") 英創(chuàng)信息技術(shù)精簡ISA總線Linux編程 – Part2簡介
英創(chuàng)信息技術(shù)精簡ISA總線Linux編程 – Part2簡介
精簡ISA總線接口是一種8-bit寬度的雙向并行擴(kuò)展總線,其特點(diǎn)是地址數(shù)據(jù)分時復(fù)用8位總線,加上4條總線控制信號,即可實(shí)現(xiàn)對外部數(shù)據(jù)的快速讀寫。若再使能一條總線時鐘信號(共13條信號),就可實(shí)現(xiàn)高達(dá)10MB/s以上的數(shù)據(jù)傳輸。精簡ISA總線作為英創(chuàng)主板的特色功能之一,在ESM6802、ESM7000、ESM7100、ESM335x等多款型號中均有配置。
關(guān)于對精簡ISA總線接口的應(yīng)用編程的基本方法,請參考《精簡ISA總線編程 – Part 1》。本文介紹由應(yīng)用程序啟動基于DMA的數(shù)據(jù)塊讀寫,即MemCpy方式的DMA。采用DMA進(jìn)行ISA總線數(shù)據(jù)傳送的目的,是為了降低高速傳送大量數(shù)據(jù)時的CPU開銷。MemCpy方式的DMA是指軟件線程啟動DMA,然后該線程掛起等待DMA操作完成。在多線程環(huán)境中,其他線程即可在DMA執(zhí)行過程中得以并行運(yùn)行。
ISA總線信號定義如下:
| 信號及說明 | PIN# | 信號及說明 | |
| RESET_B,硬件復(fù)位 | 1 | 2 | ISA_ADVn,地址鎖存控制信號 |
| ISA_AD0,地址數(shù)據(jù)總線,LSB | 3 | 4 | ISA_AD4,地址數(shù)據(jù)總線 |
| ISA_AD1,地址數(shù)據(jù)總線 | 5 | 6 | ISA_AD5,地址數(shù)據(jù)總線 |
| ISA_AD2,地址數(shù)據(jù)總線 | 7 | 8 | ISA_AD6,地址數(shù)據(jù)總線 |
| ISA_AD3,地址數(shù)據(jù)總線 | 9 | 10 | ISA_AD7,地址數(shù)據(jù)總線,MSB |
| MSLn,支持多模塊掛接總線 | 11 | 12 | ISA_WEn,數(shù)據(jù)寫控制信號 |
| GPIO9,可選作為IRQ | 13 | 14 | ISA_RDn,數(shù)據(jù)讀控制信號 |
| GPIO8,可選作為IRQ | 15 | 16 | ISA_CSn,片選控制信號 |
| GPIO25,可選作為IRQ | 17 | 18 | VDD_5V0,+5V供電 |
| GPIO24 / ISA_BCLK,同步時鐘ISA_BCLK | 19 | 20 | GND,電源信號地 |
本文以下部分,將以ESM7000 Linux平臺為例,介紹具體的編程方法。
DMA總線訪問API
應(yīng)用啟動DMA數(shù)據(jù)傳輸,需要使用數(shù)據(jù)結(jié)構(gòu)struct isa_transfer的傳遞參數(shù)和數(shù)據(jù),structisa_transfer的結(jié)構(gòu)定義如下:
|
