") 除了史上最大芯片之外,Hot Chips還有哪些值得關(guān)注的內(nèi)容?
除了史上最大芯片之外,Hot Chips還有哪些值得關(guān)注的內(nèi)容?
今年的Hot Chips,Cerebras搞了個(gè)大新聞,各種媒體刷屏。那么,除了史上最大芯片之外,Hot Chips還有哪些值得關(guān)注的內(nèi)容?一起來(lái)看芯片專家唐杉的解讀。
首先,Cerebras這次確實(shí)做了非常好的宣傳,各種介紹和分析也很多,我就不多說(shuō)了。不管大家怎么評(píng)價(jià),我個(gè)人還是很欽佩他們的工作的,所以拼了一張AI芯片的圖,算是致敬一下給我們帶來(lái)“美感”的工程師們。
這幾天介紹Hot Chips的文章也很多,我就全憑個(gè)人興趣挑幾個(gè)點(diǎn)和大家一起看一下。今年我自己沒(méi)有參會(huì),所以主要是根據(jù)演講的材料以及Anandtech上的Live Blog做一些分析。如果大家感興趣,也可以看看我去年寫(xiě)的文章(Hot Chips 30,黃金時(shí)代的縮影,Hot Chips 30 - 機(jī)器學(xué)習(xí),Hot Chips 30 - 巨頭們亮“肌肉”),有些內(nèi)容可以作為參考。
摩爾定律怎么“續(xù)命”
從某種意義上說(shuō),我們整個(gè)半導(dǎo)體產(chǎn)業(yè)都是在為摩爾定律的延續(xù)而努力,即我們希望能給18個(gè)月之后的應(yīng)用需求提供成倍增長(zhǎng)的“性能”支撐,只不過(guò)現(xiàn)在這個(gè)承諾不再是單單靠工藝節(jié)點(diǎn)的演進(jìn)和晶體管數(shù)目來(lái)支撐了。
這次Hop Chips上的兩個(gè)主旨演講,可以說(shuō)就是從不同角度討論了這個(gè)問(wèn)題。一個(gè)是處理器巨頭AMD的Dr. Lisa Su分享的“Delivering the Future of High-Performance Computing”;另一個(gè)是TSMC的Dr. Philip Wong分享的“What Will the Next Node Offer Us?”。先看看Lisa Su的總結(jié),為了給未來(lái)十年提供高性能計(jì)算能力,我們可做和要做的事情還是很多的。
source:Hot Chips 2019[1]
從Foundry的角度,Dr. Philip Wong講的就更直接,“MOORE’S LAW IS WELL AND ALIVE”,不過(guò)他的說(shuō)法也不是單獨(dú)針對(duì)晶體管的性能,而是各種技術(shù)綜合發(fā)展的結(jié)果。
source:Hot Chips 2019[2]
