

思必馳聯合創始人、上海交大教授俞凱在機器之心和 Comet Labs 聯合舉辦的「Interface 智能機器系列活動」上做了題為《自然語言處理中的認知計算》的演講。
1)首先,俞凱教授對自然語言處理與對話系統的基本概念進行了深入解讀,強調了「交互」的重要性;
2)分析了人工智能與認知計算的概念和關系,介紹了如何通過交互架構的重新設計來解決交互層面的認知問題;
3)講解了與自然語言處理相關的認知計算進展,包括如何通過傳統方法和深度學習來解決特征表達問題,用 RNN 和 LSTM 來解決記憶遺忘問題的技術原理,并對序列級的編碼器-解碼器架構進行了重點講解;
4)介紹了解決聊天、問答、任務型口語對話三類對話問題的認知計算技術;
5)最后,俞凱教授介紹了自然語言認知交互的未來,并表示,圍繞這個問題,思必馳會在今年年底提出一種全新的理論研究框架。
俞凱,思必馳聯合創始人兼首席科學家,劍橋大學語音博士,上海交大教授,IEEE 高級會員,***計劃」、NSFC 優秀青年科學基金獲得者,上海市「東方學者」特聘教授,中國語音產業聯盟技術工作組副組長。清華大學自動化系本科、碩士,劍橋大學工程系博士。 2012 年在上海交通大學創建智能語音技術實驗室,將人機口語對話系統的全面技術引入回國。在人機口語對話交互的主要核心技術領域進行了廣泛研究,在國際一流期刊和會議上發表論文 80 余篇,獲得 ISCA 頒發的 2008-2012 Computer Speech Language 最優論文獎等多個國際期刊和會議優秀論文獎。俞凱多次擔任 InterSpeech 等國際會議的對話或語音處理領域主席,多次在美國國防部、美國國家標準局組織的大規模語音識別評測,國際研究機構組織的對話系統挑戰賽等國際評測和競賽中獲得冠軍,2014 年獲得中國人工智能學會頒發的「吳文俊人工智能科學技術獎」進步獎。
思必馳,國內唯一一家專注于智能硬件領域的智能語音方案服務商,團隊成立于 2007 英國劍橋,2008 年回國落戶蘇州后一直從事于智能語音技術研發,2014 年之后全面專注于智能硬件企業的語音交互技術。目前已經在車載、家居、機器人領域進行了全面戰略布局,并與小米、YunOS、阿里小智、高德、海爾、魅族、慶科、君正、聯想等一流企業達成合作,并先后獲得兩輪融資。思必馳受到市場青睞的背后,依托的是強大的技術研發實力,這得益于其與上海交大聯合成立的智能語音研究實驗室,該實驗室由俞凱負責。
今天我分享的主題是語言。我自己在劍橋大學待了 10 年,前 5 年做語音識別方面的研究,當時和美國人去 PK ,在美國國防部電話監聽的項目里面去看誰的語音識別率高。而后 5 年,我做的是另外一件事,是對話系統研究,這個不同于原來的語音識別。我回到國內之后,包括我在做研究和企業創業過程中,很多人都介紹我是搞語音識別的,我每次都要做一個補充糾正。今天很高興,這可能是我回國第一次,據我所知恐怕也是在國際上第一次有人來仔細的講,我們這些從語音出來的人是從何種角度來做自然語言處理的,而且為什么說我們這個角度,被稱為「對話」,是殊途同歸的全新人機交互的未來。之后希望大家記住我們所做的東西叫語音交互。
今天演講有四部分,前兩部分我會講什么叫對話,它和自然語言處理是什么關系,今天的主題叫做自然語言處理中的認知計算。什么叫認知?自然語言處理里的認知和自然語言處理是什么關系?它有什么不一樣?如何在人工智能的框架下來研究?
后面兩部分是講:1)近期,尤其是深度學習發展起來之后,和自然語言處理相關的,對認知計算產生重大作用的一些工具,這主要是指理論工具的進展;2)在自然語言對話方面,我們在實踐和研究中做了哪些工作,方向是什么。
一、自然語言處理與對話系統
自然語言處理是一個很傳統古老的學科,國內外在講自然語言處理時基本是沿著語言學這條線,因為自然語言處理最早是由計算語言學專家提出,現在自然語言處理領域的頂級國際會議也都與之相關。從語言學的角度來說,自然語言處理的典型任務有:分詞、詞性、句法分析和語義分析。

