 思必馳的“人工智能技術”即“人工智能交互系統”
思必馳的“人工智能技術”即“人工智能交互系統”
回憶近年語音技術的發展歷程,早年主要談的是“合成”,再過些年開始著重談“識別”,那時所謂語音技術的含義就是“識別+合成”。直到我們真正要把語音技術運用到智能硬件上的時候才發現,很多情景下光靠“識別+合成”已經徹底不夠用了,我們開始需要的是“人性化的”擁有交互智能的語音技術。
講到“人工智能”,所有的公司都在講一個字“腦”, 那么同樣都在說“腦”,思必馳的智能語音和別人做的有什么不同呢?
大家都知道IBM的超級計算機“深藍”,它下棋可以贏國際象棋大師,但它只能算是一個計算機而不是一個機器人。因為對一個機器人來說,單獨模塊的優秀不是它的全部,它還要具備一個完整的從局部智能到整體智能的一整個人工智能系統,才算是一個機器人。這也就是為什么我們做的東西叫“對話系統”,不叫“語音識別”。
思必馳的“人工智能技術”,不只擁有以上依“腦”而生的技術模塊,更重要的是,我們將這些模塊協調整合和聯合運用,使其成為一整個“系統”,即“人工智能交互系統”。
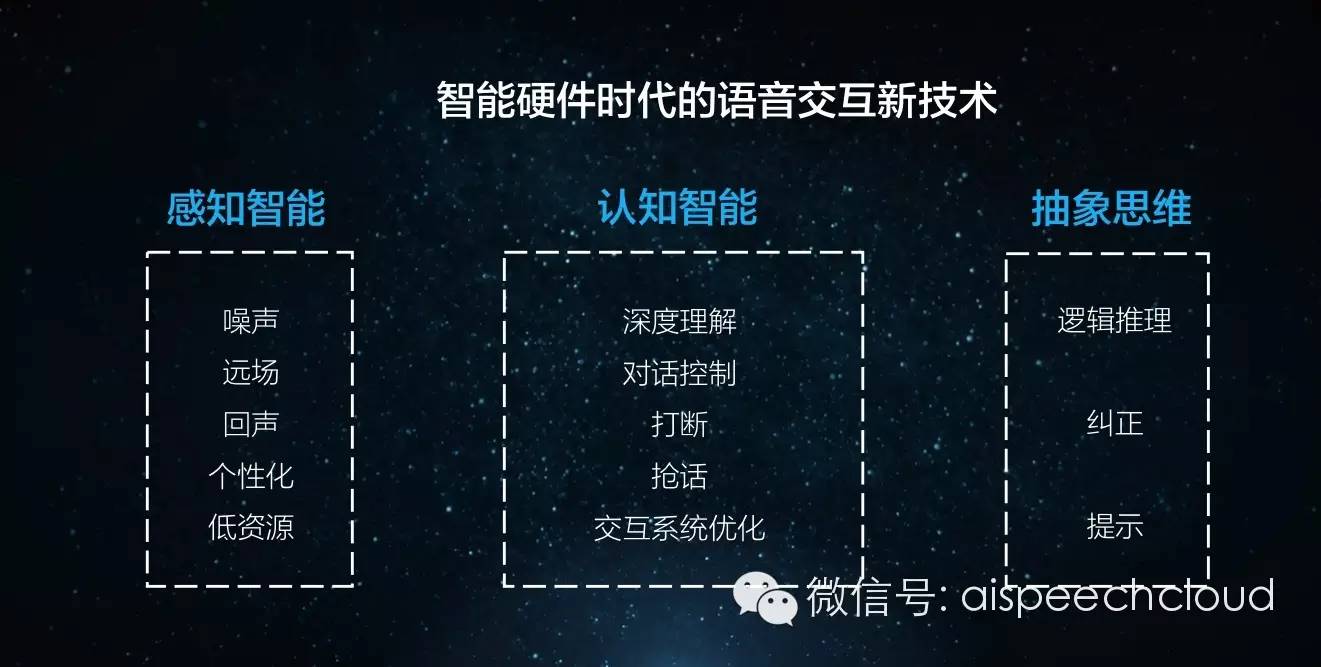
我們面臨的技術挑戰,大體上就這三類;首先要感知準確,就是識別率要高;其次準確理解用戶的意圖,給出正確的反饋;而后當反饋發生錯誤時,可以糾正。
先從“感知”即語音識別率入手。在移動互聯時代,我們有兩個非常重要的點,可以極大的優化我們的語音識別率。一塊是“大數據”,另一塊就是“深度學習”。
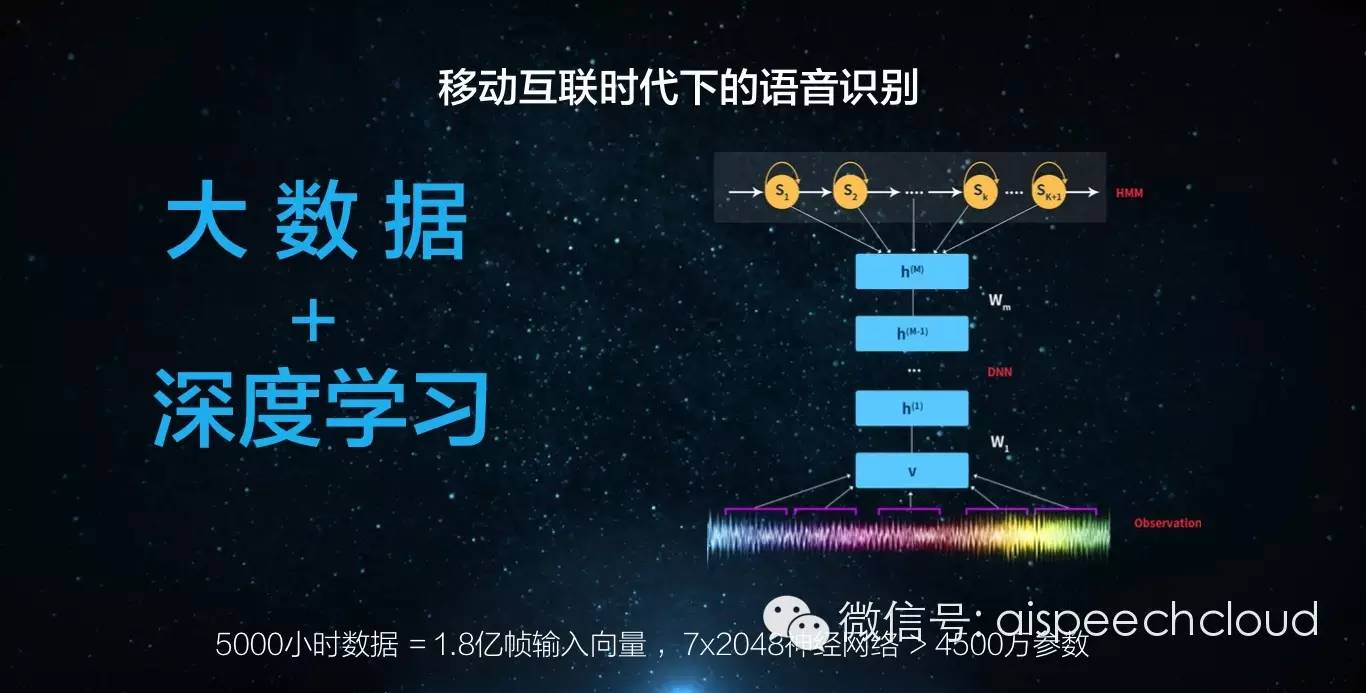
思必馳的人工智能語音系統經過自優化的“深度學習”和大數據計算之后已經被調教成國際上最好的語音識別技術之一,識別率已經到了95%以上。其語音技術僅靠在單麥,和后臺算法支持情況下就可以做到國際一流的識別準確率。在抗噪技術領域,思必馳的最新結構化抗噪語音識別技術刷新了國際噪聲標準測試庫記錄,取得目前世界最好成績。模型算法的優化突破,使思必馳僅用軟件就可以達到以往采用語音降噪芯片才能達到的效果,大幅提升了識別率,降低了成本。