從架構(gòu)“黃金時(shí)代”(黃金時(shí)代)的說(shuō)法來(lái)看,工藝演進(jìn)速度放緩并不一定是壞事情,大家為了延續(xù)摩爾定律會(huì)在更多的方向上努力。比如,在這次會(huì)議上,Nvidia展示的工作[3]就是一個(gè)覆蓋了很多領(lǐng)域和設(shè)計(jì)環(huán)節(jié)的實(shí)驗(yàn)。它包括Multi-chip架構(gòu),NoC(Network-on-Chip)和NoP(Network-on-Package)構(gòu)成的層次化通信,高帶寬的inter-chip互聯(lián),甚至是敏捷開(kāi)發(fā)方法,挺有意思。而Facebook的講演[4]也介紹了大型系統(tǒng)協(xié)同設(shè)計(jì)的非常好的實(shí)踐。而在其它很多講演中,比如Intel,Nvidia,AMD,華為等等,我們也可以大量看到新型封裝和集成技術(shù)的應(yīng)用和快速進(jìn)展。
NN加速器架構(gòu)的下一步
這次也有幾家展示了NN加速器的架構(gòu),比較詳細(xì)的包括華為和Tesla。我們先看看Tesla。
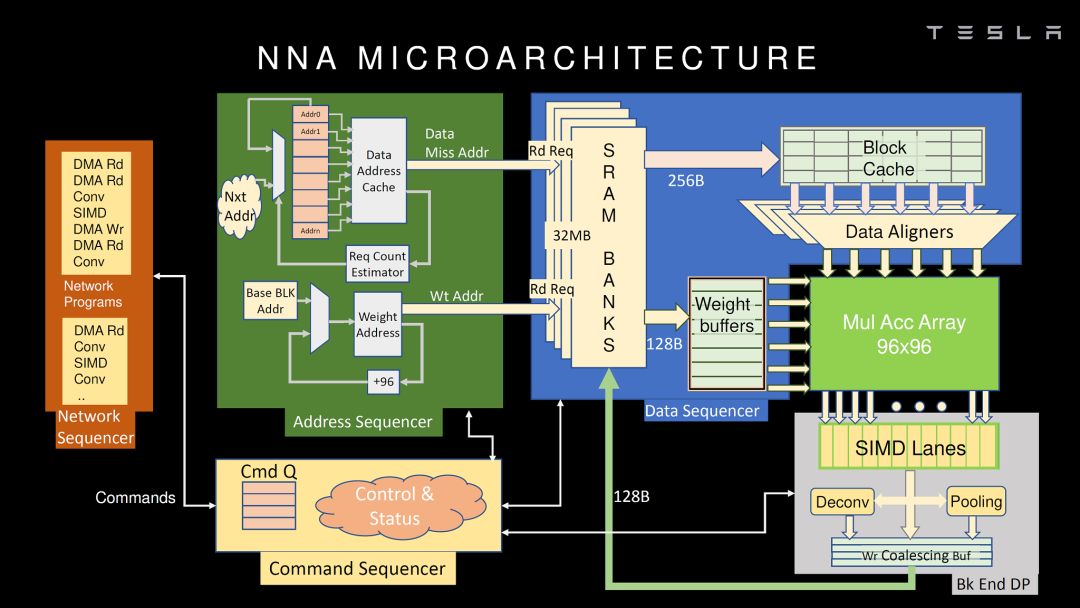
source:Hot Chips 2019 [3]
應(yīng)該說(shuō),Tesla的NNA不管從指令集還是微架構(gòu)都和Google TPU(公開(kāi)的第一代)非常類似,MAC矩陣實(shí)現(xiàn)卷積和矩陣乘,SIMD實(shí)現(xiàn)其它運(yùn)算,再加一些特殊運(yùn)算的硬件加速。這種架構(gòu)應(yīng)該是目前看到最多的設(shè)計(jì),簡(jiǎn)單直接,硬件實(shí)現(xiàn)比較容易,挑戰(zhàn)是MAC矩陣的使用效率。當(dāng)然,在很多細(xì)節(jié)上,Tesla的NNA還是做了不少優(yōu)化。如我之前的文章的分析,Tesla的芯片完全是自用的,合適就好,沒(méi)有太多可比性(多角度解析Tesla FSD自動(dòng)駕駛芯片)。
相比之下,華為的DaVinci Core應(yīng)該是結(jié)合了這幾年的AI芯片經(jīng)驗(yàn)和深入的思考。其特點(diǎn)是在一個(gè)Core里面同時(shí)支持3D(Cube),2D(Vector)和1D(Scalar)的運(yùn)算,以適應(yīng)不同網(wǎng)絡(luò)和不同層的運(yùn)算分布的變化。當(dāng)然,把各種運(yùn)算架構(gòu)放在一個(gè)Core里面并不是特別困難的事情,更難的是設(shè)計(jì)參數(shù)的選擇,運(yùn)算和存儲(chǔ)的比例,軟件mapping工具等等。這些問(wèn)題在華為的talk里也給出了一些分析。
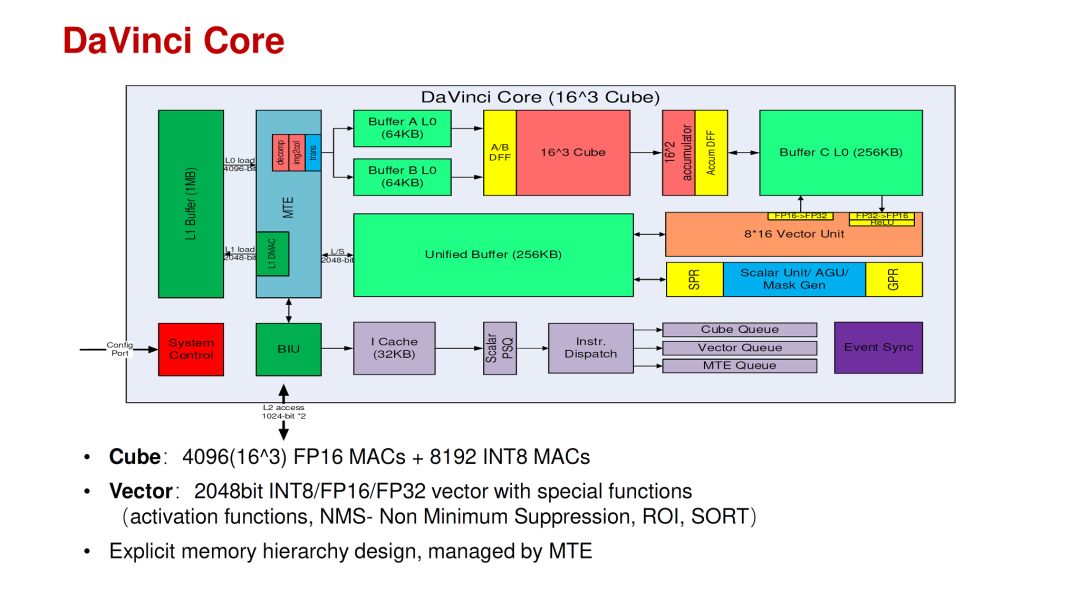
source:Hot Chips 2019 [4]
另外,Intel和Xilinx也展示了他們的AI加速Core的設(shè)計(jì)。如下:
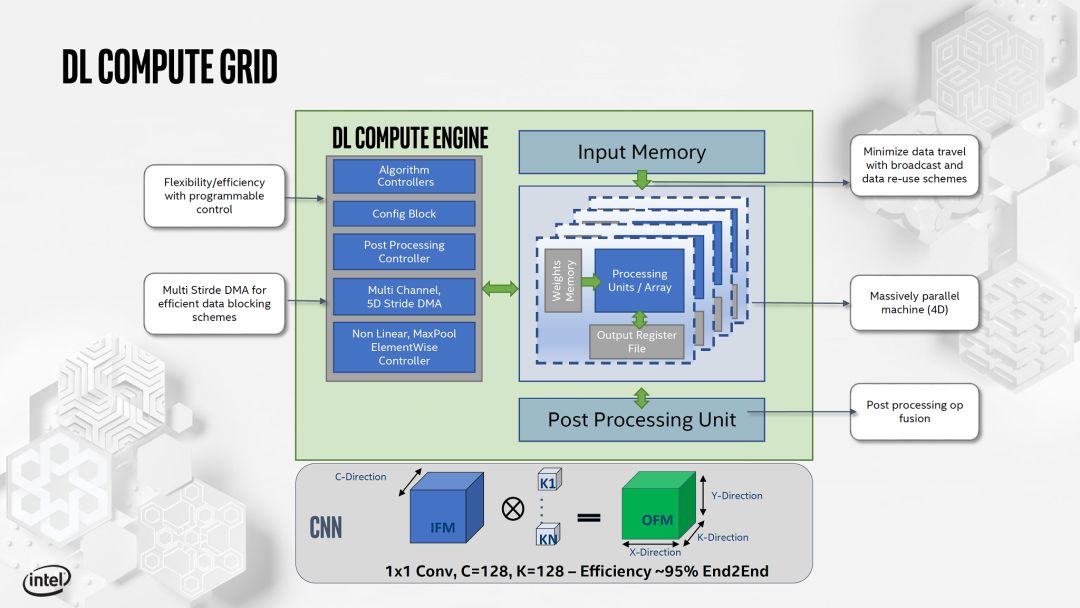
source:Hot Chips 2019 [5]
source:Hot Chips 2019 [6]
從指標(biāo)來(lái)看,目前比較容易對(duì)比的主要是云端inference芯片,Nvidia的T4,Habana的Goya,Intel的NNP-I,都有ResNet-50的IPS(Image Per Second)和IPSW(IPS/W)數(shù)據(jù)。
data source:廠商