在近二十年,從應用角度研究自然語言處理的人逐漸多起來,因此,出現了許多人用機器學習去研究自然語言處理。但是,近二十年的主流仍然以語言學的元素為核心,同時采用機器學習的方法去研究。應用的任務中,最典型的是1)命名實體識別,比如說聯想之星(注:演講所在地)這是一個命名實體,它不是一個人,我們把它識別出來;2)文本分類和信息檢索,這在谷歌和百度相關搜索應用里非常多;3)最典型的一類是機器翻譯,統計方法在這一類上的應用非常多。但是近二十年的前段時間,研究主流都還是借助語言學相關元素,基于語言學的相關規則做翻譯,比如說要先把句子的順序搞對,然后再做單詞的翻譯,等等。
我們今天所講的是一個新的話題,移動互聯網帶來了一些新的語言智能,這個智能就是交互。我們通過一段 Siri 的視頻了解一下 ,今天演講中會大量使用 Apple 的視頻,因為它是一個先驅,它的發展歷史反映了我們對自然語言處理理解的不斷進化的歷史。
從 2011 年 iPhone 4s 發布時介紹 Siri 的一段視頻中可以明顯的看到一個很重要的特點,就是交互。移動互聯網出現后,自然語言處理進入到一個需要考慮交互的新時代,此時的傳統處理技術遇到了很多不能解決的問題。最初蘋果公司也沒意識到這個問題。

上面這個圖代表了 iPhone 交互進化的歷史。最開始是智能電話,前兩代沒有語音交互的,之后他們做了一個市場調查,發現 75% 的人希望有語音控制,后來就在撥號和導航功能上加上了語音控制,但發現經常使用的人不到 5% ,于是他們開始反省為什么是這樣,不是想要語音嗎?怎么不使用了?他們后來得出的結論是,用戶不單單需要語音,而是要把機器當成一個 Agent ,要用自然語言和機器進行交流,這樣的東西人們才會用。而他們這些思考的結晶就是后來 iPhone 4s 上的 Siri ,發現 87% 的用戶每個月都會使用一次 Siri,這時我們發現:語音不能簡單的作為鍵盤替代品,它需要變成用自然語音和語言交互的手段。后來又發現一個問題,用戶的絕大部分是在調戲siri,是沒有與Siri 進行真正有目的的交互行為的。于是,他們就開始考慮再往后的未來是什么?我的一個朋友,Jerome Bellegarda,蘋果公司的 Distinguished Scientist on Human Langage Technology,在 2013 年的國際會議上和我談起,需要用一種新的途徑去衡量語音功能的好壞,要去看整體的完成率是不是足夠高。語音也好,語言也好,最終要看幾個輪回交互過程之后,是不是能夠完成用戶的目標。
而這里就立刻出現了一個問題,我們在原始情況的語音控制是單輪的,比如說開燈這個命令,但一個單輪命令在自然語言的情況下是無法滿足人類需求的,所以必須要多輪,這也是為什么蘋果在 2015 年收購了 VocalIQ,它專門研究基于統計的對話系統,蘋果希望用他們的研究來打造下一代 Siri,所以蘋果現在在歐洲招了很多人專門做多輪交互方面的研究。這之后,Siri 原來創始團隊的人就離開了,他們出去創辦了一家新公司,就是最近新聞比較多的 Viv,而這家公司講到一句話「Conversational interface to anything」,第一個詞就是「對話式的」。
大家可以從蘋果整個進化發展史中看出,他們把語音和語言引進來,得出兩大結論,1)要自然;2)要有交互。這就是為什么說自然口語對話是自然語言處理中的一個新興任務,我前面提的搜索、翻譯等都沒有。因此,除了蘋果一家,之后 Google Now 推出來了,2014 年微軟有 Cortana,還有最近亞馬遜的 Echo,不管是哪一種,它們都是助理,而助理的核心特點是要通過交互去理解用戶的意圖并完成任務,并且一定要用自然語言交互。
而這也是我們思必馳在做的事情——語音對話交互技術的整體解決方案,而不是單純的語音識別解決方案。