structisa_transfer { void *rx_buf; /* != NULL: buffer for bus read */ void *tx_buf; /* != NULL: buffer for bus write */ unsigned len; /* buffer length in byte */ unsigned offset; /* offset,port address on isa bus */ unsigned inc; /* = 0: fixed offset, = 1: offset+1 after r/w */ }; |
每一個總線周期的操作只能是讀或?qū)懀虼嗽趇sa_transfer結(jié)構(gòu)中只能有一個buffer指針不為NULL。以下是執(zhí)行32字節(jié)數(shù)據(jù)塊寫的代碼,寫入地址為0x4040。順序的數(shù)據(jù)可方便時序的觀察。
|
unsignedchargbuf[64 * 1024]; unsignedint i, value; structisa_transfer t; unsignedchar *pBuf8; // write data block memset(&t, 0, sizeof(structisa_transfer)); t.offset = 0x4040; t.len = 32; // max len<= 16KB = 16 * 1024 t.tx_buf = gbuf; // fill data value = 0x55; // initialvalue pBuf8 = (unsignedchar*)t.tx_buf; for(i = 0; i *pBuf8 = (unsignedchar)(value + i); pBuf8++; } isa_write_buf(fd, &t); |
注意offset必須是0x4000 – 0x40FF,驅(qū)動程序才會啟動MemCpy方式的DMA傳輸。若從0x4040讀入32字節(jié)數(shù)據(jù),實(shí)現(xiàn)代碼則為:
|
unsignedchargbuf[64 * 1024]; structisa_transfer t; // read data block memset(&t, 0, sizeof(structisa_transfer)); t.offset = 0x4040; t.len = 32; // max len<= 16KB = 16 * 1024 t.rx_buf = gbuf; isa_read_buf(fd, &t); |
DMA傳輸總線時序說明
圖1、圖2分別為MemCpy方式DMA讀總線時序概要、寫總線時序概要。
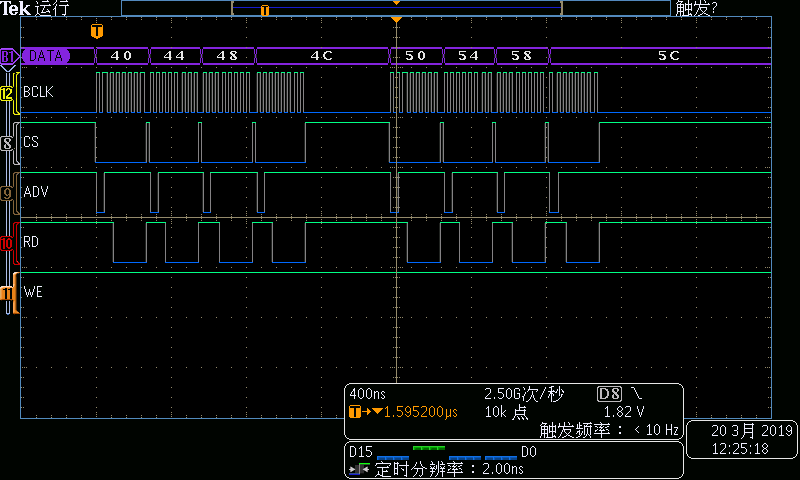
圖1DMA讀總線時序
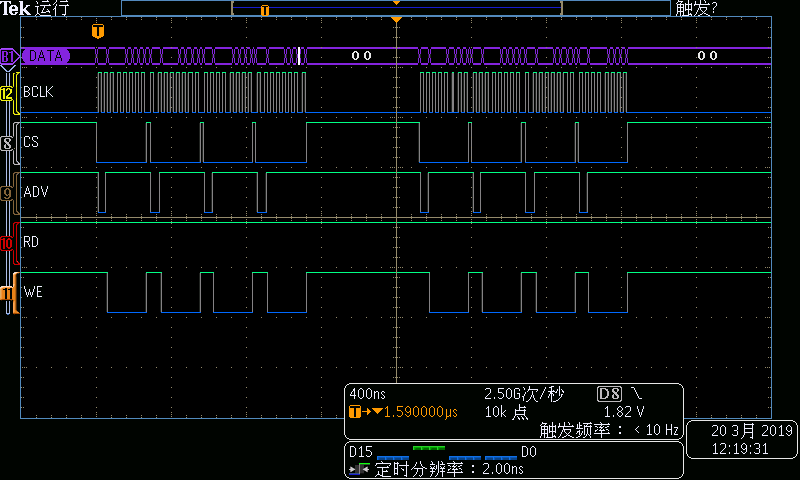
圖2DMA寫總線時序
從上面的時序可見,DMA也是16字節(jié)一組,連續(xù)4個總線周期組成,每組之間有一定間隔。DMA讀操作的總線速率大約為11.8MB/s,DMA寫操作的總線速率大約為11.2MB/s。
展開DMA寫的總線時序可看到:
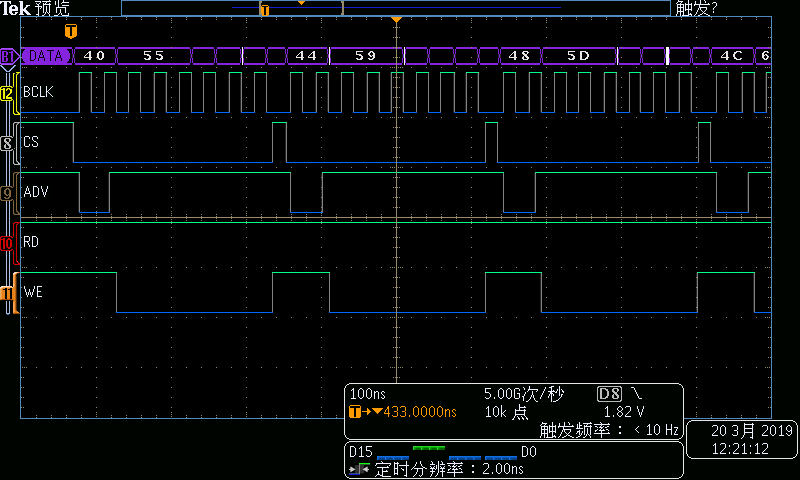
圖3DMA寫總線時序—第1組起始部分
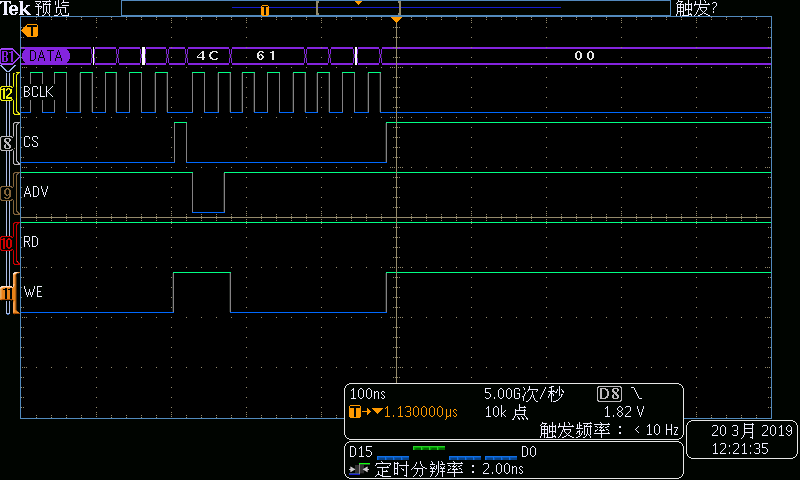
