") NVDIA提出一種面向場景圖解析任務的圖對比損失函數(shù)
NVDIA提出一種面向場景圖解析任務的圖對比損失函數(shù)
關系識別(Relationship Detection)是繼物體識別(Object Detection)之后的一個重要方向。使用視覺關系構建的場景圖(Scene Graph)可以為很多下游任務提供更豐富的語義信息。這篇文章我們討論目前常規(guī)模型遇到的兩個普遍問題,并提出三種loss解決,同時我們也設計了一個高效的end-to-end網(wǎng)絡搭配我們的loss來構建場景圖。我們的模型在三個數(shù)據(jù)集(OpenImage, Visual Genome, VRD)上都達到了目前最優(yōu)結果。
張驥,羅格斯大學在讀博士生,曾在Facebook AI Research (FAIR),Nvidia Research實習參與計算機視覺領域研究項目,在CVPR,AAAI,ACCV等會議均有論文發(fā)表,并在2018年Kaggle上舉辦的Google OpenImage Visual Relationship Detection Challenge比賽上獲得第一名。這篇文章是參賽模型的一個改進版本。
論文鏈接:https://arxiv.org/abs/1903.02728
代碼鏈接:https://github.com/NVIDIA/ContrastiveLosses4VRD
近兩年來,場景圖解析任務(Scene Graph Parsing,也稱Scene Graph Generation)開始獲得越來越多的關注。這個任務的定義是針對輸入圖片構建一個描述該圖片的圖(graph),該圖中的節(jié)點是物體,邊是物體之間的關系。下圖是一個例子:
圖片來源:J. Zhang, et al., AAAI2019[1]
眾所周知,物體識別是一個相對成熟的領域,目前很多state-of-the-art方法在非常challenging的數(shù)據(jù)集上(MSCOCO, OpenImages)也能得到不錯的結果。這意味著,在構建場景圖的過程中,把節(jié)點(也就是物體)探測出來不是一個難點,真正的難點在于構建圖中的邊,也就是物體之間的視覺關系(visual relationship)。
自2016年ECCV第一篇視覺關系識別的文章[2]出現(xiàn)以來,已經(jīng)有很多工作關注于如何通過給物體兩兩配對并且融合物體特征來得到它們之間關系的特征,進而準確探測出關系的類別[3, 4, 5, 6, 7, 8, 9]。但這些工作的一個共同問題在于,場景圖中每一條邊的處理都是獨立的,也就是說,模型在預測一對物體有什么關系的時候不會考慮另一對物體,但實際情況是,如果有兩條邊共享同一個物體,那么這兩條邊常常會有某種客觀存在的聯(lián)系,這種聯(lián)系會顯著影響預測的結果,因而在預測兩條邊中任何一條的時候應該同時考慮兩條邊。
這篇文章正是觀察到了邊之間存在兩種重要的聯(lián)系,進而針對性地提出三種損失函數(shù)來協(xié)同地預測視覺關系。更具體地說,這篇文章觀察到了兩個客觀存在的常見問題,這兩個問題在前人的工作中并沒有被顯式地解決:
問題一:客體實例混淆
客體實例混淆的定義是,一個物體只和相鄰的很多同類別的物體中的一個存在關系時,模型不能正確識別出它和這些同類別物體中的哪一個有關系。換言之,很多視覺關系是有排它性的。一個人如果在騎馬,那么即便他周圍有一百匹馬,他也只可能在騎其中一匹。下圖是一個文章中給出的例子。圖中的人面前有若干酒杯,該人只拿著其中一只杯子,但傳統(tǒng)模型由于缺乏顯式的區(qū)分機制,它錯誤地認為桌上那個酒杯在被人拿著。
問題2:鄰近關系模糊這個現(xiàn)象是說,當兩對物體靠的很近,同時它們之間的關系類別一樣的時候,模型很難作出正確的匹配。下圖是這個現(xiàn)象的一個例子。圖中有兩個“man play guitar”,和一個“man play drum”。由于三個人靠的很近且都在演奏樂器,視覺上很容易把人和他對應的樂器混淆,在這張圖片中,傳統(tǒng)的scene graph parsing模型就把右邊人錯誤地認為是在打中間的鼓。
這兩個問題的根本原因都在于,決定物體之間關系的視覺特征往往非常微妙,而且當需要判別出物體之間有無關聯(lián)時,觀察者往往需要將注意力集中到鄰近的多個物體并進行對比,這樣才能避免混淆,準確區(qū)分出誰和誰是相關的。這正是本文提出的解決方案的動機。 解決方案
針對這兩個問題,本文提出三種損失函數(shù)來解決。總的來說這三種損失函數(shù)的思想是,訓練過程中對于每個節(jié)點(即物體),篩選出當前模型認為與之匹配,但置信度最小的那個正樣本,同時選出當前模型認為與之不匹配但置信度也最小的那個負樣本,再計算這兩個樣本的置信度的差異,然后把這個差異作為額外的損失值反饋給模型。根據(jù)這種思想,本文進一步設計了三種類型的損失函數(shù)形式:
1. 類別無關損失(Class AgnosticLoss)