需要注意的是,語音識別加上傳統的自然語言處理,并不等于語音交互,這是因為在真正解決對話時,傳統的自然語言處理不能夠解決對話當中的一些新問題,比如說一些認知計算的問題。
因此,對話不是傳統的自然語言處理,它是一個新興任務,事實上在一個系統里面,不同類型的對話,采用的技術是千差萬別的,一個商業級的系統往往要采用這些技術的組合。而對于研究來說,則必須當成幾種基本的不同類型分別去做,因為對話是相當復雜的,大體可以分成三種不同類型:
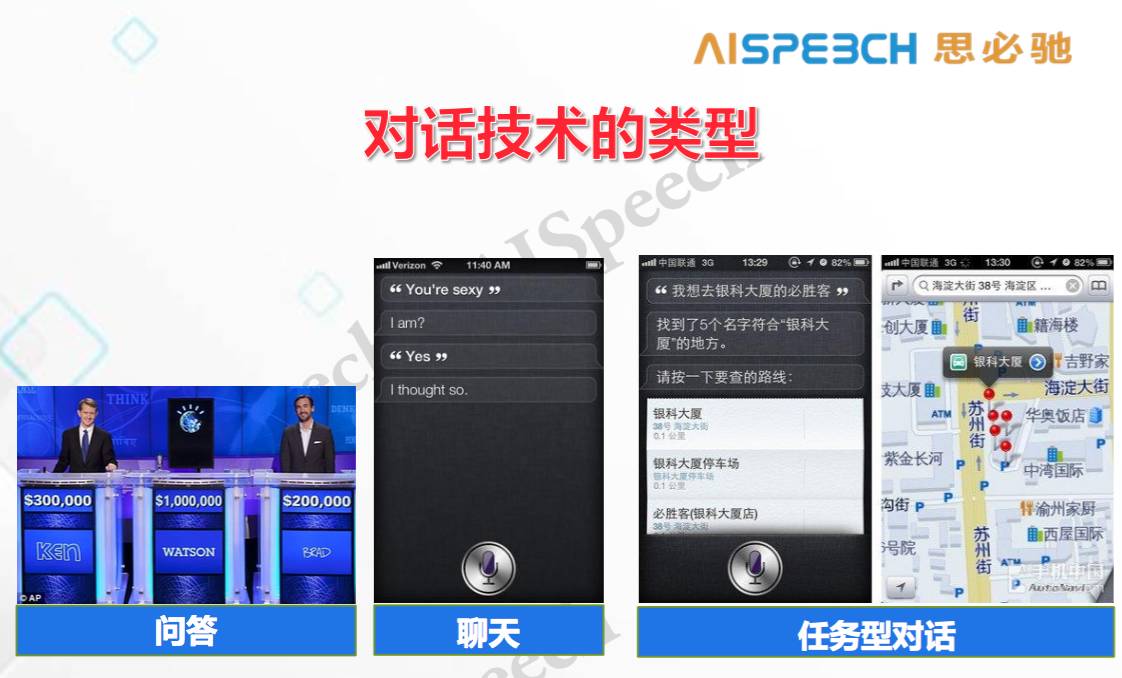
第一類型是問答。這類對話的特點是,1)單輪的,往往是一問一答;2)非結構化,沒有辦法用一種數據庫、語義槽的方式去表達。一問一答的方式往往涉及到后端的知識搜索,以及在回答中的匹配。
第二類是聊天。問答是要完成任務和提取知識點,有非常明確的信息需求,而聊天的情況千差萬別,因為很多時候是沒有問題的。從本質上講,聊天是人類復雜交互的一個非常集中的體現,這一類任務是最難的也是最容易的,說最容易是沒有正確和錯誤,只要有意思就行了;最難是指,用現有技術去做可控的聊天是不可能的。
第三類是任務型對話。所有東西都是以任務為核心,所以它有一個本體的概念,問答里面絕大情況沒有本體概念,在任務型對話中,你可以把很多信息形式化,最極端的例子就是把它變成一個數據庫的查詢,通過交互不斷去做結果更新。復雜一點的話,開放的領域和語義槽有很強的模糊性,這些東西也是需要處理的,但無論如何,它們都是有直接的最終目標。第一類的問答不一定有直接最終目標,它只是獲取一次信息,而任務型對話絕大部分都是多輪的。
未來要把對話這個事情做好,那一定是以上三種類型都做好了,但這種可能性很低,一定是先有一些東西,然后再補充其他東西。
下面是一個關于 Siri 的惡搞視頻,從里面你會發現我們所希望的智能機器是怎樣的,這里體現出人類對真正能夠產生智能反應的機器的認知。
從這個視頻可以發現,里面這個 Agent 和我剛才談的東西有一個飛躍——它是「自主的」,一個真正未來可對話的 Agent 不單單需要交互和認知去完成任務,還需要有自主意識,這才是擁有真正自然語言智能的一個比較完整的機器,它真正變成了一個大腦,我們現在還走不到這里,但是我們如果想要走到這兒,還需要很多的途徑。
從業者都知道,但凡是自然語言處理的東西,它簡單的一面是,你總可以通過寫規則達到一定效果,只要在你寫的規則范圍之內還是會表現的非常好。但讓我們非常感興趣的一件事情是,我們想要做的技術是要把規則上升到統計,一個不能在大數據里學習的技術,它絕無可能發展到去進行自主決策和交互,因此我們下面談到的將是,人工智能和認知計算之間到底是什么關系?我們是不是有一些辦法可以把剛才我們所說的和對話相關的東西逐漸變成統計?以及在這個路徑上我們會碰到什么樣的問題?下面就是在這個過程中我們碰到的問題及初步解決方案。
二、人工智能與認知計算
說到人工智能,「人工」比較好理解,但什么是「智能」,人工智能有兩條線,一條線是人的右半腦,屬于情感智能;另一條線是人的左半腦,屬于邏輯智能。這里只說邏輯智能,因為要完成任務。邏輯智能從低級到高級,包括了計算存儲;感知和表達對應的輸入輸出,就是聽說看聞觸行等;認知智能,主要是理解、思考、反饋和適應(即今天所講的認知);以及最高級的抽象知識處理智能,這里不涉及原子概念的模糊,往往是在一些已經形式化好的東西上去做分析、推理、歸納和演繹,像 AlphaGo 基本上是這個階段的智能。

這大體上是人工智能的一個框架,我們所說的語音識別是在感知智能;語義理解在感知智能和認知智能之間;對話的交互控制是在認知智能;問答系統后面的知識分析和知識圖譜處理,一部分在認知智能,一部分在抽象知識處理智能。