在交互的大前提“感知”做好之后,個性化語音合成輸出也是近年來的一個“漸痛點”。思必馳拋棄了傳統語音采用的笨拙拼接合成技術,而采用最新的基于統計的參數化語音合成方法,不僅實現了模型規模的大幅壓縮,縮小了語音文件的體積,語音連貫性的大幅提升,同時也允許更自由的個性化的語音訓練。(目前思必馳已經完成一些名人的聲音合成,基本能夠保證與真人語音相差無幾。)

“等周二許春來到蘇州后約他一點鐘在九寨溝喝茶”,究竟說的是許春來到蘇州后請許春去喝茶,還是這個人來了許春約他去喝茶。這對機器來講是一個不小的挑戰。語義的解析不等于語義的理解。我們怎么解決這個事?一次性的交互是很難的,我們認為從鍵盤、鼠標到麥克風是不夠的,必須要有腦子去思考去判斷。很多情況下,由于識別一點點不準確,后面的整個任務變得沒辦法完成。語音識別在硬件里面想要用,必須和后端某些東西結合在一起,就是我們說的認知技能。

達成認知智能需要解決幾個方面的問題,一個是靜態認知,這一項我們已經通過深度學習和大數據的運算做的很好了。但是在現實場景下,即便擁有高識別度的靜態認知也是不夠的,還需要會動態認知,即交互過程中,智能硬件能通過用戶不斷反饋來學習,甚至主動詢問,并最終完成任務。不僅如此,在動態認知的交互過程中,我們還要讓系統可打斷,在打斷時還可以做回聲消除,可以做部分理解,然后還可以在部分理解的基礎上多輪交互,并對信息進行篩選理解。動態認知之后是進化認知,是讓系統能夠做到用得人越多,學得越好。
(發布會中演示的“語音糾正”功能,實錄)
思必馳已完成了一個真正可使用的系統級對話技術框架,一個真正具有認知能力的人機交互界面,不只提升識別率,更實現了深度理解和智能反饋,以及支持任性語音輸入的對話交互架構,做到了真正的智能交互。我們相信,智能硬件時代已經到來,而感知層面的適配技術與認知層面的對話技術,則是人機交互的未來。
思必馳的目標是希望能夠專注于智能語音交互技術的研發,我們自己不做硬件,但是我們會支持,我們特別希望做的事情就是所謂的用戶體驗的深度優化和深度結合。我們希望通過用戶體驗深度優化,支持產業創新,最后希望和各位開發者一起共同成長。
-
計算機
+關注
關注
19文章
7518瀏覽量
88192 -
人工智能
+關注
關注
1792文章
47409瀏覽量
238924 -
思必馳
+關注
關注
4文章
286瀏覽量
14293
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論