該函數(shù)的計算分成兩步,第一步計算正負樣本的置信度差異:
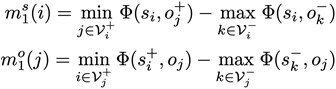
其中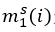 是當物體i作為主語(subject)的時候它所有可能對應的賓語中正負樣本置信度差異的最小值。這里“正負”的含義是某物體作為賓語與這個主語
是當物體i作為主語(subject)的時候它所有可能對應的賓語中正負樣本置信度差異的最小值。這里“正負”的含義是某物體作為賓語與這個主語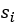 是否存在視覺關系。這里
是否存在視覺關系。這里 代表物體i當前被作為主語考慮,j和k分別用來索引與主語存在關系的正樣本賓語
代表物體i當前被作為主語考慮,j和k分別用來索引與主語存在關系的正樣本賓語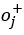 和不存在關系的負樣本賓語
和不存在關系的負樣本賓語 。
。 和
和 分別代表與主語
分別代表與主語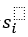 存在關系的所有賓語(即正樣本)的集合,和與主語
存在關系的所有賓語(即正樣本)的集合,和與主語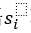 不存在關系的所有賓語(即負樣本)的集合。與之相似地,
不存在關系的所有賓語(即負樣本)的集合。與之相似地,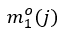 的定義是物體作為賓語時它所有可能對應的主語中正負樣本置信度差異的最小值。
的定義是物體作為賓語時它所有可能對應的主語中正負樣本置信度差異的最小值。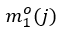 公式中符號的含義與之類似,這里不再贅述。
公式中符號的含義與之類似,這里不再贅述。
第二步是利用第一步的兩個差異值來計算一個基于邊界的損失:
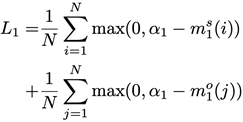
其中 是預先設定的邊界值,N是當前的batch size。這個損失的作用是使得上述第一步中的差異值大于預定的
是預先設定的邊界值,N是當前的batch size。這個損失的作用是使得上述第一步中的差異值大于預定的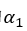 ,只有滿足這個條件的時候
,只有滿足這個條件的時候 才為0,也就是說我們希望差異值至少是。 熟悉contrastiveloss和triplet loss的朋友應該發(fā)現(xiàn),這個loss的形式和它們很類似。的確,這里的對比形式參考了triplet loss,但不同點在于這個loss受限于圖模型的結構,即每一個節(jié)點的正負樣本都只來自于和當前主語或賓語可能存在關系的節(jié)點,而不是像一般triplet loss那樣直接在所有節(jié)點中搜索正負樣本。
才為0,也就是說我們希望差異值至少是。 熟悉contrastiveloss和triplet loss的朋友應該發(fā)現(xiàn),這個loss的形式和它們很類似。的確,這里的對比形式參考了triplet loss,但不同點在于這個loss受限于圖模型的結構,即每一個節(jié)點的正負樣本都只來自于和當前主語或賓語可能存在關系的節(jié)點,而不是像一般triplet loss那樣直接在所有節(jié)點中搜索正負樣本。
另一個不同點是triplet loss一般的應用場景是用于訓練節(jié)點的嵌入(embedding),因此它的輸入通常是正負樣本的嵌入向量,但這個loss的輸入就是原始模型的輸出,即每一個視覺關系的置信度,它的目的是通過對比正負樣本的置信度把當前視覺關系的最重要的上下文環(huán)境反饋給原始模型,從而讓原始模型去學習那些能夠區(qū)分混淆因素的視覺特征。
2. 物體類別相關損失(Entity Class Aware Loss)
該函數(shù)與類別無關損失形式類似,唯一的不同在于這個loss在選擇正負樣本時,樣本中物體的類別必須一樣:
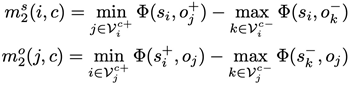
這一步與上一個loss的第一步的唯一區(qū)別就是加入了一個額外輸入c,它的作用是規(guī)定在計算正負樣本差異時,所有考慮到的物體必須同屬于類別c。這個額外限制迫使模型去注意那些同一個類別的不同物體實例,比如上圖中的多個酒杯,并在學習過程中逐漸區(qū)分存在視覺關系和不存在視覺關系的實例的特征,因此這個loss是專門設計用來解決上文提出的第一個問題的,即客體實例混淆。
3. 謂語類別相關損失(Predicate Class Aware Loss)
該函數(shù)與類別無關損失形式也類似,唯一的不同在于這個loss在選擇正負樣本時,樣本中謂語的類別必須一樣:

這里加入了一個額外輸入e,它代表的是目前考慮的謂語類別。它的作用是規(guī)定在計算正負樣本差異時,所有考慮到的樣本的視覺關系必須都以謂語連接。這個額外限制迫使模型去注意那些具有同樣視覺關系的物體對,比如上圖中同樣在“play”樂器的三個人,然后在訓練過程中學會識別正確的主客體匹配。很顯然這個loss是專門用來解決上述的第二個問題,即鄰近關系模糊。
關系檢測網(wǎng)絡(RelDN)
本文同時也提出了一個高效的關系識別網(wǎng)絡,結構圖如下:

該網(wǎng)絡首先用事先訓練好的物體識別器識別出所有物體,然后對每一對物體,從圖片中提取它們的視覺特征,空間特征以及語義特征。其中空間特征是bounding box的相對坐標,語義特征是兩個物體的類別。這三個特征分別被輸入進三個獨立的分支,并給出三個預測值,最后網(wǎng)絡把三個預測值加總并用softmax歸一化得到謂語的分布。
值得注意的是,中間這個Semantic Module在前人的工作中也叫Frequency Bias或者Language Bias,它意味著當我們知道主客體的類別時,我們即便不看圖片也能“猜”出它們之間的謂語是什么。這個現(xiàn)象其實是符合客觀規(guī)律的。試想有一張圖片里有一個人和一匹馬,現(xiàn)在我們不看圖片去猜這個人和這匹馬有什么關系,我們一般最容易想到“騎”,其次是“拍”或者“牽著”之類的動作,但幾乎不可能是“站在”或者“躺在”,因為這與客觀常識不符。
如果要構建符合真實世界分布的場景圖,那么符合客觀規(guī)律的常識就不能忽略,因此這個Language Bias不可或缺。
實驗結果
1. 成分分析
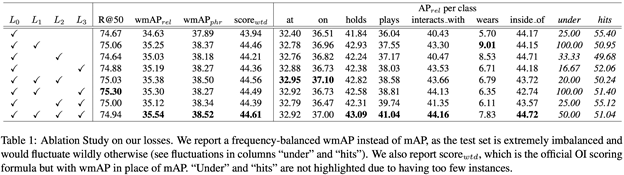
這張表是ablation study,以一步步添加子模塊的方式證明三個損失函數(shù)都是有效的是傳統(tǒng)方法通用的multi-class cross entropy loss,簡言之就是softmax層后面接的分類loss,分別是類別無關損失(Class Agnostic Loss),物體類別相關損失(Entity Class Aware Loss)和謂語類別相關損失(Predicate ClassAware Loss)。

這張表對應的實驗是,人工隨機地挑選出100張圖片,這些圖片里面廣泛地存在著本文開頭提到的兩個問題,然后分別用不帶本文提出的losses的模型和帶這些losses的模型去跑這100張圖片然后對比結果。很明顯,帶losses的模型幾乎在所有類別上優(yōu)于不帶losses。這個實驗直接證明了添加本文提出的losses能夠很大程度上解決客體實例混淆和鄰近關系模糊這兩個問題,從而顯著提高模型整體精確度。 除了使用Table2量化地證明losses的有效性,本文同時對模型學到的中間層特征進行了可視化,示例如下:
上圖是從驗證集(validation set)里挑選的兩張圖,每張圖分別用不帶losses和帶losses的模型跑一下,然后把最后一個CNN層的特征提出來并畫成上圖所示的heatmap。可以發(fā)現(xiàn),在左邊這張圖中不帶losses的模型并沒有把正確的酒杯凸顯出來,而帶losses的模型很清晰地突出了被人握著的那個酒杯;在右邊這張圖中,不帶losses的模型突出的位置所對應的物體(鼓)并沒有和任何人存在關系,而被人握在手里的話筒卻并沒有被突出出來。相比之下,帶losses的模型則學到了正確的特征。
2. 與最新方法的比較
本文在三個數(shù)據(jù)集上都做到了state-of-the-art,三個數(shù)據(jù)集是OpenImages (OI), VisualGenome (VG), Visual Relation Detection (VRD):
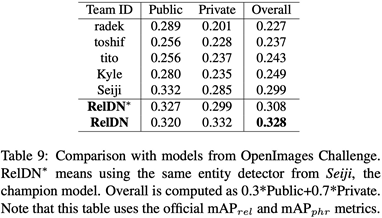
OpenImages(OI)由于數(shù)據(jù)集較新,之前沒有論文做過,所以本文直接和Google在2018年舉辦的OpenImages Visual Relationship Detection Challenge的前8名進行了比較,結果比冠軍高出兩個百分點。