而我們現在比較關注的是,移動互聯網當中的人機對話,我們叫自然口語交互,和此前的自然語言處理不同,它最大的認知特性是不確定性。比如上圖中「等周二許春來到蘇州后約他九點鐘在九寨溝喝茶」這句口語表達有很多歧異的,需要結合上下文才能準確理解。另一方面,人在口語傳遞時一定不會給你一個特別完整的東西,認知科學里面有一個道理:不確定性和效率是有直接關系。不確定性比較高,效率就比較高;不確定性比較低,效率就比較低。你想要不確定低,你就把所有的信息毫無混淆的說出來,這時就需要用很長的文字編碼,編碼效率非常差。反之,傳遞很少的信息只需要很少的文字編碼,效率高,但信息的不確定性也高。而人類的口語交互都是試圖采用最低的不確定性實現最高的信息傳輸,必然會有不確定性。
交互中除了文字內容本身的不確定性,還有交互過程中產生的不確定性,因為用戶要求交互「要快」。比如大家以前都看過「山東高速糾正哥」的那個視頻。在這個視頻中,絕大多數的人第一反應是語音識別不準,但真正的問題其實是在于,當語音識別出現不確定性時,后面的理解及對話管理和推理能否去解決這個問題。剛才視頻中已經有了這個固定的語境,用戶就是要去糾正 135,然后讓機器去匹配。
這引發思考的是,即使識別完全正確,后面要做的事情是什么。這就是我們需要解決的認知計算的問題,以下是我們的認知型自然口語交互系統。
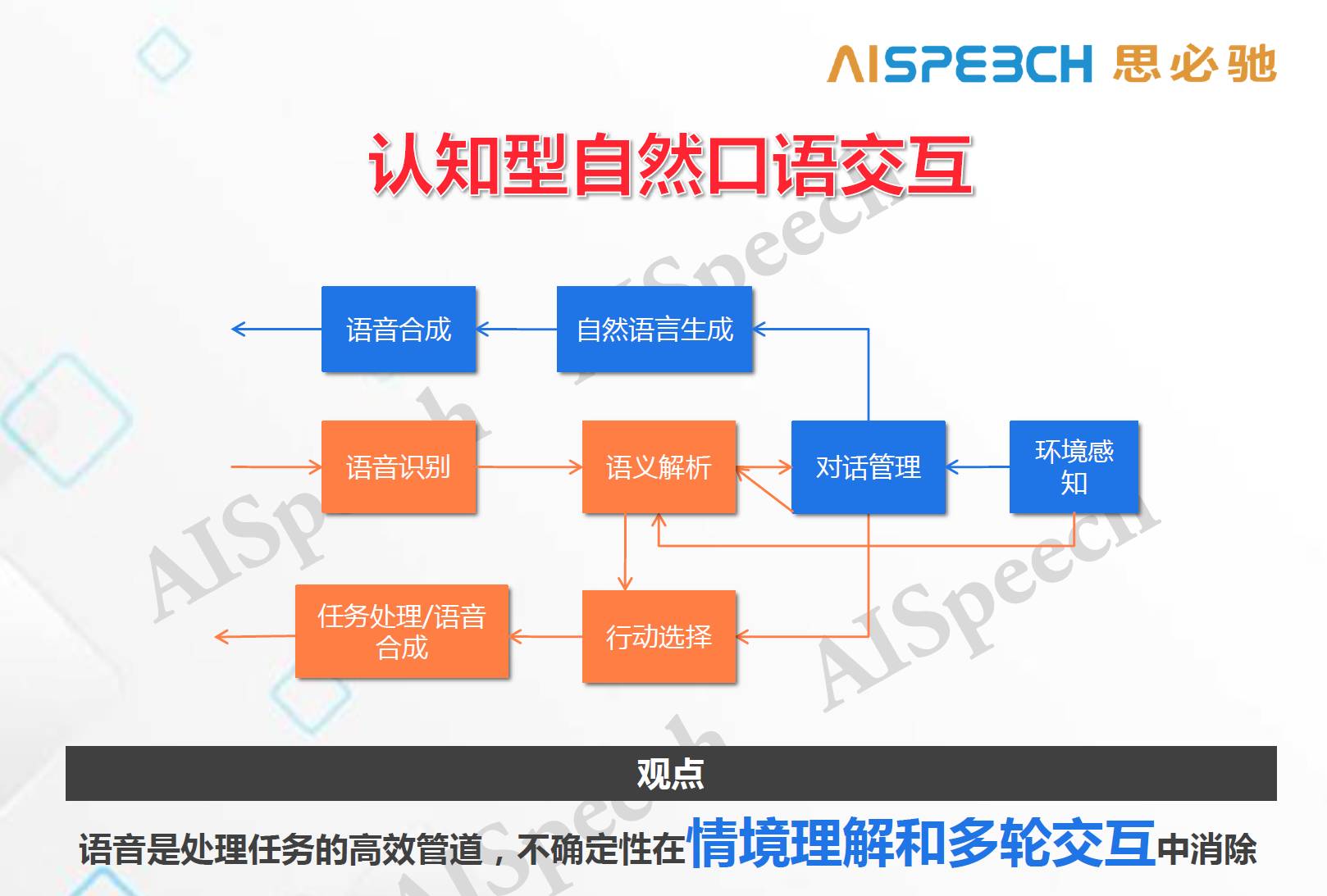
上圖中,橘色的是標準循環,藍色的是我們新添加進去的一部分環境感知和對話管理,簡單的說,我們添加了一個能夠更好監測和管理交互過程一個輔助設施,并且可以生成一些交互語言去做確認。這個架構體現了我們一個很重要的觀點,語音(包括語言)只是處理任務的一個高效管道,但它一定會有不確定性,不確定性應該在情景理解和多輪交互中消除,這是一個本質特征,它不會因為一些技巧而改變,有些技巧可能會使得單輪交互的效率會提升,我們也會做,但本質上是解決不了問題的。
所以,除了理解和交互內容本身,交互架構也會有一些相應調整,山東高速糾正哥這個視頻在本質上沒有那么復雜的自然語言處理,但它對交互的要求是比較復雜的。以下就是我們在改變了交互架構的前提下做出的 demo 。
思必馳糾正哥demo(思必馳提供)
所以,我們要在交互架構上進行處理,我們對于交互本身的理解要結合到情景,這就涉及到怎么去建模的問題。基于認知在交互里的三個層面,我們究竟要從科學上和工程上解決哪些問題。

第一個是靜態的,對某句話的不理解,你會有一些語義的表達,在特定的表達下面我會給他一個什么樣的值,這是一種理解方式;你也可以分成主、謂、賓語等,這些聯系到的領域(domain)是什么,可以有很多種聯系的方法;這里是對單句靜態的理解。
第二類是動態認知,在已經知道有多輪的情況下,機器如何回答,在面對任務時機器需要進行交互決策,這個過程是多輪里的一個動態認知過程,就是機器需要學習什么樣的反饋是最有效的,最能消除不確定性,并且把對話的成功率提高。
第三類是進化認知,即我有一次完整的實驗結果之后,我一定會對自己的總體策略、理解概念和上下文進行調節。
不管是哪一個類,在計算的角度上要解決幾個問題,1)怎么做模式分析和特征抽取;2)在動態過程中處理記憶和遺忘的問題,這在理解當中很重要,如何通過表示來解決抽象化的問題,此外還有推理、決策規劃和綜合反饋等問題。
三、自然語言處理相關的認知計算進展
接下來討論的是,大數據和新的機器學習方法在哪些方面對解決對話類自然語言處理比較有幫助。深度神經網絡、卷積神經網絡的循環神經網絡在機器學習中發展比較快,尤其是語音和圖像都取得了非常重要的進展。
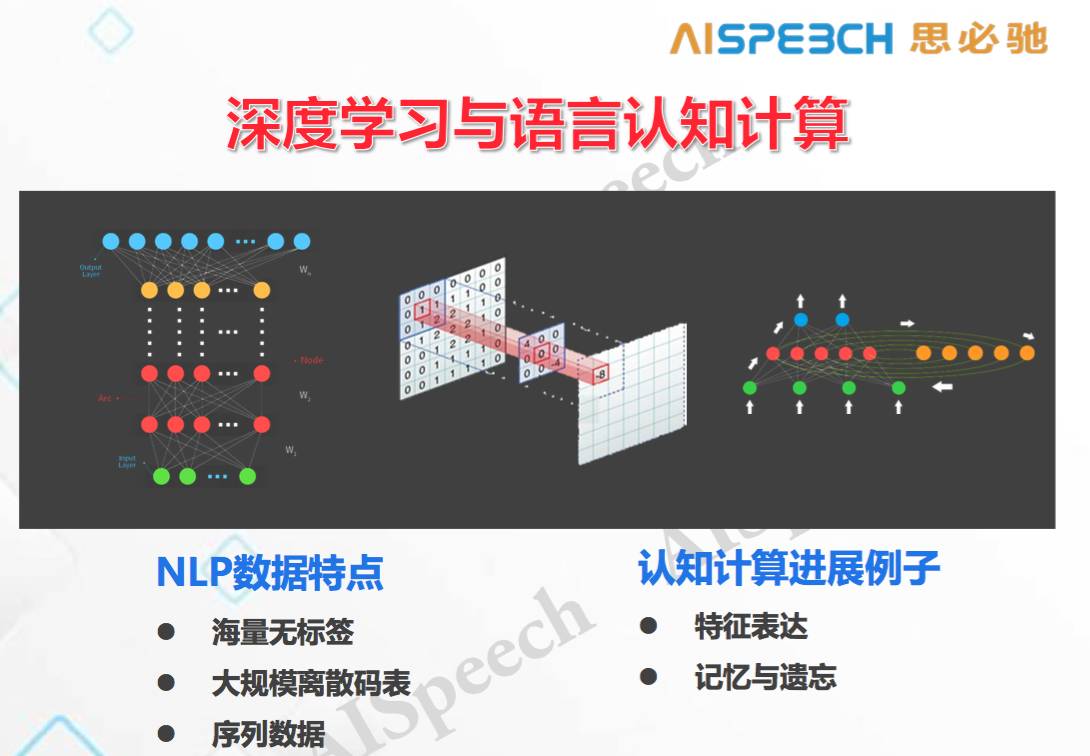
但語言數據有幾大特點(如上圖):
1)海量無標簽,如果做語音識別,用一萬小時去訓練模型應該足夠大了。如果用同樣的機器學習算法,折合到語言上面這大概相當于幾個 G 的語料,非常小,我們正常訓練大規模語言模型可能需要上百個 G 。所以語言所需要的數量比語音和圖像要大的多,而且無標簽。
2)有大規模的離散碼表,不管我們做圖像還是語音,輸入都是特征,輸出都是分類標簽,語音的分類標簽有大概有三千到一萬,圖像的大約是小幾千,而正常的一個通用詞表是有十幾萬個標簽,因此標簽類別大大增加了,而所需的數據量還特別大,所以對語言的處理難度很大。