如果考慮到T4并不是單純的inference功能,以及NNP-I的工藝優(yōu)勢(shì),那么大家的Inference IPSW指標(biāo)的差異并沒(méi)有太大。當(dāng)然,可能得等大家都提交了MLPerf的結(jié)果,我們才可能進(jìn)行更完整和公平的對(duì)比。對(duì)于指標(biāo)的分析,大家也可以看看我之前的文章,“數(shù)據(jù)中心AI Inference芯片今年能達(dá)到什么樣的性能?”,看起來(lái)我之前的預(yù)測(cè)沒(méi)太大問(wèn)題。
我們?cè)倏碩rainning芯片,不論是Nvidia,Google,Habana還是Intel這次發(fā)布NNP-T,更重要的已經(jīng)不是NN加速器core的架構(gòu),而是存儲(chǔ)容量,訪存帶寬,和可擴(kuò)展能力。
所以,不管是從大家公布的架構(gòu),還是從指標(biāo)來(lái)看,從TPU,Eyeriss,NVDLA到今天的Tesla FSD芯片和華為的DaVinci Core,如果不考慮基于新型存儲(chǔ)和器件的特殊設(shè)計(jì),可以說(shuō)NN加速器基本的硬件架構(gòu)已經(jīng)定型,主要工作是設(shè)計(jì)參數(shù)的優(yōu)化或者針對(duì)不同應(yīng)用的 trade off。換句話說(shuō),新架構(gòu)(專用處理器相對(duì)CPU和GPGPU)的紅利已經(jīng)充分兌現(xiàn)了。那么,對(duì)于架構(gòu)設(shè)計(jì)者來(lái)說(shuō),下一步的機(jī)會(huì)是什么呢?個(gè)人感覺(jué)可能有下面一些方向。也歡迎大家留言討論。
第一,更專用NNA的設(shè)計(jì)。一般來(lái)說(shuō)我們即使是做Domain-Specific設(shè)計(jì),也希望芯片能夠面向一類而非一個(gè)應(yīng)用。但如果一個(gè)應(yīng)用(比如只跑一個(gè)典型網(wǎng)絡(luò))有足夠大的市場(chǎng)和更嚴(yán)格的PPA要求(一般芯片滿足不了),做一個(gè)更專用的設(shè)計(jì)也未嘗不可,甚至可能是很好的機(jī)會(huì)。這種情況在我們說(shuō)的IoT應(yīng)用里比較多,芯片不大,但對(duì)PPA很敏感,適合算法硬件協(xié)同能力強(qiáng),并且可以快速迭代的團(tuán)隊(duì)。當(dāng)然,這種模式成立有個(gè)大前提,即AI使能更多新的應(yīng)用,并越來(lái)越快的落地。
第二,從單純NN加速設(shè)計(jì)到“NN+非NN”加速設(shè)計(jì)。在NN可以實(shí)現(xiàn)真正的end-to-end之前,即使是所謂的AI應(yīng)用,NN算法和非NN算法也會(huì)在一起共存很長(zhǎng)時(shí)間。一個(gè)好的架構(gòu)應(yīng)該是加速完整的應(yīng)用而不僅僅是NN部分(其實(shí)用戶根本不在乎你的架構(gòu)),這個(gè)需求在Edge/Device這個(gè)應(yīng)用領(lǐng)域更為明顯。