圖4DMA寫總線時序—第1組結(jié)束部分
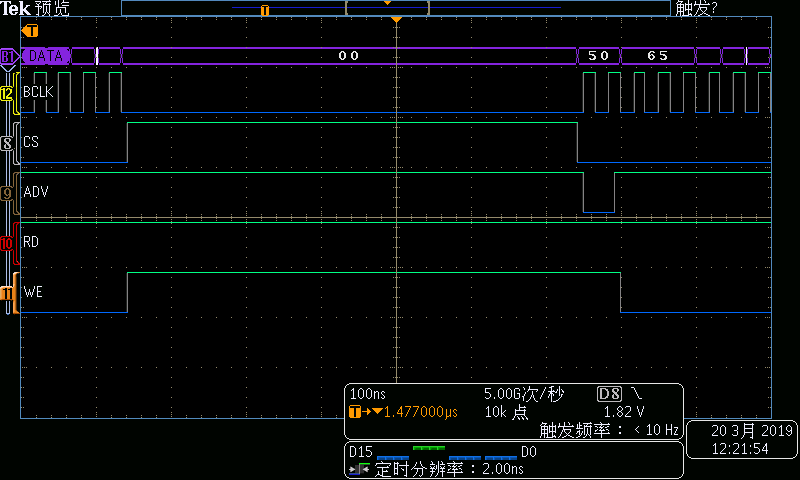
圖5DMA寫總線時序—第2組起始部分
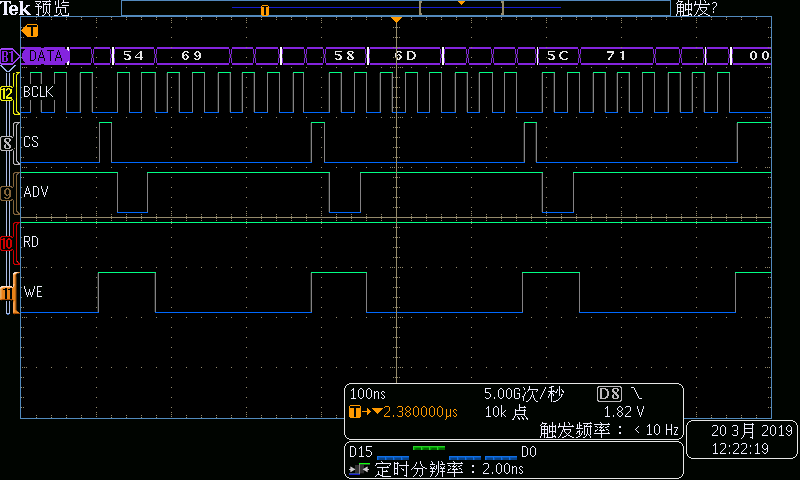
圖6DMA寫總線時序—第2組結(jié)束部分
在每個總線周期中,地址遞增4。這樣當(dāng)傳輸長度超過256字節(jié)時,ISA地址及會循環(huán)。這意味著當(dāng)采用MemCpy方式DMA進(jìn)行數(shù)據(jù)傳輸時,數(shù)據(jù)端口譯碼不能采用普通的組合電路地址譯碼方式,而必須采用BCLK+ ADV#的同步電路譯碼方式。具體方式就是每個周期的第一個BCLK下降沿鎖存到有效ADV#,標(biāo)志同步周期的開始,之后經(jīng)過連續(xù)7個BCLK下降沿后同步周期結(jié)束。
DMA傳輸時的CPU負(fù)載率
與純軟件的同步總線周期傳輸相比,DMA傳輸最大的優(yōu)點(diǎn)是有效降低了總線傳輸?shù)腃PU開銷,使應(yīng)用程序的其它線程能同步運(yùn)行。基本的測試代碼如下:
|
#define MAX_DMA_LEN (16*1024) unsignedchar gbuf[64 * 1024]; unsignedint i, count = 1; struct isa_transfer t; unsignedchar *pBuf8; longdouble a[4], b[4], loadavg; //for CPU utilization calculation FILE *fp; constchar *bus_type_name[] = {"async-cpu","async-dma-mem","async-dma-ext","sync-cpu","sync-dma-mem","sync-dma-ext"}; // fill data pBuf8 = (unsignedchar*)gbuf; for(i = 0; i < MAX_DMA_LEN; i++){ *pBuf8 = (unsignedchar)(value + i); pBuf8++; } memset(&t, 0, sizeof(struct isa_transfer)); // get initial values for calculating CPU usage in % fp = fopen("/proc/stat","r"); fscanf(fp,"%*s %Lf %Lf %Lf %Lf",&a[0],&a[1],&a[2],&a[3]); fclose(fp); // write data block loop while(count) { i = (count < MAX_DMA_LEN)? count : MAX_DMA_LEN; t.offset = offset; t.len = i; t.tx_buf = gbuf; isa_write_buf(fd, &t); count -= i; } // get end values for calculating CPU usage in % fp = fopen("/proc/stat","r"); fscanf(fp,"%*s %Lf %Lf %Lf %Lf",&b[0],&b[1],&b[2],&b[3]); fclose(fp); // calculate