3)自然語言是序列數據,不是點上的數據,這又使整個處理變得復雜。語音我們切成十毫秒一幀,而整個圖像是當成一個樣本點,一個輸入對應一個輸出,都是點對點的。而對于自然處理來說不是這樣,好的認知算法都是一個序列,所以從這個角度上來講,比較適合于自然語言處理的模型大部分都在循環神經網絡(RNN),因為它擅長處理序列。
我要講的關于認知計算的進展有兩塊,一個是特征表達,一個是記憶遺忘。
1. 特征表達,語言的分布式表達

上面提到,大規模離散碼表是自然語言處理中的一個核心難點,原始方法是用 0/1 向量去表達。現在如果我用分布式表達,即不是把所有信息集中在一個點上,而是要把它們分開,這樣就可以把維數大大縮小,比如說縮減到 100 位或者 200 位,在這種情況下就得到一些數字化的連續表達。現在有很多在做詞向量(Word Embedding)的研究,還有句子向量和語言向量等等。所以,很多人開始把離散的詞用連續的東西來表達。如上圖所示,和數字、人物等相關的都會自動的被聚類,這樣一類分布式表達為我們解決自然語言處理問題提供了基礎。
現在大體上有兩類方式來做分布式表達:
1)傳統的用基于count及線性代數的方法統計
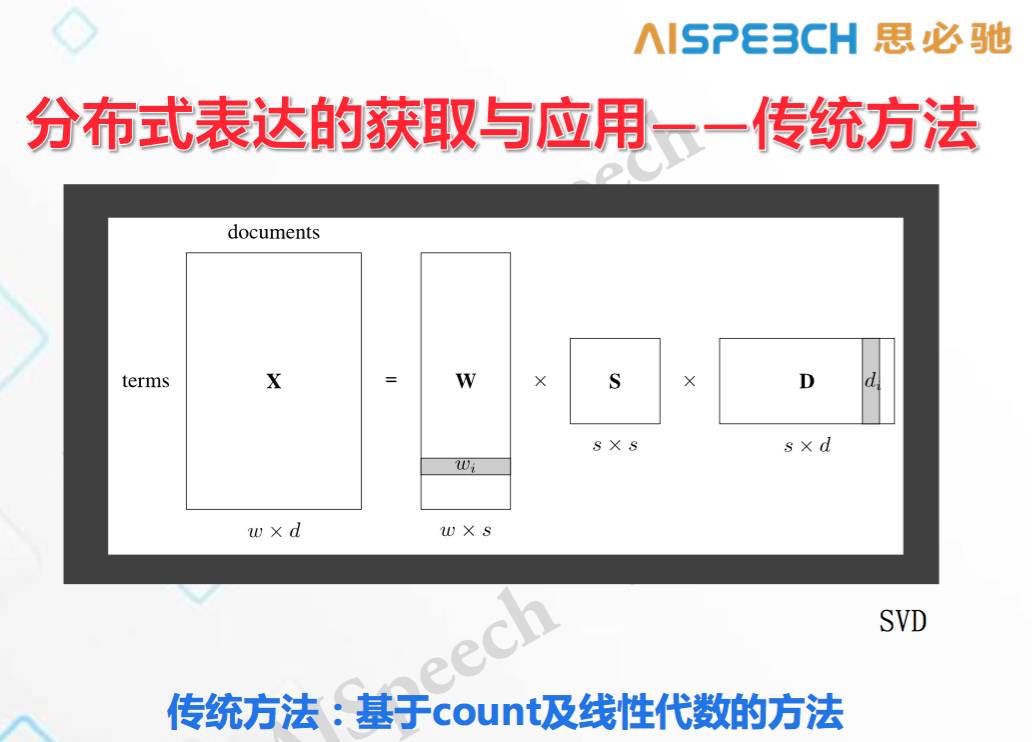
對于每一個文檔中,統計它的詞表,以及每個詞在不同文檔中出現的頻率,分解完成后就會在詞表上得到一個小的矩陣,然后根據它的頻度得出向量。這些方法是無監督的。
2)深度學習方法
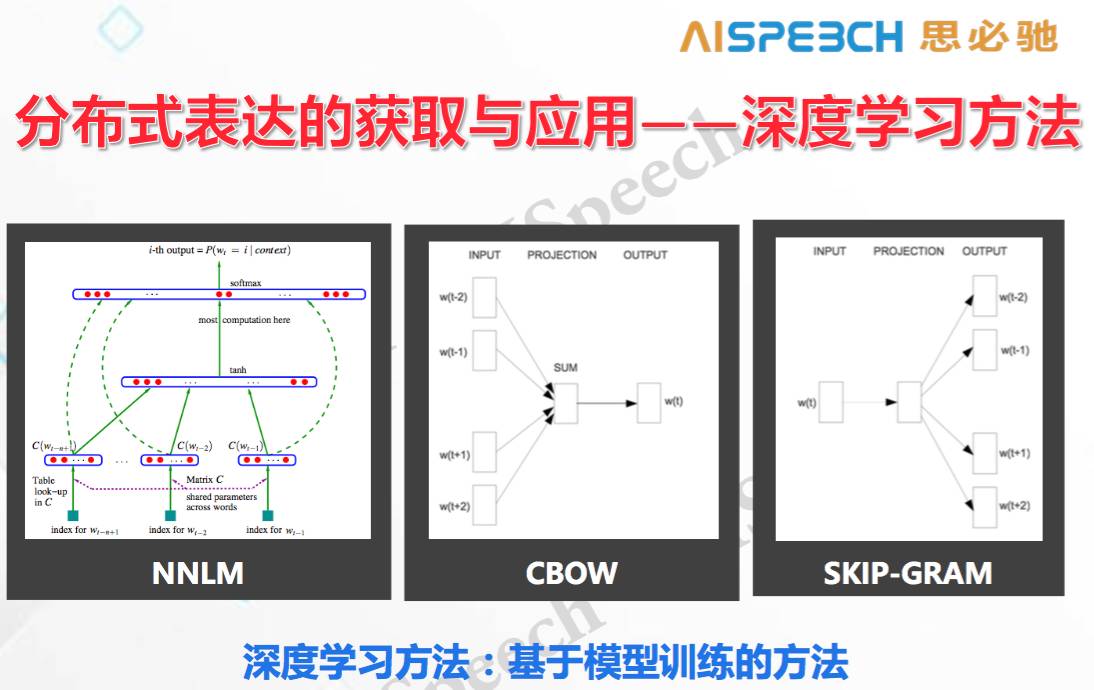
這種方法也可以認為是無監督,但要經過訓練。一般來說,深度學習要用一定的線性模型或非線性模型對海量語料進行訓練來得到詞向量,最典型的就是 Bengio 提出的 NNLM,我們輸入正常的文字,然后這個文字通過矩陣變換得到相應的文字的離散表達,這類似于在一個矩陣里,你的輸入取矩陣當中的一行。我們用這個東西在神經網絡里做預測,然后通過神經網絡的自更新得到每一個矩陣當中的行數,這些行就是它最終的詞向量。而 Thomas Mikolov 是用 CBOW 或者 SKIP GRAM 這樣偏線性的方式,用周圍的詞去預測中間的詞,或者用中間的詞去預測周圍的詞,都是用訓練的方式去預測,箭頭中表示的都是把原先的詞表從矩陣中取一行,變成相應的分布式方法。這里值得注意的是,上面提到的是訓練方法,沒有說準則,事實上最后做出來東西有沒有用,高度取決于你用什么樣的準則去訓練這樣的向量。而在認知計算里,如果你的準則是得當的,那你所得到的這個 embedding 會更好的用在你的認知任務里。
總之,這部分的意思是我們會把詞用連續的向量去表達。
2. 解決遺忘的問題
最典型解決遺忘的問題就是用傳統的循環神經網絡。
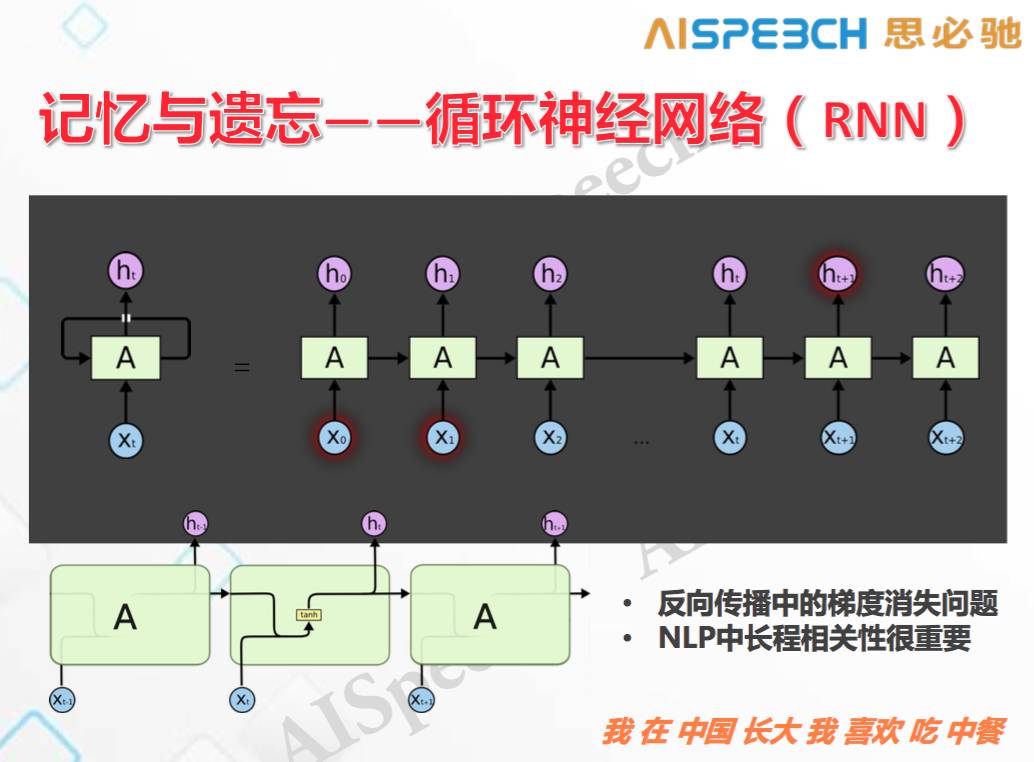
以上是循環神經網絡的結構圖,一個輸入有一個輸出,輸出不單單考慮輸入的信息,還考慮了上一個隱含層的輸出信息,可以循環回來。把它展開的話,對這一點輸入預測,既取決于當前輸入,同時也取決于上一個隱含層節點的輸出,而上一個隱含層節點的輸出又取決于這個節點的輸入以及再上一個隱含層節點的輸出,這樣下去的話就會把整個序列都考慮進去。在這個過程中,我們會用一個反向傳播算法(BP算法),但這個算法有一個比較麻煩的問題,當這些矩陣本身的模不是1或者不接近1的時候,傳的時間長了會存在梯度消失的問題。在語音識別里面這個東西往往影響沒那么大,因為我們考慮前面三五步就夠。但在自然語言處理中是不行的,長程相關性是非常重要的。比如說這個例子,「我 在 中國 長大 我 喜歡 吃 中餐」,當前面一個詞是「吃」的時候,我去預測下一個詞是不是「中餐」,這是一個概率。但在這句話里面,其實非常靠前的這個詞「中國」對于「吃」后面預測出來的詞是「中餐」還是「西餐」,會產生非常重大的影響,很早的一個詞對很后面的一個詞會產生影響。