解決這個(gè)問(wèn)題有兩種思路,一個(gè)是異構(gòu)架構(gòu)的優(yōu)化,特別是NN和非NN算法在不同硬件架構(gòu)上的mapping和協(xié)同。另一個(gè)思路是以比較傳統(tǒng)的Vector DSP(即可以做NN加速,也可以做很多傳統(tǒng)算法,包括CV和語(yǔ)音,有可能會(huì)有優(yōu)勢(shì))為基礎(chǔ),以特殊指令或緊耦合的加速器的形式集成小規(guī)模的Tensor Core,來(lái)找到更好的平衡點(diǎn)。
第三,軟硬件協(xié)同設(shè)計(jì)還是有很大空間。在DaVinci的例子里,即使硬件支持不同粒度的運(yùn)算,在實(shí)際網(wǎng)絡(luò)怎么用好這些硬件也還是非常困難的課題。最近我討論這個(gè)話題也比較多(AI芯片“軟硬件協(xié)同設(shè)計(jì)”的理想與實(shí)踐)。其實(shí)這次Hot Chips上Google的tutorial就是“Cloud TPU: Codesigning Architecture and Infrastructure”。這里并沒(méi)有太多的介紹TPU架構(gòu),而是把重心放在了協(xié)同設(shè)計(jì)上,其的內(nèi)容也遠(yuǎn)遠(yuǎn)超出了NN加速本身。從這里也可以看出,未來(lái)的協(xié)同設(shè)計(jì)不僅僅是NN加速器這一個(gè)點(diǎn),而在“高手過(guò)招”當(dāng)中,必須要完整考慮整個(gè)系統(tǒng)的優(yōu)化。
source:Hot Chips 2019 [7]
一個(gè)有趣的插曲是,當(dāng)我在朋友圈分享這個(gè)內(nèi)容的時(shí)候。一個(gè)評(píng)論是“每次這種會(huì)上,都會(huì)覺(jué)得“哇好有道理”,然后一想好像又啥都沒(méi)說(shuō)”。其實(shí)協(xié)同設(shè)計(jì)的現(xiàn)狀也類似,就是看起來(lái)很美,做起來(lái)不易。
另外,這次會(huì)議還有一個(gè)來(lái)自Stanford AHA Agile Hardware Center的名為“Creating An Agile Hardware Flow”的演講,也是在講如何快速進(jìn)行軟硬件協(xié)同設(shè)計(jì)。他們的一個(gè)思考是,協(xié)同設(shè)計(jì)最大的挑戰(zhàn)在于設(shè)計(jì)空間太大,為了縮小探索的空間,我們可以使用CGRA可重構(gòu)硬件架構(gòu)作為硬件基礎(chǔ)(只需探索CGRA的配置);以HalideDSL作為穩(wěn)定的軟硬件接口,實(shí)現(xiàn)優(yōu)化的解耦。所以,從軟硬件協(xié)同設(shè)計(jì)這個(gè)角度來(lái)看,CGRA架構(gòu)也是非常值得關(guān)注的。這個(gè)話題我后面會(huì)找時(shí)間詳細(xì)討論。
存內(nèi)計(jì)算和“近存儲(chǔ)”計(jì)算