CPU usage in % loadavg = ((b[0]+b[1]+b[2]) - (a[0]+a[1]+a[2])) /((b[0]+b[1]+b[2]+b[3]) - (a[0]+a[1]+a[2]+a[3])); loadavg *= 100; i = (offset >> 12) & 0xf; printf("%s bus write, CPU utilization is : %Lf%%\n",bus_type_name[i], loadavg); |
使用100M數(shù)據(jù)長度來測試總的CPU負(fù)載率的情況如下:
| 模式 | MemCpy DMA | 純軟件操作 |
| 同步總線讀 | 6.01% | 50.3% |
| 同步總線寫 | 5.71% | 50.0% |
ESM7000使用的是具有雙核CPU的iMX7D,總CPU負(fù)載率50%,表示某個CPU核的負(fù)載已經(jīng)100%。DMA的使用對提高系統(tǒng)整體的性能是非常顯著的。
進(jìn)一步可測試應(yīng)用層實(shí)際的傳輸速率如下:
| 模式 | 傳輸速率 | CPU負(fù)載 |
| MemCpy DMA同步總線讀 | 8.67MB/s | 6.01% |
| MemCpy DMA同步總線寫 | 7.93MB/s | 5.71% |
若把每個周期傳輸?shù)淖止?jié)數(shù)從4個提升到8個,傳輸率則可有50%的提升。
-
Linux
+關(guān)注
關(guān)注
87文章
11319瀏覽量
209830 -
嵌入式主板
+關(guān)注
關(guān)注
7文章
6085瀏覽量
35434
發(fā)布評論請先 登錄
相關(guān)推薦
不同類型的總線技術(shù)對比
飛騰助力首屆教育信息技術(shù)應(yīng)用創(chuàng)新大賽圓滿落幕
有方科技參編的信息技術(shù)團(tuán)體標(biāo)準(zhǔn)發(fā)布
龍芯中科助力2024首屆教育信息技術(shù)應(yīng)用創(chuàng)新大賽成功舉辦
拓維信息參與牽頭組建!長沙新一代信息技術(shù)產(chǎn)教聯(lián)合體正式獲批

中科創(chuàng)達(dá)榮獲2024年軟件和信息技術(shù)服務(wù)優(yōu)秀企業(yè)
Linux應(yīng)用編程的基本概念
信創(chuàng)國產(chǎn)化背景下的工控主板發(fā)展現(xiàn)狀
加速鯤鵬落地!拓維信息信創(chuàng)遷移工具榮獲鯤鵬原生開發(fā)技術(shù)認(rèn)證
梯度科技入選2023年信息技術(shù)應(yīng)用創(chuàng)新解決方案名單
中軟國際信創(chuàng)服務(wù)助力大連信創(chuàng)產(chǎn)業(yè)發(fā)展
光庭信息榮膺武漢市僑屆“科創(chuàng)之星”稱號
龍芯中科三項(xiàng)信創(chuàng)方案入圍工信部2023年信息技術(shù)應(yīng)用創(chuàng)新應(yīng)用示范案例名單

RX78M組 EtherCAT ETG.5003示例程序固件信息技術(shù)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論