這個例子說明,長程相關性在自然語言處理中是非常重要的。單純用循環神經網絡是不夠的,現在我們開始用長短時記憶模型(LSTM)去解決這個問題。
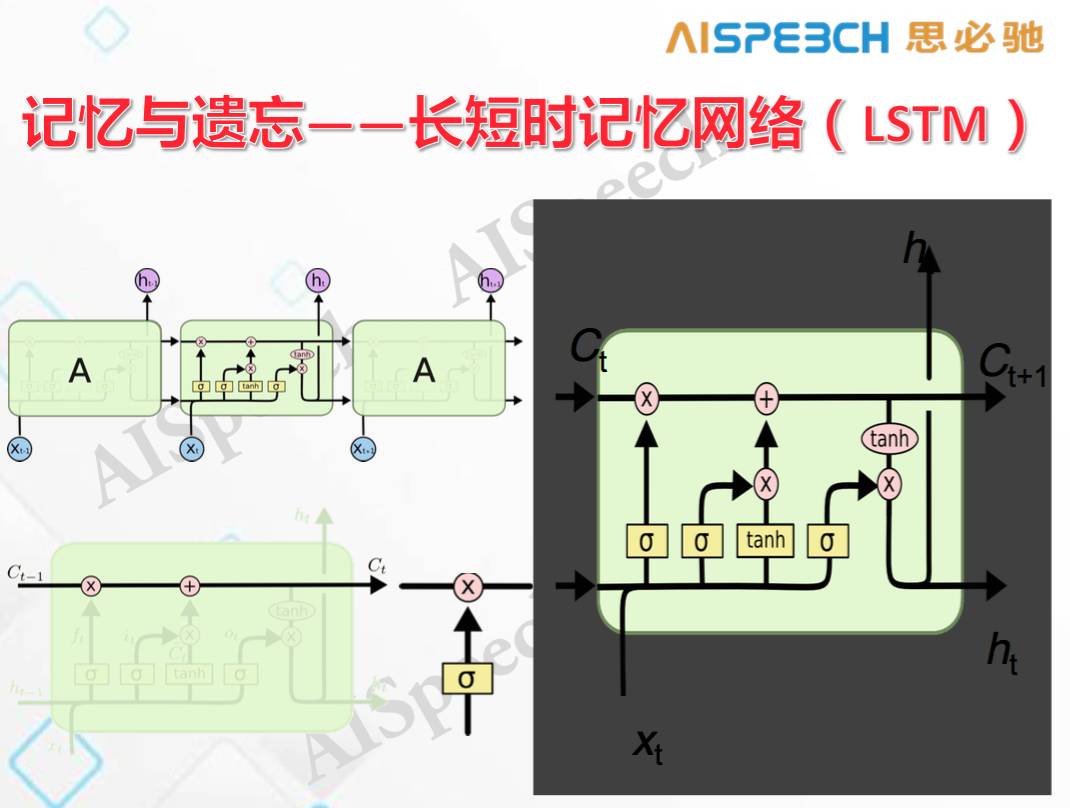
它可以通過一些門的限制使得原始的記憶信息采用線性的方式傳過去,而門只是選擇什么樣的信息該往下傳,什么樣的信息不該往下傳,它會采用一個遺忘機制使得你的記憶可以更牢靠。
剛才提到,自然語言處理里最關鍵的在于序列,所以我這里重點講的就是序列,對序列自身的建模有以下幾種形式,最原始的就是對序列進行記憶,對每個單元進行預測,這在自然語言里中的一個典型就是語言模型。
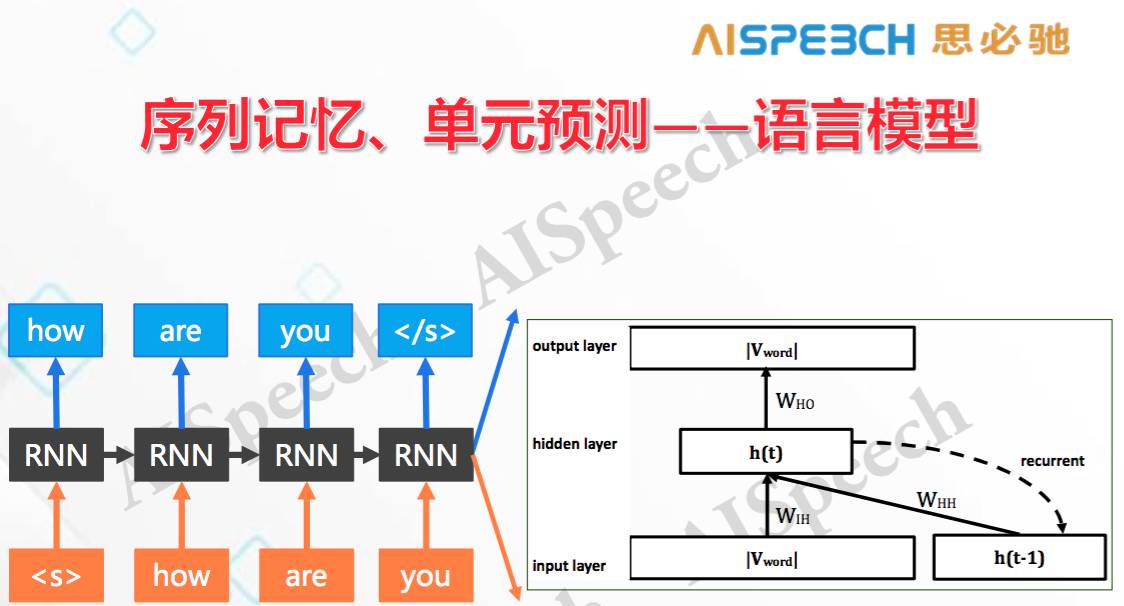
比如說「How are you」這句話,給定一個詞「how」,去預測下面一個詞是什么,因為在進行預測時,RNN的隱含層節點會不斷往下傳,所以當「are」的下一個詞時,我已經考慮了左邊左右的詞,以及當前的輸入「are」,然后去預測下一個是「you」的概率。所以這是對序列前面的歷史都記憶,但是一個點一個點的去預測。
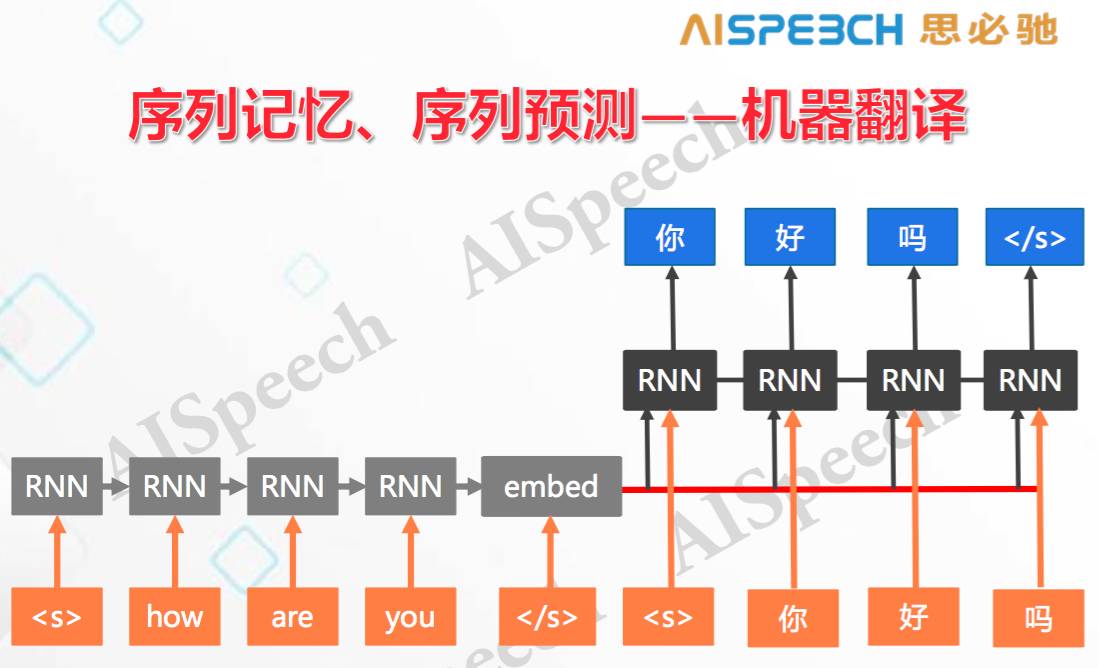
而比較新的研究是序列記憶,序列預測。是指把整個序列都吃進來,在肚子里面想一想,再把新的序列吐出去,機器翻譯就是這樣一個典型的任務,我把一個英文序列翻譯成一個中文序列。最開始的使用也是用循環神經網絡把每個詞都讀下來,讀每個詞時更新一下參數,但一直不輸出,直到把整個句子都讀完,在開始翻譯時才正式開始輸出,這時會把前面所有的歷史放在一起來,在句向量的基礎上預測新的語言中的詞,這就是序列的輸入和輸出。這一般叫序列級的「編碼器-解碼器」架構。
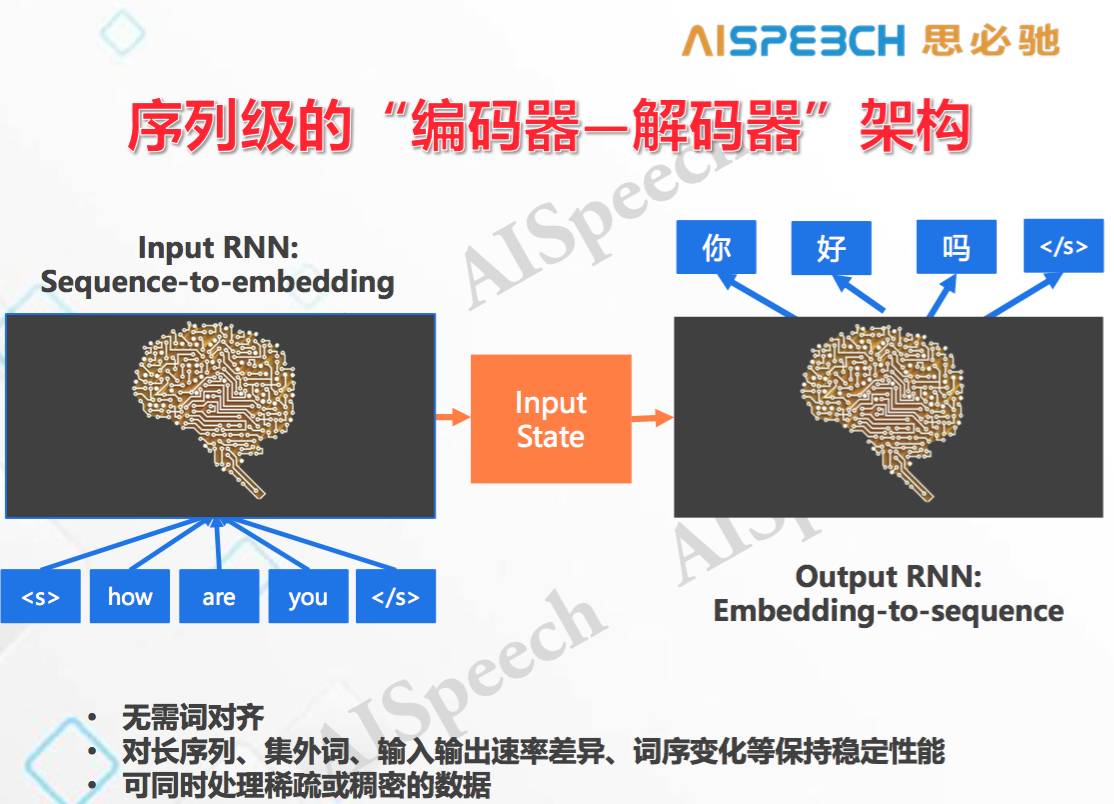
這種序列級的「編碼器-解碼器」和元素級的「編碼器-解碼器」具有一些本質不同,它最關鍵的不同在于特別適用于自然語言處理,因為:
1)無需詞對齊,現在做語義理解和機器翻譯最難受的一件事是每個詞都要做標記,而用序列和序列是不需要詞對齊的;
2)語義理解、翻譯等很多自然語言處理任務,經常出現長序列和集外詞的問題,比如說,很長的一句話會帶來很多干擾,包括一些集外詞,如果用一個詞一個詞的標簽去對的話,它的錯誤率是比較大的。同時出現輸入輸出速率差異,比如輸入 20 個字,輸出只有兩個語義項。還有詞序變化等等都會影響我們預測的準確率,如果序列到序列這些事都不用了。
3)可同時處理稀疏或者稠密的數據。可以看出,這種架構非常適合自然語言處理。
除此之外,注意力模型 Attention 也是最近特別流行的一個模型。
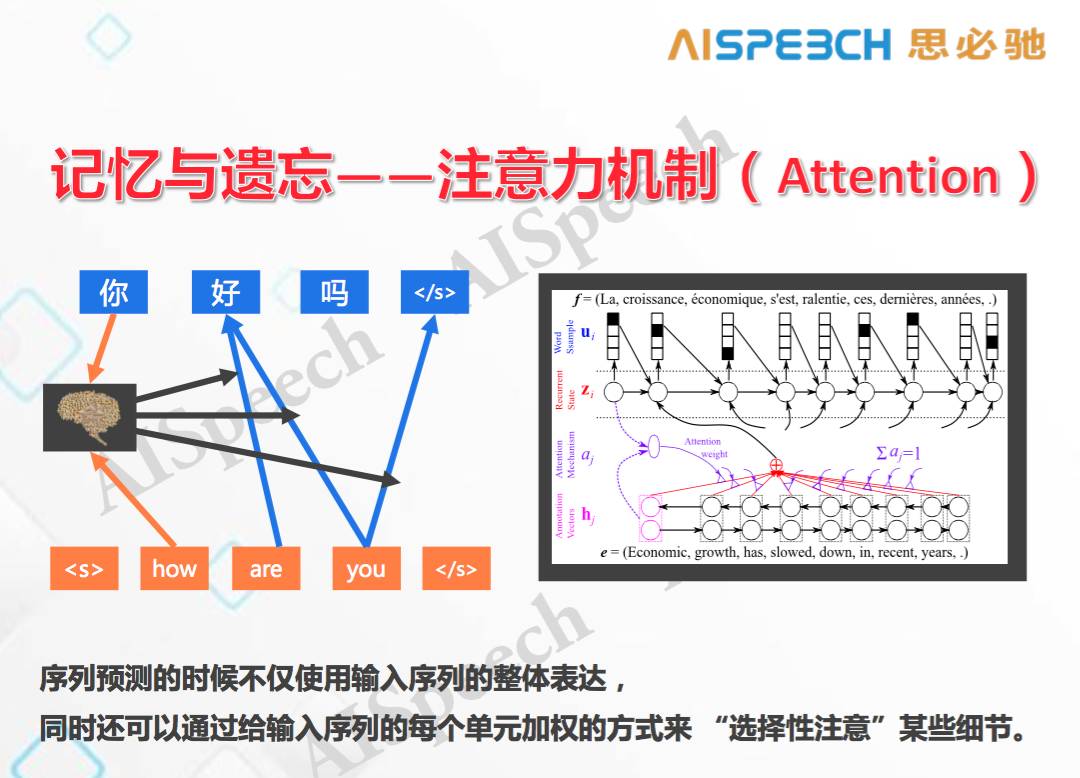
它的意思說,當將整個序列完全吞進去時還能記住原始的每一個詞的特點是什么,在輸出時,不單單基于整體概念,還可以對原始序列中每一個詞的含義進行不同的加權。所以在進行翻譯時,它知道整體感覺和局部特征對翻譯效果產生的影響。在上圖這個經典的翻譯案例里,輸入時把每個節點都讀進去,進行輸出會由每個節點輸入的加權平均得到一個新的輸出,這個新的輸出對翻譯結果中每輸出一個新詞會產生不同作用,也就是說,在輸出新詞時不單單使用了整體信息,還考慮了不同的局部加權信息,這就使機器翻譯的翻譯效果大大增強,因為它對翻譯中個別詞匯有了相應的一些注意力。
以上是幾個一般性進展,還有一些最新進展,比如 Memory Network 等。這幾樣都是最近機器學習領域里面出現的。接下來,我將介紹面對三類對話人類,我們在實際研究和工作中所用到的一些技術。
四、對話技術中的認知計算
1)聊天
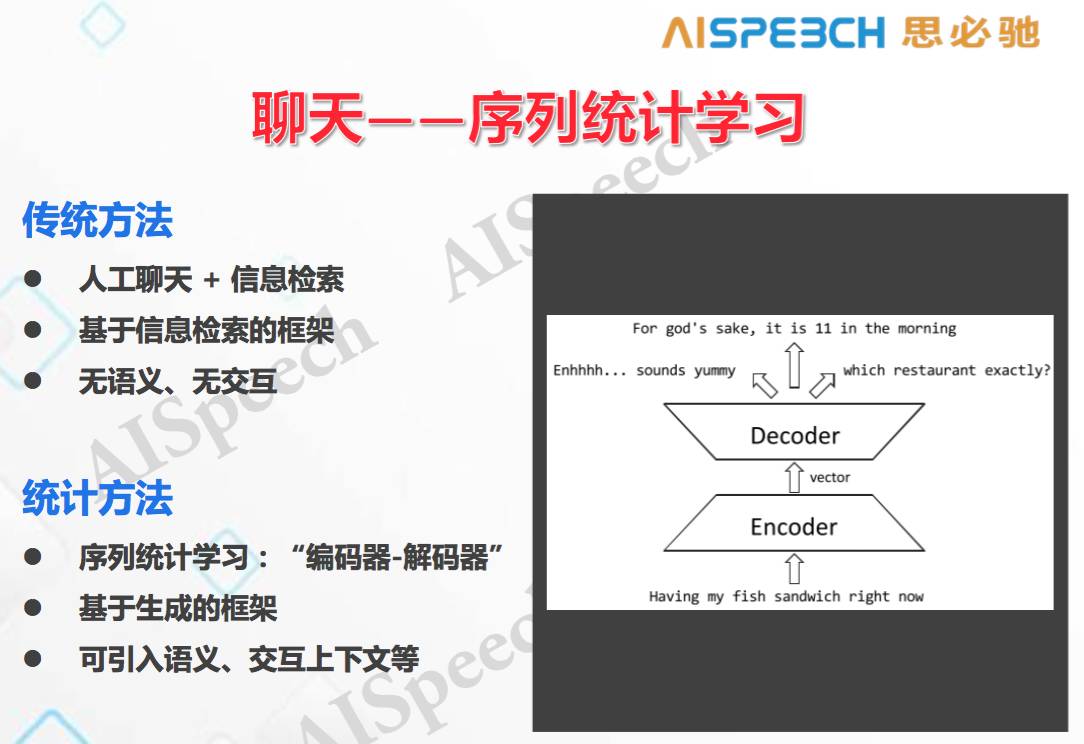