在VisualGenome(VG)上,使用和前人相同的settings,本文提出的模型也顯著地超過了前人的最好成績。值得注意的是,這里加和不加losses的區(qū)別沒有OpenImages上那么大,很大程度上是因為Visual Genome的標注不夠完整,也就是說圖片中很多存在的視覺關系并沒有被標出來,這樣導致模型誤認為沒有標注的物體之間不存在視覺關系,進而把它們認定為負樣本。
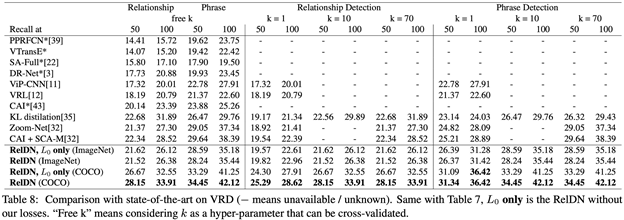
在VRD數(shù)據(jù)集上我們看到帶losses和不帶losses的差別相比VG明顯了很多,這是因為VRD的標注相對較完整,整體標注質量也相對較好。
作者有話說。。.
最后是我在這個領域做了兩年多之后的一些關于視覺關系識別場景圖構建的經(jīng)驗和思考,和本文無直接關聯(lián),但希望能和大家分享。
1. 前文提到的Language Bias是符合客觀世界分布的。如果你希望在你的任務中使用場景圖來提取更豐富的信息,而且你的數(shù)據(jù)集是從真實世界中無偏差地采樣出來的自然圖片,那么Language Bias應該是有幫助的,但如果你的數(shù)據(jù)集有偏差,或者是合成數(shù)據(jù)集(比如CLEVR),那么Language Bias可能不起作用,或者會起到反作用。
2. 在實際應用中,一個可能更好的構建場景圖的方式是把所有謂語分成若干大類,然后每個大類分別用一個模型去學,比如可以把謂語分成空間謂語(例如“to the left of, to the right of”),互動謂語(例如“ride,kick, sit on”)和其它謂語(例如“part of”)。
這么做的原因在于不同類型的謂語表達的語義是非常不同的,它們對應的視覺特征的分布也很不同,因此使用獨立的若干模型分別去學習這些語義一般會比用一個模型去學習所有語義要好。
3. 在上述的不同類型的關系當中,空間關系是最難識別的一類,因為相比而言,同一個空間關系所對應的視覺分布要復雜很多。
比如,“人騎馬”的圖片可能看上去都十分相似,但“人在馬的右邊”的圖片卻有很多種可能的布局。如果人和馬都是背對鏡頭,那么人會在整個圖片的右側,而如果人和馬是面對鏡頭,那么人會在左側,而如果人和馬是側對鏡頭,那么人在圖片中會在馬的前方或者后方。歸根結底,這種空間分布的多元性是由于
1)用2D圖片平面去描述3D世界的真實布局具有局限性;
2)Language Bias在空間關系中作用相對小很多,因為空間布局的多樣性相對很廣,在不看圖片的情況下更難“猜”出空間關系是什么。
總而言之,目前空間關系是關系識別和場景圖構建的短板,我認為后面工作可以在這個子問題上多加關注。
-
函數(shù)
+關注
關注
3文章
4327瀏覽量
62574 -
計算機視覺
+關注
關注
8文章
1698瀏覽量
45980 -
數(shù)據(jù)集
+關注
關注
4文章
1208瀏覽量
24690
原文標題:將門好聲音 | NVDIA提出一種面向場景圖解析任務的圖對比損失函數(shù)
文章出處:【微信號:thejiangmen,微信公眾號:將門創(chuàng)投】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
一種面向飛行試驗的數(shù)據(jù)融合框架

RNN的損失函數(shù)與優(yōu)化算法解析
SUMIF函數(shù)對比VLOOKUP的優(yōu)勢
YOLOv8中的損失函數(shù)解析

SUMIF函數(shù)的應用場景分析
語義分割25種損失函數(shù)綜述和展望

利用DX-BST原理圖智能工具實現(xiàn)原理圖對比的技術方法

C語言函數(shù)指針六大應用場景詳解
鴻蒙原生應用開發(fā)-ArkTS語言基礎類庫多線程TaskPool和Worker的對比(一)
verilog function函數(shù)的用法
verilog中函數(shù)和任務對比
對象檢測邊界框損失函數(shù)–從IOU到ProbIOU介紹
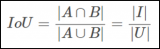
一種擴展Spring控制反轉的絕妙方法
一種AT命令通信解析模塊介紹
一種面向標識公共遞歸解析節(jié)點的數(shù)據(jù)安全加固策略





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論