化模型參數,還可以通過基于模型的標定(Model-BasedCalibration)技術實現部分參數的標定工作。
-
處理器
+關注
關注
68文章
19343瀏覽量
230229 -
代碼
+關注
關注
30文章
4801瀏覽量
68735
發布評論請先 登錄
相關推薦
廣汽部件榮獲SGS ISO 26262 ASIL D功能安全流程認證
華陽通用通過ISO 26262 ASIL D認證
鑒源實驗室·ISO 26262中測試用例的得出方法-等價類的生成和分析

什么是汽車ISO 26262功能安全標準?

芯來NA系列產品再獲ISO 26262 ASIL-D產品認證證書

【直播預告】基于ISO 26262實現高質量的MBD過程

威靈汽車獲得ISO 26262 ASIL-D汽車功能安全流程認證證書

美行科技通過ISO26262:2018汽車功能安全ASIL D流程認證

天合智控獲DEKRA德凱ISO 26262汽車功能安全體系認證證書

超星未來通過 ISO 26262 功能安全管理體系 ASIL D 認證

技術分享 | ISO 26262中的安全分析之FMEA

芯驛電子獲得ISO 26262汽車功能安全最高等級ASIL D認證

星宸科技獲ISO 26262功能安全管理體系ASIL D等級認證,進軍車規級市場
孚能科技獲DEKRA德凱ISO 26262汽車功能安全產品認證證書






 工商網監
工商網監
評論