如上圖,目前大部分還是基于規則,用信息檢索的辦法去做統計訓練,不太考慮語義,也并不是從交互的角度上去進行建模,這是傳統的處理聊天的方法。但我們現在在嘗試一些新的東西,基于序列的統計學習,基于編碼器和解碼器。這種東西是基于生成的框架,也就是說先讀進來上一輪、甚至更早的信息,然后一個詞一個詞的去生成,在這種框架下比較容易引入語義和交互的工具。比如說上個圖右側,輸入一句話之后,再用解碼生成,用不同的生成結果中選出一個,這個基本上就和翻譯一樣的架構。
實際上單純這樣做可能效果很差,所以我們把注意力模型給引進過來,這樣就有了一個上下文概念,把前面聊天的內容通過編碼的方式記錄下來,下一句再通過解碼器去做預測,同時用注意力模型結合前面的一些信息。這里會涉及預測的方法,是對單獨每個詞做預測,還是整體一整句話,在預測的多句話中選一個。是基于序列生成,最大化序列的概念,還是最大化一個詞的概率,通過采樣的辦法去得到。這些會得到不同的結果。
總體上講,優化序列的結果會更好一些,我們可以基于「編碼-解碼」的方式來處理聊天類任務。
2)問答
微軟在這方面做了很多工作,他們當時提出了一個概念,叫深度語義相關度量(DSSM)。它是指,假如說我有輸入的文字和對應的輸入的回答,我現在想做的一件事是對整個序列提取特征向量,使得這個特征向量能夠代表這個序列本身的語義,同時這個語義又與它所對應的回答那句話的語義向量之間的差距是最小的。其中使用了多個神經網絡,在神經網絡里,有一個文字輸入,通過神經網絡提取之后,會有一個抽象的向量,正確的輸入也會有個抽象向量,訓練的準則是計算這兩者之間的 cos distance,使得兩者之間的 cos distance 最小。同時也會生成一些反例,把反例也輸進去,反例也有個向量,它會使這個向量與原始語義的向量的距離變得更大,使得語義相關度更小。通過這種訓練之后得到一個新的神經網絡,任意兩個東西輸進去之后,可以去計算它們的語義相似度,就會使得我們很容易去進行基于語義的匹配類檢索。所以,任務里就可以使用這種方法。
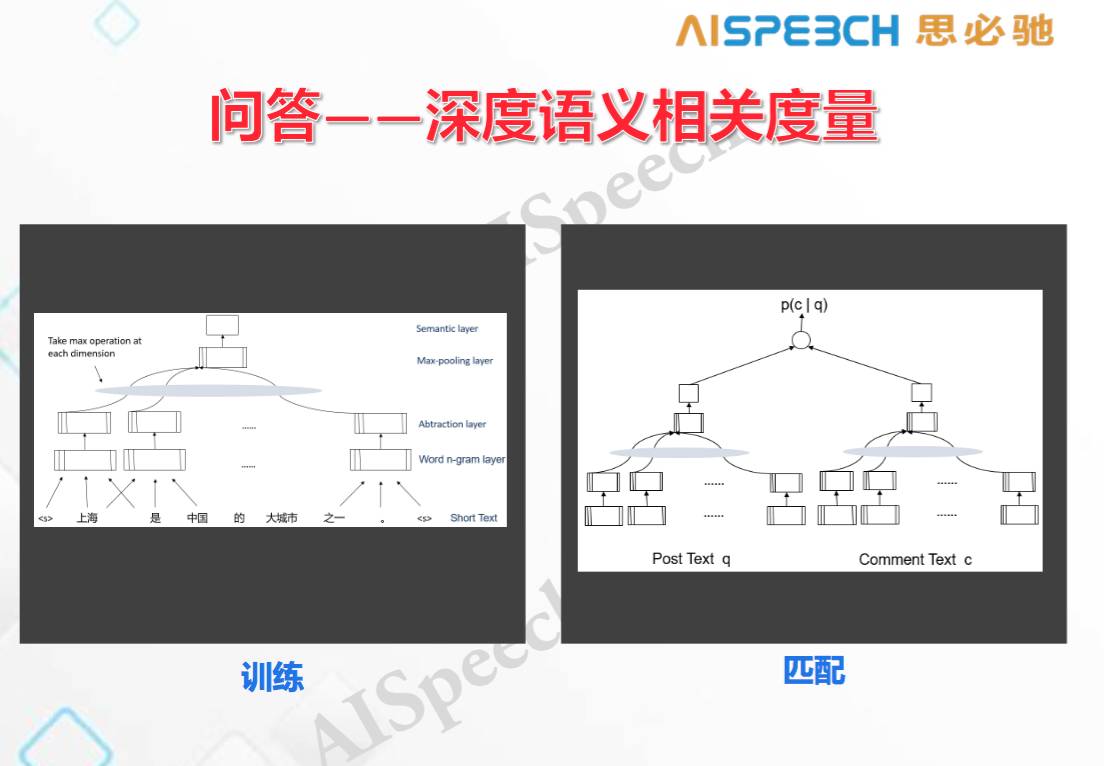
在問答之前提到 CNN 也可以處理序列,我們就可以用基于卷積的 DSSM 來處理問答 。它對文字通過卷積運算,再用類似于DSSM的架構把問題和答案分別輸進去,然后把得到的反例也輸進去來訓練這個網絡,最后你會得到兩個網絡。在實際用的時候,進來一個 post,先生成一些候選答案,再把生成的序列用 DSSM 去重新排序,這就是可以用深度相關的神經網絡得到比較有意思的匹配。我們發現,它確實是在語義上比較相似,因為一般來講,大家做問答的時候避免不了要用關鍵詞做匹配,那生成的答案絕大部分是有關鍵詞的,那我們發現這個模型生成的東西看起來是沒有關鍵詞匹配,它是在語義上匹配的,所以這是一個比較有意思的進展。
3)任務型口語任務
我們在這方面工作做得比較多。

首先要去定義任務型對話的一個框架,對話行為的概念由三部分組成,我們假定這個機器自身對于任何一個任務都會有一個狀態空間,我們在狀態空間里去推理。狀態包括用戶所做的總體意圖,當前這一句的語義,以及我們碰到的所有對話的歷史,我們把這些結合在一起變成狀態空間。這里要解決兩個問題,一個是要對狀態進行跟蹤,另一個是要進行決策。由于語音和語言在交流過程當中會有不確定性,所以你永遠不能知道用戶的真實狀態是什么,只能知道它所處狀態的一個分布,所以我們都是會基于分布。
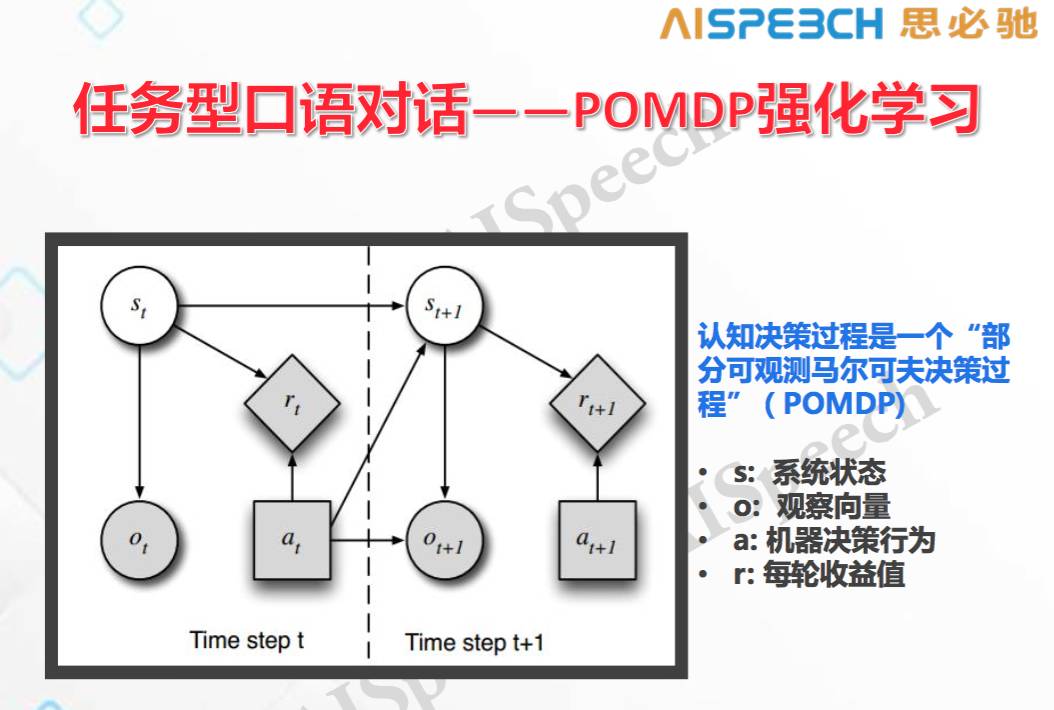
目前在處理對話類任務中一個比較完整的框架是 POMDP 強化學習,它認為認知決策是部分可觀測的馬爾可夫決策過程,狀態是不知道的,只能通過每一輪次狀態的分布來進行預測,基本上由四個關鍵因素組成:
系統狀態,機器的宇宙是什么樣子;
觀察向量,機器能看到什么;
機器決策行為,機器能做出什么樣的反應;
每輪收益值,在整個過程里,對機器每一輪訓練時的獎勵和懲罰。