去年的Hot Chips上,基于Flash Cell做存內(nèi)計(jì)算的初創(chuàng)公司Mythic很受關(guān)注,我也做過(guò)比較詳細(xì)的分析(Hot Chips 30 - 機(jī)器學(xué)習(xí))。這一年以來(lái),基于各種memory cell,包括SRAM,DRAM,F(xiàn)LASH和新型存儲(chǔ)器件,MRAM,RRAM等等的存內(nèi)計(jì)算初創(chuàng)公司大量涌現(xiàn),非常熱鬧。其實(shí)除了存內(nèi)計(jì)算,還有另一類“近存儲(chǔ)”計(jì)算。借杜克大學(xué)燕博南同學(xué)的一張圖說(shuō)明一下。
其中In-Memory的意思是直接使用存儲(chǔ)單元陣列來(lái)做計(jì)算,一般是模擬方式,通過(guò)AD/DA和數(shù)字邏輯部分交互。而Near-Memory則是盡量把運(yùn)算邏輯(處理器或者加速器)放在離存儲(chǔ)單元比較近的地方。
在這次的會(huì)議上,一個(gè)初創(chuàng)公司upmem,雖然自稱是PIM,但實(shí)際走的是近存儲(chǔ)計(jì)算的路線。upmem的產(chǎn)品看起來(lái)和傳統(tǒng)的DRAM顆粒和DIMM沒(méi)有什么區(qū)別,但在每個(gè)4Gb DRAM顆粒里嵌入了8個(gè)處理器核。
source:Hot Chips 2019 [10]
這是近存儲(chǔ)計(jì)算的一個(gè)很好的例子,在DRAM里的處理器可以分擔(dān)CPU的工作,減少不必要的數(shù)據(jù)搬移,當(dāng)然有很多好處。但是要真正把計(jì)算邏輯和DRAM放在一起并不是那么容易的,其中最大的挑戰(zhàn)就是如何使用DRAM工藝來(lái)支持處理器設(shè)計(jì),下圖列舉了主要的困難。
source:Hot Chips 2019 [10]
所以,這個(gè)講演的大量?jī)?nèi)容是如何克服DRAM工藝的這些困難設(shè)計(jì)處理器,包括:
1. 在DRAM工藝上建立數(shù)字邏輯的flow,比如Logic cell library,SRAM IP和Logic Design & Validation flow,這些是處理器設(shè)計(jì)和實(shí)現(xiàn)的基礎(chǔ);
2. 使用比較“慢”的晶體管設(shè)計(jì)實(shí)現(xiàn)“快”的處理器的方法,14級(jí)流水實(shí)現(xiàn)500MHz,Interleaved pipeline,24個(gè)硬件線程(這個(gè)是保證深流水線效率的主要方式)。
3. 不使用Cache,而是Explicit memory hierarchy,這個(gè)也和多線程有關(guān)系。
4. 優(yōu)化的指令集,專門強(qiáng)調(diào)了沒(méi)有使用ARM和RISC-V。這里也解釋了,由于不需要運(yùn)行OS,所以沒(méi)有必要考慮兼容性問(wèn)題,只要實(shí)現(xiàn)CLANG/LLVM的支持。
此外,在DRAM中加了這么多處理器核,怎么使用(編程模型)是個(gè)問(wèn)題。在upmem的講演中也分析了這方面的內(nèi)容。(此處圖配錯(cuò)了,抱歉)
source:Hot Chips 2019 [10]
如果我們考慮近存儲(chǔ)計(jì)算,其實(shí)還有一個(gè)大量存儲(chǔ)數(shù)據(jù)的地方,就是硬盤(pán)。因此,現(xiàn)在也有很多的SSD控制器芯片加入的更多的計(jì)算功能。比如前一段時(shí)間我們看到初創(chuàng)公司InnoGrit就在SSD控制器芯片中加入了NDLA專門加速AI運(yùn)算。當(dāng)然除了直接在芯片中增強(qiáng)算力,還有一種模式就是在SSD控制器外增加FPGA,比如三星的Smart SSD方案(下圖)。在這次Hot Chips的Poster里面,就有一個(gè)來(lái)自Bigstream的工作是基于Smart SSD構(gòu)建的應(yīng)用框架。
source:samsungatfirst.com/smartssd/
總的來(lái)說(shuō),相對(duì)存內(nèi)計(jì)算,不依賴工藝進(jìn)展的近存儲(chǔ)計(jì)算可能更容易在短期內(nèi)落地。但和存內(nèi)計(jì)算一樣,近存儲(chǔ)計(jì)算也需要有完整的軟硬件解決方案,否則簡(jiǎn)單增加的算力可能僅僅是雞肋。
-
芯片
+關(guān)注
關(guān)注
456文章
50960瀏覽量
424798 -
半導(dǎo)體
+關(guān)注
關(guān)注
334文章
27525瀏覽量
219863 -
AI芯片
+關(guān)注
關(guān)注
17文章
1894瀏覽量
35103
原文標(biāo)題:史上最大芯片長(zhǎng)得像iPad?那你還沒(méi)看懂Hot Chips
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
除了雷電放散裝置,風(fēng)電場(chǎng)架空線路還有哪些防雷措施
請(qǐng)問(wèn)同一款芯片,SOIC和SOP除了封裝不同外,還有其他區(qū)別嗎?
史上最大屏幕Apple Watch亮相 屏幕面積增加了30%
電流反饋運(yùn)放的反相輸入端和同相輸入端除了輸入阻抗不同之外還有什么區(qū)別嗎?
NVIDIA 在 Hot Chips 大會(huì)展示提升數(shù)據(jù)中心性能和能效的創(chuàng)新技術(shù)

數(shù)據(jù)分析除了spss還有什么
除了英偉達(dá),這些AI概念公司在2024年還有巨大的投資價(jià)值(一)

除了英偉達(dá),這些AI概念公司在2024年還有巨大的投資價(jià)值(三)

除了英偉達(dá),這些AI概念公司在2024年還有巨大的投資價(jià)值(四)
除了英偉達(dá),這些AI概念公司在2024年還有巨大的投資價(jià)值(二)
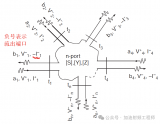
除了S參數(shù),還有哪些網(wǎng)絡(luò)參數(shù)呢?
滑動(dòng)變阻器除了保護(hù)電路,還有什么作用?
電源模塊除了轉(zhuǎn)換電壓還有哪些功能
2023年十大兒童電子設(shè)備盤(pán)點(diǎn):除了兒童手表還有啥?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論