所以,這個框架有兩大核心內容,第一塊是狀態更新,需要描述的是用戶想干什么,曾經表達過什么,機器已經做了什么。第二塊是系統決策,給定了系統的狀態分布,我們怎么把它映射到系統可能的選擇上面,這兩個東西都是可以用統計訓練的。
我 2007 年在劍橋開始這方面工作時就是基本上基于這個框架,但這個框架不太容易擴展到大規模系統,所以現在近幾年又出現了一些新的辦法,就是用不同的機器學習的方式把它變得比較大。
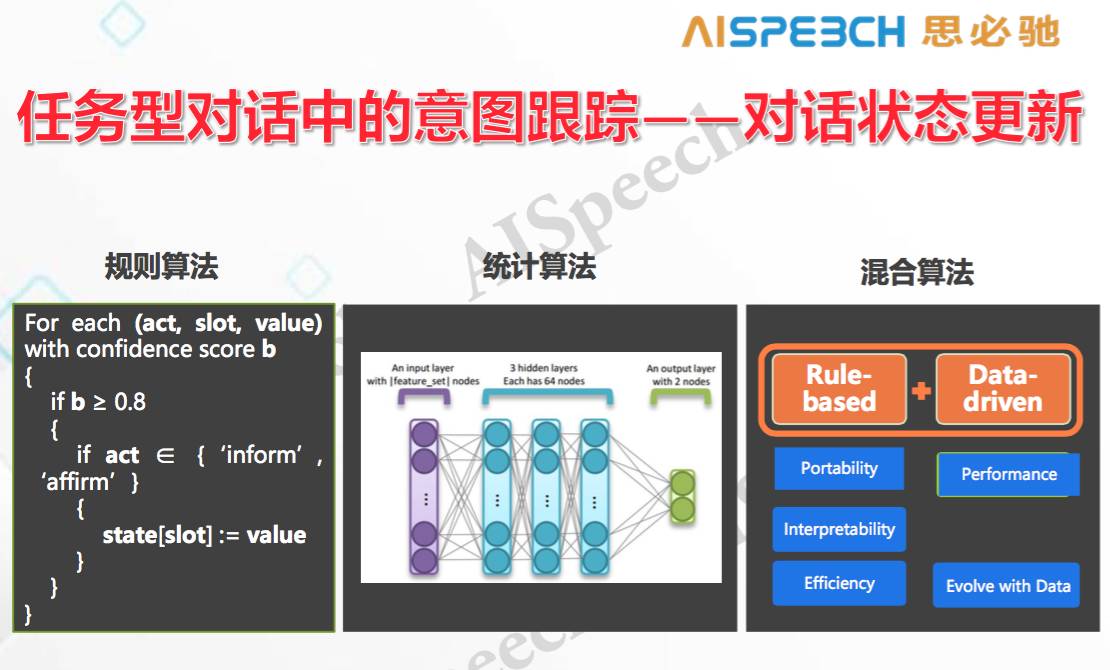
首先從對話狀態更新的角度上把它變大,原來狀態更新的辦法絕大部分是用規則,最近幾年用統計的方法,而我們最近用的比較新的方法是一個混合算法,簡單來說它整合了規則和統計兩種方法的好處,首先你可以添加各種各樣的新規則,從而具有解釋性并且比較快;其次是可以有一個自更新的過程,有數據之后會讓它變得更好。對話交互的狀態更新領域除了這種方法外,還有一類就是基于循環神經網絡(RNN)的統計方法,后者和混合算法所達到的效果差不多,但是要慢很多。
2010 年,我們去參加 CMU 組織的一個口語對話挑戰賽獲得了可控測試的冠軍。它用了真實的匹茲堡市政公交系統作為實驗平臺,每個參賽系統都用真人去問一些公交信息,比如說從哪個站到哪個站,以及幾點公交車會來,然后統計每個系統的對話語音識別的正確率和錯誤率,同時還去統計用戶的需求是不是被滿足了,就是這個任務是否完成。這樣的話,即使有些情況下語音識別和語義理解有一些錯誤,但機器仍然可以提供正確的信息,這種情況是1,如果提供不了就是 0,在平均之后,我們就知道在任何一個語音識別的錯誤率的區間上有多少對話被完成了,我們把這個叫做對話完成的預測準確率。當錯誤率在 50% 時,CMU 的對話成功率大體上在 60%,而我們所使用統計訓練的系統的成功率在 90%,差距是巨大的。這告訴我們,真正要想把對話做好,不單單要考慮前端的感知水平和每一句語義理解的水平,同時要對整個交互過程進行考慮。
五、自然語言認知交互的未來
最后再放一段錄像,這是蘋果在 1987 年預測 2011 年交互是什么樣子,而 2011 年恰好是 Siri 發布的那一年,這個錄像和我認為的自然語言交互的未來架構非常像的。
2011 年出現的 Siri 其實還遠沒有達到視頻中的第一步。里面出現了很多和對話交互的東西,你會發現有提示、打斷、增量學習(incremental understanding),還有很重要的基于知識的聯結,把這些東西都集成在一起形成了一個完整的人機對話。所以從這個角度上來看,如果在我們這個時代真的可以把它完成,那大體上需要這樣一個架構,這個也是我們在思必馳公司和上海交大的聯合實驗室里面采用的主要架構:
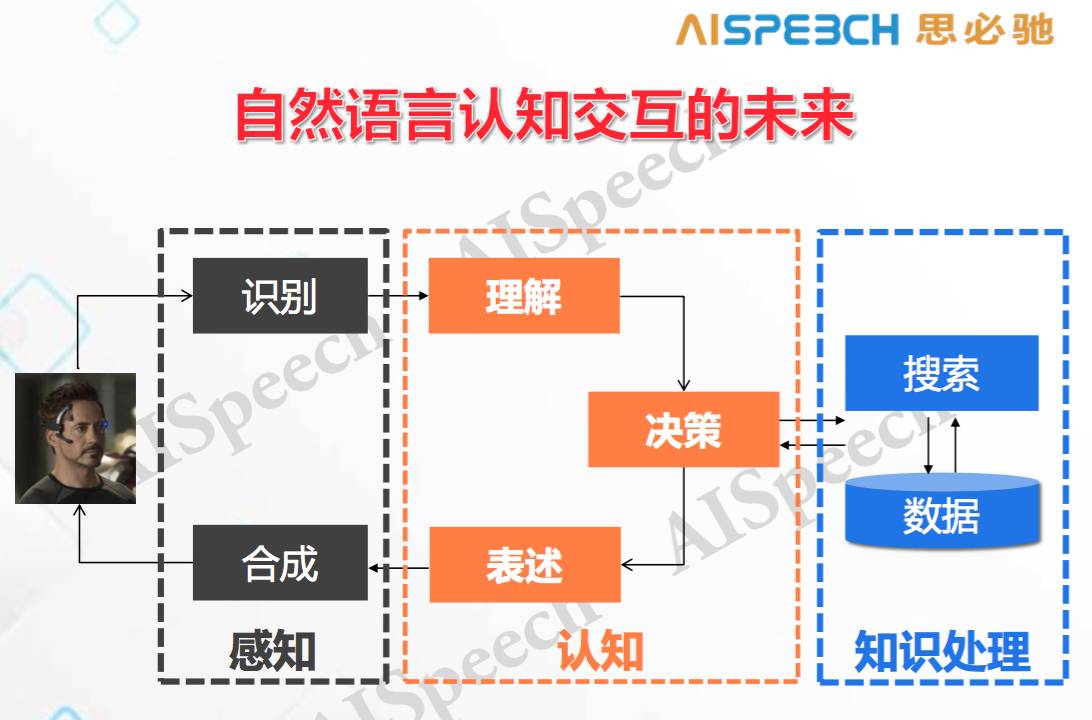
我們現在很多工作都在圍繞與之相關不同模塊和整體架構,現在不少人在做識別和合成,這是感知的部分,我們除了把感知要做到盡可能好之外,還在做理解、決策和表述。更重要的一件事情就是后端的決策一定會和你的知識結構放在一起,比如說我搜索一下,之后能不能結果總結一下放到對話交互中用,這是最基本的東西,但現在還沒有很好的完成。我們現在內部的研究已經做出了一些東西,有很好的提高,但距離理想的要求還有差距。對于領域相關的知識處理更重要,尤其是怎么樣把相應的 ontology 做好,這是未來很重要的一個事情,是基于上面提到的基于統計的能夠不斷學習的框架下的未來。
當然,也還有一種可能,會有一些新的實踐、框架和理論。今年年底,我們會從思必馳研究的角度提出一些新的理論,這和剛才提到的理論是不一樣的,也許它會使得自然人機對話的未來早日到來。
俞凱注:文章中所示PPT和內容有所刪節,希望與更多語音專家共同研討業界未來。
-
語音交互
+關注
關注
3文章
303瀏覽量
28462 -
思必馳
+關注
關注
4文章
319瀏覽量
15024 -
自然語言處理
+關注
關注
1文章
626瀏覽量
13996
發布評論請先 登錄





 工商網監
工商網監

評論